Наткнулся на статью в блоге компании Школа Данных и решил проверить, на что способна библиотека Fast.ai на том же датасете, который упоминается в статье. Здесь вы не найдете рассуждений о том, как важно своевременно и правильно диагностировать пневмонию, будут ли нужны врачи-рентгенологи в условиях развития технологий, можно ли считать предсказание нейронной сети медицинским диагнозом и т.д. Основная цель — показать, что машинное обучение в современных библиотеках может быть довольно простым (буквально требует немного строчек кода) и дает отличные результаты. Запомним пока результат из статьи (precision = 0.84, recall = 0.96) и посмотрим, что получится у нас.
Берем данные для обучения отсюда. Данные представляют собой 5856 рентгеновских снимков, распределенных по двум классам — с признаками пневмонии и без. Задача нейронной сети — дать нам качественный бинарный классификатор рентгеновских снимков для определения признаков пневмонии.
Начинаем с импортирования библиотек и некоторых стандартных настроек:
Далее определяем batch size. При обучении на GPU важно его подобрать таким образом, чтобы у вас не переполнялась память. При необходимости его можно уменьшить в два раза.
Важный Update:
Как справедливо заметили в комментариях ниже, важно четко отслеживать данные, на которых модель будет обучаться и на которых мы будем проверять ее эффективность. Обучать модель будем по изображениям в папках train и val, а валидировать по изображениям в папке test, аналогично тому, как делалось здесь.
Определяем пути к нашим данным
и проверяем, что все папки на месте (папку val перенесли в train):
Готовим наши данные для «загрузки» в нейросеть. Важно отметить, что в Fast.ai есть несколько методов сопоставления изображения метке. Метод from_folder говорит нам о том, что метки нужно брать из имени папки, в которой находится изображение.
Параметр size означает, что мы ресайзим все изображения до размера 299х299 (наши алгоритмы работают с квадратными изображениями). Функция get_transforms дает нам аугментацию изображений для увеличения объема данных для обучения (мы оставляем здесь дефолтные настройки).
Заглянем в данные:
Для проверки смотрим, какие классы у нас получились и какое количественное распределение изображений между train и validation:
Определяем модель обучения на архитектуре Resnet50:
и начинаем обучение на 8 эпох, основываясь на One Cycle Policy:
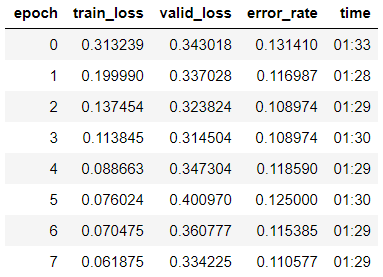
Видим, что мы уже получили точность в 89% на валидационной выборке. Запишем пока веса нашей модели и попробуем улучшить результат.
«Размораживаем» всю модель, т.к. до этого мы обучали модель только на последней группе слоев, а веса остальных были взяты из предобученной на Imagenet модели и «заморожены»:
Ищем оптимальный learning rate для продолжения обучения:
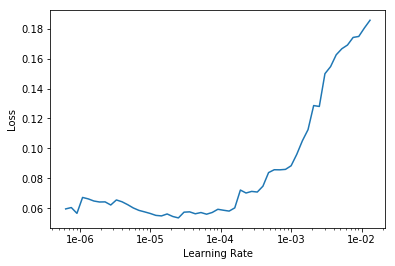
Запускаем обучение на 10 эпох с различными learning rate для каждой группы слоев.

Видим, что точность нашей модели немного повысилась до 89,4% на валидационной выборке.
Запишем веса.
Строим Confusion Matrix:

