Всем привет! Рассмотрим данные о грибах, предскажем их съедобность, построим корреляцию и многое другое.
Воспользуемся данными о грибах с Kaggle (исходный датафрейм) с https://www.kaggle.com/uciml/mushroom-classification, 2 дополнительных датафрейма приложу к статье.
Все операции проделаны на https://colab.research.google.com/notebooks/intro.ipynb
# Загружаем библиотекeу для работы с данными import pandas as pd # для построения леса деревьев решений, обучения моделей и построения confusion_matrix: from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import GridSearchCV from sklearn.metrics import confusion_matrix # для работы с графикой: import matplotlib.pyplot as plt import seaborn as sns # Загружаем наш датафрейм mushrooms = pd.read_csv('/content/mushrooms.csv') #Просматриваем наши данные mushrooms.head() # Что будет изображено после выполнения кода можете увидеть на картинке внизу:

#Краткая сводка данных mushrooms.info()

#Информация о количестве строк и столбцов mushrooms.shape # Используем кодировщик данных LabelEncoder для преобразования наших категоральных или текстовых данных в числа (обязательно перед heatmap) # Если мы этого не сделаем, при обучении дерева у нас возникнет ошибка на этапе его обучения from sklearn.preprocessing import LabelEncoder le=LabelEncoder() for i in mushrooms.columns: mushrooms[i]=le.fit_transform(mushrooms[i]) # Посмотрим как преобразовались наши данные mushrooms.head()

# Просмотрим корреляцию наших данных с помощью heatmap fig = plt.figure(figsize=(18, 14)) sns.heatmap(mushrooms.corr(), annot = True, vmin=-1, vmax=1, center= 0, cmap= 'coolwarm', linewidths=3, linecolor='black') fig.tight_layout() plt.show()

Положительно коррелирующие значения: Сильная корреляция (veil-color,gill-spacing) = +0.9 Средняя корреляция (ring-type,bruises) = +0.69 Средняя корреляция (ring-type,gill-color) = +0.63 Средняя корреляция (spore-print-color,gill-size) = +0.62 Отрицательно коррелирующие значения Средняя корреляция (stalk-root,spore-print-color) = -0.54 Средняя корреляция (population,gill-spacing) = -0.53 Средняя корреляция (gill-color,class) = -0.53 Если в нашем исследование возьмем максимально тесно связанные коррелирующие значения, то получим максимально точные значения и точно обученную модель. В нашей задаче мы будем обучать модель по классу, представляя, что аналитик не воспользовался таблицей корреляции.
# Отбросим колонку, которую будем предсказывать. X = mushrooms.drop(['class'], axis=1) # Создадим переменную, которую будем предсказывать. y = mushrooms['class'] # Создаем модель RandomForestClassifier. rf = RandomForestClassifier(random_state=0) # Задаем параметры модели, изначально когда мы не знаем оптимальных параметров для обучения леса задаем так #{'n_estimators': range(10, 51, 10), 'max_depth': range(1, 13, 2), # 'min_samples_leaf': range(1,8), 'min_samples_split': range(2,10,2)} parameters = {'n_estimators': [10], 'max_depth': [7], 'min_samples_leaf': [1], 'min_samples_split': [2]} # Обучение Random forest моделей GridSearchCV. GridSearchCV_clf = GridSearchCV(rf, parameters, cv=3, n_jobs=-1) GridSearchCV_clf.fit(X, y) # Определение наилучших параметров, и обучаем с ними дерево для получения лучшего уровня обучаемости best_clf = GridSearchCV_clf.best_params_ # Просмотр оптимальных параметров. best_clf

# Создание confusion matrix (матрицу ошибок) по предсказаниям, полученным в прошлом шаге и правильным ответам с нового датасета. y_true = pd.read_csv ('/content/testing_y_mush.csv') sns.heatmap(confusion_matrix(y_true, predictions), annot=True, cmap="Blues") plt.show()
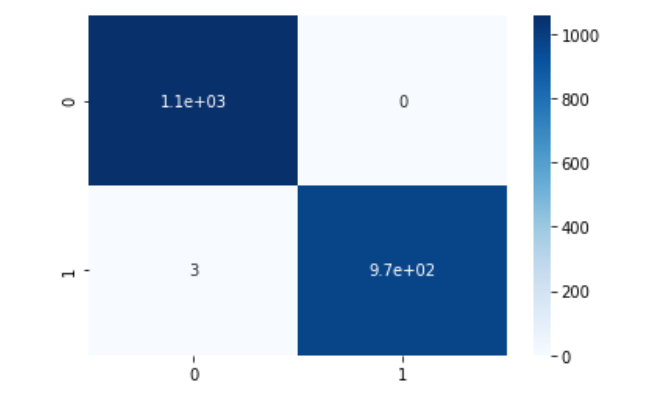
Данная матрица ошибок показывает, что у нас отсутствуют ошибки первого типа, но присутствуют ошибки второго типа в значении 3, что для нашей модели является очень низким показателем стремящемся к 0.
Далее мы проделаем операции для определения модели наилучшей точности нашем дф
# определим точность нашей модели from sklearn.metrics import accuracy_score mr = accuracy_score(y_true, predictions) #Данные для тренировки и тестировки датафрейма from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0) #Логистическая регрессия #Тренируем модель from sklearn.linear_model import LogisticRegression lr = LogisticRegression(max_iter = 10000) lr.fit(x_train,y_train) #Строим матрицу ошибок from sklearn.metrics import confusion_matrix,classification_report y_pred = lr.predict(x_test) cm = confusion_matrix(y_test,y_pred) #Делаем проверку точности log_reg = accuracy_score(y_test,y_pred) #K ближайших соседей #Тренируем модель from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors = 5, metric = 'minkowski',p = 2) knn.fit(x_train,y_train) #Создаем матрицу ошибок from sklearn.metrics import confusion_matrix,classification_report y_pred = knn.predict(x_test) cm = confusion_matrix(y_test,y_pred) #Делаем проверку точности from sklearn.metrics import accuracy_score knn_1 = accuracy_score(y_test,y_pred) #Дерево решений #Тренируем модель from sklearn.tree import DecisionTreeClassifier dt = DecisionTreeClassifier(criterion = 'entropy') dt.fit(x_train,y_train) #Создаем матрицу ошибок from sklearn.metrics import confusion_matrix,classification_report y_pred = dt.predict(x_test) cm = confusion_matrix(y_test,y_pred) #Делаем проверку точности from sklearn.metrics import accuracy_score dt_1 = accuracy_score(y_test,y_pred) #Простой вероятностный классификатор #Тренируем модель from sklearn.naive_bayes import GaussianNB nb = GaussianNB() nb.fit(x_train,y_train) #Создаем матрицу ошибок from sklearn.metrics import confusion_matrix,classification_report y_pred = nb.predict(x_test) cm = confusion_matrix(y_test,y_pred) #Делаем проверку точности from sklearn.metrics import accuracy_score nb_1 = accuracy_score(y_test,y_pred) #Осущевстляем проверку точностей plt.figure(figsize= (16,12)) ac = [log_reg,knn_1,nb_1,dt_1,mr] name = ['Логистическая регрессия','К ближайших соседей','Простой вероятностный классификатор','Дерево решений', 'Случайные деревья'] sns.barplot(x = ac,y = name,palette='colorblind') plt.title("График точностей моделей", fontsize=20, fontweight="bold")

Мы можем сделать вывод, что наиболее точной моделью для наших предсказаний является дерево решений.

