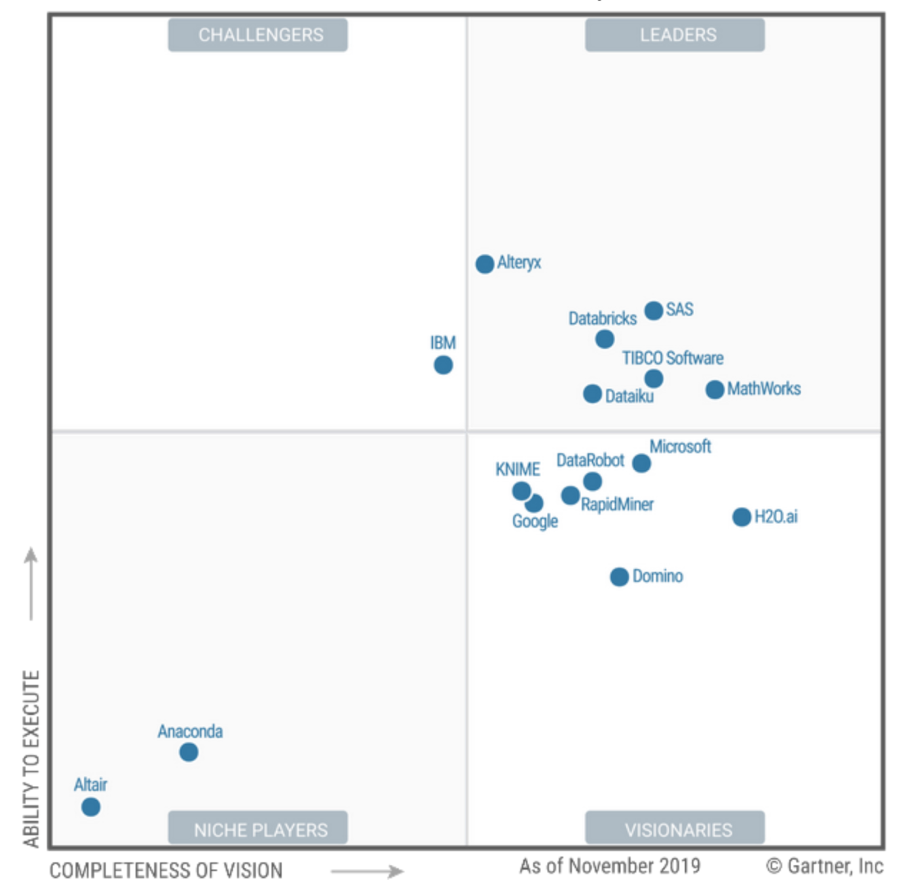
Невозможно объяснить причину, зачем я это прочел. Просто было время и было интересно, как устроен рынок. А это уже полноценный рынок по Gartner с 2018го года. С 2014-2016 называлось продвинутой аналитикой (корни в BI), в 2017 – Data Science (не знаю, как перевести это на русский). Кому интересны передвижения вендоров по квадрату – можно здесь посмотреть. А я буду говорить про квадрат 2020го года, тем более, что изменения там с 2019го минимальные: выехал SAP и Altair купил Datawatch.
Это не систематизированный разбор и не таблица. Индивидуальный взгляд, еще с точки зрения геофизика. Но мне всегда любопытно читать Gartner MQ, они прекрасно некоторые моменты формулируют. Так что тут вещи, на которые я обратил внимание и в техническом плане, и в рыночном, и в философском.
Это не для людей, которые глубоко в теме ML, но для людей, которые интересуются тем, что вообще происходит на рынке.
Сам DSML рынок логично гнездится между BI и Cloud AI developer services.
Сначала понравившееся цитаты и термины:
Итак:
Прикольный интерфейс прямо игрушечный. С масштабируемостью, конечно, туговато. Соотвественно коммьюнити Citizen инженеров вокруг таких же с цацками поиграть. Аналитика своя все свое в одном флаконе. Напомнило мне комплекс спектрально-корреляционного анализа данных Coscad, который программировали в 90х.
