Привет, Хабр! Сегодня мы немного поговорим о DevOps и самоорганизации на примере одного из наших проектов.
Начнем с фразы, с которой не соглашается добрая половина разработчиков в индустрии: "каждый разработчик должен быть сам себе DevOps". Кто-то считает, что этим должен заниматься отдельно выделенный человек, чтобы у разработчика оставалась забота только о качестве кода. А кому-то свойственно думать о конвейере доставки кода в той же степени, как и о самом коде. Я же считаю, что в современных реалиях рынка и избытке инструментов/знаний разработчик должен уметь настроить и обслуживать конвейер быстрой и предсказуемой доставки артефакта в нужную ему среду. В отличие от мобильных разработчиков, для которых вопросы инфраструктуры и доставки приложения в большей степени решены самим вендором (Google и Apple), backend и web разработчики должны если не владеть, то хотя бы интересоваться практиками доставки кода.
И речь не идет о настройке каких-то больших и громоздких билд-систем, для которых обычно приносится в жертвую целая штатная единица. Нет. DevOps - не человек, а система ежедневных маленьких привычек, основанных на самоорганизации. Понятие, взрастающее снизу вверх, а не сверху или в бок. И если вы, как разработчик, смогли ускорить поток артефактов (любимое американцами понятие "Value Stream") на небольшой процент, то поздравляем - это уже DevOps way. Рекомендуем прочесть книгу "DevOps Handbook" by Gene Kim - лучшая книга для понимания этого концепта (ссылка в конце статьи).
В этой статье мы представим вам маленькую историю зарождения DevOps в нашей команде, позволившую нам ускорить разработку проекта. Эта история применима как к разработчику-одиночке, так и к большой команде.
Кто
Одна из наших команд занимается разработкой системы интернет-банкинга для одного крупного банка. Команда достаточно большая, но речь сегодня пойдет о конкретных персонажах:
3 фронтенд разработчика с кучей пулл реквестов в день
2 тестировщика, бастующие за улучшение QX (QA experience)
Что
Клиентское и администраторское web-приложения на Angular 9.0, собираемые из одного репозитория.
Где
Моя команда известна как ярый адепт продуктов Atlassian, поэтому вся экосистема нашего проекта живет в "австралийских облаках":
задачи и релизы в Jira
код в Bitbucket
CI в Bitbucket Pipelines
подробная документация в Confluence.
Наша команда использует стандартный план Bitbucket за $4/чел, включающий в себя 1500 минут сборки в Bitbucket Pipelines. О нем в сегодняшней статье и пойдет речь. Принцип работы и синтаксис настройки на 90 процентов похожи на Gitlab CI, поэтому любому пользователю Gitlab вся схема работы будет максимально понятной.
Сама система интернет банкинга разбита на микросервисы и работает в контейнерах на серверах Банка. Но в этой статье речь будет идти не о контейнерах, хотя настройка CI с помощью Docker-образов звучит очевидным.
