Недавно мы со Сбером проводили опрос о том, кто должен заниматься работой с данными и как это организовано в ваших компаниях. Чтобы не прослыть сапожниками без сапог, для анализа результатов мы использовали DS-подход. Хотите узнать, что у нас получилось? Тогда милости просим под кат.
Всего в опросе приняло участие 3540 человек, из которых 1874 дошли до конца и ответили на все вопросы. Их ответы мы и будем анализировать. В анализе данных мы использовали Google Sheets, R и Data Studio как средство визуализации, но перед публикацией попросили нашего дизайнера привести все графики к единому стилю.
Общие вводные
85% принявших участие в опросе сидят на Хабре как незалогиненные пользователи.

Если рассматривать ОС, то, как и в целом по миру, наблюдается доминирование пользователей с Windows — 62%, при этом 75% пользователей проходили опрос с десктопов.

Если рассматривать распределение ответов по датам, хорошо видно, что большинство ответов приходится на будние дни, в частности на понедельник и вторник.
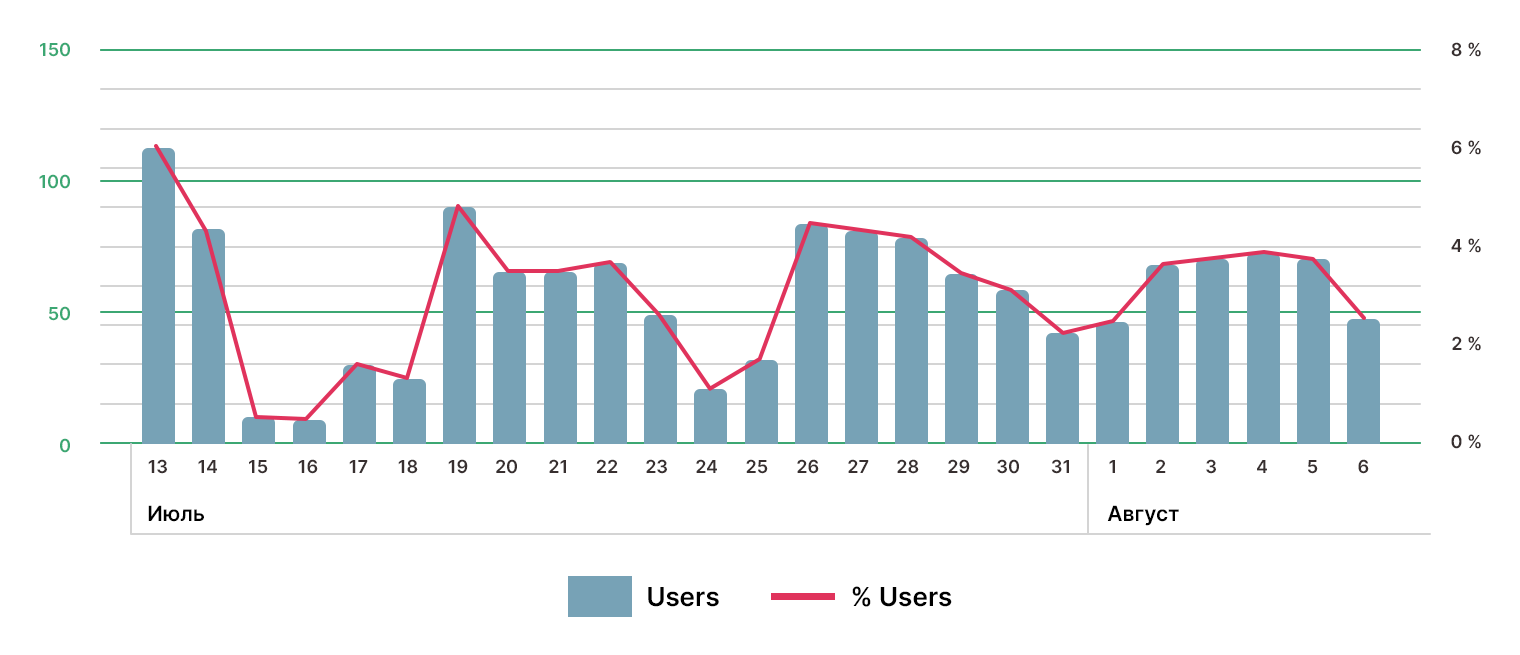
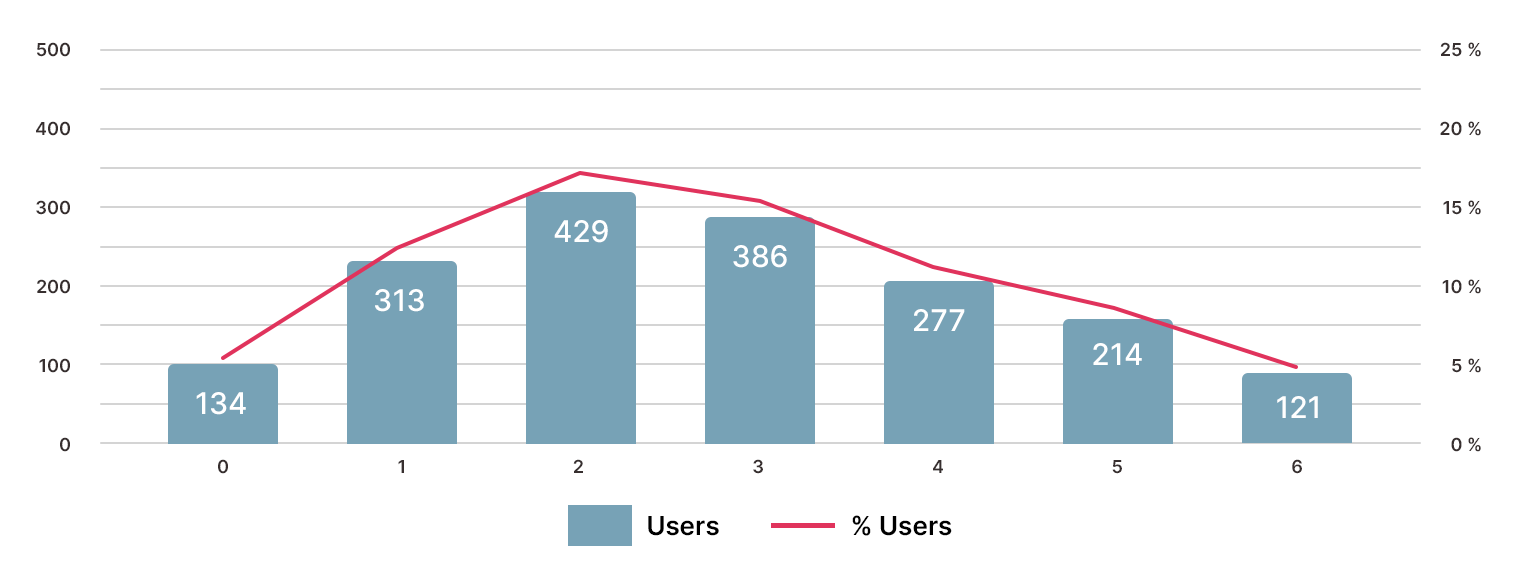
В течение дня участники чаще всего давали ответы в послеобеденное время. Учитывая всё перечисленное, можно выдвинуть гипотезу, что опрос большинство проходило в рабочее время и за рабочими машинами. Как известно, почитывание Хабра после обеда способствует рабочему и пищеварительному процессам.
Участники опроса — кто они?
