Comments 52
Компилятор делает более оптимально, минимизируя циклы обращения к RAM.
Си же код записи алгоритма более подходит для «обобщённого» понимания записи алгоритма вне прямого акцентирования на потоке команд управления данными.
Как то так. ?
Честно говоря, я сомневаюсь, что на языке высокого уровня можно написать это более компактно и понятно.
Компактно - запросто. С "понятно" все сложнее, потому что это чисто субъективное понятие, которое полностью зависит от бэкграунда читающего. Например я чаще имею дело с армовским ассемблером и меня вымораживают названия регистров в x86.
Автор написал код на ассемблере, транслировал его в плюсы и получил нечитабельное нечто - вот так новость, видимо ассемблер самый понятный в мире язык. Вот, ловите нормальный код:
while ( !p->next && p->parent ) p = p->parent;
p = p->next ? p->next : p;
while ( p->f_child ) p = p->f_child;Ваш код не работает корректно если коренных узлов больше одного. То есть не эквивалентен C++ коду в статье.
Даже если не вариант сделать список корней кольцевым, то можно так:
while ( !p->next && p->parent ) p = p->parent;
if ( p->next ) p = p->next;
else
{
while ( p->prev ) p = p->prev;
}
while ( p->f_child ) p = p->f_child;Да, теперь все в порядке.
Но самое интересное, что теперь ваш код компилируется до абсолютно тех же самых инструкции как и мой C++ код.
Теперь надо только разобраться кто из них более удобочитаемый. :)
Этого не может быть. Нормальный компилятор как минимум заиспользует инструкцию test вместо cmp.
Удобочитаемый - тот, где путь выполнения выражен простыми для понимания конструкциями вроде цикла while. А не jmp и иди разбирайся куда оно там прыгает.
Если вам все еще интересна тема...
у меня, кажется, есть аргумент, которого я не увидел во всей дискуссии.
Я много и успешно(!) писал на разных ассемблерах в свое время, но, тем не менее, демонстрация кода на ассемблере вызывает у меня совершенно ненужное напряжение, по сути, расстраивает меня, потому что вы написали код на ассемблере который используется у вас(!), а мне чтобы использовать ваш код нужно будет переписать его на ассемблер, который поддерживает моя система- мой процессор, а он может быть 16-битный или 8-битный, или даже 64-х битный.
То есть причину очень просто понять если вы писали код не только на ассемблере для 32-битных процессоров, а еще для, например 8-битных процессоров, или хотя бы для 16-битных процессоров.
Удивительно что вам никто не привел этот аргумент! Удивительно как коротка память у целого сообщества, ведь язык С появился именно по этой причине: чтобы сделать код читаемым для людей которые работают на разных ассемблерах, на разном железе. Кстати, язык С появился, когда процессоры были в основном 8-битные!
Кстати, я не вижу признаков плюсов в вашем коде, это вполне плейн-С код.
По-моему, про то что язык С, а за ним С++ обладают преимуществом для понимания кода написанного на них перед любым ассемблером можно прочитать где-то в начале изложения основ в их стандартах, конечно при желании обращать внимание на эти основы. Собственно, все дело в том, что С/С++ это универсальный язык в отличие от любого конкретного ассемблера – универсального ассемблера не существует!
В этом смысле ваш вопрос является достаточно интересной провокацией, которая демонстрирует этот достаточно интересный эффект короткой памяти сообщества!
Я попробовал написать аналогичный код на kotlin (работоспособность не проверял, он больше для иллюстрации). Благодаря elvis оператору, nullable типам и хвостовой рекурсии выглядит сильно иначе. На мой взгляд, в таком декларативном стиле получается понятнее.
tailrec fun lastFChild(n: Node): Node =
n.fChild?.let{ lastFChild(it) } ?: n
fun Node.first(): Node =
prev?.first() ?: this
fun cycle(n: Node): Node =
n.next ?: n.parent?.let{ cycle(it) } ?: n.first()
fun Node.findNext(): Node =
lastFChild(cycle())
Кажется, если написать на С с использованием goto получится тоже самое, что на Асм?
Не понял посыла статьи: короткие алгоритмы можно писать без ограничений структурного программирования? Ну да, можно, пока их можно одним глазом видеть. Проблемы будут на алгоритмах больших.
В общем любопытно, лайкнул бы, да грехи карма не позволяет )
На ассемблер можно и нужно писать сообразно идеи структурного программирования. Структурное программирование далеко не заключается в неиспользованием goto/jmp.
