Комментарии 85
И подобрав особую последовательность, сможем убирая один байтик вначале вкорне изменить интерпретацию последующих символов. Не?
Да, это верно как для SCSU, так и для моей UTF-C.
Но в моей задаче (и кажется, во многих практических задачах тоже) такая проблема не может возникнуть, так что у меня не стояло цели её решать. Цель была только в компактности.
P.S: Автору UTF-C — мегареспект! :)
Вот только протоколы передачи данных откусить биты не могут, байты могут легко, а о ваших символах вообще представления не имеют.
Думается, если есть такие опасения, то задачу сохранения целостности на протоколы передачи данных и стоит возложить. В любом случае, мне сложно представить ситуацию, когда с покусанной таким образом строкой клиент сможет сделать что-то осмысленное — независимо от того, по границе символа её обкусали или нет.
(Да и не для того это делалось же, чтобы эти строчки куда-то в сеть передавать)
(Да и не для того это делалось же, чтобы эти строчки куда-то в сеть передавать)
Просто буква T в названии UTF-C вводит в заблуждение.
Ну вот вам задача. Многогигабайтный текстовый документ. Пользователь тыкает в скроллбар.
Задача просмотрщика текста: Переместиться примерно в примерно нужное место файла, найти ближайший символ, попробовать найти после (или до) него ближайший перенос строки, начать рендеринг оттуда.
Учитывая, что большинство строк имеет смысл хранить именно как строки (причём immutable), а не как буфер с байтами – не великая проблема.
Из минусов — при хранении в БД приходится решать вопрос поиска по БД слов с этими entities.
Из плюсов — ощутимое изменение размера БД и производительности.
В свое время меряли объемы и скорость — habr.com/en/post/116822 — соотношения до сих пор актуальны, на sphinx и прочих БД так же сохраняются. Хотя казалось бы создатели БД могли бы уже озаботится вопросом более компактного внутреннего хранения utf-8 и работы с ним.
Видимо, под «обычным текстом» подразумевается текст преимущественно на каком-то одном языке, чтобы под него можно было выбрать удобную однобайтовую кодировку?)
Мне вот хотелось уметь хорошо хранить строчки, язык которых заранее неизвестен.
Кстати, Википедия говорит, что вот SQL Server 2008 R2 как раз SCSU внутри себя использует, чтобы компактно строчки хранить.
Видимо, под «обычным текстом» подразумевается текст преимущественно на каком-то одном языке, чтобы под него можно было выбрать удобную однобайтовую кодировку?)В целом да, но чуть шире.
windows-1252 позволяет охватить практически все европейские языки.
windows-1251 закрывает почти все кириллические языки.
Мне вот хотелось уметь хорошо хранить строчки, язык которых заранее неизвестен.Если их немного, то как вариант можно хранить пометку «исключение» с хранением исходного текста в дополнительной таблице, при этом в основной хранить приведенный текст.
Тогда и поиск нормально получается и исходный текст присутствует. Такой подход может оправдывать себя если текстов в не основных кодировках не больше примерно 20%.
p.s.: Но вообще да, в современных реалиях нередко проще задавить этот вопрос сервером подороже:)
Если их немного, то как вариант можно хранить пометку «исключение» с хранением исходного текста в дополнительной таблице, при этом в основной хранить приведенный текст.Мне кажется, мы с вами всё-таки немного про разные категории задач говорим. Вы больше про конкретный продукт, который кладёт тексты в какую-то базу, а я писал движок, который сам по себе «база данных» в некотором смысле, и у него нет знаний об используемом языке. И когда нужно что-то искать в массиве пожатых строк, это достаточно недорого делается вызовом функции декодирования для каждой.
И при этом нам не вполне понятно, чем Ваш подход лучше gzencode, т.к. Вам всё равно придется раскодировать строку перед работой с ней или перед выдачей ее юзеру, а gzencode на более или менее длинных текстах ужимает больше чем в 2 раза. При этом если Вам надо держать в памяти миллион коротких строк по 10 символов — почему бы не заменить это на 10 тысяч строк по 1000 символов, по принципу зип архива — если уж на то пошло?
