Привет, Хабр! Я – Евгений Ненахов из центра Big Data МТС Digital. Это вторая часть статьи о том, как мы создали универсальный инструмент потоковой обработки данных и построили с его помощью мощную систему стриминга. Если вам интересна обработка данных – вам будет интересен и этот текст.

В первой половине статьи мы обсудили основные компоненты методологии, а сейчас поговорим о том, как ими пользоваться. Поехали!.
Где хранить конфигурации?
Первоначальная идея заключалась в том, чтобы сделать самодостаточный инструмент и не плодить технологии. Так, нашему потребителю не нужно иметь каких-то сложных компетенций для того, чтобы этим пользоваться. Казалось бы, самое простое решение – сделать структурированный файлик, и в нем хранить конфигурации. Это работает хорошо до тех пор, пока у вас всего пять пайплайнов. Но когда их становится 10, 20 или 30, то следить за пайплайнами и управлять ими становится невыносимо тяжело.
Почему бы тогда не положить весь наш пайплайн и все обработчики в Postgres? Может быть, это хорошо ложится в ту модель, которую нам может предложить Postgres? Оказалось, что да, все наши данные и этапы обработки мы можем разделить на таблички и связать воедино. Причем аккумулирующей табличкой будет Action, которая содержит в себе все результаты обработчиков пайплайна.
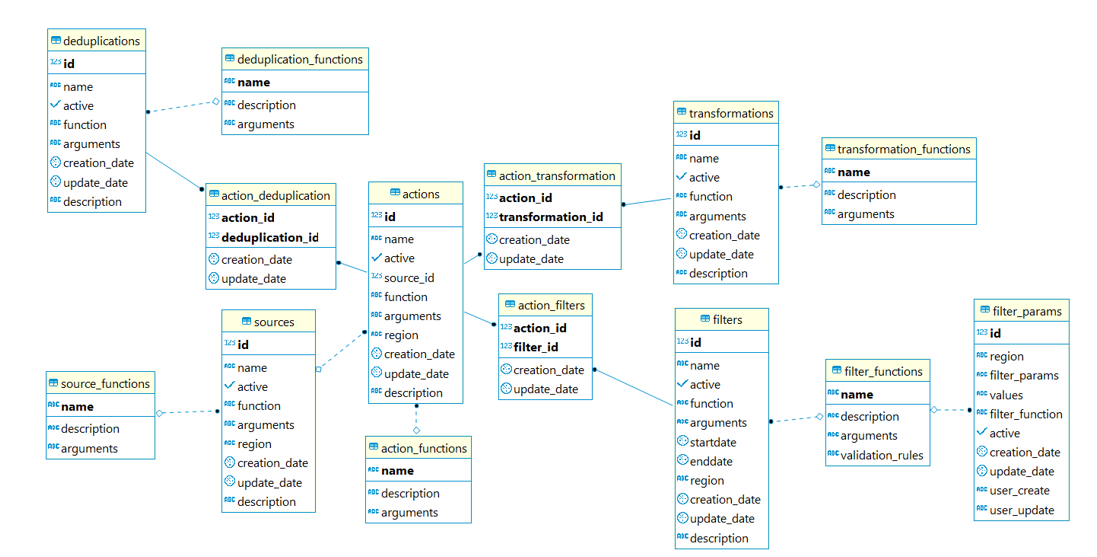
При первом взгляде на картинку выше кажется, что там все очень сложно, но хочу заверить, что большинство таблиц, которые имеют связи — это технические таблицы. Они заполняются автоматически. Чтобы в этом разобраться, достаточно сделать пару селектов и инсерт, чтобы настроить нужного рода пайплайн.
Хорошо, разобрались с пайплайнами. С концепцией тоже разобрались: взяли Scala и Spark, написали код, протестировали. Теперь думаем – надо все это дело запускать на кластере. Сделали себе кластер, настроили конфигурации пайплайнов и запускаем spark-submit. И вдруг – никуда ничего не едет. Мы начали копаться, поняли, что у нас проблемы – то падают экзекьюторы с memory exception, то какие-то подвисания, то почему-то микробатчи друг за другом не двигаются. Куча проблем, причем совершенно магических.
Как мы нашли решение?
Мы подумали, что очень плохо написали код и стали в нем копаться. На самом деле оказалось, что мы просто не настроили ни Kafka, ни Spark Streaming. История о их тюнинге — это история долгая и очень сложная. Мы потратили на это много времени и выявили для себя несколько параметров, которые позволили нам повысить производительность и отказоустойчивость. Этой историей я хочу с вами поделиться.

