
Компания Rittman Analytics — партнер по внедрению сегментного подхода в маркетинге. С помощью сервисов Segment Personas и Segment Connections мы соединяем все элементы цифрового маркетинга и формируем единую картину взаимодействия с клиентами и посетителями для задействованных цифровых каналов.
Платформы клиентских данных, такие как Segment Personas, позволяют эффективно собирать подробную историю взаимодействия с существующими и перспективными клиентами. Эти данные можно комбинировать с информацией о сделках и другими сведениями, которые мы сохраняем о клиентах, когда они заходят на наш сайт со своими учетными данными или выражают интерес к предлагаемому нами новому продукту или услуге.
Используя данные о клиентах из Segment Personas, мы снабжаем свою службу чат-ботов Intercom информацией о проекте, реализуемом нами для клиента, а также о его предпочтениях и интересах, чтобы сделать взаимодействие с ним более релевантным и эффективным и повысить вероятность успешного результата.

Зачем нам нужно хранилище клиентских данных?
Personas и прочие платформы клиентских данных в целом эффективно помогают понимать и оптимально учитывать потребности существующих и потенциальных клиентов, когда те активно взаимодействуют с цифровой стороной нашего бизнеса. Однако такие сервисы по определению анализируют данные лишь тех, кто посещает наш веб-сайт или взаимодействует с другими маркетинговыми каналами.
Основная часть нашего взаимодействия с существующими и потенциальными клиентами приходится не на сеть, а на отделы продаж, доставки и финансовых расчетов, и именно это взаимодействие позволяет собрать гораздо более подробные, разносторонние и актуальные данные, особенно если учесть возраст нашей компании.
Лучшим местом для хранения таких комплексных данных о взаимодействии с клиентами является облачное хранилище данных, и в этой статье я расскажу, как мы используем для этой цели Google BigQuery совместно с Looker, Segment и нашим решением RA Warehouse for dbt. С помощью этих инструментов мы объединяем данные офлайн-коммуникации с данными из сети как для клиентов, так и для контактных лиц и синхронизируем их с нашей CRM-системой Hubspot при помощи нового сервиса «обратного ETL» — Hightouch.
Создание комплексного представления всех взаимодействий с клиентами
Я уже писал о том, как мы создали собственное хранилище данных, используя Google BigQuery, dbt и наш пакет с открытым кодом RA Warehouse for dbt. Этот пакет обеспечивает аналитику данных о финансовых операциях, проектах, маркетинге, клиентах и продуктах, а недавно в нем была реализована совместимость с хранилищем данных Snowflake.
Данные, генерируемые в ходе наших операций, централизуются в едином интегрированном представлении предприятия. Для этого используются средства dbt (Data Build Tool) и наш пакет RA Warehouse for dbt. С их помощью мы соединяемся с источниками данных, преобразуем данные и управляем различными этапами процесса интеграции. На скриншоте ниже продемонстрировано количество источников и этапов преобразования, составляющих процесс формирования комплексного представления о клиенте в настоящее время (источники показаны светло-зеленым цветом, преобразования — голубым).

Итогом этого процесса является таблица BigQuery, в которой каждому клиенту отведена одна строка и содержатся данные о выставлении счетов, контактных лицах и участии этих лиц в маркетинговой активности или продажах; данные структурированы в форме вложенных повторяющихся столбцов BigQuery. На основе данных из этой таблицы создается шкала событий, отражающая всю историю нашего взаимодействия с клиентом и всеми его контактными лицами, — см. скриншоты таблицы ниже.

Еще одна последовательность шагов в нашем пакете dbt совмещает и интегрирует данные отдельных контактных лиц, отражая их активность от имени всех компаний в нашей базе данных, с которыми они могут быть связаны.