Немного контекста
Первые наши шаги в DevOps и конкретно в улучшении QX (QA experience) мы начали задолго до этого в проектах мобильных приложений. Мы интегрировали между собой Jira, Bitbucket и сервис Bitrise.io во всех наших пулл-реквестах, что позволило иметь на выходе конкретный билд на каждый коммит по конкретной задаче. Для наглядности: тестировщик понимал, что пулл реквест №30 выдает билд приложения №170, в которой нужно тестировать Jira-задачу №500. Если вкратце описать процесс пулл-реквестов, то обязательными требованиями к слиянию пулл-реквеста являются
Зеленый билд на последнем коммите
Добро от разработчика-ревьюера
Добро от тестировщика
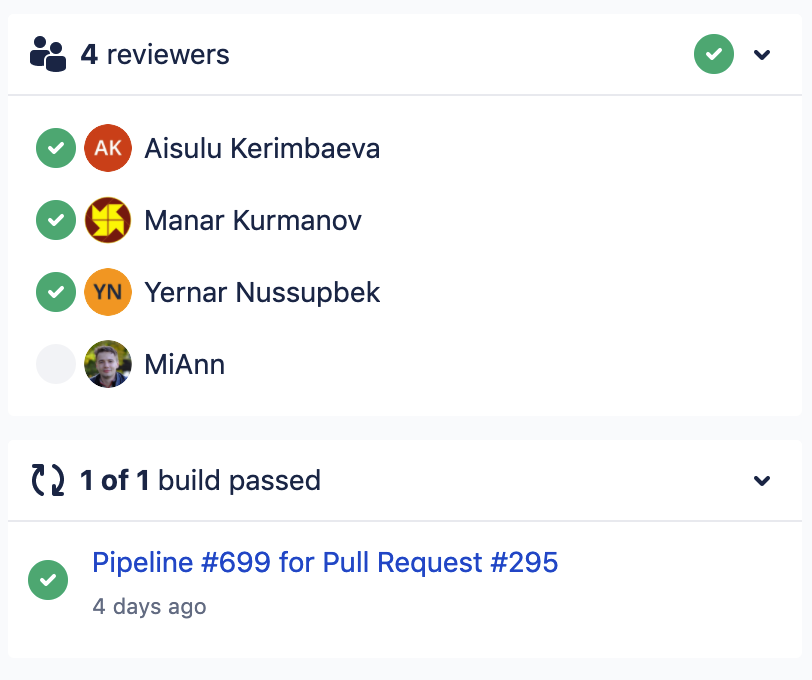
Если один из этих шагов давал красный свет, то пулл-реквест проходит все шаги заново.
Такой процесс позволяет нам обеспечить высокое качество кода и продукта в стабильной ветке репозитория. Мы с высокой долей уверенности можем релизить приложение, собранное с master (мы начали работать по trunk-based development и поэтому master наша стабильная ветка).
В данном проекте для мобильных приложений мы применили ту же самую рабочую схему для мобильных приложений и начали выпускать и проверять тестовые приложения с первого дня.
Подобного механизма пулл-реквестов никогда не существовало в web приложениях. Мы всегда делали приемку задач после слияния пулл-реквестов в стабильную ветку, из-за чего каждый третий коммит в ней был дефектным. Настроить такой же процесс приема пулл реквестов, как в мобилке, было для нас очевидным шагом. Сделать CI окружение для web приложения на инфраструктуре Банка было для нас слишком долгой историей, потому что хотелось настроить и поехать очень быстро. А все, кто работал с большими банками, почувствовал "скорость" продвижения задач по железу. Все процессы, что мы опишем в этой статье, мы планируем воссоздать в инфраструктуре банка с помощью оркестратора (Kubernetes или OpenShift, на усмотрение заказчика), но это уже другая история. В тот момент нам нужно было как можно быстрее начать работать правильно.
Первый очевидный вопрос: куда доставлять? Мы начали присматриваться к разным вариантам: Heroku, AWS, Netlify, Surge итд. В итоге остановились на использовании AWS S3. Для тех, кто думал, что S3 это всего лишь файловое хранилище - S3 может работать как сайт и его можно привязать к доменному имени. Подробнее об этом можно прочитать на страничке AWS.
Так почему же AWS?
Доступная цена. При всей репутации AWS как дорогой экосистемы, ежемесячные счета за S3 выходят в среднем 2 доллара при следующих метриках:
Новых ПР в день ~ 2
Пайплайнов в день ~ 12
Кол-во единовременно существующих бакетов ~ 5
Средний размер бакета = 13 Mb
У AWS отличный API и CLI. у "Surge" и других легковесных сервисов хостинга не настолько качественный и полноценный тулинг, как у Amazon AWS. Надо отметить, что CLI и документация Heroku не уступает Амазону, но высокий на наш взгляд порог вхождения и специфика работы Heroku Dynos заставили нас отойти от его выбора.
У команды уже был опыт работы с продуктами AWS.