Для начала мы должны снизить нагрузку на GC совокупностью параметров. Именно совокупностью — по отдельности это может не оказать влияния. Если вы по какой-то причине не используете G1 Garbage сollector в своих машинах – это надо исправить, потому что G1 очень хорошо работает с большими объемами памяти и мы это подтвердили своими тестами. Также стоит установить максимальную паузу GC в 500 миллисекунд. Понимаю, что это рекомендательный параметр для GC. Скорее всего, в большинстве случаев GC будет игнорировать этот параметр и превышать лимит, но примерно 3% он позволит вам сэкономить.
Также я советую поиграться с параметром, который указывает заполняемость кучи перед параллельной сборкой мусора. Мы установили эмпирическим путем, что 35% — это золотая середина, где мы наиболее оптимально расходуем ресурсы и паузы stop the world у нас уже не такие большие.
Еще один интересный параметр – Concurrent. Причем я знаю, что не все люди в принципе в курсе того, что такой параметр существует. И еще меньше людей знают, как его правильно настроить.
Concurrent позволяет улучшить параллельность работы с job. Пайплайны в нашем инструменте реализованы таким образом, что при обработке микробатчей у нас будет максимум два job. Причем они будут работать последовательно при дефолтных настройках Spark Streaming. И если мы настраиваем, например, штук пять наших пайплайнов, то в нашем Spark Streaming-приложении будет 10 job, которые станут работать последовательно. Это нам не подходит, так как у нас много CPU и мы хотим, чтобы все были задействованы в один момент времени.
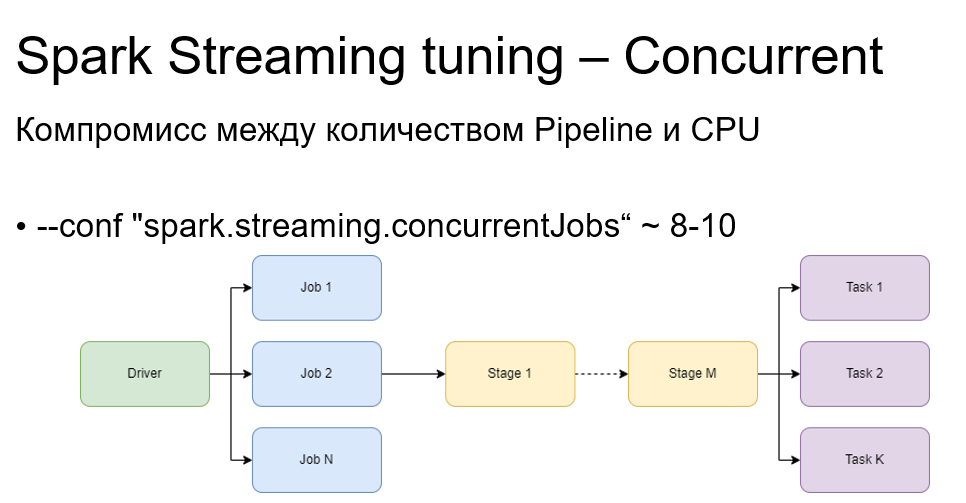
Поэтому мы устанавливаем при пяти пайплайнах 10 concurrent job и работают все пайплайны параллельно. Бывают ситуации, что какой-то job подзавис из-за зависшей таски. И вот он висит, пожирает одну CPU, все остальные CPU «сидят и ждут», а мы не можем взять при этом следующий микробатч в работу. Так вот, устанавливая concurrent job в правильное значение, мы можем взять в работу следующий микробатч, не дожидаясь обработки предыдущего.
Занимательный параметр – Speculation. Он позволяет перезапускать в автоматическом режиме таски, которые подвисли у Spark Streaming. Как Spark streaming понимает, что таска подвисла? Об этом говорят параметры multiplier и quantile.
Например, multiplier=3 и quantile=0.9. Это означает, что если время выполнения задачи в три раза превышает медианное время 90% остальных выполненных тасок, – эта task подвисла. Если есть 10 задач, девять из которых выполнились за одну секунду, а одна работает уже четыре секунды, – ее стоит перезапустить.
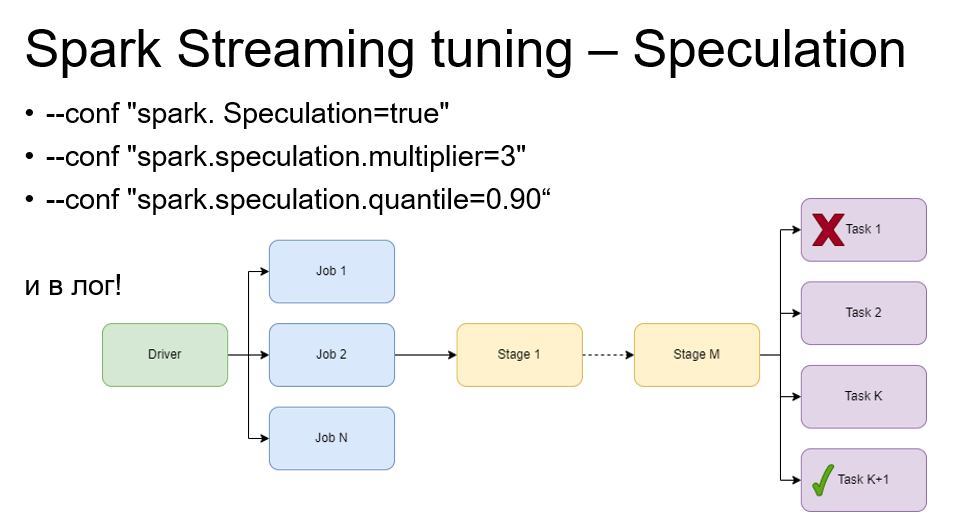
В 70% случаев Spark перезапускал такую задачу и она работала отлично. Так происходит из-за различных интеграций с источниками, где на источник указаны таймауты. Например, батч интервала установлен в 10 секунд и каждые 10 секунд вы хотите обрабатывать данные, а таймаут у вас установлен в четыре минуты. Вы висите на этой таске четыре минуты, пока таймаут не отобьется, а задача не перезапустится. Speculation в этом плане нас очень сильно выручил.
Еще один интересный параметр называется Blacklist. Если вдруг Spark Streaming запускает на какой-то ноде экзекьютор и он постоянно падает – параметр помещает эту ноду в черный список. Некоторое время экзекьюторы на этой ноде не запускаются. Так мы можем сохранить производительность, особенно в пиках. При этом не надо руками выводить ноду из кластера, чтобы понять, что с ней происходит. Она просто продолжает дальше находиться в кластере.