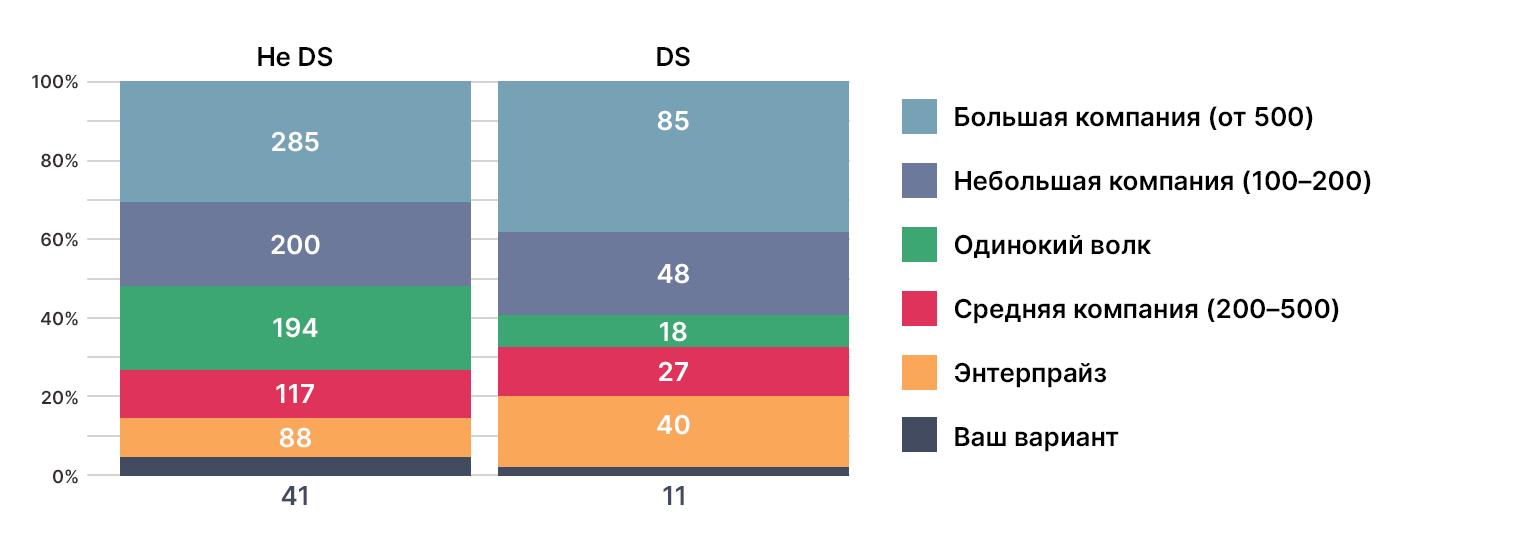
В первых двух вопросах мы спрашивали, кто наши участники, как давно они в профессии, и узнавали размер компаний, в которых они работают.
Практикующие DS оказались в меньшинстве — 366 человек из 1874 прошедших опрос. Так что мы разделили варианты ответов на две группы (DS и не DS) и проанализировали их в сравнении друг с другом. В основном большой разницы в ответах не было, но интересные расхождения всё же встречались, о чём расскажем ниже.
Из тех, кто не имеет отношения к DS, подавляющее большинство интересуется темой или уже планирует освоить специальность. Были и не совсем обычные участники:
“
Я школьник, который изучает всё, связанное с ПК.
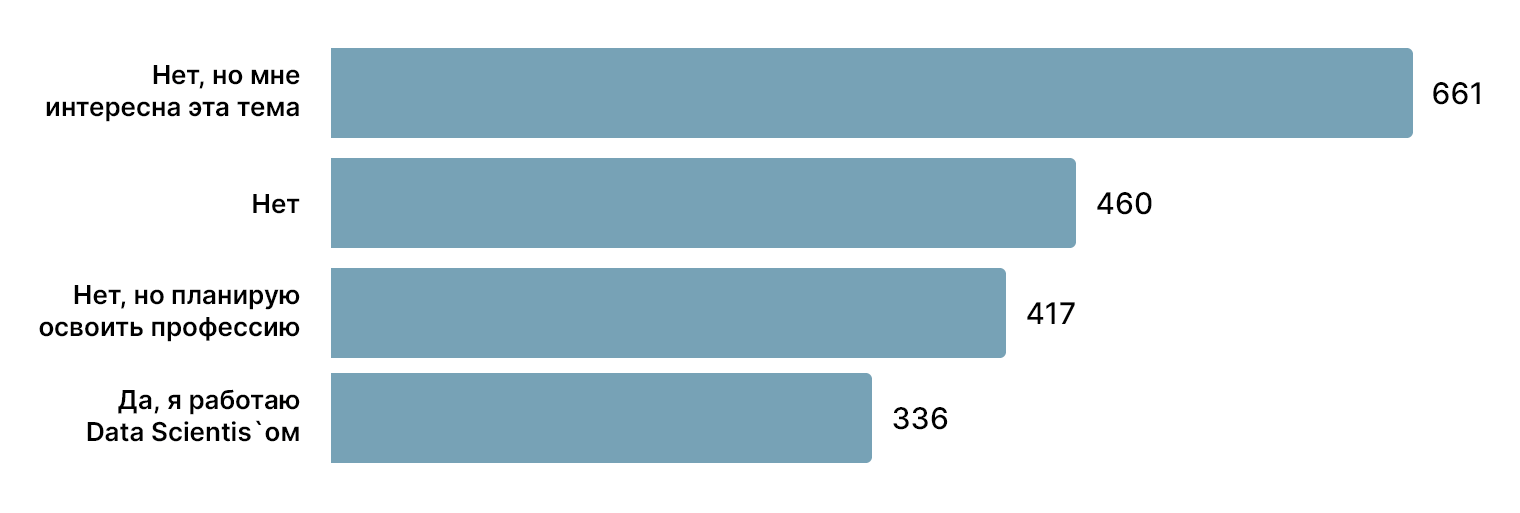
Примерно половина практикующих сайентистов в профессии от года до трёх. 59 человек занимаются DS менее года, и 47 в теме уже давно.
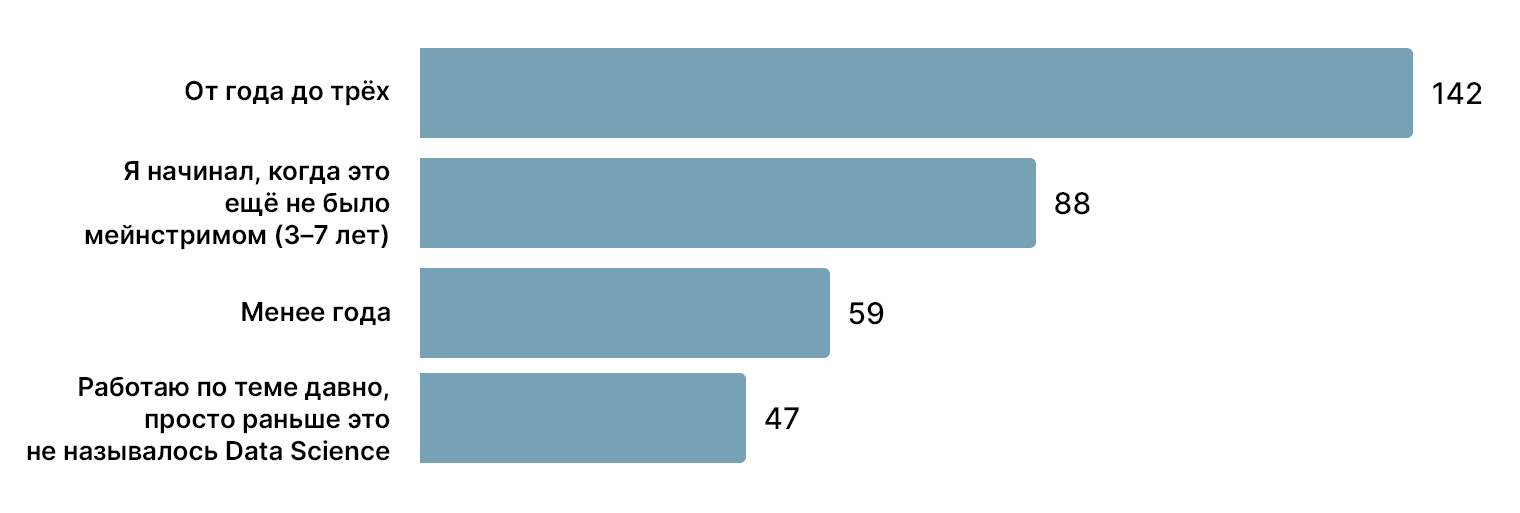
Не менее интересна и разбивка по размеру компаний, где работают наши участники.
