

Привет, Хабр. Меня зовут Наиль, я работаю unix-инженером в МегаФоне в IT-инфраструктуре. На работе администрирую высоконагруженные IT-платформы на базе операционной системы Linux и часто занимаюсь диагностикой и траблшутингом инцидентов, связанных с утилизацией серверных процессоров (CPU) и памяти (RAM and SWAP).
Ключевым моментом при проведении технической диагностики при траблшутинге обычно является анализ системных логов и данных систем мониторинга, таких как Zabbix, Nagios или некоторых предварительно настроенных узкоспециализированных метрик в дашбордах Grafana. Появление в логах ошибок вида "Сannot allocate memory", "kernel: Out of memory: Kill process ID", «kernel: segfault» и аналогичных требует проведения тщательного анализа причин, которые привели к их появлению, и незамедлительной выработки мер для исключения их влияния на предоставляемый сервис.

Не секрет, что для анализа текущей утилизации CPU, RAM и SWAP на серверах с ОС Linux мы можем воспользоваться консольными утилитами top (htop), ps, iostat, pidstat, mpstat, iotop и другими, позволяющими мониторить производительность сервера в настоящий момент времени.
Но часто при проведении такого анализа возникает вопрос, как же посмотреть данные о загруженности сервера спустя какое-то время после инцидента, например, спустя сутки или спустя неделю в период с 03:00 по 03:30 ночи? Тут нам на помощь приходит известная утилита для мониторинга производительности sar, являющаяся частью пакета sysstat. Ее можно использовать для просмотра данных производительности в заданных промежутках времени в течение месяца. Sar предоставляет широкие возможности для анализа, сохраняя данные в лог-файлы, и производит необходимую ротацию логов собственными средствами, но, к сожалению, несмотря на весь свой богатый функционал, sar не дает возможность анализировать утилизацию CPU, RAM и SWAP по отдельному процессу или по нескольким при необходимости.
Дополнительно отмечу и пакет atop. Вот он как раз умеет хранить логи по отдельным процессам и предоставляет просмотр этих данных через свою встроенную штатную утилиту atopsar. На первый взгляд, этот инструмент должен идеально решить поставленную задачу. Однако из-за того, что логи хранятся в бинарном виде и есть ограничения по выборке количества топ-процессов при диагностике - использование этого инструмента в высоконагруженных системах оказалось проблематичным.

Именно это и послужило мотивом для разработки вспомогательного механизма, позволяющего выполнить логирование необходимых нам данных в автоматическом режиме, но уже с уклоном на отдельные процессы и с последующей ротацией собранных логов. Практика использования скриптов в качестве средств автоматизации каких-либо задач далеко не нова и в нашем случае позволяет гибко построить и сам процесс сбора данных с их записью в лог-файл, и сделать выборку именно тех данных, которые наиболее информативны.

Хочу сразу отметить, что на всех этапах разработки, помимо обязательного тестирования промежуточных результатов, всегда происходит обсуждение практически любого принимаемого решения с коллегами, они могут находиться в разных городах, но при этом сплочены едиными интересами, компетенциями и задачами в рамках компании. В процессе обсуждения выслушиваются и проверяются любые предлагаемые решения, они проходят с жаркими спорами, с критическим анализом, с замечаниями «по сути», дружескими шутками и не без ошибочных предположений с тупиковыми направлениями. Все это помогает максимально снизить вероятность ошибки при разработке и максимально точно решить проблему или поставленную задачу.
И так, после трёх или четырёх моих аудитов по производительности и неосторожного вброса “хорошо бы иметь данные по отдельным процессам за длительный период” началось... Сперва в Jira прилетает задача «Разработка и внедрение логирования производительности по отдельным процессам», после уже читаю в переписке: «давай подключайся к обсуждению задачи».
Итак, поехали...
День первый.

8:30. Начало рабочего дня. Еще работаю на удаленке, а в офис то хочется, оказывается, спустя год дистанса, эх. Подключаюсь к своему рабочему месту. Разгребаю корпоративную почту и вопросы в чате.
9:30. Задачи в Jira. Проверяю результат начатой вчера под конец рабочего дня «сборки» виртуального сервера для тестирования, версию ОС и необходимые установленные пакеты...
11:00. Обсуждение насущных текущих проблем сообществом.
