Существует типичная проблема в большом классе задач, которая возникает при обработке потока сообщений:
— нельзя пропихнуть большого слона через маленькую трубу, или другими словами, обработка сообщений не успевает
«проглотить» все сообщения.
При этом существуют некоторые ограничения на поток данных:
- поток не равномерный и состоит из событий разного типа
- количество типов событий заранее не известно, но некоторое конечное число
- каждый тип события имеет свою актуальность во времени
- все типы событий имеют равный приоритет
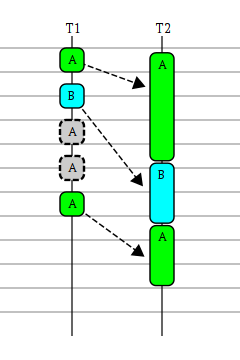
На диаграмме приведён пример разрешения проблемы:
нагребатор(tm), работающий на нитке
T1, в то время как
разгребатор(tm) работает на нитке
T2
- за время обработки события типа A успевают прийти новые события как типа B, так и A
- после обработки события типа B необходимо обработать наиболее актуальное событие типа A
Т.о. стоит задача о выполнении задач по ключу, так, что выполняется только самая актуальная из всех задач по данному ключу.
На суд публике представляется созданный нами
ThrottlingExecutor.
Замечание терминологии: stream есть
поток данных, тогда как
thread есть
нитка или
нить выполнения. И не стоит путать потоки с нитками.
Замечание 1: проблема осложняется ещё тем, что может быть несколько
нагребаторов(tm), при этом каждый
нагребатор(tm) может порождать только события одного типа; с другой стороны есть потребность в нескольких (конечно же, для простоты можно выбрать
N=1)
разгребаторах(tm).
Замечание 2: мало того, что данный код должен работать в многопоточной (конкурентной) среде — т.е то самое множество
нагребаторов(tm) —
разгребаторов(tm), код должен работать с максимальной производительностью и низкими latency. Резонно к этим всем качествам добавить ещё и свойство
garbage less.
И почти в каждом проекте так или иначе возникает эта задача, и каждый её решает по разному, но все они либо не эффективны, либо медленны, либо и то, и другое вместе взятое.

 Прошлой ночью в возрасте 88 лет умер Дуглас Энгельбарт (Douglas Engelbart). Его дочь пишет, что отец скончался мирно во сне, в своём доме.
Прошлой ночью в возрасте 88 лет умер Дуглас Энгельбарт (Douglas Engelbart). Его дочь пишет, что отец скончался мирно во сне, в своём доме.
 Некоторое время назад зам.главы московского офиса разработки Badoo Алексей Рыбак и ведущие IT-Компот записали выпуск подкаста «Архитектура высоконагруженных приложений. Масштабирование распределенных систем".
Некоторое время назад зам.главы московского офиса разработки Badoo Алексей Рыбак и ведущие IT-Компот записали выпуск подкаста «Архитектура высоконагруженных приложений. Масштабирование распределенных систем".

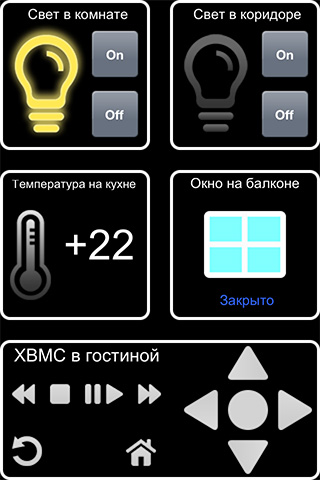

 Многие пытаются собрать «Умный дом» своими руками. При выборе системы стоит учитывать не только ассортимент и стоимость конечных устройств, но и возможности контроллера. Большинство контроллеров сразу готовы к работе «из коробки», но представляют ограниченные возможности. Однако нередко именно гибкость и возможность лёгкой интеграции является основополагающим критерием при выборе.
Многие пытаются собрать «Умный дом» своими руками. При выборе системы стоит учитывать не только ассортимент и стоимость конечных устройств, но и возможности контроллера. Большинство контроллеров сразу готовы к работе «из коробки», но представляют ограниченные возможности. Однако нередко именно гибкость и возможность лёгкой интеграции является основополагающим критерием при выборе.
 На Tuts+ опубликован новый курс учебных скринкастов "
На Tuts+ опубликован новый курс учебных скринкастов "