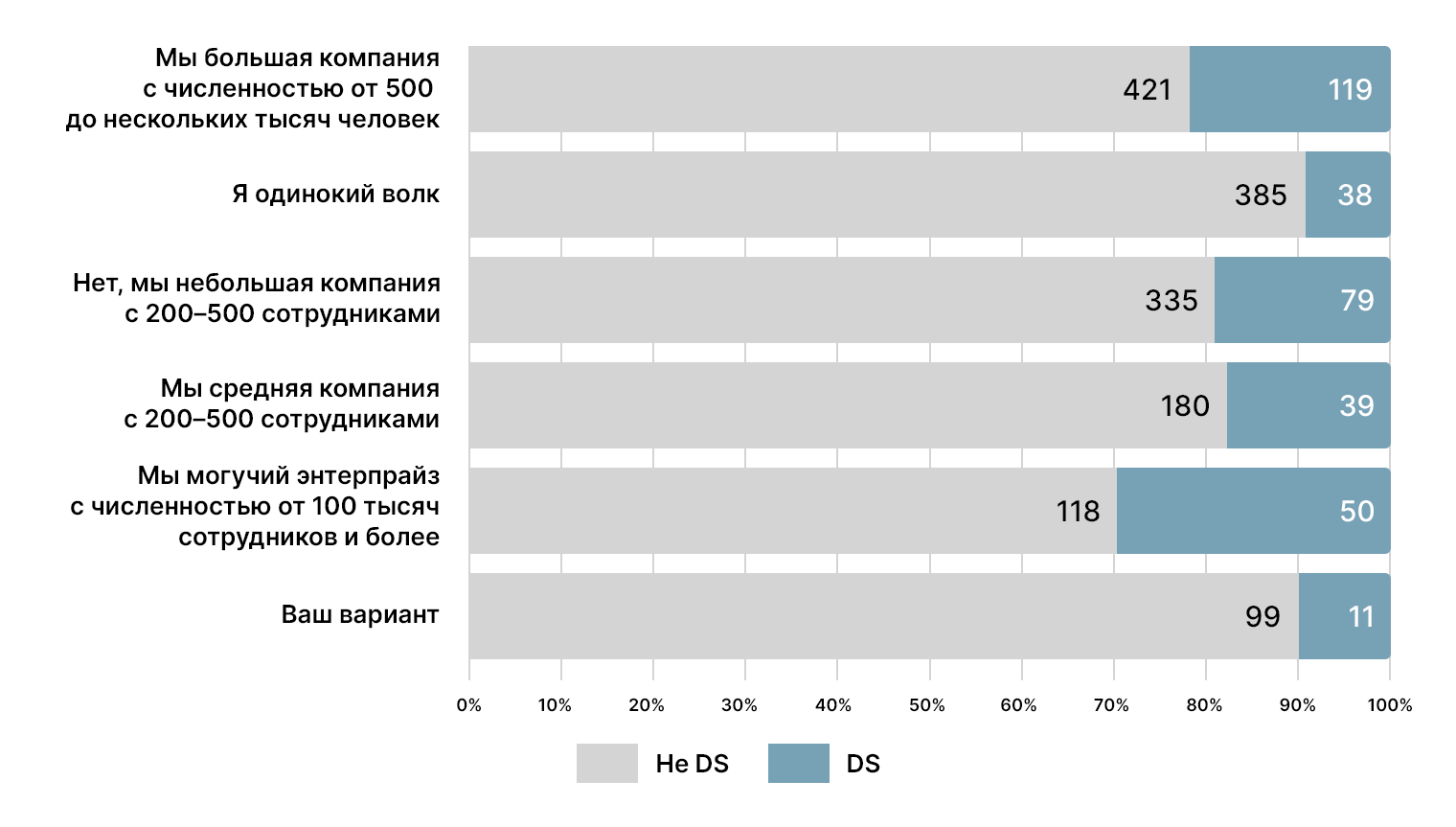
35% DS работают в крупных компаниях. На втором месте небольшие компании, и замыкает тройку лидеров энтерпрайз с 15% опрошенных.
11% DS сформировали стаю одиноких волков. При этом среди них есть как те, кто в профессии от года, так и те, кто занимается работой с данными уже давно.
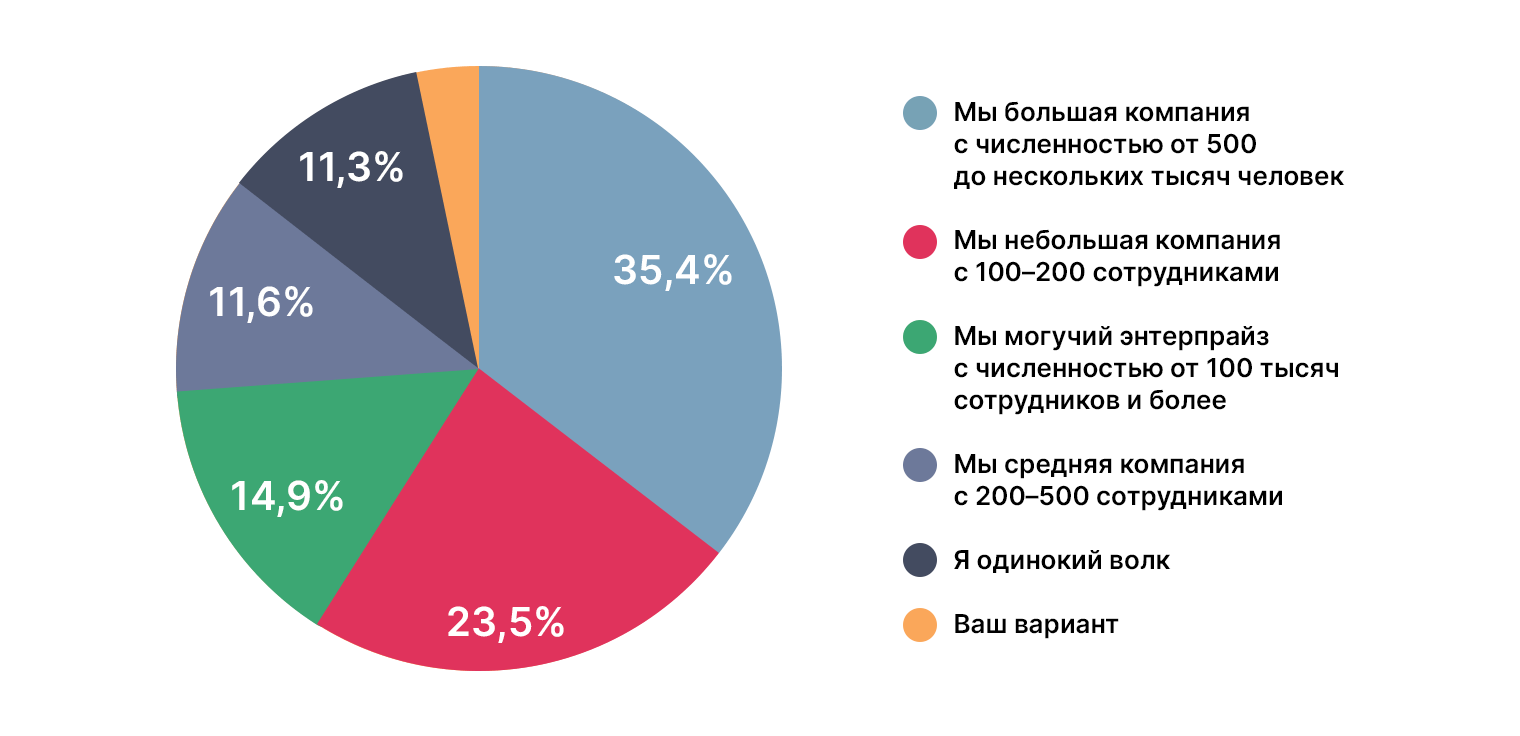
Результаты для DS
Среди интересующихся 27% одиноких волков и примерно столько же сотрудников крупных компаний.
Достаточно интересное распределение, и в следующем пункте оно тоже себя проявит.
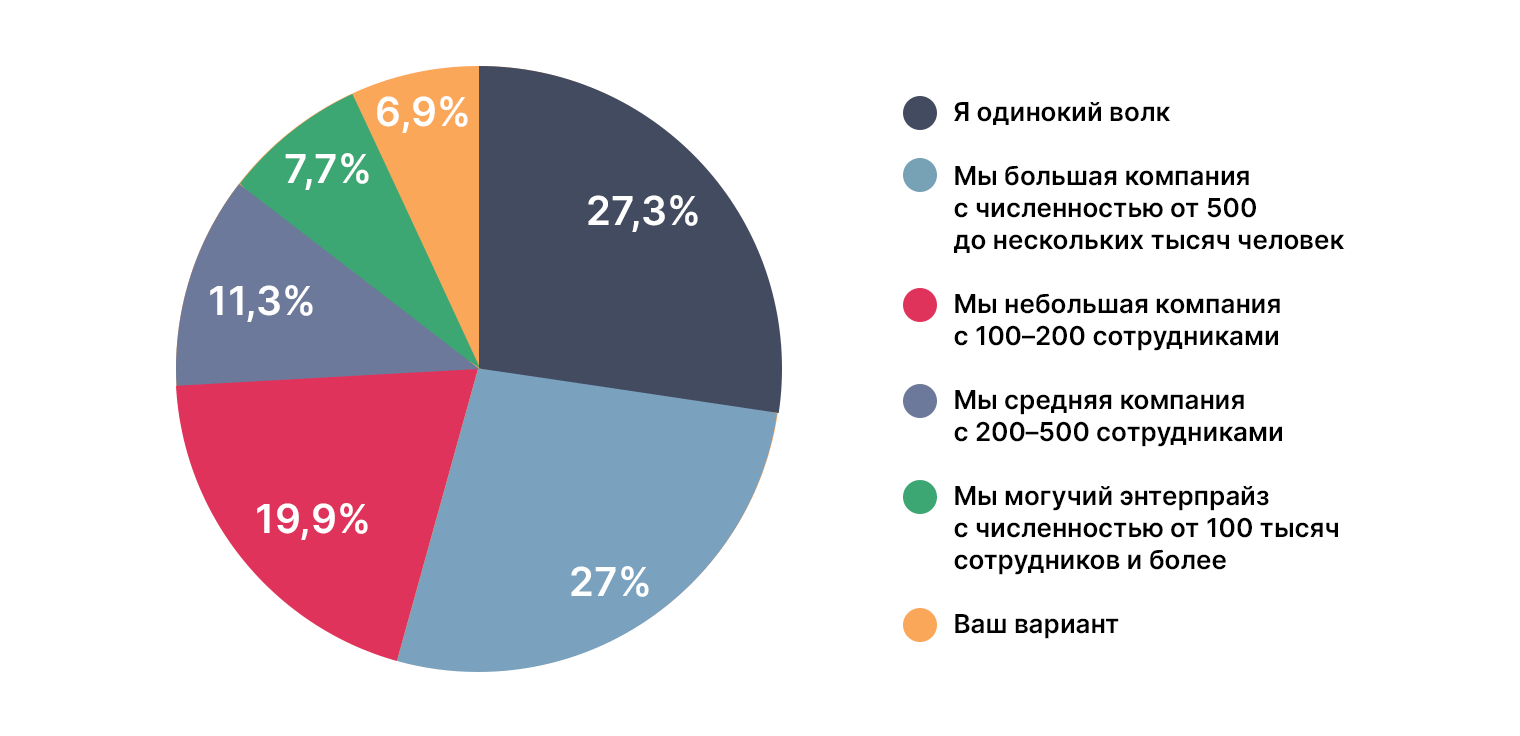
Результаты для не DS
Среди тех, кто только интересуется темой DS, одиноких волков меньше, чем среди тех, кто планирует освоить профессию, — 27% против 35% соответственно. Видимо, чем глубже погружаешься в специфику, тем больше матереешь.