Коммьюнити вокруг Python и R экспертов. Опенсорса большая соотвественно. Выяснилось, что мои коллеги постоянно используют. А я не знал.
Состоит из трех opensource проектов — разработчики Spark денег подняли адово количество с 2013. Я прям должен процытировать wiki:
А проекты такие:
Посмотреть можно про Spark, кто вдруг не знает или забыл: ссылка. Видосики посмотрел с примерами от немного занудных но детальных консалт-дятлов: DataBricks для Data Science (ссылка) и для Data Engineering (ссылка).
Короче Databricks вытаскивает Spark. Кто хочет Spark нормально поюзать в облаке берет DataBricks не задумываясь, как и задумывалось :) Spark – здесь главный дифференциатор.
Узнал, что Spark Streaming — это не настоящий fake realtime или microbatching. А если нужен настоящий Real Real time — это в Apache STORM. Еще все говорят и пишут, что Spark круче MapReduce. Лозунг такой.
Прикольная штучка end-to-end. Рекламы много. Не понял, чем от Alteryx отличается?
Paxata для подготовки данных классно – это отдельная компания, которую в Декабре 2019 купили Дата Роботы. Подняли 20 MUSD и продались. Все за 7 лет.
Подготовка данных в Paxata, а не в Excel – здесь посмотреть: ссылка.
Автоматические лукапчики там и предложения join’ов между двумя датасетами. Отличная вещь — чтобы поразбираться с данными, еще бы побольше упора на текстовую информацию (ссылка).
Data Catalogue – отличный каталог никому не нужных “живых” датасетов.
Тоже интересно как каталоги формируются в Paxata (ссылка).
Основной продукт Data Robot это здесь. Их лозунг — от Модели к корпоративному приложению! Обнаружил консалтинг для нефтянки в связи с кризисом, но очень банальный и неинтересный: ссылка. Посмотрел их видео по Mops или MLops (ссылка). Это такой Франкенштейн собранный из 6-7 аквизишенов различных продуктов.
Конечно становиться понятно, что большая команда Data Scientists должна иметь именно такую среду для работы с моделями, а то они наплодят их множество и ничего никогда не задеплоят. А в нашей нефтегазовой upstream реальности — одну модельку бы удачную создать и это уже большой прогресс!
Сам процесс очень напомнил работу проектными системами в геологии-геофизике, например Petrel. Все кому не лень делают и модифицируют модели. Собирают в модели данные. Потом сделали эталонную модель и передают в производство! Те между скажем геологической моделью и ML моделью можно найти много общего.
Упор на открытую платформу и на коллаборейшн. Бизнес пользователей пускают бесплатно. Их Data Lab сильно напоминает шарепоинт. (А от названия сильно отдает IBMом). Все эксперименты линкуют к исходному датасету. Как это знакомо :) Как в нашей практике – какие-то данные в модель затащили, потом там в модели почистили и привели в порядок и все это там уже живет в модели и концов в исходных данных не найти.
У Domino крутая инфраструктурная виртуализация. Собрал машинку сколько надо ядер за секунду и поехал считать. Как сделано — не совсем понятно сразу. Везде Docker. Много свободы! Любые воркспейсы последних версий можно подключать. Параллельный запуск экспериментов. Трэкинг и отбор удачных.
То же что и DataRobot — результаты публикуются для бизнес пользователей в виде приложений. Для особо одаренных «стейкхолдеров». И еще мониторится собственно использование моделей. Все для Мопсов!
Не понял до конца как сложные модели в продакшн уходят. Какое-то API предоставляется, чтобы их накормить данными и получать результаты.
Driveless AI — очень компактная и понятная система для Supervised ML. Все в одной коробочке. Про бэкэнд не понятно до конца сразу.
Модель автоматически упаковывают в REST сервер или Java App. Это отличная идея. Многое сделано для Interpretability и Explainability. Интерпретация и объяснение результатов работы модели (Что по своей сути не должно быть объяснимо, иначе и человек может то же посчитать?).
Впервые подробно рассматривается кейс про неструктурированные данные и NLP. Качественная архитектурная картинка. И вообще картинки понравились.