Еще один параметр — Memory. Все знают про driver memory, про executor memory, но многие забывают про memory overhead. Он в Spark memory model необходим для различных нужд JVM, например, для интернирования строк. И на больших потоках данных дефолт назначения в 10% от основной памяти не хватает. Поэтому эмпирическим путем мы высчитали, что где-то 30% от этой памяти нам хватает и экзекьюторы при этом не падают с out of memory.

Стоит обратить внимание на конкретные параметры Kafka, особенно на maxRatePerPartition, который должен коррелировать с интервалом микробатча. MaxRatePerPartition говорит о том, какое максимальное количество записей будет прочитано в одну секунду из одной партиции одного топика.

Это, естественно, нужно вычислять в потоке эмпирическим путем. Нам очень помогла вот такая табличка, мы ее не сами составили, а нашли на просторах интернета.

Говорит она о том, какие параметры и как нужно вытащить. Например, Acks и min.insync.replicas. Нам подошла именно третья строчка, ведь мы желали заполучить высокую пропускную способность. А Latency нас не очень интересовала, потому что весь Latency в Kafka у нас бы сожрал Spark Streaming интервал. Также интересна была высокая доступность и мы выставили Acks в All и min.insync.replica в двоечку.
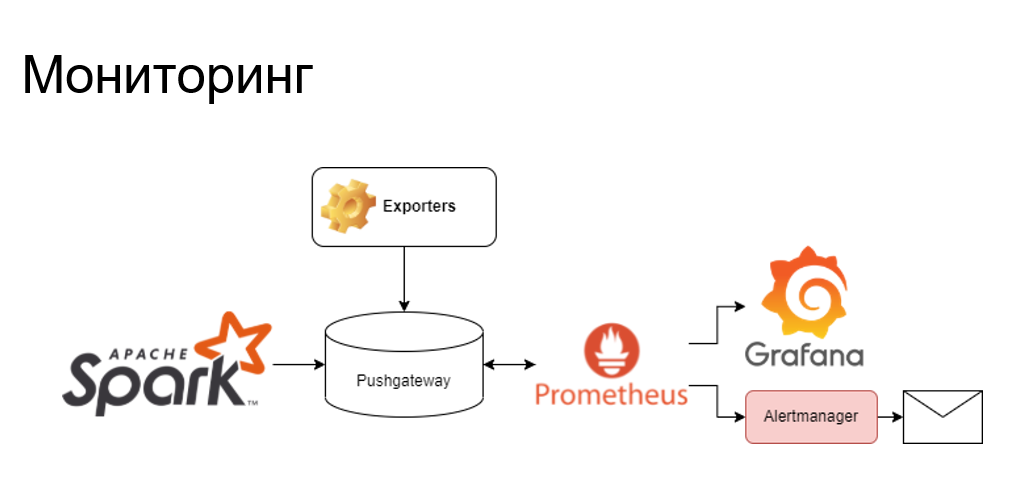
С точки зрения мониторинга здесь стандартная история. У Spark streaming много технических метрик. А если нам каких-то метрик не хватает – пишем на Python экспортеры. Все это льется у нас в Pushgateway, после чего отдается в Prometheus и визуализируется в Grafana. Если что-то пошло не так на проде – «письма счастья» через алерт-менеджер приходят к нам на почту. Логи тоже собираются стандартным образом, это ELK-стек, вся обработка идет в Logstash, хранится в Elasticsearch, анализируется и визуализируется все в Kibana.
На чем все это дело работает?
