В предыдущих публикациях (ч. 1 и ч. 2) были рассмотрены основные подходы, применяемые в алгоритме нечеткого поиска TextRadar и особенности решения практических задач. В продолжение начатой в ч. 2 темы оптимизации, сегодня речь пойдет об индексировании, в первую очередь как средстве ускорения поиска в многостраничных текстах, но не только. В результате мы получим тот же результат, что и с использованием описанных ранее подходов, только быстрее.
Задача поиска фразы в тексте, разбитом на страницы, сводится к расчету коэффициента релевантности для каждой из страниц и последующей сортировке списка в порядке убывания коэффициента.
В процессе расчета в соответствии с базовым подходом каждая страница подвергается посимвольному анализу и здесь кроется возможность оптимизации.

При вычислении коэффициента анализируются группы совпадающих символов строк поиска и данных, при этом группы могут образовываться только в рамках слов. С другой стороны, рассматривая проблему завышенной значимости «длинных» слов (в ч. 2), в качестве возможного варианта решения предлагался «расчет релевантности поисковой фразы как среднего от релевантностей входящих в нее слов, вычисленных независимо». Использование индекса позволит получить результат, эквивалентный именно этому подходу.
Идея индексирования не нова и состоит в следующем — в связи с тем, что слова в тексте повторяются, объем вычислений можно сократить. Для этого по тексту, в котором будет осуществляться поиск, необходимо предварительно сформировать индекс. В простейшем случае индекс представляет собой таблицу всех слов текста, в которой помимо слов содержатся данные о страницах, на которых они встречаются. Фрагмент таблицы индекса, построенного по тексту романа Л.Н. Толстого «Война и мир» (всего в нем содержится порядка 50 тыс. слов), приведен на рисунке.

Непосредственно в процессе обработки запроса, строка поиска сначала разбивается на слова. Далее, для каждого из слов строки поиска вычисляется релевантность каждому из слов индекса. Результаты расчета накапливаются в таблице предварительных результатов, содержащей колонки «Слово строки поиска», «Слово индекса», «Коэффициент релевантности», «Номер страницы». В таблицу попадают только те строки индекса, коэффициент релевантности по словам которых превысил заданный порог. То есть, каждая строка индекса с подходящим словом порождает в таблице предварительных результатов строки в количестве, равном числу страниц текста, на которых это слово встречается. Ниже приведен фрагмент таблицы предварительных результатов для поиска фразы «Вечер у Анны Павловны Шерер».

Затем таблица предварительных результатов сортируется по колонкам Номер страницы, Слово строки поиска, Коэффициент (по убыванию).

Обходя строки отсортированной таблицы, по каждой из страниц и для каждого слова строки поиска выявляется наиболее релевантное слово данной страницы – благодаря описанной выше сортировке это первое слово для каждой комбинации Номер страницы – Слово строки поиска. Остальные строки по комбинации отбрасываются.

Таким образом, для каждой страницы текста, попавшей в таблицу предварительных результатов, по каждому слову строки поиска будут найдены наиболее релевантные слова этой страницы с соответствующими коэффициентами. Сумма коэффициентов найденных на странице слов, отнесенная к количеству слов в строке поиска, даст коэффициент релевантности для страницы.

Например, на приведенном выше рисунке, поиск происходит по строке «Вечер у Анны Павловны Шерер» (предлог «у» не учитываем), выделенные серым строки отброшены при обходе. Коэффициент релевантности для страницы 1 будет (0,75 + 1 + 0,875 + 1) / 4 = 0,906, для страницы 2 – 0.906, для 3 – 0.75.
Если не учитывать время, затраченное на индексирование, результаты которого используются многократно и принять во внимание, что общий объем вычислений, оценка которого приводилась в ч. 1, кратен длине строки данных:
 ;
;
можно говорить о том, что выигрыш от использования индекса будет кратен отношению:

