

В современной разработке ПО наблюдаемость (observability) является важнейшей концепцией, которая относится к способности получать представление о внутренних процессах сложных систем. Она подразумевает сбор данных из разных источников, таких как журналы, метрики и трейсы, с последующим их использованием для лучшего понимания функционирования системы, выявления проблем и их устранения. И в этой статье мы подробно разберём все аспекты реализации этой концепции.
В своей сути наблюдаемость отражает то, насколько легко можно определить состояние системы по её внешним проявлениям, для чего используются соответствующие техники. Эти техники включают сбор данных и метрик из различных источников, таких как системные журналы, сетевой трафик и индикаторы производительности системы. Эта информация в итоге используется для понимания поведения системы, её быстродействия и состояния.
Наблюдение за системой даёт ряд преимуществ командам, отвечающим за разработку и обслуживание сложных систем ПО. Вот некоторые из основных:
- Ускорение разрешения инцидентов: с помощью инструментов наблюдения команды могут быстро определять и диагностировать проблемы в системах, сокращая время на их устранение.
- Повышение быстродействия системы: за счёт мониторинга метрик системы и выявления узких мест команды могут оптимизировать её производительность, а также улучшать пользовательский опыт.
- Эффективное планирование ресурсопотребления: инструменты наблюдения помогают проанализировать паттерны использования системы, позволяя командам планировать будущие потребности и оптимизировать использование ресурсов.
- Повышение эффективности разработки: наблюдение позволяет разработчикам лучше понять влияние внесённых изменений кода, а также облегчает процесс отладки и тестирования.
- Более эффективное сотрудничество: за счёт предоставления общей картины поведения системы инструменты наблюдения помогают командам более эффективно сотрудничать, обмениваться знаниями и разрешать проблемы.
- Повышение надёжности системы: за счёт мониторинга состояния системы и определения неполадок до того, как они станут критическими, наблюдение помогает командам убедиться в надёжности подопечных систем и их доступности для пользователей.
В качестве примера мы подробно разберём в этой статье темы распределённой трассировки, метрик, мониторинга, логирования и оповещения.
Распределённая трассировка
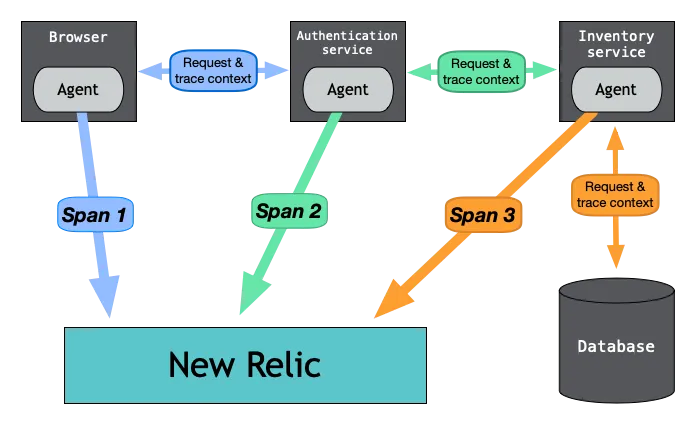
Распределённая трассировка – это техника мониторинга и отладки крупных распределённых систем. Она подразумевает реализацию кода для генерации трейсов, представляющих собой записи активности отдельных запросов по мере их прохождения через систему. Впоследствии эти трейсы агрегируются для предоставления подробной картины обработки запросов различными компонентами системы.
Распределённая трассировка особенно полезна в системах, состоящих из множества сервисов или компонентов, взаимодействующих по сети. В таких системах бывает трудно отслеживать источник ошибок или проблемы производительности, так как один запрос может затрагивать многие их части.
▍ Как это работает
- Работает эта техника путём генерации и распространения контекста трейса (trace context) по распределённой системе.
- Когда сервис получает запрос, он генерирует контекст трейса, включающий уникальный trace ID и span ID.
- Trace ID используется для определения самого запроса, а span ID определяет конкретную операцию или активность в рамках этого запроса.
