Здравствуй «ХабраСообщество»!
Выкладываю небольшой обзор и результаты тестирования основных алгоритмов сжатия с Java.
Кому интересно прошу под кат, кому нет — просьба не минусовать и сказать, что тема не достойна хабра – уберу в черновики.
Итак:
Steria.LZH 100
java.util.zip.GZIP(stream) 1000
java.util.zip.Deflater.BEST_COMPRESSION (block) 1000
java.util.zip.Deflater.BEST_SPEED (block) 1000
java.util.zip.Deflater.HUFFMAN_ONLY (block) 1000
apache.commons.compress.BZIP2 (stream) 10
apache.commons.compress.GZIP (stream) 1000
apache.commons.compress.XZ (stream) 10
com.ning.LZF (block) 1000
com.ning.LZF (stream) 10
QuickLZ (block) 1000
org.xerial.snappy.Snappy (block) 1000
Код — мое творение, у каждого свой стиль. Так что прошу ПРАВИЛЬНОСТЬ сильно не обсуждать.
TextDat_1Kb.txt – простой текст какой-то статьи из википедии(англ).
TextDat_100Kb.txt — простой текст каких-то статей из википедии(англ).
TextDat_1000Kb.txt — простой текст каких-то статей из википедии(англ, нем, исп..).
PdfDat_200Kb.pdf – то же что и *.doc только переконвертированно и подогнан размер.
PdfDat_1000Kb.pdf – то же что и *.doc только переконвертированно и подогнан размер.
PdfDat_2000Kb.pdf – то же что и *.doc только переконвертированно и подогнан размер.
HtmlDat_10Kb.htm – текст какой-то документации без рисунков с тэгами, тоисть форматированный html.
HtmlDat_100Kb.htm – текст какой-то документации без рисунков с тэгами, тоисть форматированный html.
HtmlDat_1000Kb.htm – текст какой-то документации без рисунков с тэгами, тоисть форматированный html.
ExcelDat_200Kb.xls – забит случайными числами от 0 до 1 excel-функцией random().
ExcelDat_1000Kb.xls – забит случайными числами от 0 до 1 excel-функцией random().
ExcelDat_2000Kb.xls – забит случайными числами от 0 до 1 excel-функцией random().
DocDat_500Kb.doc — тексты статей из википедий с несколькими рисунками (англ, нем, исп..).
DocDat_1000Kb.doc — тексты статей из википедий с несколькими рисунками (англ, нем, исп..).
DocDat_2000Kb.doc — тексты статей из википедий с несколькими рисунками (англ, нем, исп..).
HtmDat_30000Kb.htm – форматированный текст и таблицы с числами.


…
Сделал я это правильно, не правильно, — надеюсь, что правильно, но сделал! У кого какие соображения, готов к критике! Выкладываю — может кому пригодится.
Некоторые результаты для меня странные, но такие какие числа получились в итоге, то и занес в табличку.
Не знаю есть ли возможность аккуратно вставлять excel-таблицы, поэтому закидываю рисунками. Если кому-то нужен excel-файлик – залью без проблем.
P.S. Спасибо за внимание, рад что дочитали до конца. :)
Выкладываю небольшой обзор и результаты тестирования основных алгоритмов сжатия с Java.
Кому интересно прошу под кат, кому нет — просьба не минусовать и сказать, что тема не достойна хабра – уберу в черновики.
Итак:
- SteriaLZH – это имплементация lzh алгоритма который сейчас актуальный в проекте над которым трудится фирма, и из-за чего появилось задание найти лучшую альтернативу.
- протестированы не все найденные алгоритмы(имплементации компрессии файла, данных). Например JZip от JCraft, и еще несколько, все что протестировал видно в табличке.
- тестировалась только компрессия, декомпрессию не тестировал.
