В предыдущей статье я обозначил некоторые плюсы декларативного описания реляционных структур данных в web-приложениях с "WordPress-философией" (слабонагруженные, модульные, с единой БД). В этой статье я рассматриваю экспериментальную реализацию данного подхода. Сразу предупреждаю, что это не готовый рецепт того, как нужно делать (пусть даже и с моей точки зрения), а, скорее, публичные размышления. Ну нравится мне размышлять вслух, не пинайте сильно.
Реализуемая в приложении задача высосана из вакуума и практической пользы не имеет. Само приложение состоит из трёх npm-пакетов: основного и двух зависимых. Каждый пакет декларирует свою собственную структуру данных в JSON-формате. Основное приложение создаёт в двух различных базах данных две различные структуры, комбинируя свою собственную декларацию и декларацию из соответствующего пакета (own + pack1 & own + pack2). Совмещение различных фрагментов в общую структуру является типовой задачей модульных приложений с единой БД. Эту задачу я и рассматриваю ниже.
Пакеты приложения
- habr_dem_app: основное приложение;
- habr_dem_user_link: пакет для аутентификации пользователей по email-ссылке;
- habr_dem_user_pwd: пакет для аутентификации пользователей по паролю;
В общем случае в экосистеме некоторой платформы (например, WordPress) существует множество пакетов (модулей) с похожим функционалом (например, регистрация и аутентификация пользователей). Разработчик приложения (интегратор) из множества доступных выбирает пакеты, согласно реализуемой бизнес-задаче. В своём примере я взял два однотипных пакета (аутентификация пользователей), чтобы в рамках одного демо-приложения исследовать возможности совмещения основного фрагмента схемы данных с фрагментами схемы данных двух зависимых пакетов, вместо того, чтобы делать два разных демо-приложения. Структуры данных вне рамок данной статьи практического применения не имеют, не стоит относиться к ним слишком серьёзно.
habr_dem_app
Головное приложение представляет из себя "адресную книгу" — сохраняет в базе адреса для пользователей (один пользователь может иметь более одного адреса):
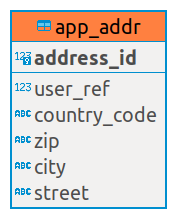
habr_dem_user_link
Пакет аутентифицирует клиентов по одноразовым ссылкам, отправляемым на соответствующий email:

habr_dem_user_pwd
Классическая аутентификация "login — password":

Конечные структуры данных
В итоге приложение должно строить в двух разных базах данных вот такие схемы:

Namespaces
В базах данных, состоящих из сотен таблиц, применяется естественная группировка таблиц при помощи правил наименования (см. пункт "Группировка таблиц"). Это очень сильно перекликается с тем, как адресуются папки и файлы в файловой системе:
name_of_the_table => /name/of/the/table
"Файловый" подход применим и к группировке и наименованию таблиц. Все таблицы (сущности) можно распределить по иерархии пакетов точно так же, как файлы распределяются по иерархии папок:
{ "entity": { "user": {...} }, "package": { "user": { "entity": { "address": {...} }, "package": {...} } } }
Выше декларируются следующие сущности/таблицы:
- /user => user
- /user/address => user_address
Реестры и дополнения
Я рассматриваю данные в базах с точки зрения сущностей, их атрибутов и взаимосвязей между сущностями (отношений). Сущности — отражения объектов (пользователь, сессия, адрес). Атрибут — свойство объекта (имя, номер, временнАя метка). Отношение — связь между объектами. В базах данных это таблицы, столбцы, внешние ключи.
Мои рассуждения применяются к приложениям с единой базой данных. В подобных системах издревле используется практика присвоения сущностям целочисленных идентификаторов и использования этих идентификаторов для ссылки на экземпляры сущности. Практика настолько распространённая, что в некоторых СУБД есть даже специальный механизм для этого — автоинкремент.
В общем случае прямого соответствия между сущностями и таблицами нет — данные одной сущности могут быть разнесены по нескольким таблицам. Но среди этих таблиц есть одна, в которой идентификатор создаётся (если автоинкремент или последовательность) или задаётся (если первичный ключ — строка, как в случае с таблицами сессий), а есть таблицы в которых их первичные ключи ссылаются на основную таблицу.
Вот в этом примере данные по одной сущности хранятся в трёх разных таблицах. В рамках одного приложения такой подход кажется не слишком удачным, но если смотреть на приложение с точки зрения модульности, то может оказаться, что все три таблицы принадлежат к разным модулям и могут использоваться различными приложениями в разных комбинациях (person & name, person & age, person & name & age):

