В процессе подготовки этой статьи мне попался интересный комментарий, в котором была процитирована очень правильная мысль:
Когда ты не правишь багов, и не сидишь на поддержке, ты лишаешь себя важнейшего элемента обратной связи — ты не видишь, какие решения оказались плохи, а какие хороши. А обратная связь — это сама суть инженерии
Следовать вышеприведенному совету архитектора очень желательно, но довольно сложно. Мало-мальски серьезная информационная система имеет, как минимум, отдельное от разработчиков подразделение, отвечающее за эксплуатацию. Часто это могут быть вообще разные компании имеющие несовпадающие интересы. Так что, даже при обоюдном искреннем желании передать-получить обратную связь, сделать это довольно непросто, не говоря уже о согласовании трудозатрат на доработки.
Отчасти у нас была похожая ситуация и кажется мы нашли неплохое решение.
В процессе эксплуатации крупных информационных систем возникает потребность в таких операциях как:
Обработка разных видов обращений пользователей
Построение разных и часто требующихся "внезапно" отчетов
Массовое изменение ролей, индивидуальных настроек, бизнес-процессов и т. п.
Исправление различных сбоев в БД
И т. д. и т. п.
И очень часто все это приходится делать вручную. Смотреть как несколько человек изображают из себе "биороботов", поочередно перебирая тысячи пользователей или объектов системы и вручную проставляя "галки", просто больно. Но, что делать – когда проектировали систему вот этот случай не предусмотрели (и вряд ли могли – ситуация поменялась).
Как мы пытались решать подобные проблемы раньше:
Подразделение, отвечающее за эксплуатацию, осознает и формулирует проблему/задачу.
Вопрос эскалируется аналитикам/разработчикам.
Разумеется, у подразделения, отвечающего за разработку, в рамках развития продукта (идет разработка очередного релиза), хватает срочных и важных задач. Причем требования прописаны в контракте с Заказчиком поэтому, в большинстве случаев, приоритет задач эксплуатации минимальный и срок решения ориентировочно "никогда".
Изредка задачи получается "протолкнуть" в следующий релиз. Но в этом случае срок решения в лучшем случае месяца через 1,5-2.
Так как нужно решить задачу/проблему не "никогда" и даже не через 1,5 месяца, а "вчера", то все требуемые операции выполняются вручную, что часто требует сотен человеко-часов. При этом разработчику потребовалось бы максимум несколько часов, чтобы написать скрипт выполняющий данную операцию. Получается крайне неэффективно.
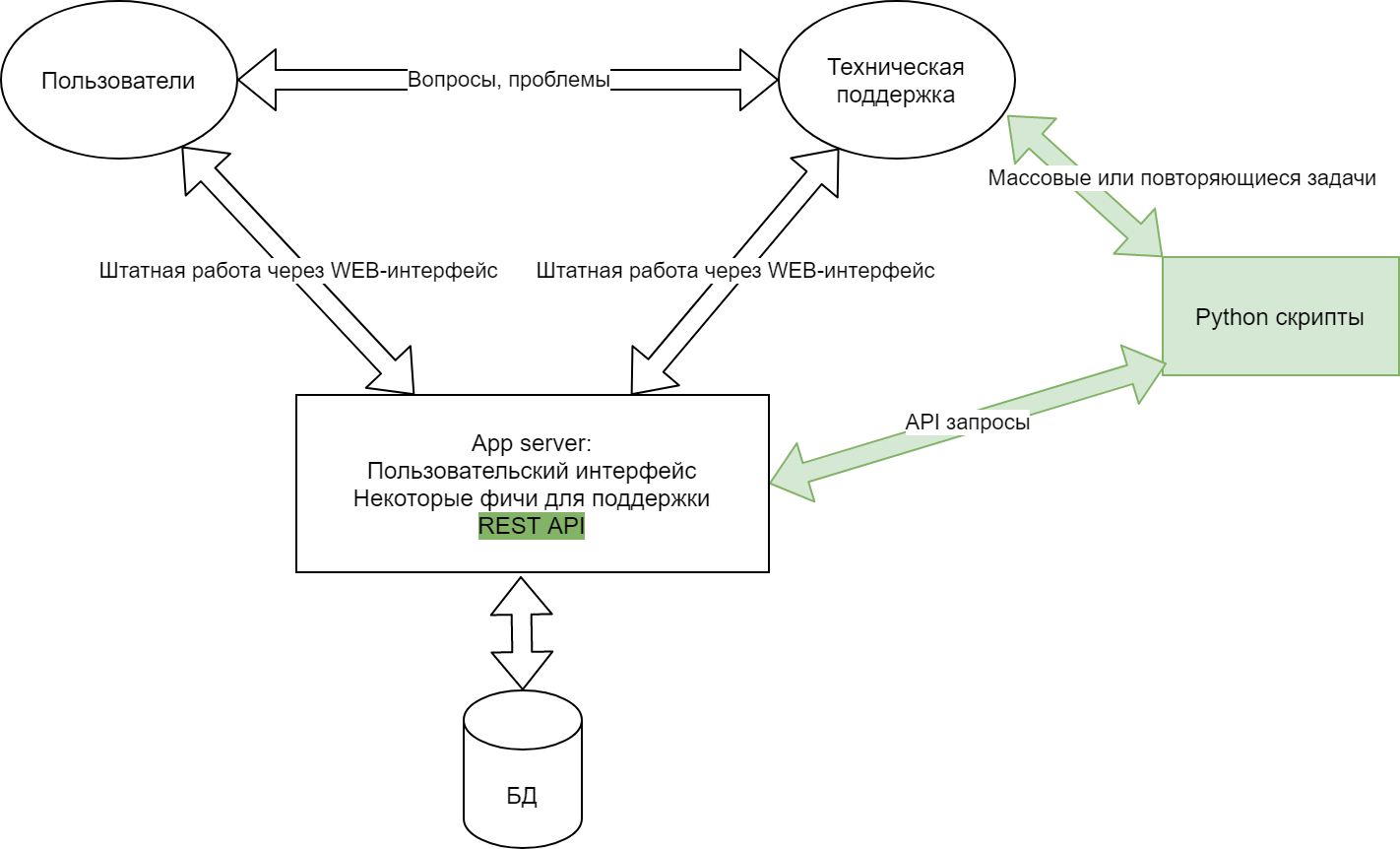
Схематично работа выглядела так:

*Под "App server" скрывается несколько инстансов, каждый из которых состоит из микросервисов. В контексте данной статьи это несущественно – предлагаемый подход также релевантен для монолита.
