В настоящее время, одним из трендов в исследовании графовых нейронных сетей является анализ работы таких архитектур, сравнение с ядерными методами, оценка сложности и обобщающей способности. Все это помогает понять слабые места существующих моделей и создает пространство для новых.
Работа направлена на исследование двух проблем, связанных с графовыми нейронными сетями. Во-первых, авторы приводят примеры различных по структуре графов, но неразличимых и для простых, и для более мощных GNN. Во-вторых, они ограничивают ошибку обобщения для графовых нейронных сетей точнее, чем VC-границы.
Введение
Графовые нейронные сети - это модели, которые работают напрямую с графами. Они позволяют учитывать информацию о структуре. Типичная GNN включает в себя небольшое число слоев, которые применяются последовательно, обновляя представления вершин на каждой итерации. Примеры популярных архитектур: GCN, GraphSAGE, GAT, GIN.
Процесс обновления эмбеддингов вершин для любой GNN-архитектуры можно обобщить двумя формулами:

где AGG - обычно функция, инвариантная к перестановкам (sum, mean, max etc.), COMBINE - функция объединяющая представление вершины и ее соседей.

Более продвинутые архитектуры могут учитывать дополнительную информацию, например, фичи ребер, углы между ребрами и т.д.
В статье рассматривается класс GNN для задачи graph classification. Эти модели устроены так:
Сначала производятся эмбеддинги вершин с помощью L шагов графовых сверток
Из эмбеддингов вершин получают представление графа с помощью инвариантной к перестановкам функций (например, sum, mean, max)
Классификатор предсказывает бинарную метку по представлению графа
Ограничения графовых нейронных сетей
В статье авторы рассматривают ограничения для трех классов GNN:
Локально инвариантные графовые нейронные сети (LU-GNN). Сюда входят вышеупомянутые GCN, GraphSAGE, GAT, GIN и другие
CPNGNN, которая вводит локальный порядок, нумеруя соседние вершины от 1 до d, где d - степень вершины (в оригинальной работе это называют port numbering)
DimeNet, которая оперирует 3D-графами, учитывая расстояния между вершинами и углы между ребрами
Ограничения LU-GNN
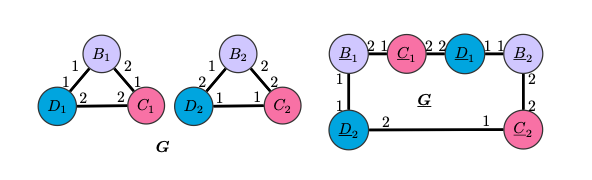
Графы G и G неразличимы LU-GNN, так как деревья вычислений будут совпадать для узлов одного цвета, следовательно эмбеддинги, полученные с помощью инвариантной к перестановкам readout-функции, будут одинаковыми. CPNGNN с введением подходящего порядка сможет различать как одноцветные вершины в G и G, так и сами графы.
Ограничения CPNGNN
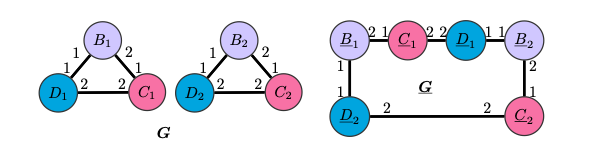
Однако, существует “плохой” порядок, при котором и CPNGNN произведет одинаковые эмбеддинги для вершин одного цвета.

Граф S8 и две копии S4 различаются в таких характеристиках, как обхват, окружность (длина наименьшего и наибольшего циклов соответственно), радиус, диаметр и количество циклов, но CPNGNN с таким порядком портов и readout-ом, инвариантным к перестановкам, произведет для одинаковые эмбеддинги. А значит, по ним невозможно будет восстановить правильные характеристики для обоих графов.

Здесь CPNGNN с такими же условиями не сможет восстановить характеристики из предыдущего примера для графа G2 и двух копий G1. Однако, DimeNet сможет это сделать, так как она учитывает углы, которые не везде совпадают в случае этих графов, например,  и
и  .
.
Ограничения DimeNet