В предложенных вариантах ответов были пропущены некоторые градации размеров компаний, о чём многие упомянули в комментариях к ответу. Из тех, кто выбрал свой вариант, большинство DS указало, что работает в небольших компаниях по 10–20 человек и стартапах, в то время как интересующиеся сейчас обучаются или находятся в поиске работы. Это коррелирует с предыдущим пунктом, согласно которому, как мы помним, среди интересующихся поровну тех, кто работает в компаниях, и одиноких волков. Можно предположить, что одинокие волки — это те, кто ищет свою первую работу, в то время как те, кто уже работает, планируют смену деятельности.
Представления о профессии
Кто должен заниматься анализом данных
Ответы распределились следующим образом:
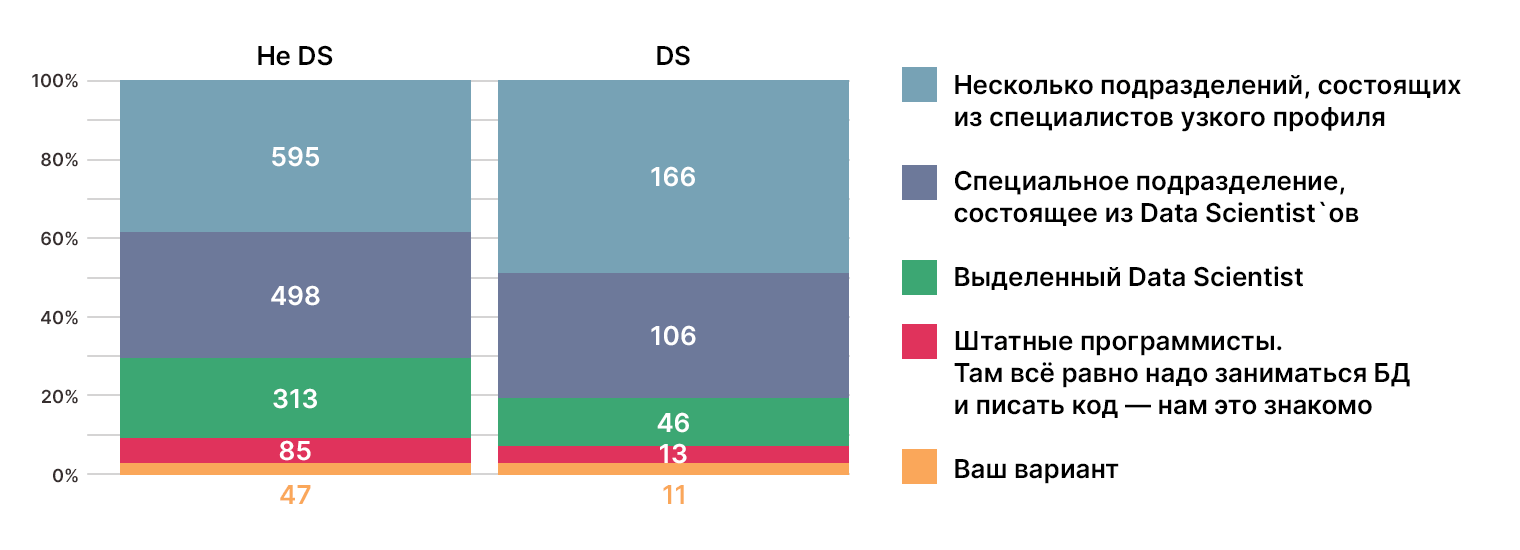
49% DS считает, что анализом данных в компании должны заниматься несколько подразделений. Большинство не DS (40%) придерживаются того же мнения.
На втором месте вариант «специальное подразделение». Голоса распределились поровну — 32−35% среди всех опрошенных.
Также радует то, что меньшинство участников из обеих групп хотят делегировать эту задачу программистам.
Были и не самые очевидные ответы:
“
Человек с аналитическим складом ума, который может из всех мест на парковках во всём городе понять, кто куда поедет домой.
Кто должен заниматься подготовкой данных
47% опрошенных выбрали дата-инженера, 19% — ETL.
Камнем преткновения в данном вопросе выступил Data Analyst: 3% DS и 17% не DS указали, что данные должен подготавливать аналитик. Достаточно большая разница в ответах, скорее всего, вызвана элементарно большим опытом практикующих DS в этой сфере.
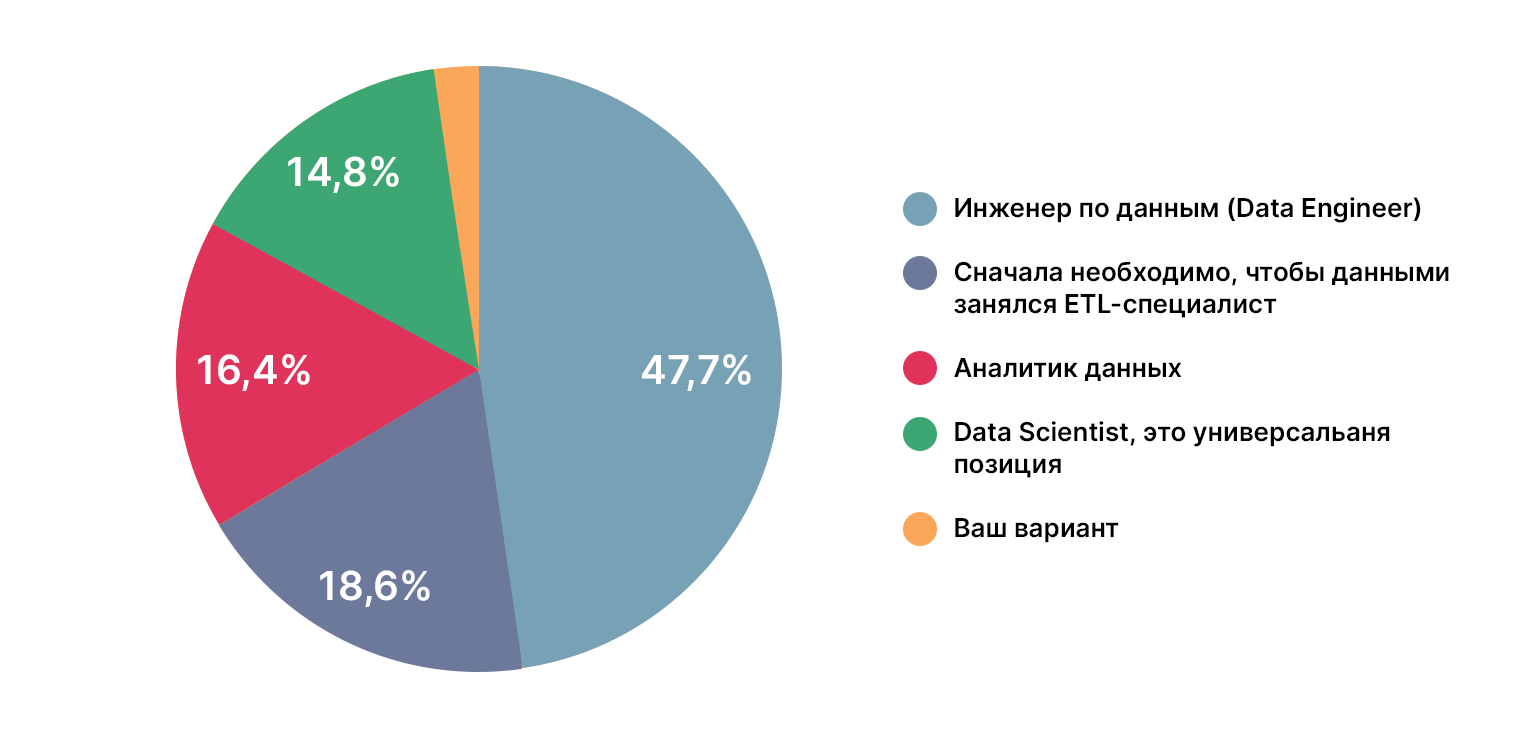
Кто должен заниматься разметкой данных
Большинство поручило эту задачу инженеру и сайентисту. И так же, как и в прошлый раз, прилетела пара новых тасок на аналитика. 13% DS и 27% не DS делегировали эту задачу именно ему.