Используя ТРИЗ мы можем выявить противоречие: задачи развития и эксплуатации системы не могут с равной эффективностью решаться одной командой в рамках одного проекта. Также, эти задачи не то чтобы противоречат архитектуре системы, но смотрятся немного как "пятое колесо". В целом получалось как-то так:

Данное противоречие требовалось устранить.
Попытка решения № 1 (частичный успех)
Одного из сотрудников поддержки переводим на разработку на Java. С помощью Selenium WebDriver автоматизируем наиболее критичные операции.
Плюсы: жить стало полегче.
Минусы: Надежность работы через браузер оставляет желать лучшего. Скорость разработки измеряется днями – неделями, что несколько хуже желаемого. Java довольно тяжеловесный инструмент для подобных задач. Зависимость от одного разработчика.
Попытка решения № 2 (частичный успех)
Постепенно отходим от использования Selenium в пользу прямых GET/PUT запросов, по-прежнему эмулируя работу через WEB-интерфейс. Надежность несколько возрастает.
Попытка решения № 3 (успех)
После очень долгих споров и раздумий было предложено следующее решение: разработать RESTful API позволяющий выполнять практически любую операцию в рамках системы. Фактически большая часть функциональности уже давно была реализована, требовалось только создать "обертку". Это было сделано в одном из релизов без существенных трудозатрат.
Небольшой пример, для понимания, о чем речь:
Get запрос http://api.nashserver.local/support/officials.json?login=eivanov&token=... если указан правильный токен, вернет данные в формате JSON (также поддерживается XML) по сотруднику с данным логином. С помощью PUT-запросов мы можем изменять данные.
Итого мы пришли к следующей схеме работы:
У технической поддержки возникает необходимость массово выполнить значительный объем работы (или объем небольшой, но повторяющийся регулярно).
Сотрудник этого же отдела пишет простенький скрипт на python (обычно это десятки строк, сотни уже редкость), который используя API делает то что требуется
Profit! (рост производительности труда по многим операциям в десятки-сотни раз)
По сути данных поход представляет собой Agile с суперкороткими спринтами. От возникновения идеи до ее реализации и начала использования требуется время от нескольких часов до дней.
Почему был выбран python:
У нас не настоящие
сварщикиразработчики, а команда эксплуатации, поэтому важен низкий порог входа.Богатая библиотека, позволяющая легко обрабатывать запросы и ответы в форматах JSON и XML, работать с Excel и т. д. и т. п.
Легковесные скрипты
В целом все устраивает, но так как лучшее - враг хорошего, несколько слов о потенциальных недостатках:
Нет проверки на корректность выполняемых через API действий. Так как все максимально упрощено и процедуры тестирования кода нет, можно массово повредить данные, нарушить консистентность. Данные хранятся в документоориентированной СУБД MongoDB, поэтому даже связей первичный-внешний ключ там нет. Ресурсов на разработку проверок на уровне API у нас не было. Кроме того, проверки создадут дополнительную нагрузку на систему и замедлят выполнения. Но если будете реализовывать нечто подобное, советую проверки консистентности сделать. Можно при этом добавить в API-запросы параметр "&check=true" (по умолчанию), "&check=false" (отключать проверки после отладки скрипта для ускорения обработки или если требуется исправить уже поломанные данные и мы точно знаем, что и для чего делаем). По факту несколько лет ничего серьезно не ломали, но риск сохраняется.
Скрипты пишут сотрудники, не являющиеся программистами. От большой части кода у меня "кровь из глаз". Но он работает и делает то что требуется. А работающий код все равно намного лучше, чем ненаписанный вовсе. Иногда делаю ревью и рефакторю сам, чаще стараюсь очень вежливо и тактично объяснить, как писать правильней. Это довольно сложно донести так, чтобы недемотивировать автора, хотя по факту хочется выкинуть всё и переписать заново. При этом четко осознаю, что как только коллега научится писать код на приличном уровне, он уйдет в разработку, а новичка придется учить заново. Уже смирился с тем что код скриптов никогда не достигнет качества, принятого во "взрослой" разработке. Также не всегда и с трудом удается привить нормальные практики использования Jira и git.
Наша система функционирует в закрытой корпоративной сети с достаточно серьезными политиками сетевой безопасности. Но вообще решение передавать токен в виде параметра http-запроса, как в приведенном выше примере, совершенно неустойчиво к MITM-атаке. Если будете реализовать подобное решение, советую хорошо проработать вопросы безопасности.

