 Привет, Хаброжители! Книга Site Reliability Engineering спровоцировала бурную дискуссию. Что сегодня понимается под эксплуатацией и почему столь фундаментальную важность имеют вопросы надежности? Теперь инженеры Google, участвовавшие в создании этого бестселлера, предлагают перейти от теории к практике — Site Reliability Workbook покажет, как принципы и практика SRE воплощаются в вашем продакшене Опыт специалистов Google дополнен кейсами пользователей Google Cloud Platform. Представители Evernote, The Home Depot, The New York Times и других компаний описывают свой боевой опыт, рассказывают, какие практики у них прижились, а какие — нет. Эта книга поможет адаптировать SRE к реалиям вашей собственной практики, независимо от размеров вашей компании. Вы научитесь:
Привет, Хаброжители! Книга Site Reliability Engineering спровоцировала бурную дискуссию. Что сегодня понимается под эксплуатацией и почему столь фундаментальную важность имеют вопросы надежности? Теперь инженеры Google, участвовавшие в создании этого бестселлера, предлагают перейти от теории к практике — Site Reliability Workbook покажет, как принципы и практика SRE воплощаются в вашем продакшене Опыт специалистов Google дополнен кейсами пользователей Google Cloud Platform. Представители Evernote, The Home Depot, The New York Times и других компаний описывают свой боевой опыт, рассказывают, какие практики у них прижились, а какие — нет. Эта книга поможет адаптировать SRE к реалиям вашей собственной практики, независимо от размеров вашей компании. Вы научитесь: - обеспечивать надёжность сервисов в облаках и средах, которые вы не полностью контролируете;
- применять различные методы создания, запуска и мониторинга сервисов, ориентируясь на SLO;
- трансформировать команды админов в SRE-инженеров;
- внедрять методы запуска SRE с чистого листа и на базе существующих систем. Бетси Бейер, Нейл Ричард Мёрфи, Дэвид Рензин, Кент Кавахара и Стивен Торн занимаются обеспечением надежности систем Google.
Управление системой мониторинга
Ваша система мониторинга так же важна, как и любая другая служба, которую вы используете. Поэтому к мониторингу следует относиться с должным вниманием.
Рассматривайте свою конфигурацию как код
Отношение к конфигурации системы как к коду и сохранение ее в системе контроля версий — обычная практика, дающая такие возможности, как хранение истории изменений, связи конкретных изменений с системой управления задачами, упрощенные откаты, статический анализ кода на наличие ошибок и принудительные процедуры инспекции кода.
Мы также настоятельно рекомендуем рассматривать конфигурацию мониторинга как код (подробнее о конфигурации — в главе 14). Система мониторинга, которая поддерживает настройку с использованием оформленных описаний целей и функций, предпочтительнее систем, предоставляющих только веб-интерфейсы или API в стиле CRUD (http://bit.ly/1G4WdV1). Данный подход к конфигурации является стандартным для многих бинарных файлов с открытым исходным кодом, которые только читают файл конфигурации. Некоторые сторонние решения, такие как grafanalib (http://bit.ly/2so5Wrx), поддерживают этот подход для компонентов, которые традиционно настраиваются с помощью пользовательского интерфейса.
Поощряйте согласованность
Крупным компаниям, где работают несколько проектных групп, использующих мониторинг, необходимо соблюдать тонкий баланс: с одной стороны, централизованный подход обеспечивает согласованность, но, с другой стороны, отдельные команды могут стремиться полностью контролировать то, как устроена их конфигурация.
Правильное решение зависит от типа вашей организации. Со временем подход Google эволюционировал в направлении сведения всех наработок в единой платформе, работающей в виде централизованного сервиса. Это хорошее для нас решение, и для этого есть несколько причин. Единая инфраструктура позволяет инженерам быстрее и проще переходить из одной команды в другую и облегчает совместную работу во время отладки. Кроме того, есть централизованный сервис по выводу информации (dashboarding service), где панели мониторинга каждой команды открыты и доступны. Если вы хорошо понимаете информацию, предоставленную другой командой, то можете быстрее исправить как свои проблемы, так и проблемы других команд.
По возможности сделайте покрытие базовым мониторингом как можно более простым. Если все ваши сервисы экспортируют согласованный набор базовых показателей, вы можете автоматически собирать эти показатели по всей организации и предоставлять согласованный набор панелей мониторинга. Этот подход означает, что для любого нового компонента, который вы запускаете автоматически, предусмотрен базовый мониторинг. Таким образом, многие команды в вашей компании — даже не инженерные — смогут использовать данные мониторинга.