- Когда запрос обрабатывается сервисом, контекст трейса передаётся другим сервисам, задействованным в этой обработке.
- Каждый сервис в процессе обработки генерирует новые спаны и добавляет их в контекст трейса. Так создаётся цепочка спанов, представляющая весь путь запроса через систему.
- Полный контекст трейса возвращается клиенту либо сохраняется в бэкенде трассировки в конце обработки запроса.
- Затем контекст трейса можно визуализировать и проанализировать для лучшего понимания производительности и поведения системы.
Разработчики обычно используют библиотеки трассировки или фреймворки, предоставляющие API для генерации и распространения контекста трейсов, делая возможной распределённую трассировку. Эти библиотеки могут поддерживать стандартные форматы трассировки, такие как OpenTracing или Zipkin, а также популярные инструменты логирования и мониторинга вроде Prometheus или Grafana.
Метрики

Метрики представляют собой количественные измерения, используемые для отслеживания и мониторинга производительности, поведения и состояния системы либо приложения. С их помощью обычно получают информацию о том, насколько хорошо работает система, а также выявляют её тенденции, паттерны и проблемы.
Как правило, метрики в течение времени собираются и сохраняются, после чего используются для генерации отчётов, сводных таблиц и оповещений. Вот их типичные виды:
- Метрики производительности, такие как время отклика, пропускная способность и частота ошибок.
- Метрики потребления ресурсов, такие как использование ЦПУ, памяти и дисковой системы ввода-вывода.
- Бизнес-метрики, такие как доход, вовлечённость пользователей и удовлетворённость клиентов.
Метрики важны для мониторинга состояния и производительности системы. При этом они также помогают выявлять проблемы до того, как те станут критическими. Отслеживая и анализируя метрики во времени, разработчики и операторы могут принимать подкреплённые информацией решения о том, как оптимизировать и улучшить быстродействие системы, а также определять направления для будущих вложений и разработки.
▍ Как собирать метрики
Метрики зачастую собираются с помощью инструментов мониторинга или фреймворков и могут сохраняться в различных хранилищах, таких как базы данных временных рядов или агрегаторы логов. Их также можно анализировать с помощью различных инструментов визуализации и анализа, например Grafana или Kibana.
- Реализация: метрики можно собирать путём реализации кода внутри приложения или системы. Это подразумевает добавление кода для перехвата определённых метрик, таких как время отклика или частота ошибок, и отправки их в систему мониторинга.
- Метрики на основе логов: метрики также можно извлекать из данных журналов, сгенерированных приложениями или системами. Этот подход включает извлечение метрик из файлов журналов, например количеств определённых типов событий или ошибок, и их отправку в систему мониторинга.
- Системные метрики: операционные системы и компоненты инфраструктуры, такие как серверы, сети и базы данных, обычно отражают встроенные метрики, которые можно собирать и мониторить с помощью инструментов системы.
- Сторонние сервисы: многие облачные сервисы предоставляют встроенные метрики, к которым можно обращаться и мониторить через API или веб-интерфейсы.
Какой бы метод ни использовался, важно, чтобы метрики собирались с подходящей частотой и точностью, и сохранялись при этом удобным для запроса и анализа образом.
Мониторинг
Мониторинг системы – это процесс наблюдения и сбора данных о производительности, поведении и состоянии компьютерной системы либо приложения. Цель такого мониторинга – обеспечение оптимальной работы системы и приложений, а также определение и разрешение проблем по мере их возникновения.
Обычно мониторинг системы включает сбор и анализ различных видов данных, таких как журналы системы и приложения, метрики производительности и использования ресурсов. К стандартным видам данных, собираемым в ходе системного мониторинга, относятся:
- Метрики производительности: определение времени отклика, пропускной способности и частоты ошибок помогает понять, насколько хорошо работает система или приложение.
- Метрики использования ресурсов: определение использования ЦПУ, памяти и дискового ввода-вывода помогает понять, каким образом задействуются ресурсы системой или приложением.