Мы же исходим из того, что хотя в целом тексты могут быть на разных языках, но в одной единице информации как правило один язык, поэтому гибкостью можно пожертвовать и указывать кодировку для всей единицы информации, кодируя исключения в entities. В обмен получаем использование стандартной общепризнанной кодировки с которой умеет работать «код с улицы», облегчается поиск и вообще всё.
Но обмен Вы отдали даже шанс на понимание Вашей кодировки чем-то, что с ней не знакомо и работает только с привычными стандартами.
Как я уже писал, речь про использование этой кодировки в своём коде. Всё взаимодействие с ней обёрнуто в функции Encode/Decode, которые на выходе/входе дают массив байт. Если нужно что-то с содержимым сделать — декодируем (обычно это нужно только в момент ввода или вывода), а если передать чему-то стороннему (или сбросить на диск, например) — передаём просто как байты.
При этом если Вам надо держать в памяти миллион коротких строк по 10 символов — почему бы не заменить это на 10 тысяч строк по 1000 символов, по принципу зип архива — если уж на то пошло?Но «держать миллион строк по 10 символов» это же вводная, как её можно поменять на другую? :) Вот представьте, у нас смешанный словарь, содержащий слова разных языков мира. Или, например, список заголовков статей всех Википедий. Как вы их склеите так, чтобы иметь доступ за O(1) к каждому заголовку по его индексу?
Но «держать миллион строк по 10 символов» это же вводная, как её можно поменять на другую? :)Это не вводная, это решение задачи хранения миллиона строк по 10 символов:)
Вот представьте, у нас смешанный словарь, содержащий слова разных языков мира. Или, например, список заголовков статей всех Википедий. Как вы их склеите так, чтобы иметь доступ за O(1) к каждому заголовку по его индексу?Так мы же написали — «по принципу зип архива». Вам же не надо разахривировать весь архив, что бы вытащить один файл по его имени? А словарь общий, поэтому оверхеда на каждую конкретную строчку нет, только общий оверхед.
Если говорить применительно к БД (дада, мы помним что у Вас свой софт:)), то в innodb есть compressed формат — правда его техническую реализацию не помним, но если опять же это вариант с общим словарем — то даже придумывать ничего не надо.
В конце концов можно сделать виртуальный сжатый диск и кинуть базу (в любом виде) тупо на него.
Ну ладно, допустим, затраты на расшифровку строки из 100 слов вместо расшифровки одного слова, и затраты на последовательный поиск одного слова из ста не так уж велики по сравнению с поиском нужной строки в дереве, если словарь очень большой. Но возникает ещё другая проблема: если добавляются новые слова, то куда вставлять их в дерево? Отдельным узлом? Или всё таки внутрь строки к другим 100 словам? И то же самое при изменении слов, когда они должны перейти на новое место. В первом случае (если новые слова добавляются отдельными узлами) при частых изменениях скопится больше коротких строк, чем длинных, и эффективность алгоритма сжатия быстро упадёт. А во втором случае (при добавлении новых слов к существующим) при частых изменениях будут скапливаться очень длинные строки, что будет увеличивать время последовательного поиска в них (и время на вставку тоже возрастёт). Можно, конечно, при достижении определённого размера делить строку на две (например, при добавлении 150-го по счёту слова делить строку на две по 75 слов). Но в целом это всё выглядит как более сложное и нагромождённое решение, чем предлагаемое автором статьи, и в любом случае менее эффективное по времени работы. А преимуществ не даёт никаких, кроме «понимания кодировки чем-то, что с ней не знакомо», что в данной задаче про хранение словаря вообще не требуется.
И когда нужно что-то искать в массиве пожатых строк, это достаточно недорого делается вызовом функции декодирования для каждой.
И это третий существенный недостаток по сравнению с UTF-8, кроме уже упомянутых ASCII-непрозрачности и неопределимых границ символов.