12:00. Ну вот, наконец то и дошли руки до погружения в обсуждение задачи по логированию. Так, на первом этапе договариваемся протестировать и выбрать какой пишем скрипт: bash или с использованием python и распределяем по коллегам что и когда делаем.
13:00. Обед.
13:45. Совещаемся по выполнению текущих спринтов с разработчиками Linux Server Update Services (LSUS) в условиях работы сегмента.
14:30. В корпоративную переписку по нашей теме коллеги уже начали скидывать примеры команд для получения интересующих нас данных по утилизации процессами памяти и CPU. Вот это уже можно использовать и поэтому сразу же на тестовым сервере, собранном под эту задачу делаю заготовку скрипта bash:
#!/bin/bash echo "$(date '+%Y-%m-%d %H:%M:%S') -----TOP-RSS---------------------------" >> ~/cpumemusage.log ps -eo uid,pid,comm,command,vsz,rss --sort -rss |grep -v "0 0" | head -n 50 >> ~/cpumemusage.log echo "$(date '+%Y-%m-%d %H:%M:%S') -----TOP-SWAP--------------------------" >> ~/cpumemusage.log for file in /proc/*/status ; do awk '/VmSwap|Name/{printf $2 " " $3}END{ print ""}' $file; done | sort -k 2 -n -r | head -n 10 >> ~/cpumemusage.log echo "$(date '+%Y-%m-%d %H:%M:%S') ------ERROR-PAGE-----------------------------" >> ~/cpumemusage.log pidstat -r 60 1 |grep -E -v "^$" |grep -E -v "Linux|Average" |sort -r -h -k 9 >> ~/cpumemusage.log echo "$(date '+%Y-%m-%d %H:%M:%S') ------TOP-CPU-----------------------------" >> ~/cpumemusage.log pidstat -u 60 1 |grep -E -v "^$" |grep -E -v "Linux|Average" |sort -r -h -k 5 >> ~/cpumemusage.log echo "$(date '+%Y-%m-%d %H:%M:%S') ------TOP-CPU-----------------------------" >> ~/cpumemusage.log mpstat -P ALL 60 1 |grep -E -v "^$" |grep -E -v "Linux|Average" >> ~/cpumemusage.log
Время выполнения скрипта с предложенными коллегами командами по сбору интересующих данных составило:
# time ./cpumemusage.sh real 3m0.447s user 0m0.164s sys 0m0.323s
и получаю первые результаты сбора данных в log-файле в виде:
# cat ~/cpumemusage.log 2021-02-25 16:23:16 -----TOP-RSS--------------------------- UID PID COMMAND COMMAND VSZ RSS ... 2021-02-25 16:23:16 -----TOP-SWAP-------------------------- ... 2021-02-25 16:23:17 ------ERROR-PAGE----------------------------- ... 04:23:17 PM UID PID minflt/s majflt/s VSZ RSS %MEM Command 2021-02-25 16:24:17 ------TOP-CPU-1---------------------------- ... 04:24:17 PM UID PID %usr %system %guest %CPU CPU Command 2021-02-25 16:25:17 ------TOP-CPU-2----------------------------
Примечание: полный лог, полученный в результате выполнения скрипта в статье не присутствует, так как не несет в себе особого смысла для ее содержания. Если у кого-то появится интерес, то он с легкостью сможет воспроизвести эти результаты.
15:30. Закидываю все полученные результаты в переписку для обсуждения. А пока переключаюсь на другие задачи…
17:30. Ну вот и первые комментарии появились…

# ~/PycharmProjects/process-mon $ time sudo python3 main.py > ~/test-psutil.txt 2>&1 real 0m1.182s user 0m0.406s sys 0m0.171s»
Сразу смотрю ~/test-psutil.txt…
Время выполнения конечно существенно меньше оказалось, но это лишь одна небольшая выборка данных и полученная без использования фильтров. Вижу, что в целом, получился интересный результат и можно развивать это направление…
Помечаю себе в Jira - «обсудить на собрании и выбрать, что будем использовать для разработки».
Подвожу итог: на первом этапе после сборки и анализа первичных результатов стала уже понемногу вырисоваться ситуация и появились первые контуры будущего скрипта. Ставлю пометки, что следует продолжить из начатого, но продолжу, видимо, уже после своего завтрашнего дежурства в своем сегменте…
18:00. Закончен рабочий день.
День второй.
