
Рекурентная нейронная сеть в 10 строчек кода оценила отзывы зрителей нового эпизода “Звездных войн”
11 мин
Hello, Habr! Недавно мы получили от “Известий” заказ на проведение исследования общественного мнения по поводу фильма «Звёздные войны: Пробуждение Силы», премьера которого состоялась 17 декабря. Для этого мы решили провести анализ тональности российского сегмента Twitter по нескольким релевантным хэштегам. Результата от нас ждали всего через 3 дня (и это в самом конце года!), поэтому нам нужен был очень быстрый способ. В интернете мы нашли несколько подобных онлайн-сервисов (среди которых sentiment140 и tweet_viz), но оказалось, что они не работают с русским языком и по каким-то причинам анализируют только маленький процент твитов. Нам помог бы сервис AlchemyAPI, но ограничение в 1000 запросов в сутки нас также не устраивало. Тогда мы решили сделать свой анализатор тональности с блэк-джеком и всем остальным, создав простенькую рекурентную нейронную сеть с памятью. Результаты нашего исследования были использованы в статье “Известий”, опубликованной 3 января.

В этой статье я немного расскажу о такого рода сетях и познакомлю с парой классных инструментов для домашних экспериментов, которые позволят строить нейронные сети любой сложности в несколько строк кода даже школьникам. Добро пожаловать под кат.
В этой статье я немного расскажу о такого рода сетях и познакомлю с парой классных инструментов для домашних экспериментов, которые позволят строить нейронные сети любой сложности в несколько строк кода даже школьникам. Добро пожаловать под кат.

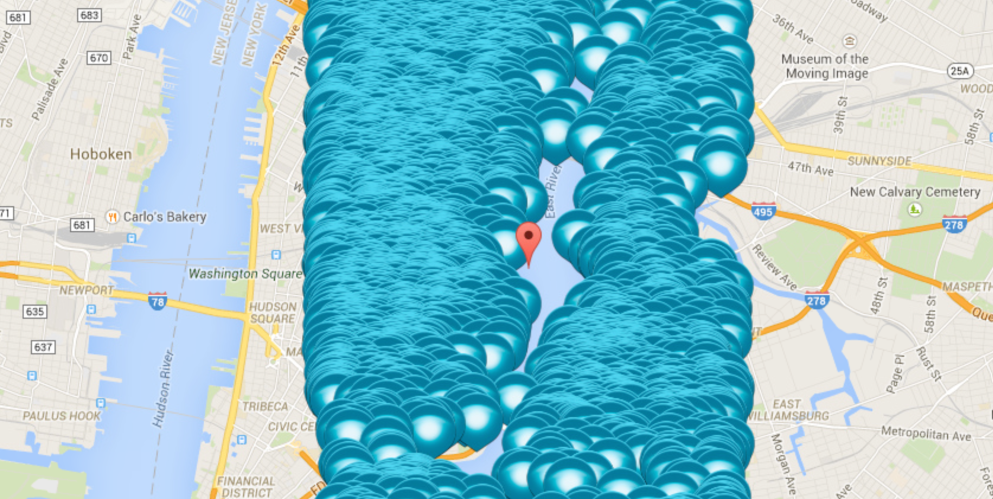

 Но данный подход трудоемок, неточен и не позволит учесть все многообразие отличий квартир друг от друга. Поэтому я решил автоматизировать процесс выбора недвижимости, используя анализ данных путем предсказания «справедливой» цены. В данной публикации описаны основные этапы такого анализа, выбрана лучшая предиктивная модель из восемнадцати протестированных моделей на основании трех критериев качества, в итоге лучшие (недооцененные) квартиры сразу помечаются на карте, и все это используя одно web-приложение, созданное с помощью R.
Но данный подход трудоемок, неточен и не позволит учесть все многообразие отличий квартир друг от друга. Поэтому я решил автоматизировать процесс выбора недвижимости, используя анализ данных путем предсказания «справедливой» цены. В данной публикации описаны основные этапы такого анализа, выбрана лучшая предиктивная модель из восемнадцати протестированных моделей на основании трех критериев качества, в итоге лучшие (недооцененные) квартиры сразу помечаются на карте, и все это используя одно web-приложение, созданное с помощью R.