Для примера в Форт при близкой семантике представления кода в сравнении с ассемблером всё же есть:
и IF… ELSE… THEN
и BEGIN… WHILE… REPEAT
и BEGIN… UNTIL
и DO… LOOP
и CASE… OF… ENDOF… ENDCASE
…
и возможность к произвольному созданию любых «экзотических» конструкций управления средствами самого языка и в управлении данными с возможностью и изменения синтаксиса под требуемую семантику штатно средствами языка не пересобирая ядро системы.
FOR… NEXT SWITCH BREAK CONTINUE…
P.S. Даже на стандартном ассемблере для AVR примерно такое тоже возможно Конструкции структурного программирования для AT90s8515
Вы просто путаете форму с содержанием. Все эти if-else-while, суть высокоуровневые конструкции, которым не место в ассемблере.
Но суть структурного программирования совсем в другом. Можно программировать структурно и на ассемблере. А можно писать неструктурированный код и на C++.
Из этого проекта для AVR
И статья Машина времени для крошек.
P.S. В любом случае при использовании в большой программе ассемблера программист старается формализовать в какой то степени и возможности по его эффективному использованию с точки зрения своих трудозатрат на написание кода на нём и дальнейшего его понимания.
У меня достаточно личного опыта использования ассемблера в программировании на них, чтобы сформировался определённый взгляд на его счёт. ?
Даже когда делал эмулятор PDP-11 процессора на x86 ассемблере и то от связки его с Форт не отказался.
Вы просто путаете форму с содержанием.
Мне понятна фраза о чём в ней говорится, но особо «тонких» и эффективных способов использования команд доступных в том или ином процессоре может и не потребоваться, хотя для себя нашёл «пару» моментов построения нетривиального ассемблерного кода при этом.
Можно программировать структурно и на ассемблере.
Сложно, не используя комманды структурного перехода, а GOTO остаться в рамках «ограничений» структурного программирования.
В этом аспекте рассмотрения можно сказать, что и Дракон язык схем сделан «структурным» при ограничениях его применения.
P.S. Кстати, по возможностям изменения эргономики мнемоник ассемблерных команд показателен случай из программы AB (Algorithm Builder 5.44) для AVR Описание ассемблер мнемомик AB программы
Учебник по работе с АВ
Топик на форуме vrtp.ru пользователей данной программы:
Algorithm Builder for AVR, Начинаем
Сам автор программы, не найдя ей коммерческое развитие сделал её бесплатной и не стал продолжать развитие идеи в рамках ARM архитектуры.
Но суть структурного программирования совсем в другом. Можно программировать структурно и на ассемблереИз текста программы будет сложно извлечь структуру. Ведь структурное программирование — это использование вложенных друг в друга блоков типа «последовательность», «ветвление», «итерация». Языки высокого уровня эти блоки естественно отображают отступами, а на ассемблере границы и вложенность блоков никак нельзя понять, не читая весь код от начала до конца.
Ассемблер читается очень и очень не так как ЯВУ. Отступы конечно можно использовать, некоторые так и делают. Но лучше всё-таки читать по ассемблерному – по вертикали и аккордами, а не отдельными инструкциями. Тогда и вложенность отличается прекрасно.
Тогда предложенный код можно на С написать так же как на АСМ и не факт, что будет менее понятно.
Короче для меня пока тезис не доказан :-)
А вы про язык или про один пример? А то давайте сразу к быстрой сортировке перейдём. Представляю если б мне пришлось это без комментариев читать, или ещё хуже - баг там искать.
Тот факт, что у вас названия переменных фиксированы (эах, оух, ...) уже делает любую нетривиальную программу нечитаемой (по сравнению с языком более высокого уровня).
названия переменных фиксированы (эах, оух, ...)Это скорее издержки IDE, которые для ассемблера от примитивного текстового редактора ничем не отличаются. В Visual Studio для MASM даже подсветки синтаксиса нет! Не говоря уже о сворачивании частей кода (аналог #region в шарпе). Я писал для этого расширение, которое в том числе позволяло привязывать к регистрам вменяемые имена (в виде всплывающих подсказок), и в идеале их вполне возможно отображать непосредственно в листинге.
Тот факт, что у вас названия переменных фиксированы
Не надо рассуждать о регистрах как о переменных. Они такими не являются. Переменные в ассемблере, находятся в памятью и имеют нормальные имена. А регистры, это регистры – ресурс которого просто нет в высокоуровневых языков.
А регистры, это регистры – ресурс которого просто нет в высокоуровневых языков.
Изначально предполагалось, что в Си будет к ним определённый доступ по ключевому слову их расположения register, но это так и осталось только задекларированной, но не поддержанной возможностью в Си компиляторах, а также могли бы быть добавлены команды непосредственно присутствующие в процессоре, как теже сдвиги по непосредственной работе с ними.