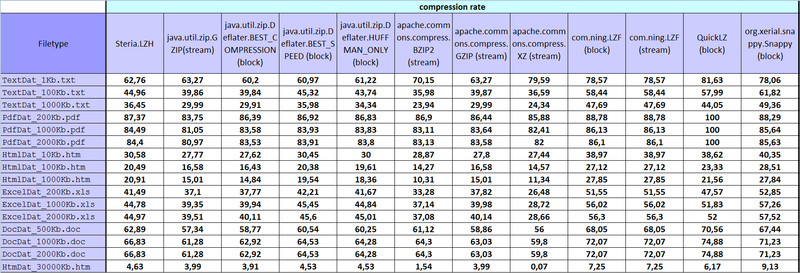
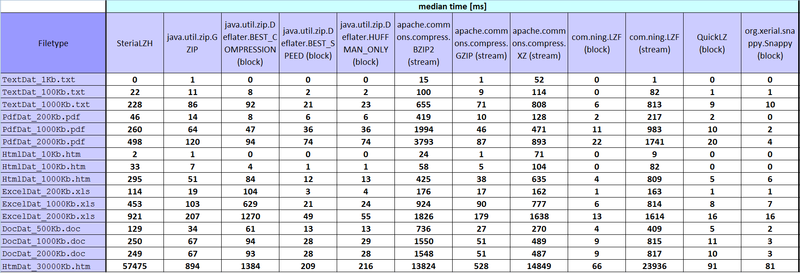
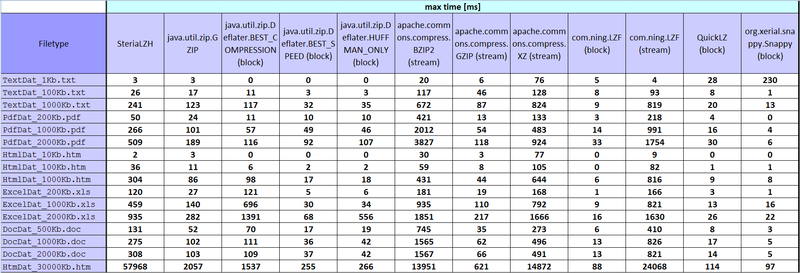
- при тестировании рассчитывались 5 параметров: compression rate, min time [ms], average time [ms], median time [ms], max time [ms].
- хорошие компрессоры прогоняли файлы по 1000 раз, не очень по 10. Ниже табличка что, сколько и по чем.
- stream — имплементация (алгоритмы): принимаем имя файла, потом соответственно читаем файл в InputStream и создаем(сохраняем) с помощью OutputStream.
- block — имплементация (алгоритмы): принимаем файл как byte[], компрессируем, обратно получаем скомпрессированный byte[].
- При stream-компрессии скомпрессированные файлы удалялись перед тем как создавались заново.
- тестировалось на рабочей машинке lenovo thinkpad T420 (Intel Core i5-2540M, CPU 2.6GHz, 4 GR RAM), WinXP:SP3.
Табличка, что и сколько раз прогонялось:
Steria.LZH 100
java.util.zip.GZIP(stream) 1000
java.util.zip.Deflater.BEST_COMPRESSION (block) 1000
java.util.zip.Deflater.BEST_SPEED (block) 1000
java.util.zip.Deflater.HUFFMAN_ONLY (block) 1000
apache.commons.compress.BZIP2 (stream) 10
apache.commons.compress.GZIP (stream) 1000
apache.commons.compress.XZ (stream) 10
com.ning.LZF (block) 1000
com.ning.LZF (stream) 10
QuickLZ (block) 1000
org.xerial.snappy.Snappy (block) 1000
Вот так вот производились измерения.
Код — мое творение, у каждого свой стиль. Так что прошу ПРАВИЛЬНОСТЬ сильно не обсуждать.
время: для каждого отдельного алгоритма(имплементации) был создан класс с public функцией которую я и вызываю передавая ей как аргумент или путь к файлу или byte[].
start = System.nanoTime(); byte[] compressedArray = compressor.compressing(arrayToCompress); end = System.nanoTime(); resultTime = end - start; start = System.nanoTime(); compressor.compressing(fileToCompress); end = System.nanoTime(); resultTime = end - start;
Измерение min time [ms], average time [ms], median time [ms], max time [ms]: в ArrayList получали все измеренные значения времени определенного файла.