8:30. Утро. Кофе. Вливаюсь в работу после суточного дежурства и небольшого отдыха. Корпоративная почта. Вопросы в чате. Задачи в Jira. Разгребаю накопившееся. Одновременно прорабатываю текущую работу и подаю заявку «презентовать» сетевой диск для нового сервера, не отключая его от старого, указываю WWN в заявке и другие необходимые технические параметры.
10.30. Короткое совещание по выбору пути разработки скрипта.
Решение: идем путем написания скрипта на bash. По совету коллег добавляю к предыдущему bash-скрипту понижение приоритета «nice -n 15» и вставляю блок кода для запрета одновременного запуска скрипта через проверку по lock-файлу:
###### # Lock file LOCKFILE="/var/run/cpumemusage.sh.lock" if test -f ${LOCKFILE} then echo "Script /cpumemusage.sh already runing!!!" 1>&2 exit 1 else touch ${LOCKFILE} fi
и в конце
###### # Clear lock file and exit rm -f ${LOCKFILE} exit 0
Время, затраченное на выполнение скрипта, стало:
# time ./cpumemusage.sh real 3m0.464s user 0m0.166s sys 0m0.334s
Сразу видно, что скрипт отрабатывает очень долго и надо как-то его ускорять. Три минуты на выполнение, и это на сервере, где процессов совсем немного. На «тяжелых» же серверах будет все печальнее. Полагаю, что все команды надо, наверное, запускать параллельно, а то как минимум три из них последовательно по 60 сек отрабатываются. Например, чтоб писалось во временные файлы, а потом уже по итогу из временных файлов в один общий лог собирать.
11:00. Отправляю результаты на обсуждение коллегам с запросом на распараллеливание выполнения команд и прошу выделить «тяжелый» сервер для тестирования скрипта по времени выполнения и определения приблизительного размера получаемого лога за один «прогон» скрипта.
И пока идет обсуждение, переключаюсь на текущую задачу по изменению конфигурации группы серверов с перерывом на обед.
15:00. Итак, сервер выделили - там под 8к процессов и есть какая-то на нем нагрузка, LA (load average) больше 100. Это то, что надо. Сразу же приступаю к тестированию. Средние результаты после нескольких прогонов получены такие:
# time ./cpumemusage.sh real 3m19.362s user 0m6.186s sys 0m14.281s # cat cpumemusage.log | wc -l 12341
16:00. Итог: видно, что в пределах 4 минут пока укладываемся, но нужно все равно попробовать «распараллелить». Этим, собственно, и планирую заняться, записываю в план дальнейших работ. Сразу дополнительно отмечаю необходимость реализации еще несколько поступивших предложений:
Плюс, дополнительно подсчитываю размер итогового log-файла. За три запуска скрипта файл с логом cpumemusage.log стал весить:
# du -chsx ~/* |sort -hr | grep cpumemusage.log 1.1M cpumemusage.log
17:00. Подвожу итоги рабочего дня и анализирую новые полученные результаты:

17:30. На сегодня хватит. Отключаюсь от своего рабочего места и быстро опустошаю холодильник от заготовленных заранее бутербродов с чашечкой вкусного кофе.
День третий.
8:30. Новый день. Кофе бодрит даже своим ароматом.
9:00. Почта, чат, Jira.
10:00. Обсуждение маршрутизации по подразделениям при отработке инцидентов.
10:30. В переписке появилось предложение внести еще дополнение и использовать все-таки logrotate с ротацией log-файла по его размеру.

Спасибо, полезное дополнение, позволит избежать проблем с переполнением lvm-раздела /var/log. Беру в работу. Проверяю готовность ранее поданной заявки «презентовать сетевой диск» для вводимого в эксплуатацию нового «железного» сервера. Увы, пока ждем. И это дает возможность продолжить разработку скрипта логирования.