Есть большой опенсорс фреймворк H2O не совсем понятно (набор алгоритмов/библиотек?). Собственный ноутбук визуальный без програмирования как Jupiter (ссылка). Еще почитал про Pojo и Mojo — модели H2O обернутые в яву. Первое в лоб, второе с оптимизацией. H20 — единственные(!), кому Gartner вписал текстовую аналитику и NLP в сильные стороны, а так же их усилия в отношении Explanability. Это очень важно!
Там же: высокая производительность, оптимизация и стандарт для отрасли в области интеграции с железами и облаками.
А в слабости логично — Driverles AI слабоват и узковат по сравнению с их же опенсорсом. Подготовка данных хромает по сравнению с той же Paxata! И игнорируют индустриальные данные — stream, graph, geo. Ну не может прямо все быть хорошо.
Понравились 6 очень конкретных очень интересных бизнес кейсов на заглавной странице. Сильный OpenSource.
Gartner из лидеров опустил в визионеры. Плохо деньги зарабатывают — хороший знак для пользователей, учитывая что Лидер – не всегда лучший выбор.
Ключевое слово как и в H2O — augmented это значит помощь убогим citizen data scientists. Впервые кого-то в обзоре поругали за производительность! Интересно? То есть вычислительных мощностей столько, что производительность вообще не может быть системной проблемой? Про это слово “Augmented” у Gartner есть отдельная статья, до которой добраться не удалось.
И KNIME в обзоре кажется первый неамериканец! (И дизайнерам нашим очень их лэндинг понравился. Странные люди.
MatLаb – старый почетный товарищ известный всем! Тулбоксы для всех областей жизни и ситуаций. Что-то очень другое. Фактически много-много-много математики на все вообще случаи жизни!
Дополнительный продукт Simulink для дизайна систем. Закопался в тулбоксы для Цифровых Двойников — ничего про это не понимаю, а тут прямо много написано. Для нефтянки. В общем это принципиально другой продукт из глубин математики и инженерии. Для подбора тулкитов математики конкретной. Согласно Гартнеру у них проблемы все как у умных инженеров — никакой коллаборации — каждый в своей модели роется, никакой демократии, никакого эксплейнабилити.
Много и сталкивался и слышал ранее (наряду с Матлабом) в контексте хорошего опенсорса. Закопался немного в TurboPrep как обычно. Интересует меня как из грязных данных чистые получать.
Снова видно, что люди хорошие по маркетинговым материалам 2018 года и ужасно говорящим по английски людям на feature demo.
А люди из Дортмунда с 2001 c сильным немецким прошлым)

Так и не понял из сайта что именно в опенсорсе доступно — нужно глубже закапываться. Хорошие видосики про деплоймент и AutoML их концепции.
Про бэкенд RapidMiner Server тоже ничего особого нет. Наверное это будет компактно и хорошо работать on premice out of the box. В Docker упаковывается. Шаред environment только на сервере RapidMiner. И еще есть Radoop, данные из хадупа, считалки из Spark в Studio workflow.
Подвинули их вниз как и ожидалось молодые горячие вендоры «продавцы полосатых палочек». Гартнер однако пророчит им будущий успех в Enterprise пространстве. Денег там поднять можно. Немцы это умеют свят-свят :) Don’t mention SAP!!!
Для ситизенов много делают! Но по странице видно как Gartner и говорит, что с инновационностью продаж туговато у них и они не борются за широту покрытия, но за прибыльность.
Остались SAS и Tibco типичные BI вендоры для меня… И оба в самом топе, что подтверждает мою уверенность в том, что нормальный DataScience логически растет
из BI, а не из облаков и Hadoop инфраструктур. Из бизнеса т.е., а не из IT. Как в Газпромнефть например: ссылка, зрелая DSML среда вырастает из прочной BI практики. Но может она и с душком и перекосом на MDM и прочие дела, кто знает.
Нечего сказать особо. Только очевидные вещи.
Стратегия читается в списке покупок на странице в Wiki длинной со страницу. Да, долгая история, но 28!!! Карл. подкупила BI Spotfire (2007) еще во времена моей техно-молодости. И еще репортинг Jaspersoft (2014), далее аж трех вендоров предиктивной аналитики Insightful (S-plus) (2008), Statistica (2017) and Alpine Data (2017), обработка событий и стриминг Streambase System (2013), MDM Orchestra Networks (2018) и Snappy Data (2019) in-memory платформа.