Предпочтите слабые связи
Бизнес-требования меняются, и ваша производственная система через год будет выглядеть иначе. Точно так же, как и контролируемые вами сервисы, ваша система мониторинга с течением времени должна развиваться и эволюционировать, проходя через различные типовые проблемы.
Мы рекомендуем, чтобы связи (coupling) между компонентами вашей системы контроля были не очень сильными. У вас должны быть надежные интерфейсы для настройки каждого компонента и передачи данных мониторинга. Отвечать за сбор, хранение, оповещение и визуализацию ваших данных мониторинга должны разные компоненты. Стабильные интерфейсы облегчают замену любого конкретного компонента наиболее подходящей альтернативой.
В мире открытого кода разделение функциональности на отдельные компоненты становится популярным. Десять лет назад системы мониторинга, такие как Zabbix (https://www.zabbix.com/), объединяли все функции в один компонент. Современное проектирование обычно предполагает разделение сбора и выполнения правил (с помощью таких решений, как, например, сервер Prometheus (https://prometheus.io/)), хранения долгосрочных временных рядов (InfluxDB, www.influxdata.com), агрегирования предупреждений (Alertmanager, bit.ly/2soB22b) и создания панелей мониторинга (Grafana, grafana.com).
На момент написания этой книги существует как минимум два популярных открытых стандарта, позволяющих оснащать программное обеспечение необходимыми инструментами и предоставлять метрики:
- statsd — демон сбора метрик, изначально написанный Etsy, теперь перенесен на большинство языков программирования;
- Prometheus — решение для мониторинга с открытым исходным кодом с гибкой моделью данных, поддержкой меток для метрик и весьма качественно реализованной функциональностью гистограмм. Другие системы тепе��ь постепенно перенимают формат Prometheus и стандартизируются как OpenMetrics (https://openmetrics.io/).
Отдельная система информационных панелей, использующая несколько источников данных, обеспечивает централизованный и унифицированный обзор вашего сервиса. Компания Google недавно ощутила это преимущество на практике: наша устаревшая система мониторинга (Borgmon1) объединяла информационные панели в той же конфигурации, что и правила оповещения. При переходе на новую систему (Monarch, youtu.be/LlvJdK1xsl4) мы решили перенести информационные панели в отдельный сервис (Viceroy, bit.ly/2sqRwad). Viceroy не был компонентом Borgmon или Monarch, поэтому у Monarch было меньше функциональных требований. Поскольку пользователи могут задействовать Viceroy для отображения графиков, основанных на данных из обеих систем мониторинга, они смогли постепенно перейти с Borgmon на Monarch.
Осмысленные метрики
В главе 5 рассказывается о том, как с помощью показателей уровня качества обслуживания (SLI) отслеживать угрозы бюджету ошибок и оповещать об их возникновении. Метрики SLI — это первые метрики, которые стоит проверять при срабатывании оповещений, основанных на целевых показателях уровня качества обслуживания (SLO). Эти метрики должны отображаться на информационной панели вашего сервиса, в идеале — на его первой странице.
При расследовании причин нарушения SLO вы, скорее всего, не получите достаточно информации от панелей SLO. Эти панели показывают, что нарушения есть, но о причинах, приведших к ним, вы вряд ли узнаете. Какие еще данные следует отобразить на панели мониторинга?
Мы считаем, что при внедрении метрик будут полезны следующие рекомендации: эти показатели должны обеспечивать разумный мониторинг, который позволяет вам исследовать производственные проблемы, а также предоставлять широкий спектр информации о ваших сервисах.
Преднамеренные изменения
При диагностике оповещений, связанных с SLO, необходимо иметь возможность перейти от метрик оповещений, которые уведомляют вас о проблемах, влияющих на пользователей, к метрикам, оповещающим вас о причинах этих проблем. Такими причинами могут быть недавние преднамеренные изменения вашего сервиса. Добавьте мониторинг, который информирует вас о любых изменениях в производстве. Для обнаружения факта внесения изменений мы рекомендуем следующее:
- мониторинг версии бинарного файла;
- мониторинг флагов командной строки, особенно когда вы используете эти флаги для включения и отключения функций сервиса;
- если данные конфигурации передаются в сервис динамически, мониторинг версии этой динамической конфигурации.
Если для какого-либо из этих компонентов системы контроля версий нет, вам необходимо отслеживать, когда была выполнена последняя сборка или упаковка данного компонента.