Эти наборы данных о клиентах и контактных лицах мы используем для создания соответствующих исследований в Looker. В последней версии Looker появилось новое приложение, которое можно установить из магазина. Оно позволяет создавать интерактивные диаграммы исследований, чтобы показать, как представления и модели связаны друг с другом.
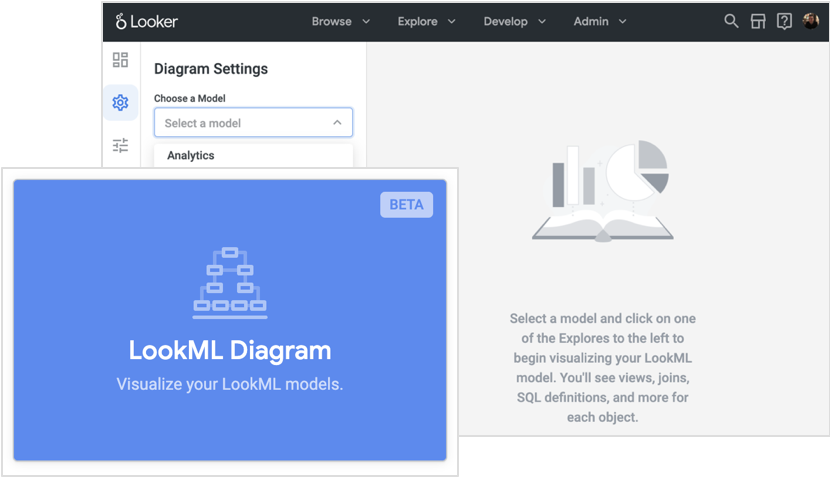
Приведенная ниже диаграмма создана с помощью этой новой функции и показывает, как мы настроили исследование клиента и как различные представления таблиц нашего хранилища связаны с центральным представлением клиента.
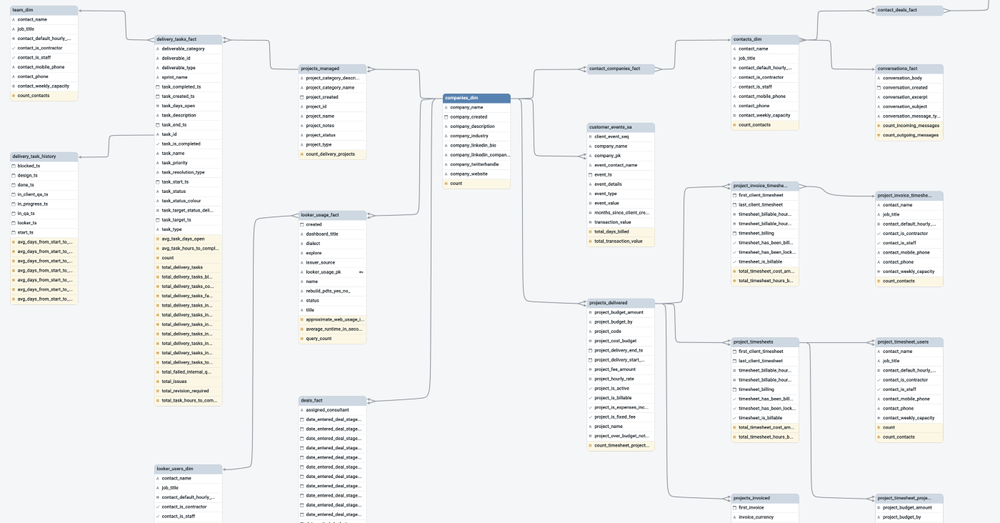
Аналогичным образом наше исследование в Looker для контактных лиц сводит воедино информацию обо всей активности контактного лица, даже если за время работы с нами оно выступало от имени разных компаний.