Привет, Фрэнки!

Это не систематизированный разбор и не таблица. Индивидуальный взгляд, еще с точки зрения геофизика. Но мне всегда любопытно читать Gartner MQ, они прекрасно некоторые моменты формулируют. Так что тут вещи, на которые я обратил внимание и в техническом плане, и в рыночном, и в философском.
Это не для людей, которые глубоко в теме ML, но для людей, которые интересуются тем, что вообще происходит на рынке.
Сам DSML рынок логично гнездится между BI и Cloud AI developer services.
Сначала понравившееся цитаты и термины:
- «A Leader may not be the best choice» — Лидер рынка – это совершенно необязательно то, что нужно вам. Очень насущно! Как следствие отсутствия функционального заказчика вечно ищут все «лучшее» решение, а не «подходящее».
- «Model operationalisation» — сокращается как MOPs. И с мопсами у всех тяжеловато! –(прикольная тема мопсик заставляет модель работать).
- «Notebook environment» – важный концепт, где код, комментарии, данные и результаты объединяются вместе. Это очень понятно, перспективно и может существенно сократить объем UI кода.
- «Rooted in OpenSource» — хорошо сказано – укореняется в опенсорсе.
- «Citizen Data Scientists» — такие легкие чуваки, ламеры такие, не эксперты, которым нужна среда визуальная и всякие вспомогательные штуки. Кодить они не будут.
- «Democratise» — часто используется в значении “сделать доступным более широкому кругу людей”. Можно говорить «democratise the data» вместо опасного «free the data», который мы раньше использовали. «Democratise» — это всегда long tail и за ним все вендоры бегут. Потерять в наукоемкости — выиграть в доступности!
- «Exploratory Data Analysis – EDA» — рассматривание данными подручными средствами. Немного статистики. Немного визуализации. То, что все делают в той или иной степени. Не знал, что для этого есть название
- «Reproducability» — максимальное сохранение всех параметров среды, входов и выходов с тем, чтобы можно было повторить эксперимент однажды проведенный. Важнейший термин для экспериментальной тестовой среды!
Итак:
Alteryx
Прикольный интерфейс прямо игрушечный. С масштабируемостью, конечно, туговато. Соотвественно коммьюнити Citizen инженеров вокруг таких же с цацками поиграть. Аналитика своя все свое в одном флаконе. Напомнило мне комплекс спектрально-корреляционного анализа данных Coscad, который программировали в 90х.
Anaconda
Коммьюнити вокруг Python и R экспертов. Опенсорса большая соотвественно. Выяснилось, что мои коллеги постоянно используют. А я не знал.
DataBricks
Состоит из трех opensource проектов — разработчики Spark денег подняли адово количество с 2013. Я прям должен процытировать wiki:
“In September 2013, Databricks announced that it had raised $13.9 million from Andreessen Horowitz. The company raised additional $33 million in 2014, $60 million in 2016, $140 million in 2017, $250 million in 2019 (Feb) and $400 million in 2019 (Oct)”!!!Великие какие-то люди Spark пилили. Не знаком жаль!
А проекты такие:
- Delta Lake — ACID на Spark совсем недавно отрелизили (то о чем мы мечтали над Elasticsearch) — превращает его в БД: жесткая схема, ACID, аудит, версии…
- ML Flow — трекинг, упаковка, управление и хранение моделей.
- Koalas — Pandas DataFrame API на Spark — Pandas — Python API для работы с табличками и данными вообще.
Посмотреть можно про Spark, кто вдруг не знает или забыл: ссылка. Видосики посмотрел с примерами от немного занудных но детальных консалт-дятлов: DataBricks для Data Science (ссылка) и для Data Engineering (ссылка).
Короче Databricks вытаскивает Spark. Кто хочет Spark нормально поюзать в облаке берет DataBricks не задумываясь, как и задумывалось :) Spark – здесь главный дифференциатор.