- Данные журналов: журналы системы или приложений помогают разобраться в их поведении, а также могут использоваться для исправления проблем и выявления ошибок.
▍ Как проводить мониторинг
Конкретный механизм для сбора и анализа данных мониторинга отличается в зависимости от типа отслеживаемой системы или приложения, но обычно включает следующие этапы:
- Сбор данных: инструменты мониторинга системы собирают данные из различных источников, таких как журналы, счётчики производительности или API. Данные можно собирать в реальном времени либо в пакетах, что зависит от требований программы мониторинга.
- Хранение данных: после сбора данные мониторинга помещаются в хранилище, такое как база данных временных рядов или агрегатор логов. Обычно данные сохраняются в структурированном формате, что позволяет их эффективно запрашивать и анализировать.
- Анализ данных: инструменты мониторинга анализируют собранные данные с целью выявления тенденций, паттернов и проблем. Этот анализ можно выполнять с помощью различных техник, таких как статистический анализ, машинное обучение или оповещения на основе порогов.
- Отчёты и визуализация: результаты анализа обычно представляются в виде отчётов, сводных таблиц или оповещений. Эти данные помогают понять производительность и поведение системы, а также выявить проблемы до того, как они станут критическими.
Задача мониторинга системы в том, чтобы делать видимой производительность и поведение компьютерных систем и приложений, а также выявлять проблемы на ранних стадиях, пока те не повлияли на пользовательский опыт.
Логирование

Логирование – это практика сбора и сохранения данных о событиях, возникающих в системе или приложении. Эти данные могут включать информационные сообщения, предупреждения, ошибки и прочую информацию, обычно сохраняемую в файле журнала или базе данных.
Помимо предоставления записи активности системы, логирование также можно использовать и для других целей:
- Аудит: с помощью логирования можно отслеживать пользовательскую активность в системе или приложении, получая информацию о том, кто, к каким данным и когда обращался.
- Соответствие требованиям: логирование можно использовать для выполнения нормативных требований или требований совместимости, таких как HIPAA или PCI-DSS, которые предписывают хранение и анализ определённых типов данных.
- Мониторинг производительности: с помощью логирования можно отслеживать метрики производительности, такие как время отклика или использование ресурсов, используя их для оптимизации быстродействия системы.
▍ Как выполнять логирование
Логи можно собирать разными способами, в зависимости от типа логируемой системы или приложения. Вот ряд типичных:
- Логирование приложений: многие языки программирования и фреймворки предоставляют встроенную поддержку логирования приложения, позволяя разработчикам логировать сообщения на разных уровнях важности (например, информационные, предупреждения, ошибки), распределяя их по разным категориям.
- Системное логирование: операционные системы и сетевые устройства зачастую предоставляют свои механизмы логирования для перехвата системных событий, таких как авторизация, ошибки и использование ресурсов.
- Логирование с помощью агентов: многие инструменты логирования и сервисы предоставляют агентов или библиотеки, которые можно установить в системы или приложения для сбора данных логов.
- Контейнерное логирование: контейнеризованные приложения, выполняющиеся на таких платформах, как Docker или Kubernetes, генерируют данные логов, специфичные для среды контейнера.
- Облачное логирование: многие облачные платформы и сервисы предоставляют механизмы логирования для перехвата событий и данных, связанных с облачными ресурсами, такими как виртуальные машины, базы данных и сервисы приложений.
Для эффективного логирования необходимо внимательное планирование и конфигурация, чтобы итоговые данные логов оказались полезными и действенными. Независимо от метода, используемого для сбора данных логов, важно согласованным образом настроить уровни логирования, категории и форматы, обеспечив тем самым пользу и действенность собранных логов.