У нас есть кластер из 18 DataNode, 3 ноды для управления этим кластером и другими приложениями. По характеристикам это 36 ядер и 384 гигабайта RAM. Тут внимание на Optane, 624 гигабайт оттуда добавляются в RAM, и менеджер ресурсов – мы используем YARN – видит именно терабайт памяти на одной такой ноде. Память Optane медленнее, чем RAM, но она нам очень помогает при решении задач дедубликации. А 8 терабайт на HDD нас вполне устраивает.

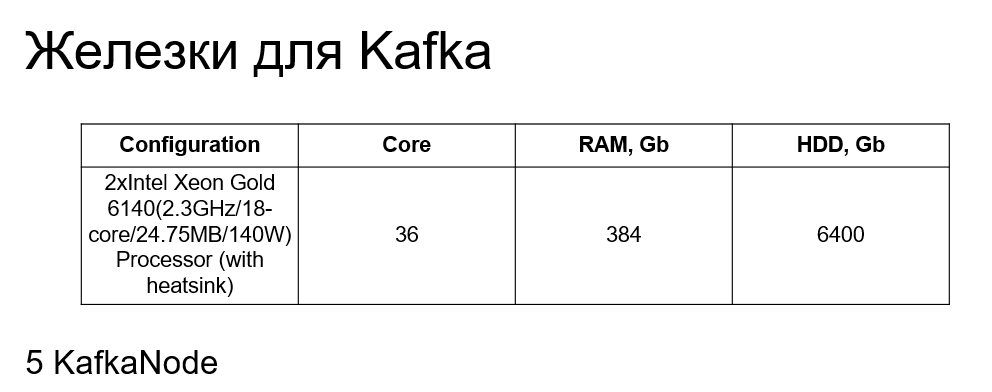
Также у нас отдельный кластер под Kafka, под промежуточные топики. Это 5 KafkaNode, с практически такими же характеристиками, только без Optane и с меньшим количеством HDD.
Что в итоге у нас получилось?
У нас были ожидания на 5 млн ~ 10 млн событий в секунду. Судя по метрикам Grafana, разбитых по доменам, пока что у нас выходит 6 млн событий в секунду в среднем и 7 млн в пике. То есть еще присутствует запас в 3 млн событий.
У нас получилось 99,9% отказоустойчивости за год, все это – благодаря небольшому зоопарку технологий, механизмам отказоустойчивости Spark и Kafka. Ну и масштабируемость — за счет Spark и Kafka она у нас и вертикальная, и горизонтальная.

Функционалы фильтрации, трансформации и дедубликации уходят в пайплайн. Здесь дам совет – лучше разделить инстансы нашего инструмента на два инстанса Spark streaming. Причем разделить как фильтрацию, так и дедубликацию, и соединить их промежуточным топиком Kafka. Потому что фильтрация в принципе просит больше CPU и памяти для того же интернирования строк. А для дедубликации нужно больше памяти и оставить немного CPU на то, чтобы не задыхался garbage collector.
Zero code-настройка обработки данных — здесь у нас вышел low code, ведь, чтобы настроить пайплайн, достаточно сделать пару инсертов.
Надеюсь, что эта статья стала для вас интересной и полезной. Вопросы и истории из вашего опыта обработки данных жду в комментариях. Спасибо за уделенное время!