Обо всех этих недостатках я упомянул в теле статьи, о преимуществах тоже. Их существенность зависит от контекста: очевидно, что в одних классах задач встают одни требования, в других — другие. Поэтому в одном случае эффективнее одно решение, а в другом — другое.
Отдельно замечу, что во многих ситуациях UTF-8 точно так же требует кодирования/декодирования, как и мой подход. Но в отличие от, например, алгоритмов сжатия (у которых тоже своя область применимости) тут довольно простая логика, это не так затратно.
Обо всех этих недостатках я упомянул в теле статьи, о преимуществах тоже.
Если и так, то поиск был упомянут где-то в самом начале, и к концу статьи уже забылся :)
Не хватает именно что подведения итогов: «преимущества моей кодировки — а, б и в; недостатки — х, у и з.»
Отдельно замечу, что во многих ситуациях UTF-8 точно так же требует кодирования/декодирования, как и мой подход.
В каких именно? (Это тоже стоило упомянуть в статье.)
Дисклеймер. Сразу сделаю несколько важных оговорок: описанное решение не предлагается как универсальная замена UTF-8, оно подходит только в узком списке случаев (о них ниже)
А можете добавить ещё и вторую половину итога — «кейсы, в которых использовать UTF-C стоит»?
Если же нужны приведение регистров и «естественная сортировка», то неизбежно придётся привязываться к какому-то конкретному языку — и в этом случае 8-битная кодировка обеспечит ещё большее удобство.
Смысл разработки в экономии места в случаях, когда алгоритмы сжатия общего назначения неэффективны. Например, если вам нужно держать миллион коротких (10-20 символов) строк в памяти. В таких случаях алгоритмы вроде deflate дадут больше оверхеда, чем пользы.
что закодированная с помощью UTF-C строка не обеспечивает ASCII transparencyНу тогда попробуйте провести сравнение ваших результатов с результатами полученными алгоритмами сжатия, для более-менее длинных текстов. Можно даже и для коротких, если мы предположим что у нас есть универсальные словари комперссии для специфичных языков.
Использование правильной кодировки упрощает некоторые алгоритмы, например сортировку. В вашем случае получается что надо перекодировать всё и потом сортировать, либо налету туда-сюда гонять.
Ну тогда попробуйте провести сравнение ваших результатов с результатами полученными алгоритмами сжатия, для более-менее длинных текстов. Можно даже и для коротких, если мы предположим что у нас есть универсальные словари комперссии для специфичных языков.
Но зачем? Основная область применения UTF-C — именно короткие тексты, когда алгоритмы сжатия не работают.
Но зачем? Основная область применения UTF-C — именно короткие текстыЯ с вашего демо взял пример, у вас там сравнение 674 байт против 379 байт в вашей кодировке. Я просто gzip попробовал, получилось 315 байт, т.е. выгоднее.
ASCII transparency это основное преимущество, если его нету то пусть будет просто компрессия, она сможет на типичных данных в разы преимущество давать.
Если будут универсальные словари для языков, то по идее можно ими пользоваться, т.е. не тянуть с собой конкретный словарь, а просто давать ссылку на словарь в нашей библиотеке, типа первый байт это ссылка на словарь. Конечно потеряется эффективность, но для типичных случаев, не на сильно много.
Опять же, можно попробовать как данные в вашем формате жмутся, тоже интересно.
Я с вашего демо взял пример, у вас там сравнение 674 байт против 379 байт в вашей кодировкеТам всё-таки достаточно длинные примеры, просто для наглядности. На строках длиной менее ~100 символов gzip начинает давать текст даже длиннее, чем UTF-8 (и не забываем ещё про тот факт, что процесс сжатия всё-таки более затратный, чем кодирование — которое делается в один проход, с небольшим числом операций на каждый символ).
Но вы правы, возможно будет ещё интересно для понимания сделать, например, графики, где будет видно, на каких объемах какой подход работает лучше.
ASCII transparency это основное преимущество, если его нету то пусть будет просто компрессия, она сможет на типичных данных в разы преимущество давать.Да, в каких-то областях применений это разумеется так. Но, например, когда речь про то, чтобы держать массив строк в памяти своего приложения ASCII transparency не требуется (хорошая компрессия требуется, но, повторюсь, надо смотреть на типичную длину строк).
