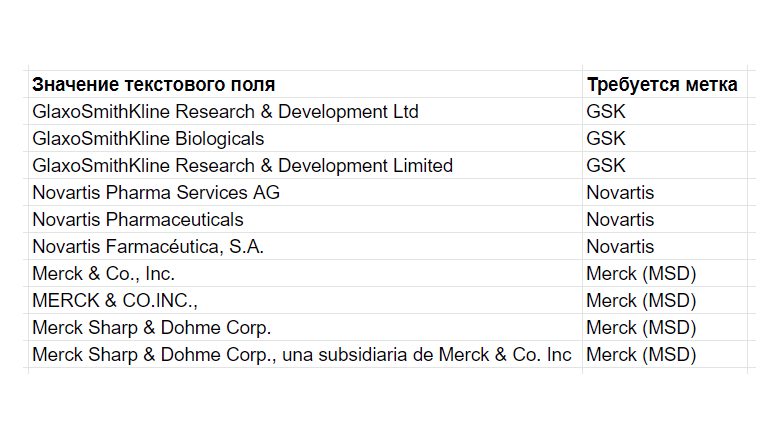
Общедоступные реестры клинических исследований, такие как clinicaltrials.gov, печально известны низкой структурированностью данных. Попытка построить сводный отчет, например, о количестве исследований, проводимых ведущими фармкомпаниями, натыкается на давно всем надоевшую проблему множественных написаний одинаковых по смыслу значений.
В очередной раз столкнувшись с этой проблемой при анализе данных в pandas, я решил подключить к решению CountVectorizer из scikit-learn. Результат показался интересным. Сразу оговорюсь, что в данном случае я не использую методы и алгоритмы машинного обучения, а только CountVectorizer как инструмент.
Традиционными инструментами в сфере Data Science являются такие языки, как R и Python — расслабленный синтаксис и большое количество библиотек для машинного обучения и обработки данных позволяет достаточно быстро получить некоторые работающие решения. Однако бывают ситуации, когда ограничения этих инструментов становятся существенной помехой — в первую очередь, если необходимо добиться высоких показателей по скорости обработки и/или работать с действительно крупными массивами данных. В этом случае специалисту приходится, скрепя сердце, обращаться к помощи "темной стороны" и подключать инструменты на "промышленных" языках программирования: Scala, Java и C++.
Но так ли уж темна эта сторона? За годы развития инструменты "промышленного" Data Science прошли большой путь и сегодня достаточно сильно отличаются от своих же версий 2-3 летней давности. Давайте попробуем на примере задачи SNA Hackathon 2019 разобраться, насколько экосистема Scala+Spark может соответствовать Python Data Science.
16 марта закончилось соревнование по машинному обучению ML Boot Camp III. Я не настоящий сварщик, но, тем не менее, смог добиться 7го места в финальной таблице результатов. В данной статье я хотел бы поделиться тем, как начать участвовать в такого рода чемпионатах, на что стоит обратить внимание в первый раз при решении задачи, и рассказать о своем подходе.