27% среди тех, кто не работает в DS, можно было бы понять. Но 13% специалистов — достаточно высокий процент. Варианта видится только два: недостаточная квалификация или личная неприязнь.
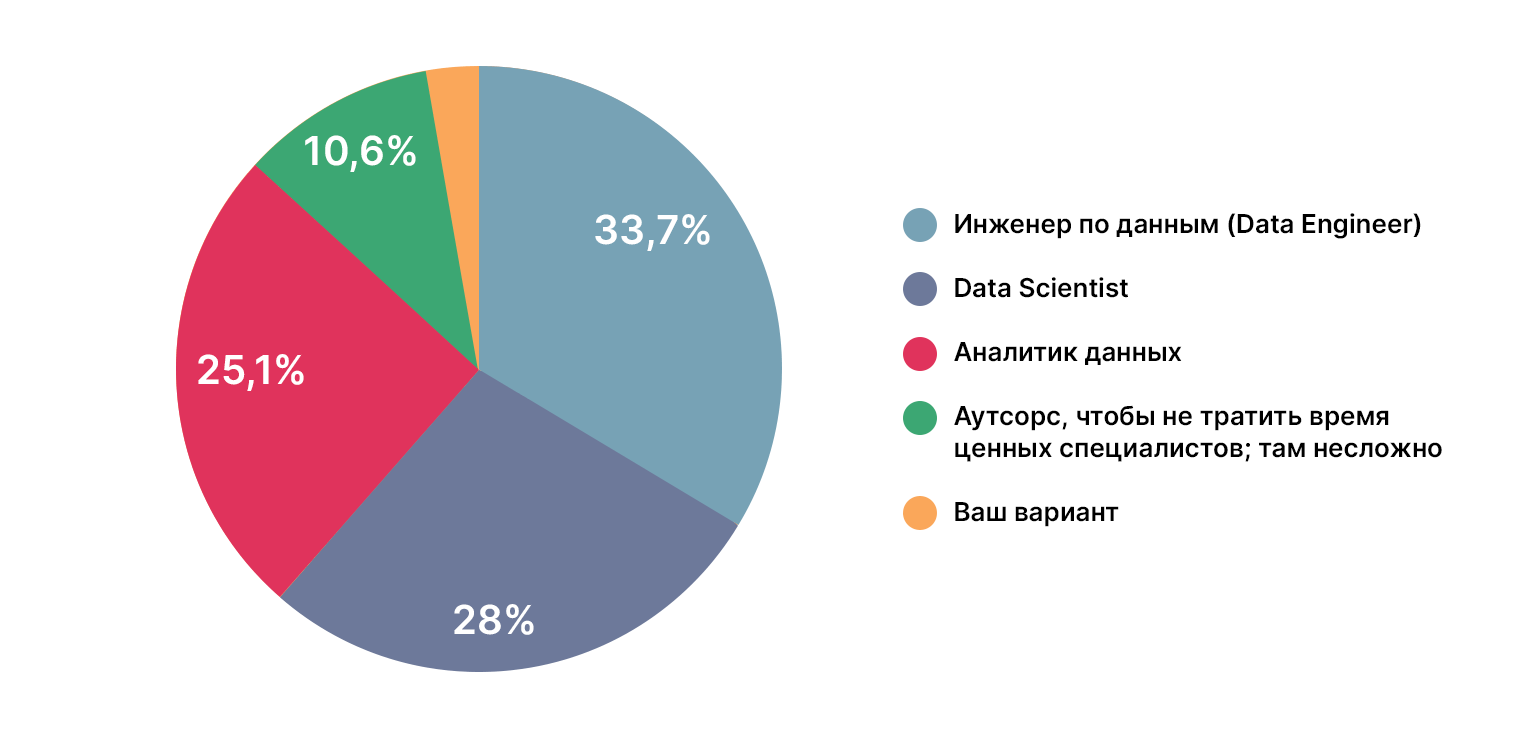
Кто должен заниматься работой с данными
На этот вопрос сообщество ответило практически единогласно: работой с данными должен заниматься DS. Но в 22% случаев может и бизнес-аналитик. Если толковый.
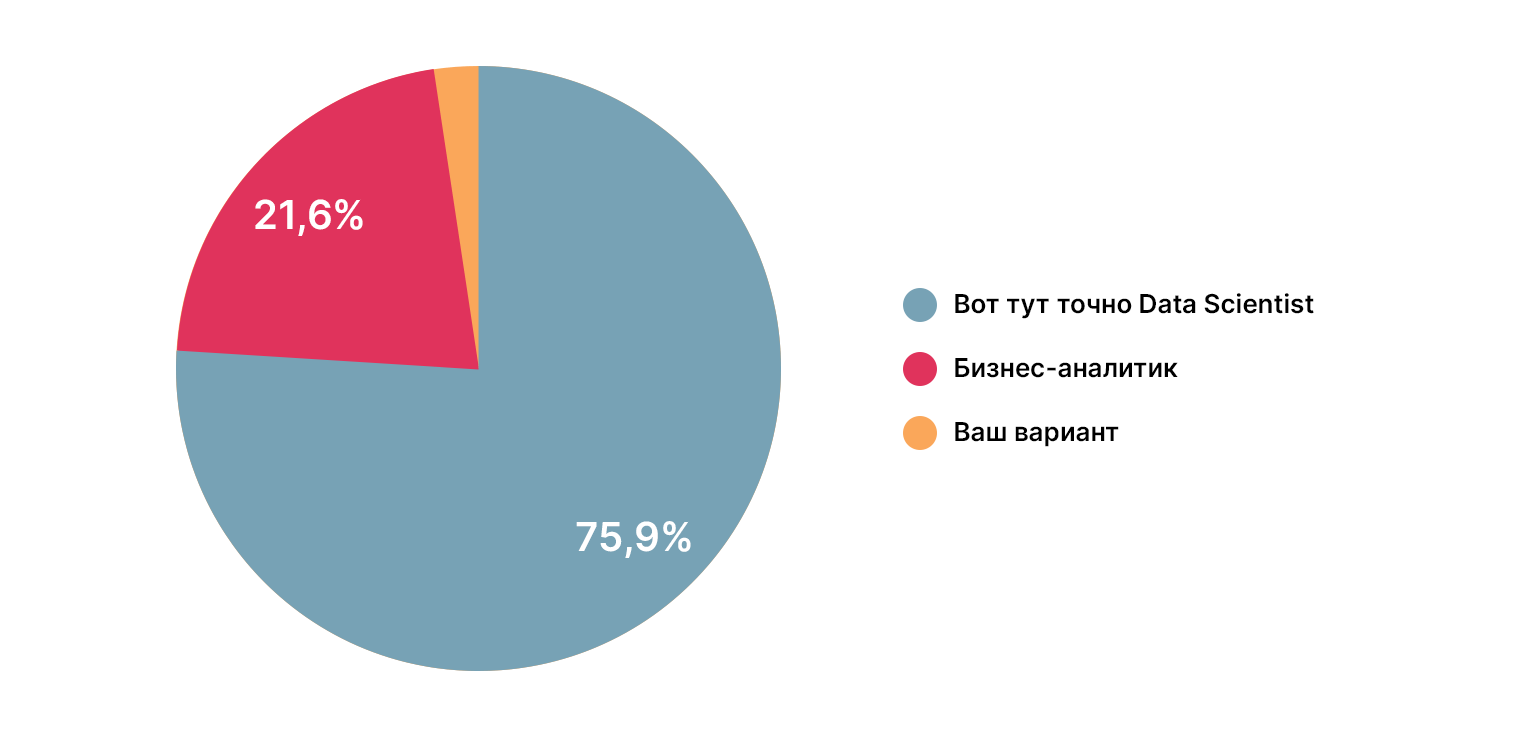
Есть ли разница между Data Engineer, Data Scientist и Data Analyst
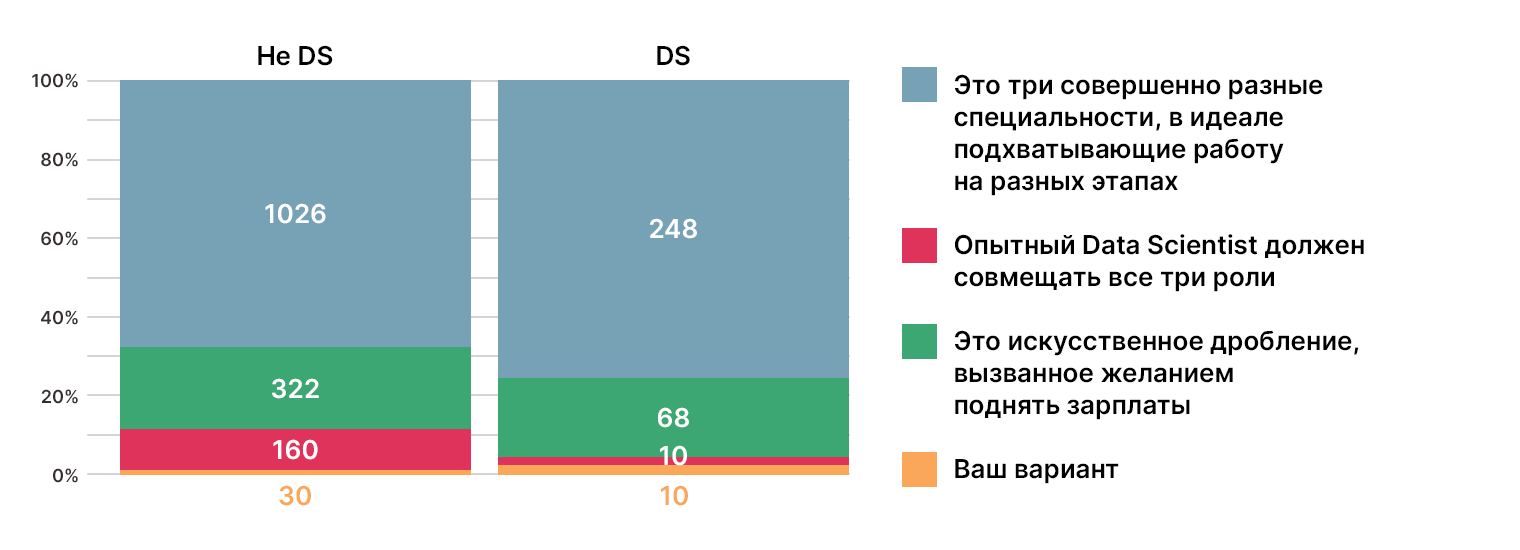
Здесь сообщество выступило консолидированно. Преобладающее большинство видит различия в трёх профессиях. 73% DS и 66% тех, кто не связан с DS, указали, что это три разные специальности. Впрочем, как и полагается, каждый из них должен знать предметную область других, о чём многие написали в своих вариантах:
“
Это разные специальности, но не совершенно разные. В идеале дата-сайентист должен немного уметь и в дата-инженерство.
“
Data Scientist и аналитик — смежные профессии, которые может совмещать один человек. Data Engineer — смежная, но отличающаяся специальность — возможный путь развития разработчика.
“
Это всё строго зависит от размера и типа данных. Опытный дата-сайентист может совмещать эти должности, но он потеряет очень много времени на эти задачи, вместо того чтобы заниматься самим анализом данных.
Кроме того, как подметил один из участников опроса,
“