Можно было бы настроить весь этот процесс в контейнерах в самом Amazon, но это повлечет за собой запуск EC2 машин. Даже с использованием Docker Hub вместо Elastic Container Registry, прогноз затрат вываливался у нас за $100 в месяц. В конечном итоге у нас получилась именно та схема работы с пулл-реквестами, которую мы представляли себе в самом начале. Но давайте проанализируем каждую ступень нашей эволюции и посмотрим на принятые решения.

Уровень №1: создание S3 бакета
Мы начали с того, что создали по одному выделенному S3 bucket для хостинга клиентского и админского приложений. Настроили конфигурацию сборки нашего проекта (bitbucket-pipelines.yml), чтобы он собирал приложения (html/css/js/img) и заливал их в соответствующий S3 bucket. В начале был использован AWS CLI, но, как оказалось, Bitbucket предоставляет набор готовых официальных Pipes (аналог Github actions), среди которых оказался Pipe для выгрузки файлов в S3 bucket. В итоге: тестировщик имеет сайт, на котором он может проверить реализацию задачи пулл-реквеста с постоянной условной ссылкой web.s3-website.ap-northeast-2.amazonaws.com.
Обязательным предварительным шагом при создании бакета через консоль AWS является включение опции "Enable static hosting" в настройках бакета. Без этой опции bucket является просто файловым хранилищем.
- step:
name: Build and deploy webadmin PR version into AWS for QA
caches:
- node
script:
# начальная конфигурация
- apk update && apk add git
- npm install
# сборка
- npm run build:admin
- cd dist/admin
# загрузка в S3
- pipe: atlassian/aws-s3-deploy:0.2.4
variables:
AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID
AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY
AWS_DEFAULT_REGION: $AWS_DEFAULT_REGION
S3_BUCKET: $S3_WEBADMIN_BUCKET_NAME
DELETE_FLAG: 'true'
LOCAL_PATH: $(pwd)
ACL: 'public-read'
Но данная схема оказалась совершенно не масштабируемой по следующей причине: запущенный пайплайн пулл-реквеста от второго автора перетирала наработки первого. С этой примитивной схемой команда жила месяц.
Оценка:
за старания - четверка
за QX - двойка
Уровень №2: выделение S3 bucket под каждого автора
В ответ на обратную связь от тестировщиков командой было решено выделить по одному S3 bucket на каждого фронтенд разработчика. В нашем проекте были разработчики Манар, Миша - следовательно были созданы условные S3 бакеты jsn-web-manar и jsn-web-michael. В bitbucket-pipelines.yml в step для пулл-реквестов была добавлена логика определения конечного S3 бакета в зависимости от PR автора.
В итоге у тестировщика следующая картина: он знает, кто автор пулл-реквеста и переходит на сайт в нужном бакете, если есть зеленый билд, и приступает к тестированию. Но это улучшение в процессе тестирования выявило ряд скрытых неудобств:
Гонка пулл-реквестов одного автора. Если один и тот же разработчик создаст 3 параллельных пулл-реквеста, то все они вызовут запуск пайплайна сборки. Мы не можем точно знать, какой из пайплайнов закончится быстрее. Команде, в частности тестировщику, без использования консоли Chrome сложно понять, какой из пулл-реквестов сейчас развернут на S3 бакете разработчика Михаила.
Появление нового автора. В наших репозиториях создавать пулл-реквест может любой член команды, поэтому эта схема сломалась ровно в тот момент, когда ПР создал кто-то, кроме фронтенд-разработчиков. По нашей тривиальной логике определения бакета его запущенный пайплайн "угонит" S3 бакет одного из разработчиков. В итоге другой тестировщик может потерять version-under-test сайт прям в момент тестирования.
Смена никнейма. Наши разработчики забавы ради любят менять свои git author name время от времени. Для нас это никогда не являлось проблемой до того, как мы применили логику с бакетами на каждого автора. К сожалению, Bitbucket Pipelines из коробки не предоставляют возможности определения автора по его Jira account, поэтому в логике присвоения бакета пришлось оперировать стандартным commit git author. Как вы и сами догадались, при смене имени с "Manar Kurmanov" на "Dark Lord" повторилась ситуация из пункта 2 - был угнан бакет другого разработчика.