Добавляю в скрипт блок кода для проверки свободного места в /var/log и тестирую:
###### # Test free space /var/log aa=$(df -hTm /var | grep var | awk '{print $5}') if [[ $aa -lt 500 ]] then echo "There is no free space in the section /var/log for the cpumemusage.sh" 1>&2 exit 1 fi
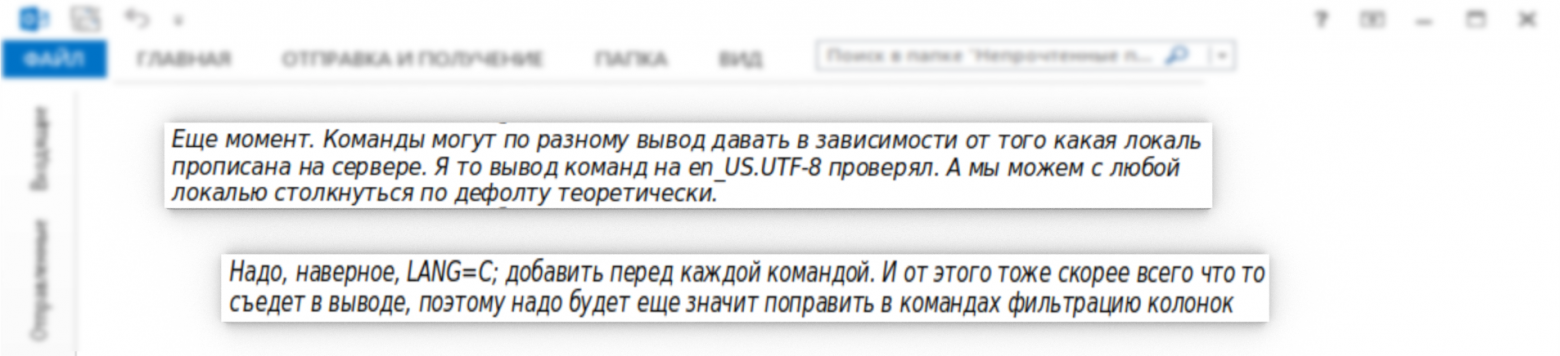
Успешно. Приступаю к распараллеливанию для снижения общего времени выполнения скрипта. Для этих целей обычно используются два подхода: использование пакета parallel и пакета xargs. Первый путь предполагает согласование и установку утилиты parallel, специально предназначенной для решения таких задач и лишенной некоторых существенных недостатков, присущих второму варианту. Второй же вариант с утилитой xargs не предполагает ее установку, утилита входит в стандартный набор устанавливаемого ПО и поэтому этот вариант выглядит наиболее перспективным для тестирования.
Протестированные команды для получения необходимых данных оборачиваю в функции и создаю список из них для формирования списка аргументов для выполнения xargs, не забыв выполнить экспорт.
###### # Analysis RSS() { nice -n 15 ps -eo uid,pid,comm,command,vsz,rss --sort -rss |grep -v "0 0" | head -n 50 #| sed 's/ -/rrrrqq/g' | sed 's/ \//rrrrww/g' | column -t | sed 's/rrrrqq/ -/g' | sed 's/rrrrww/ \//g' } SWAP() { for file in /proc/*/status ; do awk '/VmSwap|Name/{printf $2 " " $3}END{ print ""}' $file; done | sort -k 2 -n -r | head -n 10 | column -t } PAGE() { nice -n 15 pidstat -r 60 1 |grep -E -v "^$" |grep -E -v "Linux|Average" |sort -r -h -k 9 | column -t } CPU1() { nice -n 15 pidstat -u 60 1 |grep -E -v "^$" |grep -E -v "Linux|Average" |sort -r -h -k 5 | column -t } CPU2() { LANG=C; nice -n 15 mpstat -P ALL 60 1 |grep -E -v "^$" |grep -E -v "Linux|Average" | column -t } ###### # Writing to a file dir=$(cat <<EOF RSS PAGE CPU1 CPU2 SWAP EOF ) export -f "RSS"; export -f "SWAP"; export -f "PAGE"; export -f "CPU1"; export -f "CPU2" echo $dir | xargs -n 1 -P 4 bash -c >> $FILE
Распараллеливание процессов настраиваю в 4 потока (xargs -n 1 -P 4). При распараллеливании по потокам время выполнения скрипта сразу сократилось до 0,417 сек.
# time ./cpumemusage.sh real 1m0.086s user 0m0.177s sys 0m0.417s
Временно убираю в получаемом логе названия результатов выполнения команд из-за их рандомного вывода. С этим придется основательно покопаться в дальнейшем. В целом, получен неплохой результат.