Узнал, что Spark Streaming — это не настоящий fake realtime или microbatching. А если нужен настоящий Real Real time — это в Apache STORM. Еще все говорят и пишут, что Spark круче MapReduce. Лозунг такой.
DATAIKU
Прикольная штучка end-to-end. Рекламы много. Не понял, чем от Alteryx отличается?
DataRobot
Paxata для подготовки данных классно – это отдельная компания, которую в Декабре 2019 купили Дата Роботы. Подняли 20 MUSD и продались. Все за 7 лет.
Подготовка данных в Paxata, а не в Excel – здесь посмотреть: ссылка.
Автоматические лукапчики там и предложения join’ов между двумя датасетами. Отличная вещь — чтобы поразбираться с данными, еще бы побольше упора на текстовую информацию (ссылка).
Data Catalogue – отличный каталог никому не нужных “живых” датасетов.
Тоже интересно как каталоги формируются в Paxata (ссылка).
«According to analyst firm Ovum, the software is made possible through advances in predictive analytics, machine learning and the NoSQL data caching methodology.[15] The software uses semantic algorithms to understand the meaning of a data table's columns and pattern recognition algorithms to find potential duplicates in a data-set.[15][7] It also uses indexing, text pattern recognition and other technologies traditionally found in social media and search software.»
Основной продукт Data Robot это здесь. Их лозунг — от Модели к корпоративному приложению! Обнаружил консалтинг для нефтянки в связи с кризисом, но очень банальный и неинтересный: ссылка. Посмотрел их видео по Mops или MLops (ссылка). Это такой Франкенштейн собранный из 6-7 аквизишенов различных продуктов.
Конечно становиться понятно, что большая команда Data Scientists должна иметь именно такую среду для работы с моделями, а то они наплодят их множество и ничего никогда не задеплоят. А в нашей нефтегазовой upstream реальности — одну модельку бы удачную создать и это уже большой прогресс!
Сам процесс очень напомнил работу проектными системами в геологии-геофизике, например Petrel. Все кому не лень делают и модифицируют модели. Собирают в модели данные. Потом сделали эталонную модель и передают в производство! Те между скажем геологической моделью и ML моделью можно найти много общего.
Domino
Упор на открытую платформу и на коллаборейшн. Бизнес пользователей пускают бесплатно. Их Data Lab сильно напоминает шарепоинт. (А от названия сильно отдает IBMом). Все эксперименты линкуют к исходному датасету. Как это знакомо :) Как в нашей практике – какие-то данные в модель затащили, потом там в модели почистили и привели в порядок и все это там уже живет в модели и концов в исходных данных не найти.
У Domino крутая инфраструктурная виртуализация. Собрал машинку сколько надо ядер за секунду и поехал считать. Как сделано — не совсем понятно сразу. Везде Docker. Много свободы! Любые воркспейсы последних версий можно подключать. Параллельный запуск экспериментов. Трэкинг и отбор удачных.
То же что и DataRobot — результаты публикуются для бизнес пользователей в виде приложений. Для особо одаренных «стейкхолдеров». И еще мониторится собственно использование моделей. Все для Мопсов!
Не понял до конца как сложные модели в продакшн уходят. Какое-то API предоставляется, чтобы их накормить данными и получать результаты.
H2O
Driveless AI — очень компактная и понятная система для Supervised ML. Все в одной коробочке. Про бэкэнд не понятно до конца сразу.
Модель автоматически упаковывают в REST сервер или Java App. Это отличная идея. Многое сделано для Interpretability и Explainability. Интерпретация и объяснение результатов работы модели (Что по своей сути не должно быть объяснимо, иначе и человек может то же посчитать?).
Впервые подробно рассматривается кейс про неструктурированные данные и NLP. Качественная архитектурная картинка. И вообще картинки понравились.
Есть большой опенсорс фреймворк H2O не совсем понятно (набор алгоритмов/библиотек?). Собственный ноутбук визуальный без програмирования как Jupiter (ссылка). Еще почитал про Pojo и Mojo — модели H2O обернутые в яву. Первое в лоб, второе с оптимизацией. H20 — единственные(!), кому Gartner вписал текстовую аналитику и NLP в сильные стороны, а так же их усилия в отношении Explanability. Это очень важно!