️ С этой шаткой схемой команда прожила еще несколько месяцев.
Оценка:
за старания - четверка
за QX - тройка
Уровень №3: добавление штампа авторства в web приложение
Команда решила проблему гонки пулл-реквестов добавлением пояснительного текста в footer сайта:

Каждый пайплайн добавлял в футер сайта название ветки, автора и timestamp. Таким образом решалась проблема параллельных пулл-реквестов от одного автора - тестировщик четко понимает, какая Jira-задача разработчика Георгия представлена в бакете.
Фрагмент из bitbucket-pipelines.yml
- step:
name: Build PR version
caches:
- node
script:
# initial configuration
- apk update && apk add git
- npm install
# preparing site footer text
- TIMESTAMP_FILE="./src/app/some/folder/copyright.timestamp.html"
- GIT_AUTHOR=$(git log -n 1 --format=format:'%an')
- PR_URL="$BITBUCKET_GIT_HTTP_ORIGIN/pull-requests/$BITBUCKET_PR_ID"
- BRANCH_TEXT="PR branch <a href=\\"$PR_URL\\">$BITBUCKET_BRANCH</a><br>"
- echo $BRANCH_TEXT >> $TIMESTAMP_FILE
- echo "Author $GIT_AUTHOR<br>" >> $TIMESTAMP_FILE
- echo "Built at $(TZ=UTC-6 date '+%d-%m-%Y %H:%M') <br>" >> $TIMESTAMP_FILE
- echo "</small>" >> $TIMESTAMP_FILE
- cat $TIMESTAMP_FILE > src/app/target/folder/copyright.component.html
# building artefacts
- npm run build
artifacts:
paths:
# кеширование артефактов для следующего Build Step
- dist/web/**
Казалось бы, +100 к QX, куда еще прозрачнее. Но поставьте себя на место тестировщика в ежедневной работе и вы поймете еще одно скрытое неудобство. Допустим, что разработчик создал 3 параллельных пулл-реквеста и тестировщик проверил сайт на S3 бакете. Что он должен делать дальше? Тестировщику не очевидно, что он находится в ситуации очереди ПР-ок на один и тот же S3 бакет. После он должен зайти в странице Pipelines, найти нужную ветку и сделать ручной Rerun.
Мы поняли, что проблема с гонкой пулл-реквестов принципиально не решена и нашу схему тестирования нельзя назвать масштабируемой. Нужно пересмотреть процесс.
Оценка:
за старания - четверка
за QX - тройка с плюсом
Уровень №4: динамичные бакеты под каждый пулл реквест
Мы решил копнуть глубже в возможности AWS API и воссоздать поведение динамических сред для тестировщиков и разработчиков. Какие были требования:
Каждый пулл реквест должен породить свой отдельный S3 бакет и задеплоить сайт туда.
Нужно, чтобы в комментарий к пулл-реквесту писалась ссылка на этот бакет при каждом новом билде.
Автоматика должна уметь подчищать за собой неиспользуемые бакеты
Для реализации этих требований не хватало стандартных Bitbucket Pipes, поэтому нужно было писать кастомные скрипты для взаимодействия с AWS S3. К счастью Bitbucket Pipelines, как и многие CI системы, является cloud-first и предоставляет возможность запускать свои пайплайны на базе любого публичного Docker образа. Мы использовали официальный образ aws-cli, включающий в себя AWS CLI и все базовые утилиты командной строки (curl, sed, xargs).
Ниже фрагмент из bitbucket-pipelines.yml по загрузке статики сайта в динамический бакет. NOTE: в скрипте используются ключи и секреты из учетной записи AWS S3, их можно сгенерировать по официальной инструкции.