private void minMaxMedianAverCalculation(int element) { ResultsSaver resultsSaver = (ResultsSaver) compressorsResults.get(activeTest); ArrayList<Long> elementsList = new ArrayList<Long>(); for (int i = 0; i < TEST_COUNT; i++) { long timeElement = resultsSaver.getNanoSecondsTime(i, element); elementsList.add(timeElement); } Collections.sort(elementsList); this.min = (elementsList.get(0)) / 1000000; this.max = (elementsList.get(elementsList.size() - 1)) / 1000000; int elementsListLength = elementsList.size(); if (elementsListLength % 2 == 0) { int m1 = (elementsListLength - 1) / 2; int m2 = m1 + 1; this.median = ((elementsList.get(m1) + elementsList.get(m2)) / 2) / 1000000; } else { int m = elementsListLength / 2; this.median = elementsList.get(m) / 1000000; } long totalTime = 0; for (int i = 0; i < elementsListLength; i++) { totalTime += elementsList.get(i); } this.average = (totalTime / TEST_COUNT)/1000000; }
Измерение stream compression rate:
private void setStreamCompressionRatio(String toCompressFileName, String compressedFileName) { ResultsSaver resultsSaver = (ResultsSaver) compressorsResults.get(activeTest); File fileToCompress = new File(toCompressFileName); long fileToCompressSize = fileToCompress.length(); File compressedFile = new File(compressedFileName); long compressedFileSize = compressedFile.length(); double compressPercent = Math.round(((double) compressedFileSize * 100) / fileToCompressSize * 100) / 100.0d; resultsSaver.setCompressionRatio(compressPercent); }
Измерение block compression rate:
private void setBlockCompressionRatio(byte[] arrayToCompress, byte[] compressedArray) { ResultsSaver resultsSaver = (ResultsSaver) compressorsResults.get(activeTest); long arrayToCompressSize = arrayToCompress.length; long compressedArraySize = compressedArray.length; double compressPercent = Math.round(((double) compressedArraySize * 100) / arrayToCompressSize * 100) / 100.0d; resultsSaver.setCompressionRatio(compressPercent); }
Что компрессировали:
TextDat_1Kb.txt – простой текст какой-то статьи из википедии(англ).
TextDat_100Kb.txt — простой текст каких-то статей из википедии(англ).
TextDat_1000Kb.txt — простой текст каких-то статей из википедии(англ, нем, исп..).
PdfDat_200Kb.pdf – то же что и *.doc только переконвертированно и подогнан размер.
PdfDat_1000Kb.pdf – то же что и *.doc только переконвертированно и подогнан размер.
PdfDat_2000Kb.pdf – то же что и *.doc только переконвертированно и подогнан размер.
HtmlDat_10Kb.htm – текст какой-то документации без рисунков с тэгами, тоисть форматированный html.
HtmlDat_100Kb.htm – текст какой-то документации без рисунков с тэгами, тоисть форматированный html.
HtmlDat_1000Kb.htm – текст какой-то документации без рисунков с тэгами, тоисть форматированный html.
ExcelDat_200Kb.xls – забит случайными числами от 0 до 1 excel-функцией random().
ExcelDat_1000Kb.xls – забит случайными числами от 0 до 1 excel-функцией random().
ExcelDat_2000Kb.xls – забит случайными числами от 0 до 1 excel-функцией random().
DocDat_500Kb.doc — тексты статей из википедий с несколькими рисунками (англ, нем, исп..).
DocDat_1000Kb.doc — тексты статей из википедий с несколькими рисунками (англ, нем, исп..).
DocDat_2000Kb.doc — тексты статей из википедий с несколькими рисунками (англ, нем, исп..).
HtmDat_30000Kb.htm – форматированный текст и таблицы с числами.
Иии, результаты: habrastorage.org — выдал такие картинки, полно размерные 1800*615, может кто знает как сделать увеличение по клику?
…
Сделал я это правильно, не правильно, — надеюсь, что правильно, но сделал! У кого какие соображения, готов к критике! Выкладываю — может кому пригодится.
Некоторые результаты для меня странные, но такие какие числа получились в итоге, то и занес в табличку.
Не знаю есть ли возможность аккуратно вставлять excel-таблицы, поэтому закидываю рисунками. Если кому-то нужен excel-файлик – залью без проблем.
P.S. Спасибо за внимание, рад что дочитали до конца. :)