И язык Си по части своих возможостей стал бы похожим на существующий и сейчас проект С-- языка. ?
P.S. И непосредственного доступа к стеку процессора нет в высокоуровневом языке, если не ввести, как в Форт, непосредственно доступ к управлению им и дополнительного стека оперирования данными вместо необходимости использования непосредственных регистров процессора в явной форме.
В Turbo C register вполне размещал переменную в регистр.
Но если переменная использовалась не как регистровая, например брался её адрес, то она размещалась в памяти.
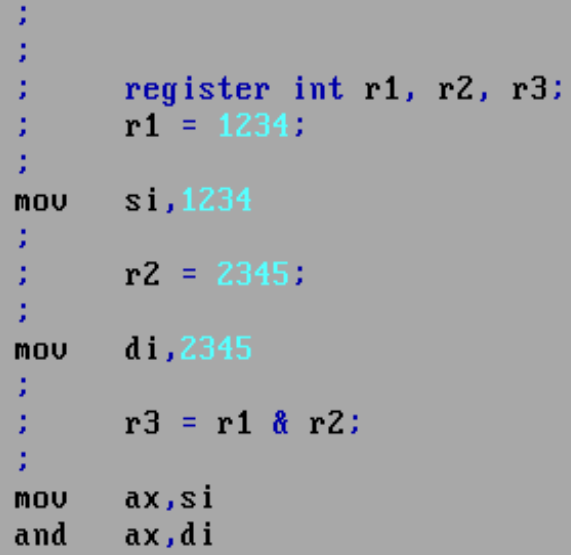
register игнорируется компиляторами. Вы не проверяли, какой код сгенерирует Turbo C без слова register? Все обычные компиляторы так же по возможности поместят переменную в регистр. То есть, что есть это слово, что нет его, на кодогенерацию никак не влияет.Конечно нет. Я такое не писал. Опять повторяю, регистры (да и стек тоже) это ресурс, которого нет в языках высокого уровня. И поэтому нельзя рассматривать их с высокоуровневой точки зрения. Ничего не получится.
Вообще, тема о удобочитаемости ассемблерного кода и вообще структурного программирования на ассемблере очень длинная и непростая. В этой статье я рассматриваю микроскопическую долю этой темы. Может быть напишу отдельную статью, где рассмотрю все это более обобщенно.
Она соответствует регистру, или нет?
Нет.
Переменные в ассемблере, находятся в памятью и имеют нормальные именаКак в соответствии с этим реализовать, например, алгоритм Евклида с переменными a и b
while (a != b)
{
if (a > b)
a = a - b
else
b = b - a;
}Как в соответствии с этим реализовать, например, алгоритм Евклида с переменными a и b
А зачем нужно это ограничение «с переменными a и b»? Правильный вопрос будет «Как реализовать алгоритм Евклида?»
Любопытно, а как Эвклид представлял переменные и поток команд в своем алгоритме.
Может не переменные, а парметры/неизвестные:
gcd(A,A)->A;
gcd(A,B)when A>B ->gcd(A-B,B);
gcd(A,B)->gcd(B,A).
Не холивара ради, но вот такой вопрос: а для arm-процессоров будете повторно такой код писать? Поскольку набор команд и подходы написания кода для arm совсем другие. Или же ОС-независимый GUI не включает ОС под arm?
К чему это я – если вам нравится хардкор и оттачивание до мелочей, не эффективней ли писать на C (т.е. даже не плюсах)?
Ну-у-у, а зачем вообще рекурсивно??? Нерекурсивный алгоритм в случае намного и читабельнее и компактнее.
Это он еще fork-join не применил
Автор, можно изобразить на ассемблере любое crud spring boot rest приложение с секьюрити, жпа и всем полагающимся. А самое главное узнать насколько читаемо это будет выглядеть и сколько времени займет. Любой джава джун за час запилит.
Или нарисуйте фронт к нему, который джун js так же быстро изобразит.
Каждый язык, - для своих целей хорош. Не надо ругать одни и превозносить другие.
Хотя, я вроде и не совсем понимаю что, все эти «crud-spring-boot-rest» значат, но если про веб, то мы это проходили. Оно все еще работает.
На секюрити не жалуюсь. Уже 2 года форум работает вообще без инцидентов и без всякой поддержки и администрации.
Удобочитаемость кода тоже ничего. По крайней мере, даже люди далеки от ассемблера могут ориентироваться и понять что к чему.
Следующий лист дерева на ассемблере в девяти инструкциях и единственном регистре