Когда вы пытаетесь соотнести возникающие проблемы сервиса с развертыванием, гораздо проще взглянуть на какую-либо диаграмму или панель, на которую есть ссылка в оповещении, чем перелистывать журналы CI/CD постфактум.
Зависимости
Даже если ваш сервис не изменился, может измениться любая из его зависимостей. Поэтому вам также необходимо отслеживать ответы, поступающие от прямых зависимостей.
Разумно экспортировать размер запроса и ответа в байтах, время отклика и коды ответа для каждой зависимости. При выборе метрики для графика помните об этих четырех золотых сигналах (см. раздел «Четыре золотых сигнала» главы 6 книги Site Reliability Engineering).
Можно использовать в метриках дополнительные метки, чтобы разделить их по коду ответа, имени метода RPC (удаленного вызова процедур) и имени вызываемого сервиса.
В идеале вместо того, чтобы просить каждую клиентскую библиотеку RPC экспортировать такие метки, можно с этой целью единожды оснастить необходимыми инструментами клиентскую библиотеку RPC более низкого уровня. Это обеспечивает большую согласованность и позволяет без дополнительных усилий организовать мониторинг новых зависимостей.
Встречаются зависимости, предлагающие очень ограниченный API, где вся функциональность доступна через один RPC-метод, называющийся Get, Query или столь же неинформативно, а фактическая команда указывается в качестве аргументов этого метода. Подход с единой точкой доступа к инструментам в клиентской библиотеке не работает при таком типе зависимости: вы будете наблюдать большую вариативность в задержке и некий процент ошибок, который может как указывать, так и не указывать на то, что какая-то часть этого «мутного» API полностью «отвалилась». Если эта зависимость является критической, хороший мониторинг для нее можно реализовать следующими способами.
- Экспортируйте отдельные метрики, разработанные специально для этой зависимости, где для получения действительного сигнала будет выполняться распаковка полученных запросов.
- Попросите владельцев зависимости переписать ее так, чтобы экспортировался расширенный API, поддерживающий разделение функций между отдельными сервисами и методами RPC.
Уровень загруженности
Желательно контролировать и отслеживать использование всех ресурсов, с помощью которых работает сервис. У некоторых ресурсов есть жесткие ограничения, которые вы не можете превысить. Например, выделенный для вашего приложения размер ОЗУ, жесткого диска или квота на ЦП. Другие ресурсы, такие как дескрипторы открытых файлов, активные потоки в любых пулах потоков, время ожидания в очередях или объем записанных журналов, могут не иметь четкого жесткого ограничения, но все же требуют управления.
В зависимости от используемого языка программирования вам нужно отслеживать некоторые дополнительные ресурсы:
- в Java — размер кучи и метапространства (http://bit.ly/2J9g3Ha), а также более конкретные показатели в зависимости от используемого типа сборки мусора;
- в Go — количество горутин.
Сами языки программирования предоставляют различную поддержку для отслеживания этих ресурсов.
В дополнение к оповещению о значительных событиях, как описано в главе 5, вам также может понадобиться настроить оповещения, которые срабатывают при приближении к критическому истощению определенных ресурсов. Это полезно, например, в следующих ситуациях:
- когда у ресурса имеется жесткий лимит;
- когда при превышении порога использования происходит снижение производительности.
Мониторинг необходим для всех ресурсов, даже для тех, которыми сервис хорошо управляет. Эти метрики жизненно важны при планировании ресурсов и возможностей.
Состояние выдаваемого трафика
Рекомендуется добавить на панели мониторинга метрики или метрические метки, которые позволят разбить выдаваемый трафик по коду состояния (если метрики, используемые вашим сервисом для целей SLI, не содержат эту информацию). Вот некоторые рекомендации.
- Следите за всеми кодами ответов для HTTP-трафика, учитывая даже те, которые из-за возможного некорректного поведения клиента не являются поводом для выдачи оповещений.
- Если вы применяете к своим пользователям ограничения количества запросов в единицу времени или квоты, следите за количеством запросов, отклоненных из-за отсутствия квоты.
Графики этих данных могут вам помочь определить, когда во время производственного изменения заметно меняется объем ошибок.