Наряду со структурированием и объединением данных о клиентах и контактных лицах для анализа в Looker, мы используем эти наборы данных и для другой аналитики: например, мы рассчитываем валовый и чистый доход от клиента по всем каналам обслуживания. Кроме того, мы оцениваем потенциальное влияние того или иного контактного лица при участии в переговорах о потенциальной сделке — для этого мы проводим количественную оценку взаимодействия такого лица с нашей командой, применяем Looker (а именно — новые возможности интеграции Stitch: для метаданных и для данных об использовании сервисов) и, наконец, смотрим, с каким количеством потенциальных сделок было связано такое лицо и сколько из них было успешно заключено.

Аналитические выводы такого рода полезно иметь на информационной панели Looker, однако еще полезнее они становятся при синхронизации с инструментами, которыми пользуются наши менеджеры по продажам и работе с клиентами: например, Hubspot.
«Обратный ETL» с помощью Hightouch
Хотя сервисы вроде Hubspot и Salesforce имеют публичные API, позволяющие обновлять сведения о клиентах и контактных лицах данными из хранилища, обычно для этого требуется специальная интеграция и дальнейшая поддержка при внесении изменений в спецификацию API (в случае Hubspot — весьма частая).
Такие сервисы, как Stitch и Fivetran, позволяют легко настроить конвейеры для извлечения, преобразования и загрузки данных (англ. Extract, Transform, Load — ETL) из приложений SaaS. Также существует новая категория сервисов, обеспечивающих «обратный ETL» (например, Hightouch и Census), которые позволяют без труда передавать аналитические данные о клиентах (и не только) из хранилища в использующие его приложения SaaS, например Hubspot, Facebook Audiences или Salesforce.

Чтобы синхронизировать с CRM-системой Hubspot свойства контактных лиц, оказывающих влияние на сделки, сначала нужно определить запрос в хранилище данных BigQuery, который будет возвращать набор контактов с уникальными идентификаторами Hubspot и значениями свойств, которые нужно синхронизировать с Hubspot.

Перед этим я настроил соединение с BigQuery и нашим хранилищем данных на облачной платформе Google Cloud Platform. Также возможны соединения с Teradata, Snowflake, MySQL и различными популярными хранилищами данных в облаке.
В качестве точек назначения поддерживаются распространенные рекламные сети (Google Ads, Facebook Custom Audiences и др.) и маркетинговые приложения SaaS (Marketo, Salesforce Marketing Cloud, Hubspot и т. п.).

