Иллюстрированная проекция модели сетевого взаимодействия OSI на универсальную последовательную шину.
Три «замечательных» уровня стека USB
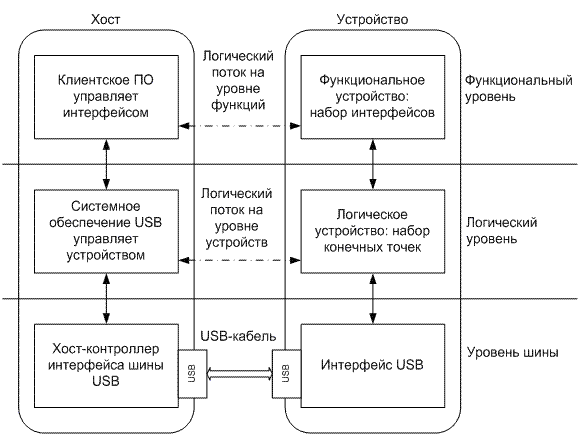
Меня не устроил вид стека USB, который можно встретить чаще всего на просторах сети:
Не сильно полезный стек USB
Уровень шины, логический, функциональный… Это, конечно, замечательные абстракции, но они скорее для тех, кто собирается делать драйвер или прикладной софт для хоста. На стороне же микроконтроллера я ожидаю шаблонный конечный автомат, в узлы которого мы обычно встраиваем свой полезный код, и он сперва будет по всем законам жанра глючить. Или же глючить будет софт на хосте. Или драйвер. В любом случае кто-то будет глючить. В библиотеках МК тоже с наскока не разобраться. И вот я смотрю на трафик по шине USB анализатором, где происходящие события на незнакомом языке с тремя замечательными уровнями вообще не вяжутся. Интересно, это у меня от гриппозной лихорадки в голове такой диссонанс?
Если у читателя бывали сходные ощущения, предлагаю альтернативное, явившееся мне неожиданно ясно в перегретом мозгу видение стека USB, по мотивам любимой 7-уровневой модели OSI. Я ограничился пятью уровнями:

Я не хочу сказать, что весь софт и библиотеки уже сделаны или должны проектироваться, исходя из этой модели. Из инженерных соображений код c уровнями будет сильно перемешан. Но я хочу помочь тем, кто начинает своё знакомство с шиной USB, кто хочет понять протоколы обмена устройств и терминологию предметной области, подобраться поближе к готовым примерам, библиотекам и лучше ориентироваться в них. Эта модель не для загрузки в МК, но в ваши блестящие умы, дорогие друзья. А ваши золотые руки потом всё сами сделают, я не сомневаюсь:)