Реализация целевых метрик
Каждая метрика должна служить своей цели. Не поддавайтесь искушению экспортировать несколько метрик только потому, что их легко сгенерировать. Вместо этого подумайте, как они будут использоваться. Архитектура метрик (или ее отсутствие) имеет последствия. В идеале значения метрик, используемые для оповещения, резко изменяются только при возникновении в системе пробл��м, а при обычной работе они остаются неизменными. С другой стороны, к отладочным метрикам эти требования не предъявляются — они должны дать представление о том, что происходит при срабатывании оповещения. Хорошие отладочные метрики укажут на потенциально проблемные части системы. Когда вы пишете постмортем, подумайте, какие дополнительные метрики позволили бы вам быстрее диагностировать проблему.
Тестирование логики оповещения
В идеальном мире код мониторинга и оповещений должен соответствовать тем же стандартам тестирования, что и код разработки. В настоящее время не существует широко распространенной системы, которая позволяла бы вам реализовать такую концепцию. Одной из первых ласточек является недавно добавленная в Prometheus функциональность юнит-тестирования правил.
В Google мы тестируем наши системы мониторинга и оповещений, используя язык, специфичный для домена, который позволяет нам создавать синтетические временные ряды. Затем мы либо проверяем значения в производном временном ряду, либо уточняем, сработало ли определенное оповещение и присутствует ли у него требуемая метка.
Мониторинг и выдача оповещений часто являются многоступенчатыми процессами, поэтому требуется несколько семейств юнит-тестов.
Несмотря на то что эта область остается в значительной степени недостаточно развитой, если вы в какой-то момент пожелаете внедрить тестирование мониторинга, рекомендуем трехуровневый подход, как показано на рис. 4.1.
- Бинарные файлы. Убедитесь, что у экспортируемых метрических переменных, как и ожидалось, при определенных условиях меняются значения.
- Инфраструктура мониторинга. Убедитесь, что исполнение правил дает ожидаемые результаты, а конкретные условия — ожидаемые оповещения.
- Диспетчер оповещений. Проверьте, что сгенерированные оповещения направляются в заранее определенное на основе значений меток место назначения.
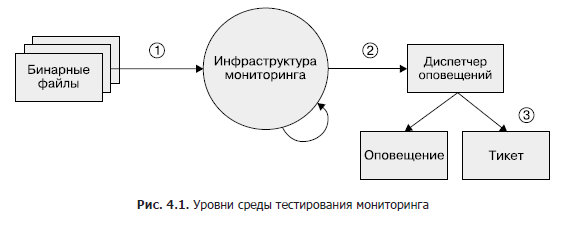
Если вы не можете протестировать свою систему мониторинга с помощью синтетизированных средств или некий этап не поддается тестированию вообще, рассмотрите возможность создания рабочей системы, которая экспортирует известные метрики, такие как количество запросов и ошибок. Вы можете использовать эту систему для проверки временных рядов и оповещений. Вполне вероятно, что ваши правила предупреждений после их настройки в течение нескольких месяцев или лет не сработают, и вы должны быть уверены, что, когда показатель превысит определенный порог, оповещения останутся осмысленными и будут доставлены тем инженерам, которым они предназначены.
Итоги главы
Поскольку SR-инженеры должны отвечать за надежность производственных систем, от этих специалистов часто требуется глубокое понимание системы мониторинга и ее функций и тесное взаимодействие с ней. Без этих данных SRE могут не знать, где искать и как определить ненормальное поведение системы или как найти информацию, которая им нужна во время чрезвычайной ситуации.
Мы надеемся, что, указав на полезные, с нашей точки зрения, функции системы мониторинга и обосновав наш выбор, сможем помочь вам оценить, насколько ваша система контроля соответствует вашим потребностям. Кроме того, мы поможем изучить некоторые дополнительные функции, которые вы можете использовать, и рассмотреть изменения, которые вы, вероятно, захотите внести. Скорее всего, вам в своей стратегии мониторинга будет полезно объединить источники метрик и журналов. Правильное соотношение метрик и журналов сильно зависит от контекста.
Обязательно соберите метрики, которые служат конкретной цели. Это такие цели, как, например, улучшение планирования пропускной способности, отладка или выдача сообщений о возникающих проблемах.
Когда у вас появится мониторинг, он должен быть визуализируем и полезен. Для этого мы рекомендуем протестировать его настройки. Хорошая система мониторинга приносит дивиденды. Основательное предварительное планирование того, какие решения использовать, чтобы наилучшим образом охватить специфичные для вас требования, равно как и постоянные итеративные улучшения системы мониторинга, — это та инвестиция, которая с лихвой окупится.
» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 25% по купону — Google
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.