16:30. Скидываю все полученные данные на этот момент в переписку для обсуждения коллегам для отзывов и новых предложений и перехожу к настройке logrotate. Создаю файл с настройками ротации нашего скрипта:
# vi /etc/logrotate.d/cpumemusage
/var/log/cpumemusage.log { compress create 0644 root root dateext dateformat -%Y%m%d delaycompress missingok nocopytruncate notifempty rotate 5 size 200M }
Это означает, что будет использовано:
сжатие кроме последнего и предпоследнего файла;
владельцем станет root с правами 0644;
в название файла будет добавлена дата ротации в формате %Y%m%d;
не будет регистрироваться ошибок при отсутствии лог-файла;
минимальный размер файла для ротации 200 мегабайт;
будем хранить 5 логов;
в процессе ротации будет выполнено переименование старого лога и создание нового, но ротация не произойдет, если файл лога пуст.
Тестирую.19:00. На сегодня всё. Подвожу итоги и отключаюсь от своего рабочего места.
Шел день четвертый.
8:30. Подключаюсь к рабочему месту, регистрируюсь. Быстро проверяю переписку и новые поступившие задачи в Jira.
9:30. Отчет.
10:00. Возвращаю в скрипт вывод в лог названий результатов выполнения команд, использовав логический элемент «И» (&&). На первый взгляд такая конструкция кажется правильной.
10:30. Проверяю заявку на презентацию диска. Пишут, что готова.
