
Недавно судами разных инстанций и разной подсудности – общей юрисдикции и арбитражными – практически одновременно с одинаковых позиций были рассмотрены иски к Яндексу. Предметом исков являлось удаление из результатов поиска ссылок на информацию, порочащую, по мнению истцов, их честь, достоинство и деловую репутацию. При этом сама информация была размещена на сайтах, не принадлежащих Яндексу, а результаты поиска были релевантны заданному поисковому запросу.
На сегодняшний день в удовлетворении всех исков отказано.
С учетом того, что некоторые аспекты правовых отношений с использованием интернета в российском законодательстве пока урегулированы недостаточно четко, судебная практика играет важную роль. Насколько нам известно, решения по этим искам являются прецедентами для российской судебной практики. Суды решили вопрос о том, является ли интернет-поисковик распространителем информации, независимо от того, «порочащая» это информация или нет. То есть, прямо выразили свою оценку деятельности поисковых систем, и эта оценка совпала с позицией самих поисковиков (в том числе и Яндекса).
В частности, Федеральный арбитражный суд Московской области установил (посмотреть копию постановления), что «поисковый сервис Яндекса не осуществляет распространение информации, а предоставляет пользователям услуги поиска информации, размещенной третьими лицами в сети Интернет». Как и мировая судебная практика, российский суд фактически признал, что поисковая система выполняет техническую роль инструмента в процессе поиска информации в сети, что она является «зеркалом сети», а не её редактором. Поисковик не может и не должен брать на себя роль суда или цензора в отношении информации, создаваемой и распространяемой третьими лицами.
Мы ожидаем, что в дальнейшем как судебная практика, так и законодательные инициативы, касающиеся регулирования интернета в целом и деятельности поисковых систем в частности, пойдут именно по этому пути.
Андрей Середа, юридический отдел Яндекса![]()
«Находить» не значит «распространять»
2 мин
Перевод
 Помнишь ZX-Spectrum, хабрачеловек?
Помнишь ZX-Spectrum, хабрачеловек?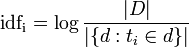




 Сегодня на Hacker News наткнулся на пост о (похоже очень) новом языке "
Сегодня на Hacker News наткнулся на пост о (похоже очень) новом языке "