и не забываем ещё про тот факт, что процесс сжатия всё-таки более затратный, чем кодирование
Есть вещи типа github.com/google/snappy
Просто базируясь на вашем названнии (UTF-C), я преполагаю что вы хотели бы предложить это в качестве стандарта в каком-то виде. Для этого как раз неудобные вопросы очень помогают, может переосмыслив некоторые вводные, вам удасться сделать удачный формат который может не выжмет последний байт эффективности, но решит проблемы про которые вас спрашивают в комментариях.
Есть вещи типа github.com/google/snappy
For instance, compared to the fastest mode of zlib, Snappy is an order of magnitude faster for most inputs, but the resulting compressed files are anywhere from 20% to 100% bigger.Ну то есть тоже trade-off какой-то присутствует. Тоже было бы любопытно сравнить (я не утверждаю, что любое сжатие медленнее кодирования на нескольких ифах, но кажется, что второе заоптимизировать можно гораздо лучше, чем первое).
Просто базируясь на вашем названнии (UTF-C), я преполагаю что вы хотели бы предложить это в качестве стандарта в каком-то виде.Ни в коем случае! Название это просто отсылка к UTF-8, на котором я построил свой подход (ну и мне показалась забавной созвучность USB-C, если честно :)
Напротив: я написал код (и статью) так, чтобы его можно было не только импортировать в свой проект по надобности, а скопировать и поменять под свои нужды. Я об этом говорю в разделе «Возможные доработки»: я считаю, что когда речь идёт о внутренних частях своего проекта, то иногда полезно не только стремиться к стандартизации (помним картинку про competing standards от xkcd), но и к кастомизации под конкретную задачу.
Но вы правы, возможно будет ещё интересно для понимания сделать, например, графики, где будет видно, на каких объемах какой подход работает лучше.
Как-то так:
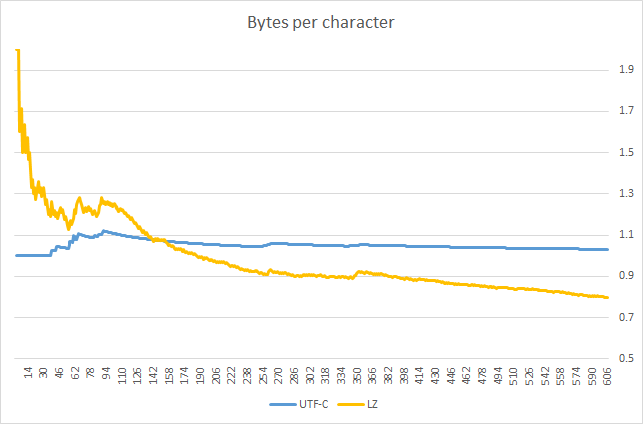
Для сравнения использованы pieroxy.net/blog/pages/lz-string/index.html и
The predominant form in Classical Greek was Týros (Τύρος), which was first seen in the works of Herodotus but may have been adopted considerably earlier. It gave rise to Latin Tyrus, which entered English during the Middle English period as Tyre. The demonym for Tyre is Tyrian, and the inhabitants are Tyrians.
У вас была неправильная предпосылка («короткие тексты не сжимаются») и на основании её вы сделали неправильный вывод.
Для меня, повторюсь, вариант тащить полноценную либу, осваивать её апи, готовить для неё какие-то данные (в надежде, что они будут репрезентативными для любого будущего датасета), и потом потенциально страдать от недостаточной производительности — не ощущался проще, чем написать две функции на 100 строчек кода. И что самое важное, это точно не ощущалось интереснее :)
В то же время я совершенно не спорю, что кому-то другому может показаться иначе (и это нормально). Хорошо же, что у нас всех есть свобода выбирать, какими решениями пользоваться, и какие велосипеды писать :)
В данной задаче могло бы помочь создание специализированных fixed huffman codes для каждого языка, и переключение между ними (стандартный блок deflate compression with fixed huffman codes, скорее всего, не будет самым эффективным), но это решение в любом случае будет сложнее, чем приведенное автором.
