В предыдущих публикациях (ч. 1 и ч. 2) были рассмотрены основные подходы, применяемые в алгоритме нечеткого поиска TextRadar и особенности решения практических задач. В продолжение начатой в ч. 2 темы оптимизации, сегодня речь пойдет об индексировании, в первую очередь как средстве ускорения поиска в многостраничных текстах, но не только. В результате мы получим тот же результат, что и с использованием описанных ранее подходов, только быстрее.
Задача поиска фразы в тексте, разбитом на страницы, сводится к расчету коэффициента релевантности для каждой из страниц и последующей сортировке списка в порядке убывания коэффициента.
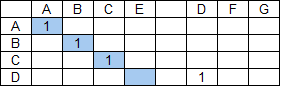
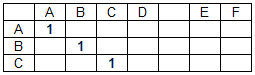
В процессе расчета в соответствии с базовым подходом каждая страница подвергается посимвольному анализу и здесь кроется возможность оптимизации.

Предпосылки
Задача поиска фразы в тексте, разбитом на страницы, сводится к расчету коэффициента релевантности для каждой из страниц и последующей сортировке списка в порядке убывания коэффициента.
В процессе расчета в соответствии с базовым подходом каждая страница подвергается посимвольному анализу и здесь кроется возможность оптимизации.