DimeNet не сможет различить G4 и граф, составленный из двух копий G3, так как расстояния и углы в этих графах будут идентичны. Значит, она так же не вычислит характеристики обоих графов. Можно заметить, что G4 и G3 являются графами S4 и S8, натянутыми на куб, а значит, даже усовершенствованная версия DimeNet с нумерацией портов из S4 и S8 не будет справляться с этой задачей.
Шаг в сторону более мощных GNN
Авторы предлагают объединить идеи вышеупомянутых подходов и добавить больше геометрической информации. Например, включить углы и расстояния между плоскостями, которые будут заданы тройкой ребер.
GNN, предложенная авторами работает так:
Шаг DimeNet
Дополнение message-эмбеддинга ребра
 геометрической информацией
геометрической информацией  по формуле
по формуле 
Получение эмбеддинга вершины с учетом введенного локального порядка
 , где c - i-ый сосед вершины v, t - эмбеддинг порядка.
, где c - i-ый сосед вершины v, t - эмбеддинг порядка.
Формула обновления представления вершины:
Шаг инвариантного к перестановкам readout-а
Классификатор или регрессор в зависимости от задачи
Такая модель позволит различать графы во всех вышеприведенных примерах.
Оценка ошибки обобщения
Авторы рассматривают конкретный класс моделей: LU-GNN, в которой обновление представления вершины происходит согласно

где  - нелинейные функции активации,
- нелинейные функции активации,  - вектор признаков для вершины v, такие, что
- вектор признаков для вершины v, такие, что  . Также,
. Также,  липшицевы с константами
липшицевы с константами  соответственно, а
соответственно, а  .
.  одинаковы на всех слоях GNN.
одинаковы на всех слоях GNN.
Далее бинарный классификатор применяется к представлению каждой вершины отдельно и полученные метки усредняются. Параметр  бинарного классификатора обладает свойством
бинарного классификатора обладает свойством  .
.
Пусть  - результат применения GNN к графу с меткой
- результат применения GNN к графу с меткой  ,
,  - разница между вероятностями правильного и неправильного лейбла,
- разница между вероятностями правильного и неправильного лейбла,  только в случае ошибки классификации.
только в случае ошибки классификации.
Фукнция потерь, где  ,
, - индикаторная функция:
![loss_{\gamma}\left( a \right ) = \mathbb{I}\left[ a > 0\right ] + (1 + \frac{a}{\gamma})\mathbb{I}\left[ a \in \left[ \gamma, 0 \right ] \right].](https://habrastorage.org/getpro/habr/upload_files/10f/f87/63c/10ff8763ced82f8bcc4a3f1514442cd6.svg)
Тогда эмпирическая сложность Радемахера для класса функций предсказания GNN  на тренировочном множестве
на тренировочном множестве  :
:

Авторы строят доказательство, пользуясь леммой, в которой утверждается, что с большой вероятностью, ошибку предсказания для GNN можно ограничить суммой ошибки на тренировочной выборке и способностью модели предсказывать класс по эмбеддингу графа. Для класса, рассматриваемого авторами (GNN, которые предсказывают метку графа по меткам большинства вершин), второе слагаемое можно заменить на способность предсказывать класс по вершинам, то есть деревьям вычислений, следовательно можно анализировать эти деревья.
Все вышеописанное было проделано для того, чтобы можно было использовать два факта:
Так как исследуется дерево, можно выразить эмбеддинг вершины рекурсивно через поддеревья
Малые изменения в весах модели так же вносят малый вклад в изменение класса (доказательство приведено в статье)
Это позволяет вывести границы ошибки обобщения по аналогии с RNN

В таблице  - “сложность перколяции”:
- “сложность перколяции”:  , r - размер эмбеддинга, d - максимальная степень вершины, m - размер тренировочной выборки, L - количество слоев,
, r - размер эмбеддинга, d - максимальная степень вершины, m - размер тренировочной выборки, L - количество слоев,  - зазор, зависящий от данных
- зазор, зависящий от данных
Эти оценки позволяют существенно более точно оценить ошибку обобщения, по сравнению с работой, где получили оценку 
Важной частью этой статьи является использование локальной инвариантности к перестановкам внутри GNN, а не только глобальной (в readout-е), как в этой и этой статьях. Это позволяет более точно оценить ошибку обобщения, так как не приходится учитывать каждый порядок, в котором могут быть расположены вершины графа.
Выводы
Важна как мощность модели (способность различать всевозможные пары графов), так и ее обобщающая способность. Однако, более сложные модели склонны к переобучению, поэтому нужно выбирать модели, которые находят баланс, например, исходя из размера датасета, вычислительных ресурсов и других факторов.
С доказательствами и более подробной информацией можно ознакомиться, прочитав оригинальную статью или посмотрев доклад от одного из авторов.