От специальности меняется требуемый уровень soft skills.
Нужна ли команда с узкой специализацией при работе с данными
80% ответивших согласны с утверждением, и это коррелирует с предыдущими вариантами ответов на тему различий между DE, DA и DS. Действительно, чтобы получить результат, задачи лучше поручать тем, кто в них компетентен, а не пытаться всё взвалить на одного сотрудника. Впрочем, бывают и исключения, но они чаще всего применимы к компаниям на старте деятельности.
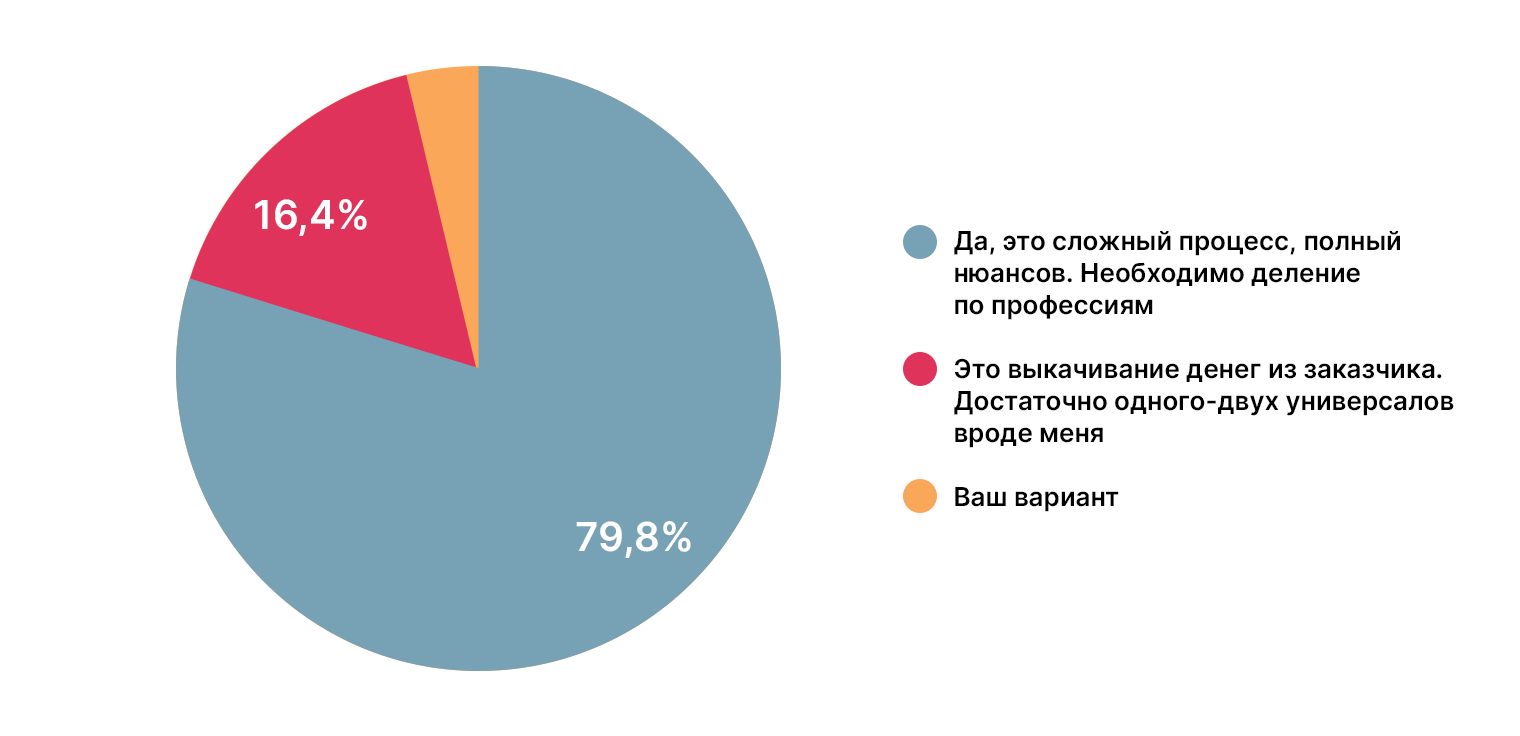
Оптимальный размер команды
Конечно, здесь всё зависит от размера проекта, о чём многие указали в своих вариантах ответа.
Но большинство (49%) за команду от 3 до 5 человек, то есть небольшой отдел, сотрудники которого тесно общаются по рабочим моментам. Кстати, интересное наблюдение: выбор участников опроса коррелирует с одним из законов Паркинсона, который гласит, что 5 человек — оптимальное количество людей в одном кабинете. Этот закон изначально был сформулирован для госучреждений, но в целом прижился во всех сферах:
“
Идеальное число членов — пять человек. При таком численном составе кабинет непременно приживётся. Два его члена смогут всегда отсутствовать по болезни или по иной причине. Пятерых легко собрать, а собравшись, они способны действовать быстро, умело и тихо. Четверым из них можно поручить финансы, иностранные дела, оборону и правосудие. Пятый, не сведущий в этих предметах, станет председателем или премьером.