Таблица person является основной (я называю такие таблицы "реестрами"), а таблицы name и age ссылаются на реестр (я называю их "дополнениями").
Хоть, как я уже отметил выше, в общем случае атрибуты одной сущности предметной области могут быть "размазаны" по нескольким таблицам базы, тем не менее в JSON-декларациях примера соответствие однозначное — одна entity в декларации соответствует одной table в базе.
Идентификаторы и ссылки
При связывании таблиц через внешние ключи типы столбцов разных таблиц, участвующих в создании ключа, должны совпадать по типам. Как я уже отметил выше, в качестве идентификатора сущности зачастую применяется беззнаковое целое с автоинкрементом. К тому же столбец-идентификатор становится первичным ключом. В декларативное описание просто просится отдельный тип для подобных идентификаторов и ещё один тип для столбцов, ссылающихся на столбцы-идентификаторы — id и ref. id-столбцы находятся в таблицах-реестрах, а ref-столбцы используются для связывания данных в таблицах-дополнениях.
Декларация зависимости
Итоговая схема данных собирается из фрагментов. Таблицы внутри отдельного фрагмента могут ссылаться на другие таблицы этого же фрагмента, а могут ссылаться на какие-то внешние таблицы (как правило, реестры), находящиеся в других фрагментах:
{ "package": { "app": { "entity": { "addr": { "attr": { "user_ref": {"type": "ref"} ... }, "relation": { "user": { "attrs": ["user_ref"], "ref": { "path": "/path/to/user/registry", "attrs": ["identity"] } } } } } } } }
Каждый фрагмент, в котором есть завязки на внешние таблицы, декларирует подобные завязки в отдельном узле refs на самом верхнем уровне:
{ "package": { "app": { "entity": { "addr": {...} } } }, "refs": { "/path/to/user/registry": ["identity"] } }
В узле refs описывается путь к таблице, не входящей в данный фрагмент, и имена столбцов этой внешней таблицы, участвующие в составлении внешних ключей. Это не должны быть реальные имена внешней таблицы и её столбцов, это, скорее, алиасы, используемые в данном фрагменте декларации.
Разрешение зависимостей
При сборке всех фрагментов схемы данных воедино в рамках приложения, интегратор создаёт карту сопоставления зависимостей, используемым во фрагментах, реальным таблицам. В рассматриваемом примере декларация схемы для habr_dem_app содержит внешнюю зависимость:
{ "refs": { "/path/to/user/registry": ["identity"] } }
и две различные карты сопоставления — для схемы с применением модуля habr_dem_user_link:
{ "/path/to/user/registry": { "path": "/user", "attrs": { "identity": "id" } } }
и для схемы с применением модуля habr_dem_user_pwd:
{ "/path/to/user/registry": { "path": "/login", "attrs": { "identity": "login_id" } } }
Итоговое описание схемы данных
Я не даю описание формата декларирования схемы данных и карты сопоставления внешних связей — он очень сырой и годится только для демонстрации идеи. Надеюсь лишь, что получилось не слишком сложно и что вышесказанного будет достаточно для чтения соответствующих деклараций.
- схема данных пакета
@flancer64/habr_dem_app - схема данных пакета
@flancer64/habr_dem_user_link - схема данных пакета
@flancer64/habr_dem_user_pwd - карта сопоставления для связывания схемы
habr_dem_appсо схемойhabr_dem_user_link - карта сопоставления для связывания схемы
habr_dem_appсо схемойhabr_dem_user_pwd
Пример рабочий (по крайней мере, на моей локалке) и демонстрирует идею составления единой схемы данных из JSON-фрагментов. Даже двух единых схем данных из трёх фрагментов:
$ git clone git@github.com:flancer64/habr_dem_app.git $ cd ./habr_dem_app $ npm install $ cd ./cfg $ cp init.json local.json $ nano local.json // set parameters to connect to DBs $ npm run schema
Резюме
Лично мне введение дополнительного уровня абстракции в виде декларативного описания схем данных кажется достаточно перспективным для применения в платформах с "WordPress-философией" (такой, как Magento). Схемы данных в форматах, более удобных для программного разбора, чем SQL, позволяют проще анализировать как отдельные фрагменты общей схемы, так и всю общую схему целиком на предмет консистентности, облегчают сравнение различных версий одной схемы данных. Ещё большее отстранение от СУБД, чем даже уровень ORM/DBAL позволяют сосредоточиться на логической структуре данных (сущности, атрибуты, связи), а не на уровне хранения данных, что облегчает разработчикам восприятие схем данных.
Да, подход не универсальный, со своей, достаточно узкой, нишей, тем не менее, в этой узкой нише я вижу, что у данного подхода есть некоторый потенциал. С интересом ознакомлюсь с альтернативными реализациями данного подхода (или похожих), если на них будут ссылки в комментах.