- step:
name: Deploy PR version into AWS bucket for QA
image:
name: amazon/aws-cli
script:
# 1. Настройка сессии в aws cli с помощью ключей
- aws configure set aws_access_key_id=$AWS_ACCESS_KEY_ID aws_secret_access_key=$AWS_SECRET_ACCESS_KEY
# 2. определяем название для динамического бакета
- export BUCKET_NAME=web-pullrequest-$BITBUCKET_PR_ID
# 3. если в AWS нету бакета с таким названием, создаем его с нужными флагами
- if [ -z $(aws s3 ls | grep $BUCKET_NAME) ]; then aws s3api create-bucket --bucket $BUCKET_NAME --acl public-read --region ap-northeast-2 --create-bucket-configuration LocationConstraint=ap-northeast-2; fi
# 4. задаем это бакету настройку статичного хостинга
- aws s3api put-bucket-website --website-configuration "{\\"ErrorDocument\\":{\\"Key\\":\\"error.html\\"},\\"IndexDocument\\":{\\"Suffix\\":\\"index.html\\"}}" --bucket $BUCKET_NAME
# 5. очищаем содержимое бакета
- aws s3 rm s3://$BUCKET_NAME --recursive
# 5. заливаем в него собранные html/css/js
- aws s3 cp dist/web s3://$BUCKET_NAME --acl public-read --recursive
# 6. Пишем коммент со ссылкой от имени сервисной учетки в нужный пулл реквест
- export PR_API_URL=https://api.bitbucket.org/2.0/repositories/$BITBUCKET_REPO_FULL_NAME/pullrequests/$BITBUCKET_PR_ID/comments
- export BUCKET_PUBLIC_URL=http://$BUCKET_NAME.s3-website.ap-northeast-2.amazonaws.com
- curl $PR_API_URL -u $CI_BB_USERNAME:$CI_BB_APP_PASSWORD --request POST --header 'Content-Type:application/json' --data "{\\"content\\":{\\"raw\\":\\"[http://$BUCKET_NAME.s3-website.ap-northeast-2.amazonaws.com](http://$BUCKET_NAME.s3-website.ap-northeast-2.amazonaws.com)\\"}}"

В качестве автора комментарий в пулл реквест мы использовали нашу сервисную учетную запись для CI с использованием App-specific password. В этой статье от Atlassian можно узнать, как создать такой пароль.
Данная схема может обслуживать и двоих и сотню разработчиков - мы обеспечили масштабируемость и прозрачность процесса тестирования.
"Единственный ручной процесс в этой схеме - чистка неиспользуемых S3 бакетов раз в неделю. Зачем это автоматизировать?" - подумали мы. Но по закону жанра команда благополучно забывала подчищать бакеты и вспомнила об этом только после того, как бухгалтер показал счет на 25 долларов от AWS из-за скопившихся бакетов.

В итоге мы решили добавить логику чистки неиспользуемых бакетов в пайплайн при слиянии пулл-реквеста.
- step:
name: Remove dangling s3 buckets left after PR merges
image:
name: amazon/aws-cli
script:
# 1. Запросить список 10 последних MERGED пулл реквестов
- export API_URL="<https://api.bitbucket.org/2.0/repositories/$BITBUCKET_REPO_FULL_NAME/pullrequests?state=MERGED>"
- curl "$API_URL" -u $CI_BB_USERNAME:$CI_BB_APP_PASSWORD > pr_list.json
# 2. выделить бакеты, соответствующие спец-формату
- aws s3 ls | grep -o '[a-zA-Z\\-]\\+pullrequest\\-[0-9]\\+' > buckets.txt
- set +e
# очистить все бакеты с номер ПР-ок, которые уже MERGED
# (AWS API требует очистки бакета перед его полным удалением)
- echo "$(cat pr_list.json | grep -o '"id":\\s[0-9]\\+')" | sed 's/[^0-9]//g' | xargs -I{} grep {} buckets.txt | xargs -I{} aws s3 rm s3://{} --recursive
# удалить все бакеты с номер ПР-ок, которые уже MERGED
- echo "$(cat pr_list.json | grep -o '"id":\\s[0-9]\\+')" | sed 's/[^0-9]//g' | xargs -I{} grep {} buckets.txt | xargs -I{} aws s3api delete-bucket --bucket {}Оценка:
За старания пятерочка
за QX - четверка с плюсом. Почему не пять? Потому что на своей шкуре мы поняли, что улучшение любого X (QX, DevX, HX) - это бесконечный процесс
Технические ремарки
Есть несколько важных моментов, которые стоит отметить для всех желающих опробовать данную схему.