Например, на демо-стенде textradar.ru, текст романа «Война и мир» разбит на 1488 страниц по 2000 символов в каждой. При этом общее количество символов в словах индекса, состоящем из 52156 элементов, составляет 434060. То есть выигрыш от индексирования составит порядка 7:

В связи с тем, что результаты, получаемые с помощью индексирования, эквивалентны результатам, получаемым с помощью одного из описанных ранее подходов без него, появляется возможность совместной обработки результатов поиска по проиндексированной и не проиндексированной частям текста. Ввиду того, что индексирование является относительно затратной операцией и обычно выполняется по расписанию, возможна ситуация, когда часть текста проиндексирована, а часть еще нет. В этом случае экономия в объеме вычислений будет кратна доле проиндексированного текста в его общем размере:

Помимо повышения скорости поиска, использование индекса открывает еще целый ряд возможностей. Например, с помощью статистических данных, полученных при индексировании, можно повысить значимость редких слов, а также выделить страницы текста, на которых слова поисковой фразы встречаются чаще. Также таблицу индекса можно расширить синонимами.
На этом цикл публикаций, посвященных описанию TextRadar завершается. Спасибо всем за проявленный интерес и ценные замечания, которые позволили продвинуться дальше, чем изначально планировалось.
На сайте textradar.ru развернут демо-стенд, на котором можно ознакомиться с работой алгоритма.
Предпосылки
Задача поиска фразы в тексте, разбитом на страницы, сводится к расчету коэффициента релевантности для каждой из страниц и последующей сортировке списка в порядке убывания коэффициента.
В процессе расчета в соответствии с базовым подходом каждая страница подвергается посимвольному анализу и здесь кроется возможность оптимизации.

При вычислении коэффициента анализируются группы совпадающих символов строк поиска и данных, при этом группы могут образовываться только в рамках слов. С другой стороны, рассматривая проблему завышенной значимости «длинных» слов (в ч. 2), в качестве возможного варианта решения предлагался «расчет релевантности поисковой фразы как среднего от релевантностей входящих в нее слов, вычисленных независимо». Использование индекса позволит получить результат, эквивалентный именно этому подходу.
Индекс
Идея индексирования не нова и состоит в следующем — в связи с тем, что слова в тексте повторяются, объем вычислений можно сократить. Для этого по тексту, в котором будет осуществляться поиск, необходимо предварительно сформировать индекс. В простейшем случае индекс представляет собой таблицу всех слов текста, в которой помимо слов содержатся данные о страницах, на которых они встречаются. Фрагмент таблицы индекса, построенного по тексту романа Л.Н. Толстого «Война и мир» (всего в нем содержится порядка 50 тыс. слов), приведен на рисунке.

Непосредственно в процессе обработки запроса, строка поиска сначала разбивается на слова. Далее, для каждого из слов строки поиска вычисляется релевантность каждому из слов индекса. Результаты расчета накапливаются в таблице предварительных результатов, содержащей колонки «Слово строки поиска», «Слово индекса», «Коэффициент релевантности», «Номер страницы». В таблицу попадают только те строки индекса, коэффициент релевантности по словам которых превысил заданный порог. То есть, каждая строка индекса с подходящим словом порождает в таблице предварительных результатов строки в количестве, равном числу страниц текста, на которых это слово встречается. Ниже приведен фрагмент таблицы предварительных результатов для поиска фразы «Вечер у Анны Павловны Шерер».

Затем таблица предварительных результатов сортируется по колонкам Номер страницы, Слово строки поиска, Коэффициент (по убыванию).