Проверяю, выполнив рескан ./rescan-scsi-bus.sh, и наличие путей к диску multipath -ll. Все отлично, сетевой диск виден, заявку закрываю со словами «Спасибо». Подготовка к замене сервера проведена и можно заводить плановые работы по замене сервера на следующем этапе.
11:00. Из переписки узнаю, что коллегами подготовлен новый класс в puppet для ротации логов для разрабатываемого скрипта со вчерашними директивами и предложение «раскатать» и протестировать полученный скрипт на выборке серверов из тестовой хостгруппы и вынести его на обсуждение коллегам.
11:20. Отлично, значит делаю следующий шаг, переношу скрипт в GIT в ветку develop и создаю запрос для merge для распространения скрипта по серверам тестовой хостгруппы сегмента. Одновременно при подаче такого запроса происходит публикация скрипта для всей it-инфраструктуры домена перед мерджем и его апробация.
Дополнительно подсвечиваем и задаем вопрос в общем IT-чате для обсуждений.
Список вопросов и дополнений не заставил себя ждать:
1. дополнение по подписям комментариев;
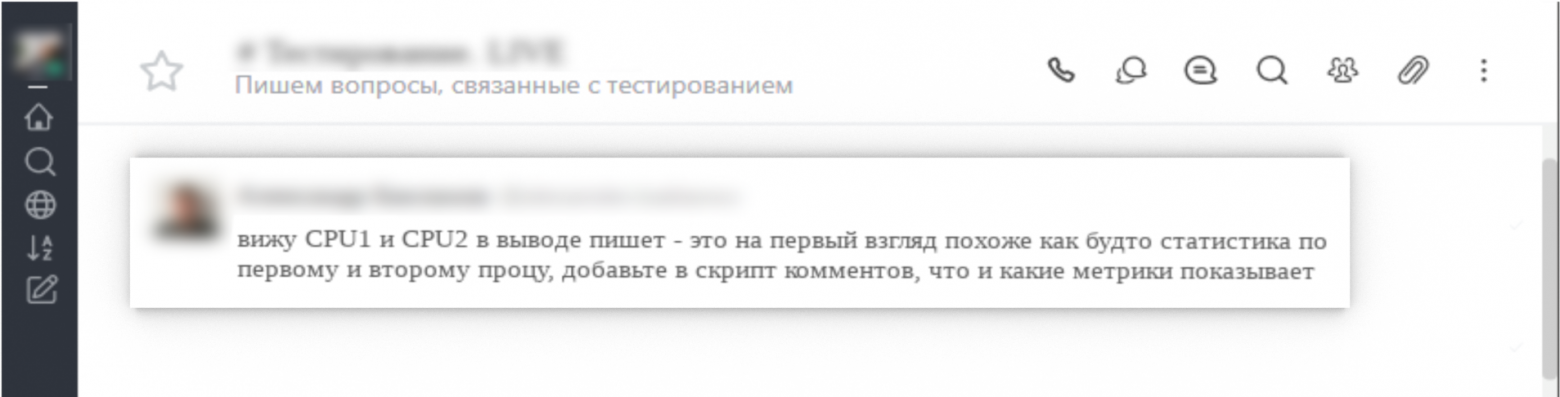
2. предложение по column -t;

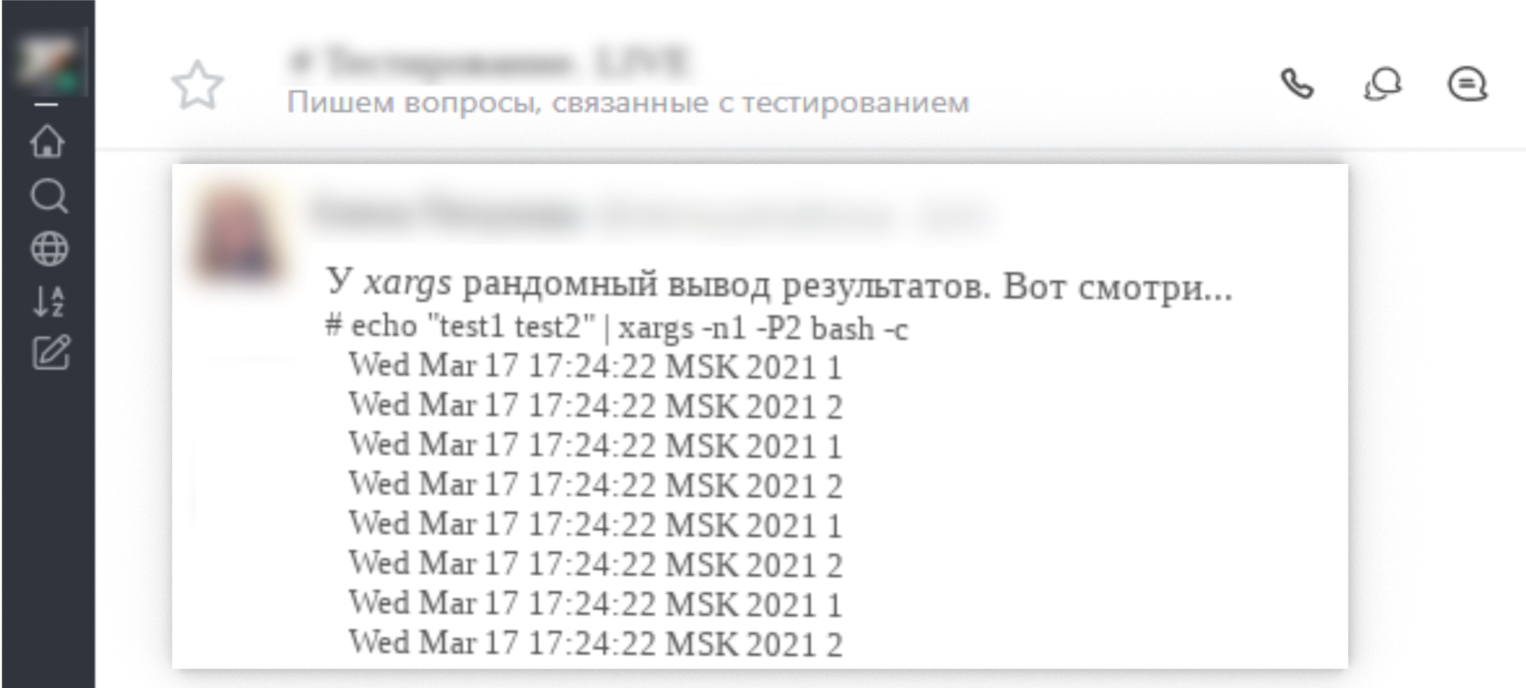
3. замечание с примером рандомного вывода результатов команд в скрипте при использовании xargs;
4. предложение использовать parallel как вариант для решения рандомного вывода xargs.