Оповещения
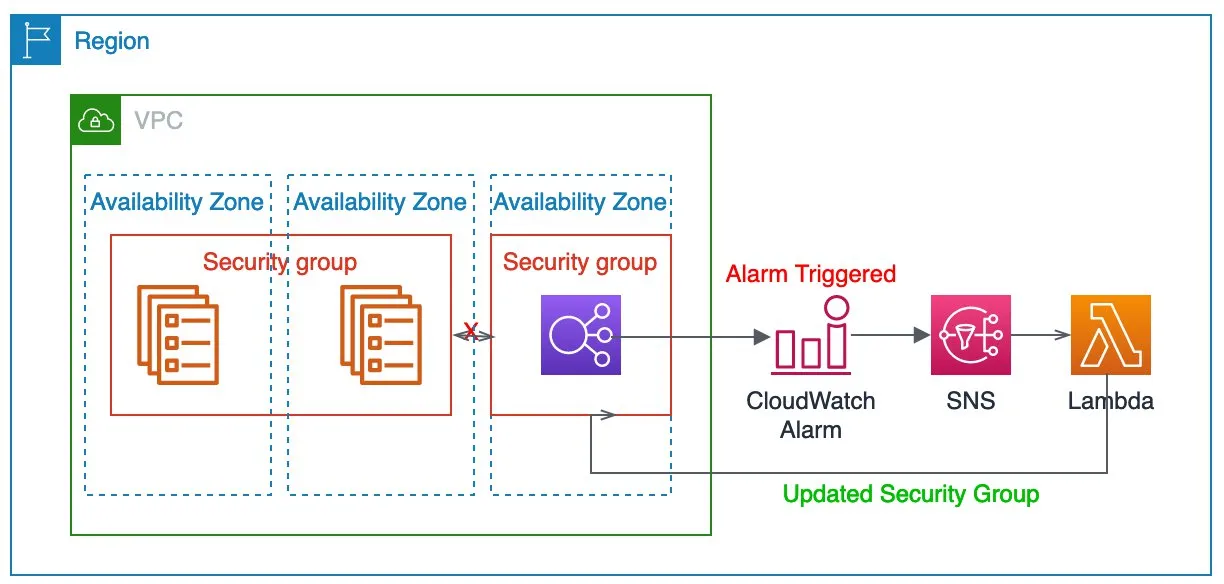
Оповещения – это способ автоматического уведомления причастных сторон о возникновении в системе или приложении конкретного события или состояния. Цель оповещений в том, чтобы быстро выявлять и реагировать на проблемы, пока они не оказали значительного влияния на производительность системы или её доступность.
Оповещения обычно генерируют инструменты мониторинга, которые собирают и анализируют данные о быстродействии и поведении системы. В случае обнаружения события или состояния такой инструмент может сгенерировать оповещение и отправить его одному или более получателям, таким как системные администраторы или команды DevOps.
Оповещения могут активироваться при различных условиях, таких как:
- Использование ресурсов: когда система или приложение превышает заданный порог использования процессора, памяти или прочих метрик ресурсов.
- Сообщения ошибок: когда в журнале приложения или системы обнаруживаются сообщения об ошибках, указывающие на проблему.
- Метрики производительности: когда метрики производительности, такие как время отклика или объём транзакции, выходят за установленный порог.
- Инциденты безопасности: в случае обнаружения событий, связанных с безопасностью, таких как провалы авторизации или попытки неавторизованного доступа.
В зависимости от потребностей организации или приложения оповещения можно настроить по-разному. Для их эффективной работы требуется внимательное планирование и настройка, чтобы оповещения были актуальными, действенными и не обременительными. Сюда входит определение ключевых событий или условий, требующих оповещений, настройка порогов, подходящих для конкретной системы или приложения, а также установка отчётливых процедур реагирования.
Заключение
В последние годы наряду с усложнением систем и повышением степени их распределённости концепция наблюдаемости становится всё более значимым аспектом анализа. Без неё зачастую оказывается трудно диагностировать и отлаживать баги, которые могут вести к даунтайму, недовольству пользователей и потере дохода. И напротив, её использование помогает командам обнаруживать и разрешать проблемы гораздо быстрее, что ведёт к построению более стабильных и надёжных систем.
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх ?️