Если вы попробуете передавать новые данные свойств клиентов в Salesforce или Hubspot из таких сервисов, как Segment Personas, то быстро обнаружите, что при постоянном устаревании документации и изменениях API успех будет весьма неустойчивым. В то же время сервисы обратного ETL, такие как Hightouch, делают эту задачу удивительно простой: в них реализован гибкий выбор свойств контактного лица для объединения входящих записей, а также они позволяют заполнять стандартные и кастомные свойства (если таковые заранее созданы), выбирая столбцы в выводе запросов при помощи выпадающих списков.
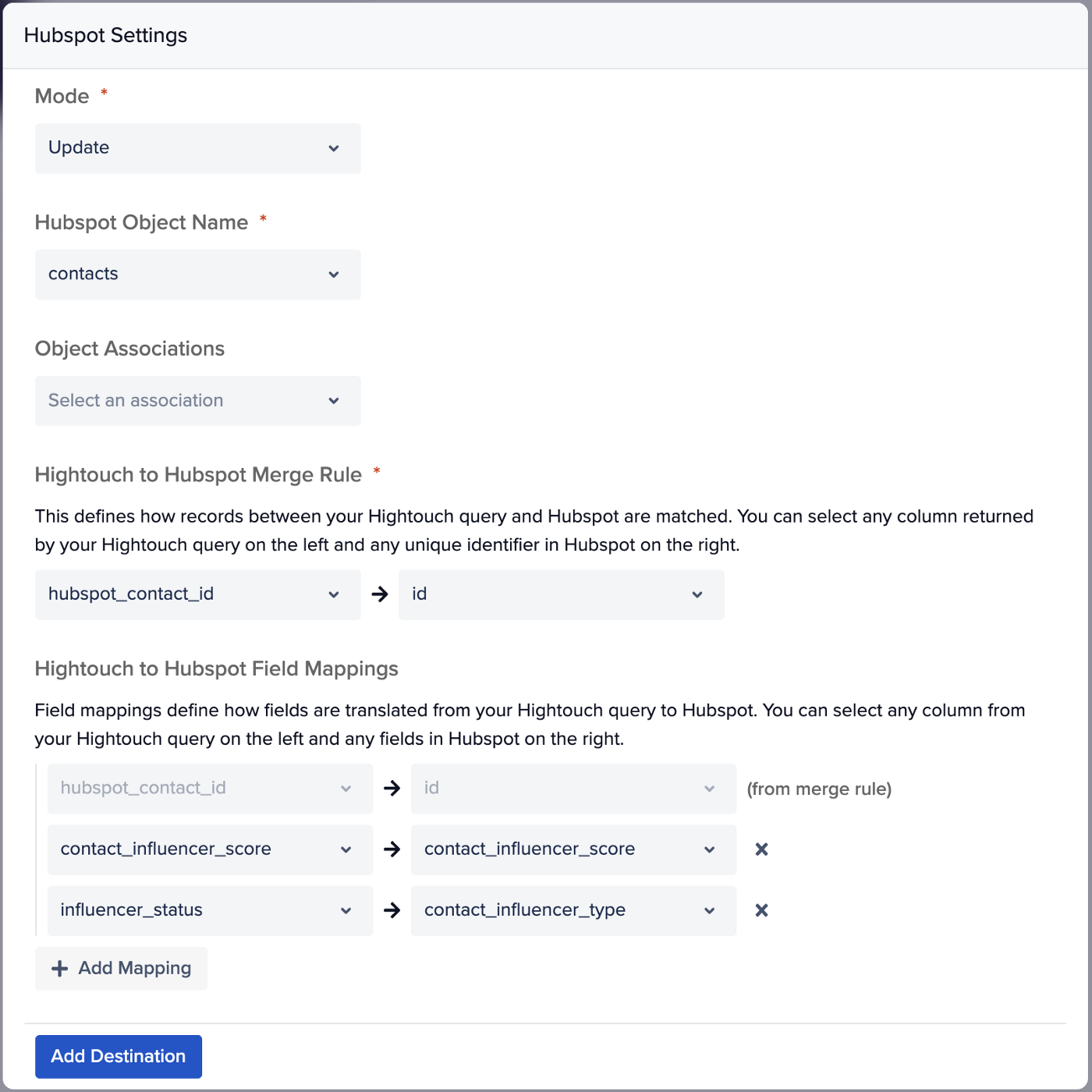
Далее я определяю, какие триггеры должны активировать синхронизацию средствами Hightouch между моим хранилищем клиентских данных и Hubspot. В данном случае имеет смысл выполнять синхронизацию при завершении задания dbt, так что сначала я регистрирую ключ API для нашей учетной записи dbtCloud, а затем задаю в настройках завершение определенного задания dbtCloud в качестве триггера для синхронизации.