Обходя строки отсортированной таблицы, по каждой из страниц и для каждого слова строки поиска выявляется наиболее релевантное слово данной страницы – благодаря описанной выше сортировке это первое слово для каждой комбинации Номер страницы – Слово строки поиска. Остальные строки по комбинации отбрасываются.
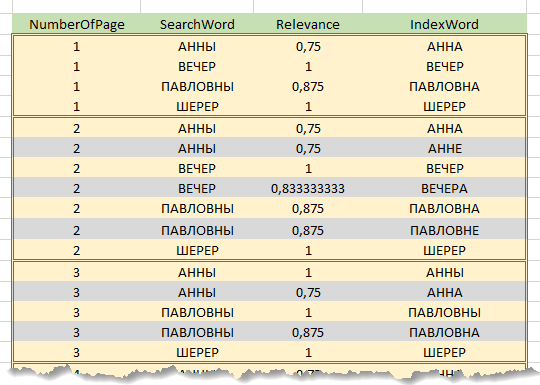
Таким образом, для каждой страницы текста, попавшей в таблицу предварительных результатов, по каждому слову строки поиска будут найдены наиболее релевантные слова этой страницы с соответствующими коэффициентами. Сумма коэффициентов найденных на странице слов, отнесенная к количеству слов в строке поиска, даст коэффициент релевантности для страницы.

Например, на приведенном выше рисунке, поиск происходит по строке «Вечер у Анны Павловны Шерер» (предлог «у» не учитываем), выделенные серым строки отброшены при обходе. Коэффициент релевантности для страницы 1 будет (0,75 + 1 + 0,875 + 1) / 4 = 0,906, для страницы 2 – 0.906, для 3 – 0.75.
Преимущества
Если не учитывать время, затраченное на индексирование, результаты которого используются многократно и принять во внимание, что общий объем вычислений, оценка которого приводилась в ч. 1, кратен длине строки данных:
 ;
;можно говорить о том, что выигрыш от использования индекса будет кратен отношению:
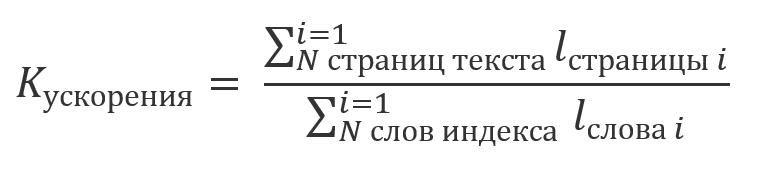
Например, на демо-стенде textradar.ru, текст романа «Война и мир» разбит на 1488 страниц по 2000 символов в каждой. При этом общее количество символов в словах индекса, состоящем из 52156 элементов, составляет 434060. То есть выигрыш от индексирования составит порядка 7:

В связи с тем, что результаты, получаемые с помощью индексирования, эквивалентны результатам, получаемым с помощью одного из описанных ранее подходов без него, появляется возможность совместной обработки результатов поиска по проиндексированной и не проиндексированной частям текста. Ввиду того, что индексирование является относительно затратной операцией и обычно выполняется по расписанию, возможна ситуация, когда часть текста проиндексирована, а часть еще нет. В этом случае экономия в объеме вычислений будет кратна доле проиндексированного текста в его общем размере:
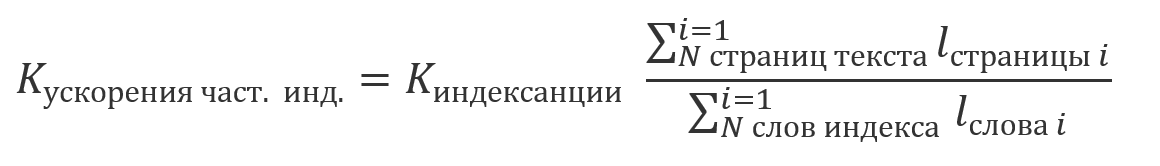
Помимо повышения скорости поиска, использование индекса открывает еще целый ряд возможностей. Например, с помощью статистических данных, полученных при индексировании, можно повысить значимость редких слов, а также выделить страницы текста, на которых слова поисковой фразы встречаются чаще. Также таблицу индекса можно расширить синонимами.
На этом цикл публикаций, посвященных описанию TextRadar завершается. Спасибо всем за проявленный интерес и ценные замечания, которые позволили продвинуться дальше, чем изначально планировалось.
На сайте textradar.ru развернут демо-стенд, на котором можно ознакомиться с работой алгоритма.