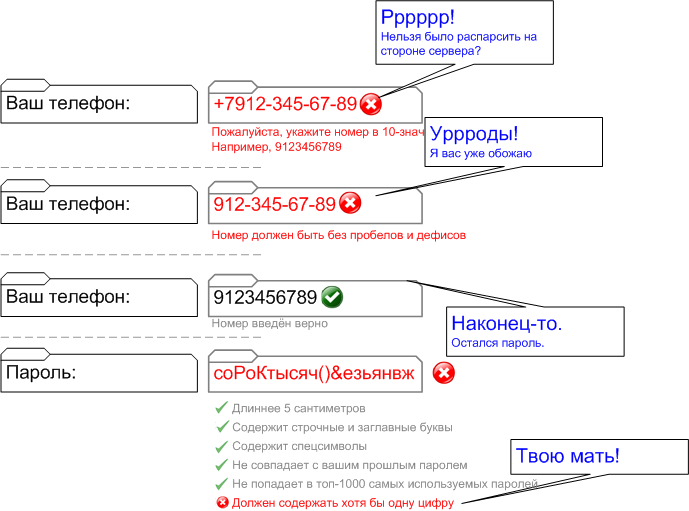
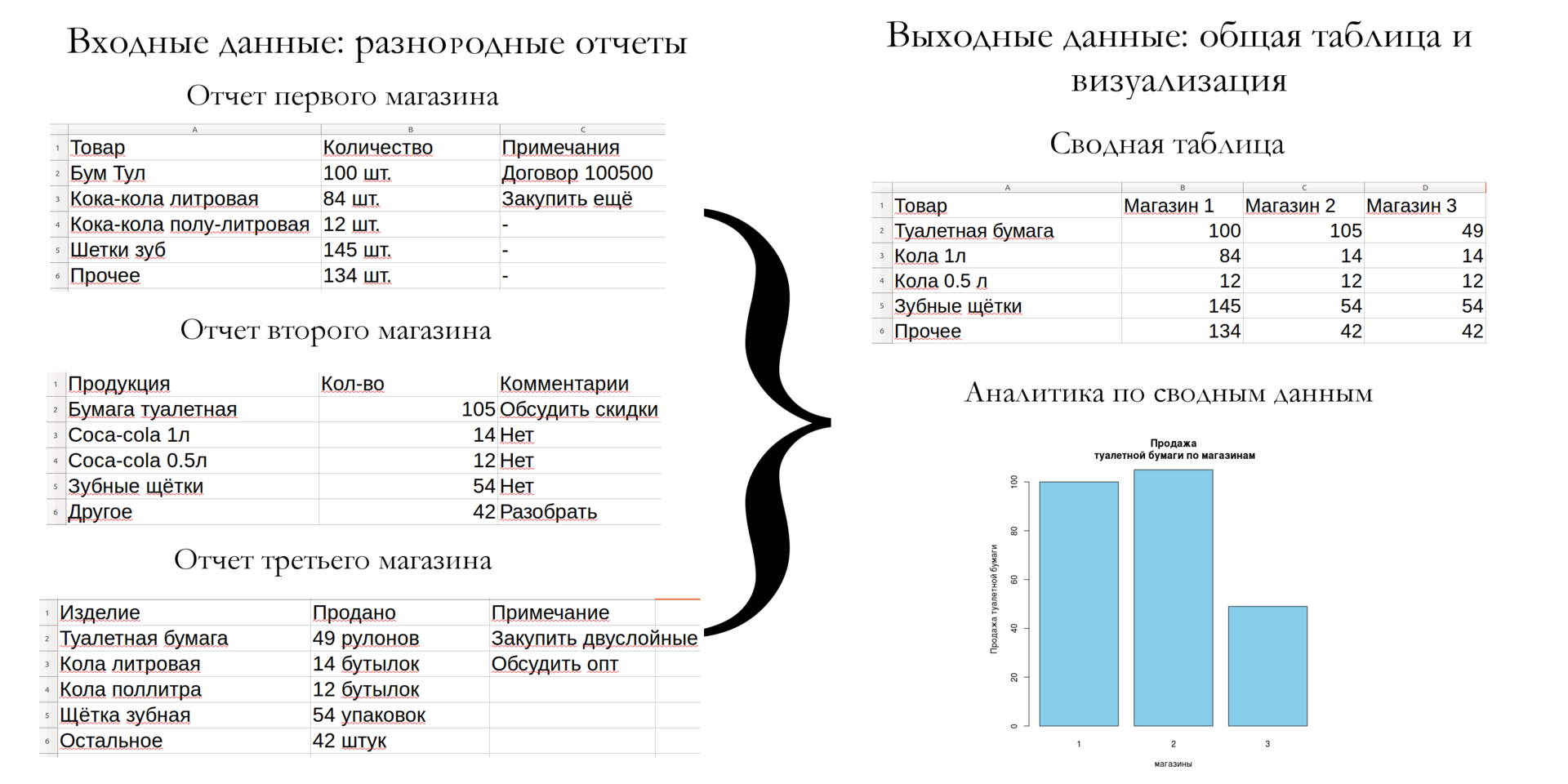






 Или как сделать, чтобы не было мучительно больно за впустую пролетевшие новогодние каникулы?
Или как сделать, чтобы не было мучительно больно за впустую пролетевшие новогодние каникулы?