Игорь Галицкий, Сбер:
DS — сфера, в которой команды могут быть очень разными. Например, R&D или продуктовыми. В продуктовой команде есть определённые роли, и, помимо дата-сайентистов, там обычно нужны как минимум дата-аналитик, дата-инженер и продакт. Важно, чтобы в команде были специалисты смежных специальностей, потому что это позволяет создать комфортные для всех условия работы. Конечно, бывают дата-сайентисты, которые вырастают в тимлидов, — им это нравится, и в Сбере это поощряется. Но не все хотят совмещать роли, поэтому лучше распределять задачи грамотно. Комфортный размер команды в таком составе — примерно пять человек. Как показывает практика, такая команда может вытащить любой проект в любых условиях. Главное, чтобы рабочий процесс был выстроен нормально, и у каждого была понятная зона ответственности. В R&D командах может быть больше участников, и многие из них могут заниматься DS, но и для них работают эти правила.
Откуда берутся дата-сайентисты?
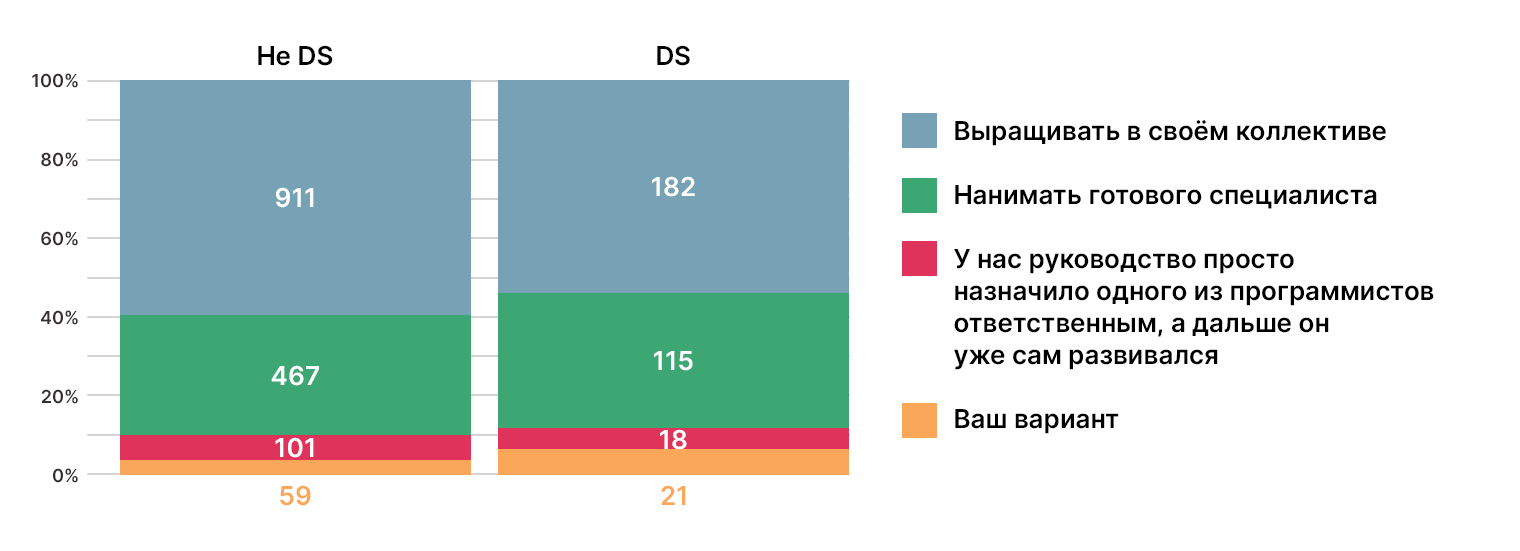
По поводу найма сотрудников сообщество единодушно: 55% DS считают, что лучше воспитывать их самостоятельно. Среди не DS 60% считают так же. По 30% из каждой группы сошлись во мнении, что лучше нанимать готового специалиста. И в обоих случаях примерно 6% опрошенных столкнулись с тем, что роль DS просто перешла программисту по наследству. При этом в своих вариантах ответов многие написали, что лучше применять комбинированный подход, то есть и воспитывать, и хантить, в зависимости от ситуации и потребностей бизнеса.
“
Нанимать со стороны и выращивать изнутри. Если компания быстро растёт, то все средства хороши.
“
Нужен баланс между наймом со стороны и развитием собственных сотрудников.
“
Нанять специалиста по DS и потратить время на погружение в специфику бизнеса.
Инструментарий
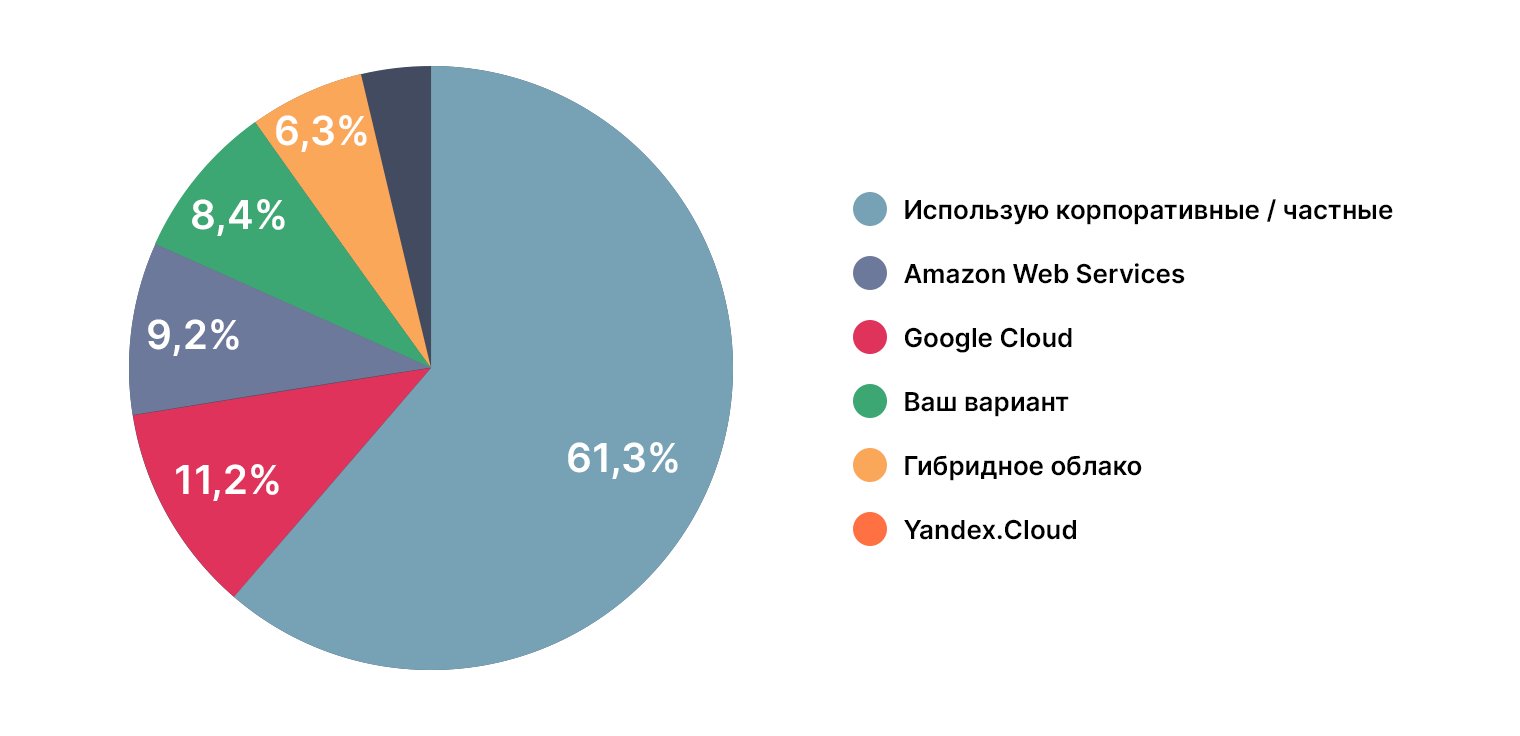
Какие вычислительные мощности используются
Абсолютное большинство (61%) использует в работе частные или корпоративные мощности. На втором месте AWS (11%), на третьем Google Cloud (9%).
Среди DS пара человек указала, что использует On-Premise решения, а также комбинации из частных и публичных, в зависимости от ситуации и проекта.
В целом, учитывая, что большинство прошедших опрос работают в крупных компаниях, распределение ответов выглядит логичным. Ведь поддержание собственной инфраструктуры — процесс сложный и дорогой, малый и средний бизнес просто не готовы этим заморачиваться в большинстве случаев. Что в целом и прослеживается в ответах пользователей. Подавляющее большинство из тех, кто выбрал корпоративные или частные мощности, работают в крупных компаниях:
Как отметил один из участников,
“
Нельзя использовать облачные сервисы, если заранее не готов попрощаться с полной потерей конфиденциальности данных и [смириться c] их незаконным изменением.