Использование правильной кодировки упрощает некоторые алгоритмы, например сортировку. В вашем случае получается что надо перекодировать всё и потом сортировать, либо налету туда-сюда гонять.
И это четвёртый существенный недостаток UTF-C по сравнению с UTF-8.
Не только сортировать, но и проверять равенство строк невозможно без перекодировки.
Отмечу, что поскольку одна и та же строка кодируется одним и тем же способом, точное сравнение вполне допустимо делать побайтово, без декодирования. А для сравнения при сортировки сложность декодирования сравнима со сложностью декодирования UTF-8 (принципы у них одинаковые).
Честно говоря, у меня складывается ощущение, что вы хотите просто сказать, что я сделал плохую и бесполезную (по вашему мнению) вещь. Для меня это несколько неприятно, но я готов принять и такое мнение.
Извините, но кажется отмеченный вами четвёртый недостаток полностью совпадает с третьим :)
Не соглашусь: поиск затруднён тем, что вхождение подстроки байт не гарантирует вхождение подстроки символов. Со сравнением строк это не связано.
Отмечу, что поскольку одна и та же строка кодируется одним и тем же способом, точное сравнение вполне допустимо делать побайтово, без декодирования.
Если так, тогда конкатенация строк требует перекодировки.
А для сравнения при сортировки сложность декодирования сравнима со сложностью декодирования UTF-8 (принципы у них одинаковые).
Строки в UTF-8 можно сортировать без декодирования, в этом и фишка.
Не соглашусь: поиск затруднён тем, что вхождение подстроки байт не гарантирует вхождение подстроки символов. Со сравнением строк это не связано.
Когда вы отмечали третий недостаток, вы цитировали моё сообщение:
И когда нужно что-то искать в массиве пожатых строк, это достаточно недорого делается вызовом функции декодирования для каждой.
Наверное, я неточно сформулировал ту фразу, но речь там шла не про подстроки, а именно про бинпоиск нужной строки (что требует таких же сравнений, как при сортировке).
Если так, тогда конкатенация строк требует перекодировки.Да, это так. Все мутирующие операции тут требуют декодирования.
Строки в UTF-8 можно сортировать без декодирования, в этом и фишка.Скажем так, это спорный момент.
Сортировать без декодирования так-то можно что угодно (и тем же бинпоиском искать потом). Сортировка прямо в UTF-8 гарантирует только то, что строки будут посортированы по порядковым кодам символов, а это неидеально: например, хорошо бы, чтобы сравнение шло без учёта регистра (чтобы буквы, отличающиеся только регистром, стояли рядом, а в Юникоде это почти никогда не так). Западноевропейские символы из Latin-1 Supplement и вовсе оторваны от родственных им аналогов без диакритики (как и русская «ё» от «е»). Так что если цель сортировать естественным образом, то декодировать нужно в любом случае, а потом применять Unicode collation algorithm.
Наверное, я неточно сформулировал ту фразу, но речь там шла не про подстроки, а именно про бинпоиск нужной строки (что требует таких же сравнений, как при сортировке).
Да, у выражения «поиск в строках» два разных значения, но оба они требуют перекодировки :-)
чтобы буквы, отличающиеся только регистром, стояли рядом
Канонический пример: i и I должны сортироваться как одна буква или как разные?
У тюрков на этот счёт иное мнение, чем у других народов.
Так что если цель сортировать естественным образом
То нужно знать конкретный язык текста: например, в польском словаре chata идёт перед cukry, а в чешском — наоборот. В немецком словаре Öl идёт перед Sand, а в шведском — наоборот. Если же в массиве строк есть и чешские, и польские, и немецкие, и шведские, (а то ещё и турецкие,) то «естественный порядок» не определён, и единственный порядок, имеющий смысл при сортировке такого массива — это порядок по codepoints, что UTF-8 и обеспечивает.