#1: По поводу CORS
Так как API запросы совершаются с одного хоста (.amazonaws.com) на другой хост (*.somebank.com), по умолчанию они будут блокироваться браузером из-за настроек CORS (cross origin resource sharing) сервера. Если вкратце, то браузер позволяет отправлять запросы только из того же хоста, откуда сайт был запрошен. Для примера, API на api.server.com будет принимать запросы только с сайта server.com. При попытке сделать GET запрос с сайта another.com браузер сначала совершит "pre-flight" запрос на сервер и поймет, что сервер строго выдерживает правило "same-origin-policy".
Для того, чтобы запросы со статичного сайта S3 бакета проходили в ваш API, вы должны добавить хост бакета в серверные настройки Headers.
Access-Control-Allow-Origin: <http://bucket.s3-website.amazonaws.com>
# или
Access-Control-Allow-Origin: *
Во всех популярных фреймворках есть поддержка управления Cross Origin.
#2: По поводу расходов
В уровне №4 в скрипте присутствует строка очистки содержимого бакета:
aws s3 rm s3://$BUCKET_NAME --recursive Это микро оптимизация расходов компании на AWS. Мы на каждом запуске ПР пайплайна очищаем предыдущее содержимое бакета, чтобы в нем не скопились файлы от 4 предыдущих сборок одного и того же пулл реквеста.
Если этого не делать, то размер бакета будет увеличиваться пропорционально кол-ву пайплайнов на 1 ПР. В масштабах 3 разработчиков это экономит нам пару центов, но в масштабе десяток разработчиков и долгих ПР - это десятки долларов. Мы считаем, что это полезное упражнение как минимум с точки зрения практики владения AWS API.
ВАЖНО! Если в вашем проекте будет использоваться долгоживущий S3 bucket и вы будете использовать официальный aws-s3-deploy pipe, то убедитесь, что вы используете DELETE_FLAG. Этот флаг очищает bucket перед очередной выгрузкой файлов. Во время уровня #1 наша команда об этом флаге не знала в течение 2 месяцев и узнала только после обнаружения нескольких тысяч файлов в одном бакете. Поэтому парочку десяток американских долларов было сожжено во имя наших познаний.
# вызов пайпа загрузки файлов в S3 с флагом DELETE_FLAG
- pipe: atlassian/aws-s3-deploy:0.2.4
variables:
AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID
AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY
AWS_DEFAULT_REGION: $AWS_DEFAULT_REGION
S3_BUCKET: $S3_WEBADMIN_BUCKET_NAME
DELETE_FLAG: 'true' # не забыть этот флаг
LOCAL_PATH: $(pwd)
ACL: 'public-read'
Вывод
Эта история проб и ошибок одного отдельного процесса позволила нам не только улучшить конкретно этот процесс, а посеяла в нас зерно DevOps ментальности и дала настрой на мини улучшения в других местах проекта и продукта. Мы рекомендуем всем, кто еще не погружался в практики CI/CD, изучить и отточить это направление в своей карьере.
Финальную версию bitbucket-pipelines.yml можно посмотреть в github репозитории.
Материалы к прочтению
Туториал от Bitbucket по CI/CD - для погружения в инструмент
http://www.yamllint.com/ - тут вы сможете валидировать YAML структуру, если нет этого инструмента под рукой
Книга DevOps handbook - для понимания концепции с примерами. Очень рекомендуем.