Затем я запускаю задание dbt для пробы и вижу, что Hightouch реплицировал рейтинги влияющих на принятие решений контактных лиц из таблиц хранилища данных, которые были заполнены с помощью dbt.
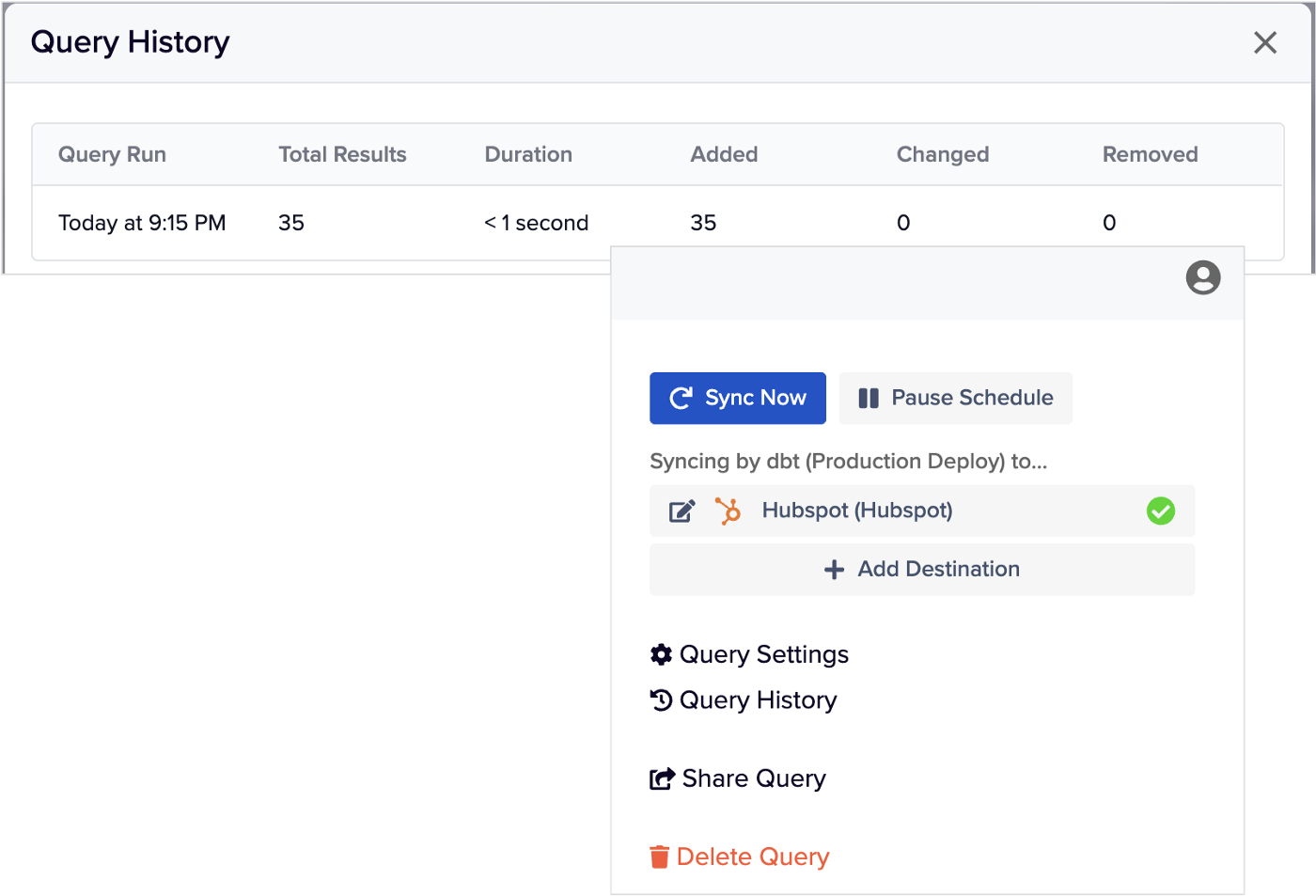
Наконец, когда я проверяю Hubspot, то вижу, что в соответствующие записи о контактных лицах добавились два новых свойства.

Аналогичным образом можно настроить синхронизацию данных на уровне компаний, включая данные, которые обычно недоступны в записях Hubspot как значения свойств, — например, валовую и чистую прибыль по счетам клиента.

Перевод статьи подготовлен в преддверии старта курса "Data Warehouse Analyst". Всех, кто желает подробнее узнать о курсе, приглашаем записаться на бесплатный вебинар, который состоится 28 июля. В рамках вебинара вы подробно узнаете о программе курса и процессе обучения, а также сможете задать вопросы нашим экспертам.