То нужно знать конкретный язык текстаДа, неплохо бы это делать с учётом языка, не спорю (и никто не мешает дополнительно и эту информацию хранить и использовать при сортировке, как это делается в MySQL, к примеру).
Но ещё я отмечу, что Юникод всё-таки определяет и некий базовый порядок сортировки символов (DUCET) и даже без уточнения под конкретный язык он даст более адекватную в большинстве случаев сортировку, нежели предлагаемую вами сортировку по кодовым точкам.
Главный мой поинт остаётся в силе — если мы хотим естественный порядок, нам нужно декодировать строки (да, хорошо бы при этом знать язык).
Если же в массиве строк есть и чешские, и польские, и немецкие, и шведские, (а то ещё и турецкие,) то «естественный порядок» не определён, и единственный порядок, имеющий смысл при сортировке такого массива — это порядок по codepoints, что UTF-8 и обеспечивает.Окей, я понял, что ваша цель не в естественном порядке. Но тогда я вообще не очень понимаю, что вы называете смыслом данного порядка, какая практическая задача этим решается?
Вот цитата непосредственно из документа Unicode Collation Algorithm:
The basic principle to remember is: The position of characters in the Unicode code charts does not specify their sort order.
Так что мне кажется, сортировка по кодовым точкам не особо лучше любой другой детерменированной сортировки (как, например, по байтам в закодированном виде).
Так что мне кажется, сортировка по кодовым точкам не особо лучше любой другой детерменированной сортировки (как, например, по байтам в закодированном виде).
Для обработки внутри приложения — наверное да.
При работе со внешними данными — удобно, когда я и вторая сторона используем один и тот же порядок сортировки, независимо от того, какой UTF с каждой стороны.
Так что поздравляю вас с изобретением велосипеда )
Так что поздравляю вас с изобретением велосипеда )Спасибо, я старался!
Если текст не состоит из чередующихся символов разных алфавитов, то выигрыш будет практически на уровне старых однобайтных кодировок.
Почти в любом тексте очень часто встречаются пунктуация, пробелы и переводы строк из диапазона U+00xx.
У вас терминал текст RTL-языках отображает слева направо — и с ивритом такое, и с арабским.
Например, арабский текст должен отображаться как الأخبار — тут в отличие от терминала видно, что буквы имеют не только другое направление, но и другой вид (зависит от положения буквы в слове), и лигатуру лям-алиф (похожа на букву ꙋ)

Впрочем, в моём GNOME Terminal — та же фигня.
Если строчка содержит текст на одном из современных языков (включая китайский), за пределы этой плоскости вы не выйдете.
Выйду же: en.wikipedia.org/wiki/CJK_Unified_Ideographs
20989 символов в BMP, и ещё 71867 вне неё.
Так же как, например, у кириллицы есть несколько дополнительных блоков кроме 0x0400 —0x04FF, но на практике мы с ними практически не сталкиваемся.
8бит всем хватает на кодировку и всегда хватало, там где это нужно — переключайте кодировки.
Это самый эффективный способ сэкономить на байтах. Других нет.
п.с.: Юникод нужен, но он нужен там, где он нужен. В 99% случаев он не нужен вообще. По сути, юникод — это избыточный крутой фреймворк, однако же подавляюще часто вы пользуетесь им на 1%, не более, а тогда зачем он вам?
Как минимум, Юникод хорош тем, что это один общий стандарт, который сейчас уже более-менее всё поддерживает. Если вам нужно обозначить какой-то символ — в юникоде точно найдётся его код.
В свою очередь, если делается продукт, который должен работать с текстами на произвольных языках (да пусть даже чтобы попросту нормальную пунктуацию вроде тире использовать), то куда лучше сразу обеспечить их поддержку, чем придумывать какие-то механизмы переключения кодировок.
Ей-богу, риторика в духе «8 бит хватит всем» мне кажется очень странной.
8бит всем хватает на кодировку и всегда хватало,
Восточноазиатам — не хватает и никогда не хватало. Сколько их, четверть населения планеты?