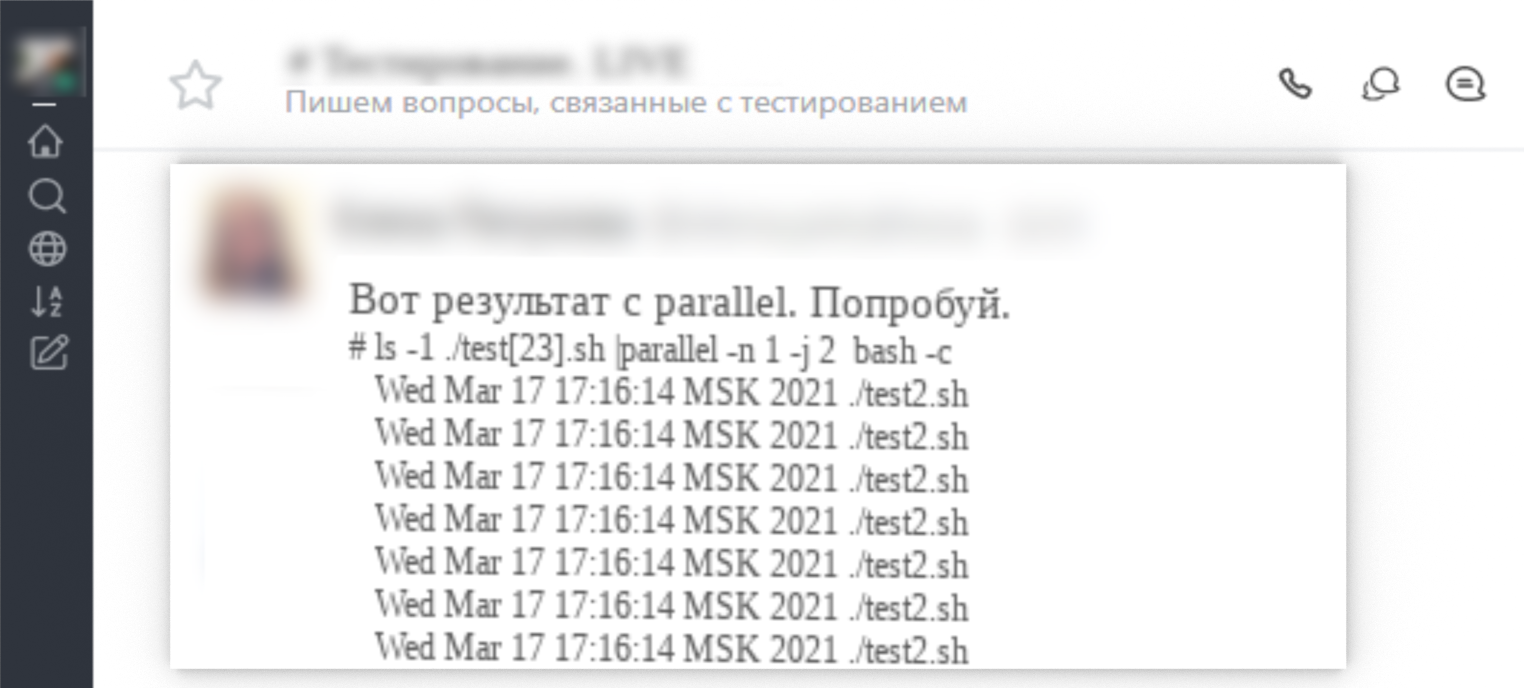
12:00. Фиксирую все предложенные правки и замечания и стучусь в «личку» к каждому автору замечаний для обсуждения по каждому пункту и заданным вопросам. Поиск решения по рандомному выводу. Обедаю «на ходу» без отрыва от процесса.
15:00. Собрание подразделения. Еженедельный отчет и постановка задач для выполнения.
16:00-22:30. Поиск решения по упорядочиванию рандомного вывода xargs. Кофе, печеньки, снова кофе, бутерброды…и опять кофе.
Но ничего не помогает, xargs упорно меняет местами шапки для выводов на длинной выборке данных и аккумулирует их в зависимости от затраченного времени на выполнение команд.
В общем, за несколько часов наперебирался разных вариантов по упорядочиванию вывода данных в лог до нервного тика. Стало даже уже казаться, что действительно выбран ошибочный путь. И как всегда - только-только начинают покидать силы и уверенность, что правильное решение будет найдено и ... - бац, успех, находится верное решение! Ну вот же, можно же «склеить» две переменные - конкатенация! Эх, как же я мог забыть?!
Быстро подправляю скрипт и вот он «красивый» лог с упорядоченными комментариями к выводам команд.
Профит!
23:30. Отключаюсь от рабочего места. Все остальное «причешу» уже завтра. Еще долго перебираю в голове разные варианты реализации, пытаясь заснуть.
В заключение.
Остальное «дело техники»: merge, наблюдение за работой скрипта и формирование лога в тестовой хостгруппе на протяжении определенного периода времени. Далее тестирование в предпродовой среде с повышенными нагрузочными характеристиками и затем уже внедрение в production с высоконагруженными платформами.