Там же: высокая производительность, оптимизация и стандарт для отрасли в области интеграции с железами и облаками.
А в слабости логично — Driverles AI слабоват и узковат по сравнению с их же опенсорсом. Подготовка данных хромает по сравнению с той же Paxata! И игнорируют индустриальные данные — stream, graph, geo. Ну не может прямо все быть хорошо.
KNIME
Понравились 6 очень конкретных очень интересных бизнес кейсов на заглавной странице. Сильный OpenSource.
Gartner из лидеров опустил в визионеры. Плохо деньги зарабатывают — хороший знак для пользователей, учитывая что Лидер – не всегда лучший выбор.
Ключевое слово как и в H2O — augmented это значит помощь убогим citizen data scientists. Впервые кого-то в обзоре поругали за производительность! Интересно? То есть вычислительных мощностей столько, что производительность вообще не может быть системной проблемой? Про это слово “Augmented” у Gartner есть отдельная статья, до которой добраться не удалось.
И KNIME в обзоре кажется первый неамериканец! (И дизайнерам нашим очень их лэндинг понравился. Странные люди.
MathWorks
MatLаb – старый почетный товарищ известный всем! Тулбоксы для всех областей жизни и ситуаций. Что-то очень другое. Фактически много-много-много математики на все вообще случаи жизни!
Дополнительный продукт Simulink для дизайна систем. Закопался в тулбоксы для Цифровых Двойников — ничего про это не понимаю, а тут прямо много написано. Для нефтянки. В общем это принципиально другой продукт из глубин математики и инженерии. Для подбора тулкитов математики конкретной. Согласно Гартнеру у них проблемы все как у умных инженеров — никакой коллаборации — каждый в своей модели роется, никакой демократии, никакого эксплейнабилити.
RapidMiner
Много и сталкивался и слышал ранее (наряду с Матлабом) в контексте хорошего опенсорса. Закопался немного в TurboPrep как обычно. Интересует меня как из грязных данных чистые получать.
Снова видно, что люди хорошие по маркетинговым материалам 2018 года и ужасно говорящим по английски людям на feature demo.
А люди из Дортмунда с 2001 c сильным немецким прошлым)
Так и не понял из сайта что именно в опенсорсе доступно — нужно глубже закапываться. Хорошие видосики про деплоймент и AutoML их концепции.
Про бэкенд RapidMiner Server тоже ничего особого нет. Наверное это будет компактно и хорошо работать on premice out of the box. В Docker упаковывается. Шаред environment только на сервере RapidMiner. И еще есть Radoop, данные из хадупа, считалки из Spark в Studio workflow.
Подвинули их вниз как и ожидалось молодые горячие вендоры «продавцы полосатых палочек». Гартнер однако пророчит им будущий успех в Enterprise пространстве. Денег там поднять можно. Немцы это умеют свят-свят :) Don’t mention SAP!!!
Для ситизенов много делают! Но по странице видно как Gartner и говорит, что с инновационностью продаж туговато у них и они не борются за широту покрытия, но за прибыльность.
Остались SAS и Tibco типичные BI вендоры для меня… И оба в самом топе, что подтверждает мою уверенность в том, что нормальный DataScience логически растет
из BI, а не из облаков и Hadoop инфраструктур. Из бизнеса т.е., а не из IT. Как в Газпромнефть например: ссылка, зрелая DSML среда вырастает из прочной BI практики. Но может она и с душком и перекосом на MDM и прочие дела, кто знает.
SAS
Нечего сказать особо. Только очевидные вещи.
TIBCO
Стратегия читается в списке покупок на странице в Wiki длинной со страницу. Да, долгая история, но 28!!! Карл. подкупила BI Spotfire (2007) еще во времена моей техно-молодости. И еще репортинг Jaspersoft (2014), далее аж трех вендоров предиктивной аналитики Insightful (S-plus) (2008), Statistica (2017) and Alpine Data (2017), обработка событий и стриминг Streambase System (2013), MDM Orchestra Networks (2018) и Snappy Data (2019) in-memory платформа.
Привет, Фрэнки!