там где это нужно — переключайте кодировки.
Забыли те времена, когда емейл на русском ходил в четырёх разных кодировках, и для просмотра каждого письма приходилось её переключать?
Гуглеж "short string compression" выдает довольно много проектов, и даже научных статей. Сравнивали с чем-нибудь из этого?
Ваша реализация находится где-то посередине между хранением и обработкой. Она будет не так компактна, как алгоритмы сжатия, и не так приспособлена к обработке текста, как UTF-8, UTF-16, либо национальные ANSI-кодировки (при работе с конкретным языком). Пожалуй, в той конкретной задаче, в которой вы её применяете, она даёт лучший результат.
Когда мне приходилось обрабатывать тексты на современных славянских языках, при этом требовался быстрый поиск по подстрокам, вырезания/слияния, индексный поиск по отдельным символам, разбиение на предложения и слова и т.п., я просто взял Windows 1251 и в символы ниже кода 32 внедрил недостающие буквы из польского и чешского алфавитов. Получилось очень компактное представление, удовлетворяющее всем вышеуказанным требованиям.
Для обработки (как в вашем случае)Не могу сказать, что в моём случае это так. Как раз-таки содержимое строк мне трогать не нужно (не требуются никакие изменения строк, поиск подстрок и тому подобное), они абсолютно статичны.
Кажется, это всё-таки чистая задача хранения строк, но при условии их малой длины (что мешает использовать алгоритмы сжатия).
Кириллице и ещё пяти алфавитам — ура — повезло, 2 байта на символ.
Какие еще 5 алфавитов составляют компанию Кириллице в числе везунчиков?
Greek and Coptic (0370–03FF)
Cyrillic (0400–04FF)
Cyrillic Supplement (0500–052F)
Armenian (0530–058F)
Hebrew (0590–05FF)
Arabic (0600–06FF)
Syriac (0700–074F)
Arabic Supplement (0750–077F)
Thaana (0780–07BF)
N'Ko (07C0–07FF)
Например, первый байт в UTF-8 всегда начинается либо с 0, либо с 11 — а префикс 10 есть только у следующих байт. Заменим префикс 11 на 1, а у следующих байт уберём префиксы совсем. Что получится?
А получится снижение устойчивости кода к ошибкам. Применяемая в UTF-8 система префиксов при потере/искажении любого байта приводит к потере/искажению только одного символа. Кроме того, UTF-8 «заточен» на потоковую передачу текста. Прием можно начинать с любого байта — декодер сам определит начало следующего символа.
В предлагаемой же системе префиксов такой возможности нет. Искажение или потеря любого байта может привести к полной нечитаемости остальной части текста.
Абсолютно верно, и об этом сказано в самой статье.
Если в вашей задаче важно, чтобы при повреждении строк сохранялась целостность последующего за ними текста — используйте UTF-8. Это ведь нормально — подбирать решение под задачу.
В моей задаче (да и во многих других практических задачах), риск повреждений невысок, а если они возникли — то это уже ошибка в любом случае, независимо от того, сколько именно символов затронуто.
UTF-C:
0xxxxxxx — 1 байт (7 бит)
10xxxxxx xxxxxxxx — 2 байта (14 бит)
110xxxxx xxxxxxxx xxxxxxxx — 3 байта (21 бит)
Предложение:
Использование алгоритма компактного числа (не помню как называется):
0xxxxxxx — 1 байт (7 бит)
1xxxxxxx 0xxxxxxx — 2 байта (14 бит)
1xxxxxxx 1xxxxxxx 0xxxxxxx — 3 байта (21 бит)
1xxxxxxx 1xxxxxxx 1xxxxxxx 0xxxxxxx — 4 байта (28 бит)
Решена проблема нахождения символа по середине текста (Поиск бита 0х80).
Правда нет загашника.
Но можно загашник использовать из ASCII, 0xxxxxxx — 1 байт (7 бит), натягивая текущий алфавит от предыдущего символа.
Ещё один велосипед: храним юникодные строки на 30-60% компактнее, чем UTF-8