Забегая вперед, скрипт был успешно протестирован на серверах тестовой хостгруппы и внедрен в production-среде. Мы уже неоднократно обращались к формируемому логу для анализа различных инцидентов. Модульная схема получения данных, реализованная в скрипте, позволила с легкостью добавить еще несколько полезных выборок интересных нам показателей, необходимых для проведения анализа.
Для тех, кто осилил этот текст до конца - скрипт (под спойлером) для тестовой хостгруппы, надеюсь, будет отличным началом для внедрения аналогичных решений вспомогательной автоматизации для высоконагруженных ИТ-платформ, и вы сможете найти свое собственное оптимальное решение.
bash-скрипт
#!/bin/bash ###### # Set PATH export PATH="$PATH:/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin" ###### # Constans FILE='/var/log/cpumemusage.log' ###### # Test free space /var/log space=$(df -hTm /var | grep var | awk '{print $5}') if [[ $space -lt 500 ]] then echo "There is no free space in the section /var/log for the cpumemusage.sh!!!" 1>&2 exit 1 fi ###### # Lock file LOCKFILE="/var/run/cpumemusage.sh.lock" if test -f ${LOCKFILE} then echo "Script /cpumemusage.sh already runing!!!" 1>&2 exit 1 else touch ${LOCKFILE} fi ###### # Header HEAD() { printf '\n' echo "*********************************************" echo "Date: $(date '+%Y-%m-%d %H:%M:%S')" echo "*********************************************" } ###### # Analysis-module RSS() { aa=$(echo "--------------- Start ps -eo uid,pid,comm,command,vsz,rss --sort -rss ---------------") aaa=$(LANG=C; nice -n 15 ps -eo uid,pid,comm,command,vsz,rss --sort -rss | grep -v "0 0" | head -n 50) echo -e "$aa\n$aaa" } SWAP() { bb=$(echo "--------------- Start Top processes using SWAP---------------------------------------") bbb=$(LANG=C; for file in /proc/*/status ; do awk '/VmSwap|Name/{printf $2 " " $3}END{ print ""}' "$file"; done | sort -k 2 -n -r | head -n 10 | column -t) echo -e "$bb\n$bbb" } PAGE() { cc=$(echo "--------------- Start pidstat -r 60 1 |sort -r -h -k 8 -------------------------------") ccc=$(LANG=C; nice -n 15 pidstat -r 60 1 | grep -E -v "^$" | grep -E -v "Linux|Average" | sort -r -h -k 8 | column -t) echo -e "$cc\n$ccc" } CPU1() { dd=$(echo "--------------- Start pidstat -u 60 1 | sort -r -h -k 7 ------------------------------") ddd=$(LANG=C; nice -n 15 pidstat -u 60 1 | grep -E -v "^$" | grep -E -v "Linux|Average" | sort -r -h -k 7 | column -t) echo -e "$dd\n$ddd" } CPU2() { ee=$(echo "--------------- Start mpstat -P ALL 60 1 --------------------------------------------") eee=$(LANG=C; nice -n 15 mpstat -P ALL 60 1 | grep -E -v "^$" | grep -E -v "Linux|Average" | column -t) echo -e "$ee\n$eee" } CPU3() { ff=$(echo "--------------- Start ps -eo uid,pid,comm,command,pcpu,psr --sort -pcpu --------------") fff=$(LANG=C; nice -n 15 ps -eo uid,pid,comm,pcpu,psr --sort -pcpu |grep -v "0.0" | head -n 50 | column -t) echo -e "$ff\n$fff" } IOTOP() { gg=$(echo "--------------- Start iotop -obt -n 1 ------------------------------------------------") ggg=$(LANG=C; nice -n 15 iotop -obt -n 1) echo -e "$gg\n$ggg" } ###### # Writing to a file dir=$(cat <<EOF RSS PAGE CPU1 CPU2 CPU3 SWAP IOTOP EOF ) HEAD >> $FILE export -f "RSS"; export -f "SWAP"; export -f "PAGE"; export -f "CPU1"; export -f "CPU2"; export -f "CPU3"; export -f "IOTOP" echo "$dir" | xargs -n 1 -P 4 bash -c >> $FILE ###### # Clear lock file and exit rm -f ${LOCKFILE} exit 0
P.S.: все картинки сделаны мной.
