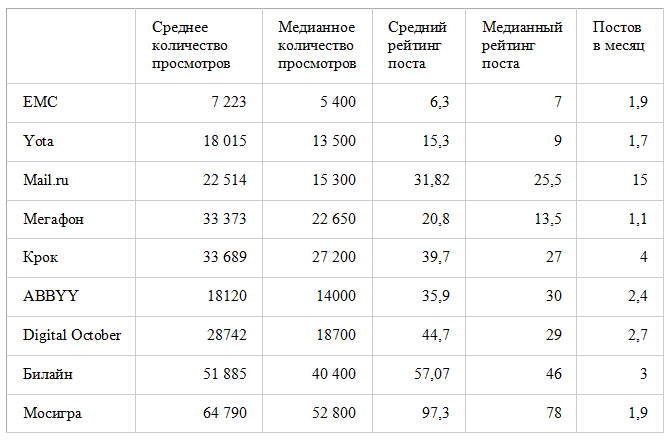
Функторы, аппликативные функторы и монады в картинках
5 мин
Перевод
Вот некое простое значение:

И мы знаем, как к нему можно применить функцию:
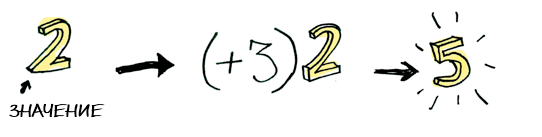
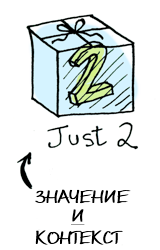
Элементарно. Так что теперь усложним задание — пусть наше значение имеет контекст. Пока что вы можете думать о контексте просто как о ящике, куда можно положить значение:
Теперь, когда вы примените функцию к этому значению, результаты вы будете получать разные — в зависимости от контекста. Это основная идея, на которой базируются функторы, аппликативные функторы, монады, стрелки и т.п. Тип данных
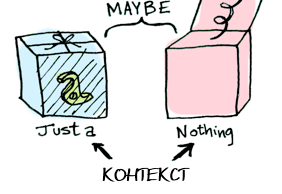
Позже мы увидим разницу в поведении функции для
И мы знаем, как к нему можно применить функцию:
Элементарно. Так что теперь усложним задание — пусть наше значение имеет контекст. Пока что вы можете думать о контексте просто как о ящике, куда можно положить значение:
Теперь, когда вы примените функцию к этому значению, результаты вы будете получать разные — в зависимости от контекста. Это основная идея, на которой базируются функторы, аппликативные функторы, монады, стрелки и т.п. Тип данных
Maybe определяет два связанных контекста:data Maybe a = Nothing | Just a
Позже мы увидим разницу в поведении функции для
Just a против Nothing. Но сначала поговорим о функторах!


 abstract: В статье описаны продвинутые функций OpenSSH, которые позволяют сильно упростить жизнь системным администраторам и программистам, которые не боятся шелла. В отличие от большинства руководств, которые кроме ключей и -L/D/R опций ничего не описывают, я попытался собрать все интересные фичи и удобства, которые с собой несёт ssh.
abstract: В статье описаны продвинутые функций OpenSSH, которые позволяют сильно упростить жизнь системным администраторам и программистам, которые не боятся шелла. В отличие от большинства руководств, которые кроме ключей и -L/D/R опций ничего не описывают, я попытался собрать все интересные фичи и удобства, которые с собой несёт ssh. Само наличие психологической деформации у какой-либо профессии, как правило, достаточно спорный момент ввиду того, что у разных людей она проявляется по-разному. Однако общую тенденцию можно выделить и, пожалуй, настало то время когда можно достаточно смело говорить, что программисты всё же имеют свой особенный психологический портрет который обусловлен их профессиональной деятельностью.
Само наличие психологической деформации у какой-либо профессии, как правило, достаточно спорный момент ввиду того, что у разных людей она проявляется по-разному. Однако общую тенденцию можно выделить и, пожалуй, настало то время когда можно достаточно смело говорить, что программисты всё же имеют свой особенный психологический портрет который обусловлен их профессиональной деятельностью.