
Привет, Хабр! Представляю вашему вниманию перевод моей статьи "Understanding the Customer Lifetime Value with Data Science".
Взаимоотношения с клиентами важны для каждой компании и играют ключевую роль в росте бизнеса. Одна из наиболее важных метрик в этой сфере — пожизненная ценность клиента (customer lifetime value, далее LTV) — предсказание чистого дохода, связанного со всеми будущими отношениями с клиентом. Чем дольше клиенты продолжают пользоваться продуктами компании, увеличивая прибыль, тем выше их LTV.
Есть много маркетинговых статей, о том, как важны LTV и сегментирование клиентов. Но, как Data Scientist’а, меня больше интересуют формулы и я хочу понимать, как модель на самом деле работает. Как предсказать LTV, используя только 3 признака? В этом посте я покажу некоторые модели, которые используются для маркетинговой сегментации клиентов и объясню математику, на которой они основаны. Здесь будет много формул, но не переживайте: все уже готово в библиотеках Python. Цель этого блога показать, как математика делает всю работу.
Beta-geometric/negative binomial модель для определения вероятности, что клиент “жив”
Рассмотрим такой пример [из онлайн-сервиса для заказа поездок (такси) по городу]: пользователь зарегистрировался 1 месяц назад, сделал 4 поездки и последняя поездка состоялась 20 дней назад. Основываясь только на этих данных, эта модель может предсказать вероятность, что клиент будет активен в течение определенного периода времени (как показано на графике), а также число транзакций в будущем (которое является основой для понимания ценности клиента в течение всей его “жизни” — взаимоотношений клиента и компании).
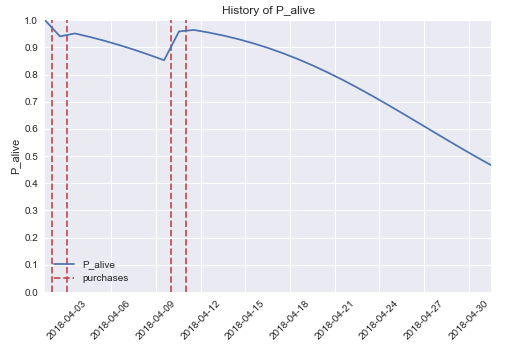
Модель дает прямое руководство к действию для бизнеса: предпринять маркетинговые меры по отношению к пользователю, когда его вероятность активности снижается ниже определенного уровня, чтобы предотвратить его уход.