В этом месте мы вспомним, что сам по себе параметр точности (accuracy) недостаточен, особенно для несбалансированных классов. Например, если в реальной жизни пневмония будет встречаться только у 0,1% тех, кто проходит рентген исследование, система может просто выдавать отсутствие пневмонии во всех случаях и ее точность будет на уровне 99,9% с абсолютно нулевой полезностью.
Здесь и вступают в игру метрики Precision и Recall:
Видим, что полученный нами результат даже немного выше, чем тот, который был упомянут в статье. При дальнейшей работе над задачей стоит помнить, что Recall — крайне важный параметр в медицинских задачах, т.к. False Negative ошибки наиболее опасны с точки зрения диагностики (означает, что мы можем просто «проглядеть» опасный диагноз).
Берем данные для обучения отсюда. Данные представляют собой 5856 рентгеновских снимков, распределенных по двум классам — с признаками пневмонии и без. Задача нейронной сети — дать нам качественный бинарный классификатор рентгеновских снимков для определения признаков пневмонии.
Начинаем с импортирования библиотек и некоторых стандартных настроек:
%reload_ext autoreload
%autoreload 2
%matplotlib inline
from fastai.vision import *
from fastai.metrics import error_rate
import osДалее определяем batch size. При обучении на GPU важно его подобрать таким образом, чтобы у вас не переполнялась память. При необходимости его можно уменьшить в два раза.
bs = 64Важный Update:
Как справедливо заметили в комментариях ниже, важно четко отслеживать данные, на которых модель будет обучаться и на которых мы будем проверять ее эффективность. Обучать модель будем по изображениям в папках train и val, а валидировать по изображениям в папке test, аналогично тому, как делалось здесь.
Определяем пути к нашим данным
path = Path('storage/chest_xray')
path.ls()и проверяем, что все папки на месте (папку val перенесли в train):
Out:
[PosixPath('storage/chest_xray/train'),
PosixPath('storage/chest_xray/test')]Готовим наши данные для «загрузки» в нейросеть. Важно отметить, что в Fast.ai есть несколько методов сопоставления изображения метке. Метод from_folder говорит нам о том, что метки нужно брать из имени папки, в которой находится изображение.
Параметр size означает, что мы ресайзим все изображения до размера 299х299 (наши алгоритмы работают с квадратными изображениями). Функция get_transforms дает нам аугментацию изображений для увеличения объема данных для обучения (мы оставляем здесь дефолтные настройки).
np.random.seed(5)
data = ImageDataBunch.from_folder(path, train = 'train', valid = 'test', size=299, bs=bs, ds_tfms=get_transforms()).normalize(imagenet_stats)Заглянем в данные:
data.show_batch(rows=3, figsize=(6,6))Для проверки смотрим, какие классы у нас получились и какое количественное распределение изображений между train и validation:
data.classes, data.c, len(data.train_ds), len(data.valid_ds)Out:
(['NORMAL', 'PNEUMONIA'], 2, 5232, 624)
Определяем модель обучения на архитектуре Resnet50:
learn = cnn_learner(data, models.resnet50, metrics=error_rate)и начинаем обучение на 8 эпох, основываясь на One Cycle Policy:
learn.fit_one_cycle(8)Видим, что мы уже получили точность в 89% на валидационной выборке. Запишем пока веса нашей модели и попробуем улучшить результат.
learn.save('step-1-50')«Размораживаем» всю модель, т.к. до этого мы обучали модель только на последней группе слоев, а веса остальных были взяты из предобученной на Imagenet модели и «заморожены»:
learn.unfreeze()Ищем оптимальный learning rate для продолжения обучения:
learn.lr_find()
learn.recorder.plot()Запускаем обучение на 10 эпох с различными learning rate для каждой группы слоев.
learn.fit_one_cycle(10, max_lr=slice(1e-6, 1e-4))Видим, что точность нашей модели немного повысилась до 89,4% на валидационной выборке.
Запишем веса.
learn.save('step-2-50')Строим Confusion Matrix:
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()В этом месте мы вспомним, что сам по себе параметр точности (accuracy) недостаточен, особенно для несбалансированных классов. Например, если в реальной жизни пневмония будет встречаться только у 0,1% тех, кто проходит рентген исследование, система может просто выдавать отсутствие пневмонии во всех случаях и ее точность будет на уровне 99,9% с абсолютно нулевой полезностью.
Здесь и вступают в игру метрики Precision и Recall:
- TP — истино-положительное предсказание;
- TN — истино-отрицательное предсказание;
- FP — ложно-положительное предсказание;
- FN — ложно-отрицательное предсказание.


Видим, что полученный нами результат даже немного выше, чем тот, который был упомянут в статье. При дальнейшей работе над задачей стоит помнить, что Recall — крайне важный параметр в медицинских задачах, т.к. False Negative ошибки наиболее опасны с точки зрения диагностики (означает, что мы можем просто «проглядеть» опасный диагноз).