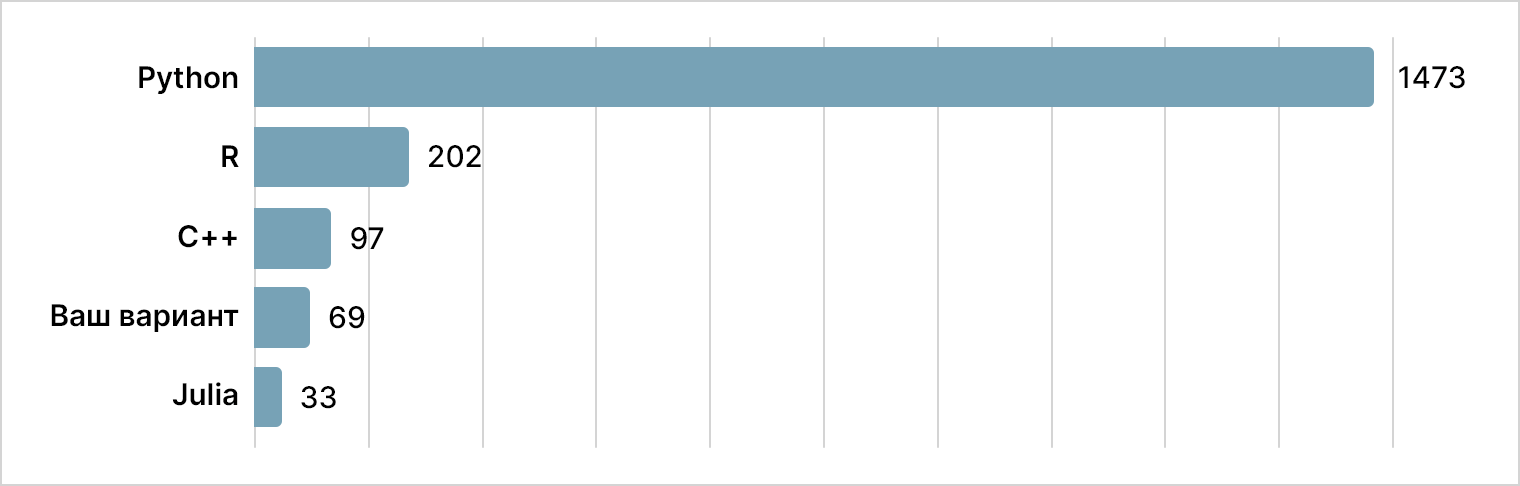
Какой язык программирования
Python уверенно держит позиции. Абсолютное большинство среди обеих рассматриваемых групп пользователей отдали предпочтение ему. Но, конечно же, в списке присутствуют и другие языки. При этом попадались интересные мнения:
“
Тут уж [зависит] от потребностей бизнеса и традиций компании, где-то R, где-то Python, нужна производительность — C++. Как говорил мой начальник, разработка идет на том языке, который знает наш шеф.
Какой инструментарий наиболее функциональный и удобный?
Большинство указало не конкретный инструмент, а их связку, что, конечно же, логично.
Пятёрка лидеров по всем участникам выглядит следующим образом:
- TensorFlow;
- Python;
- PyTorch;
- Scikit-learn;
- Jupyter Notebook
и их всевозможные комбинации между собой.
Также не забыли про Keras, Pandas, Spark, NumPy, Hadoop и R.
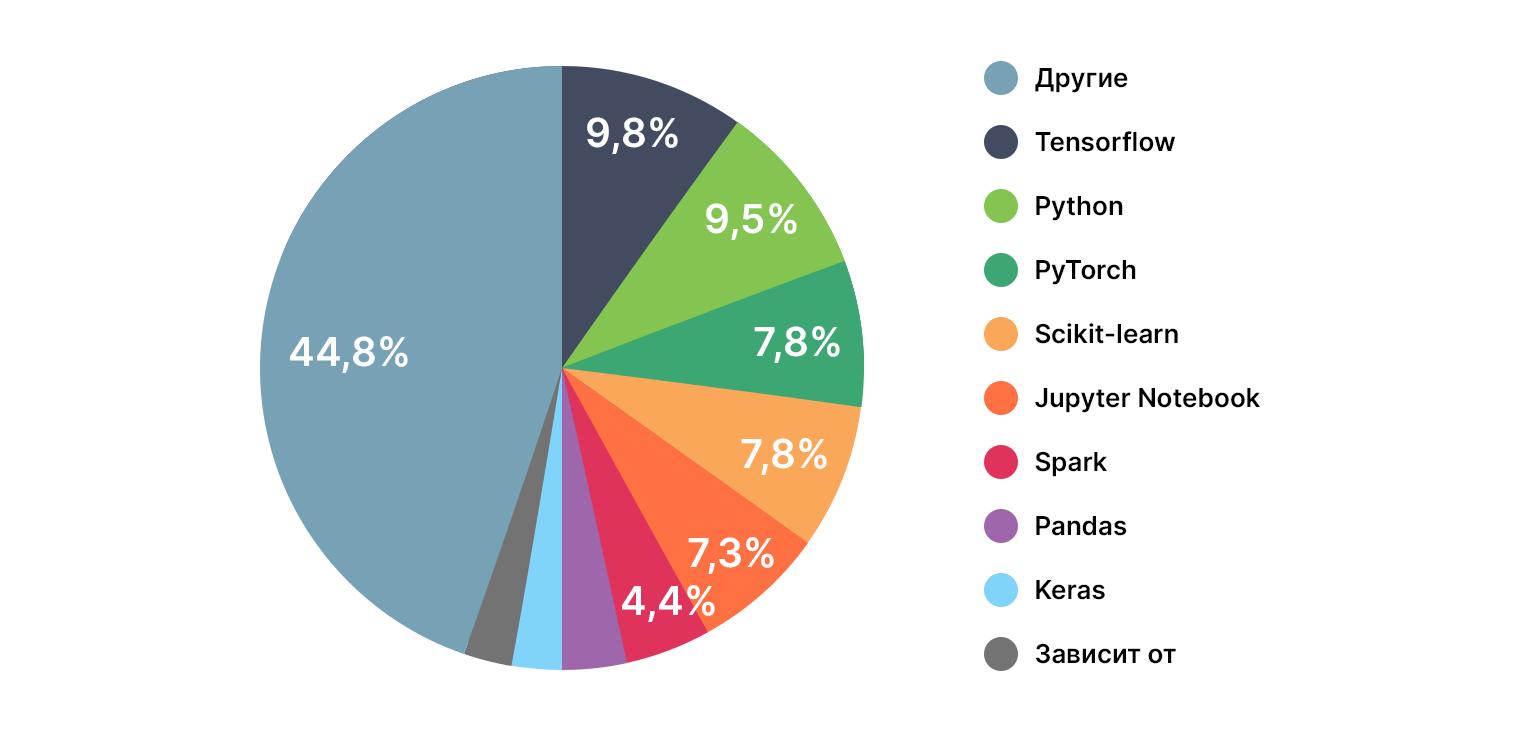
При этом среди практикующих DS большинство указало в качестве основного инструментария PyTorch, в то время как большинство интересующихся назвали TensorFlow.
Учитывая, что PyTorch считается более легким в освоении для начинающих, получается немного парадоксальная ситуация. Но, возможно, лидерство TensorFlow в когорте интересующихся связано с тем, что он чуть более распиарен.
Также нашлись старожилы в профессии, которые используют свои личные наработки:
“
Anaconda + TensorFlow + Pandas + свои; на самом деле TensorFlow + куча собственных статистических библиотек, написанных ещё в 2000–2006 годах.
Распределение ответов не зависит от размера компании или опыта работы DS.
Из интересных вариантов ответов среди интересующихся DS дважды проскочил батюшка Excel, а также весьма неочевидные варианты типа мозга или компьютера, а также «мышление и богатое воображение». Действительно, при работе в сфере DS это всё тоже может пригодиться.
Игорь Галицкий, Сбер:
Помимо стандартных инструментов для DS (Python, Jupyter, PyTorch и т. д.), в командах Сбера используют разные технологии. Для работы с Big Data — Hadoop, Kafka, Spark, Flink, Beam. Инструменты MLOps — Airflow, Jenkins, Nexus3, OpenShift, Docker, DVC, MLflow. Для ускорения DL-пайплайнов — TensorRT, ONNX, OpenVINO, Horovod, DeepSpeed. Ещё мы используем собственные AutoML-фреймворки, например LAMA. А для работы с тяжелыми DL-пайплайнами у нас есть платформа ML Space.
Выводы
Начинающие сайентисты более одиноки. Большинство сайентистов в профессии от года до трёх. Работают они в крупных компаниях и небольших отделах по 3–5 человек с разделением на роли инженера, аналитика и сайентиста. Основные инструменты, используемые в работе, — PyTorch, Python и его библиотеки. Зачастую используются корпоративные сервера, но всё зависит от проекта и задач.
Результаты опроса совпадают с вашими представлениями о профессии DS? Делитесь в комментариях.
P. S. За помощь в проведении анализа благодарим Максима Арбузова (@maxarbuzov).