Пару недель назад, необходимо было освежить информацию в голове информацию по структурам данных и алгоритмам для собеседования. Первым делом полез на www.coursera.org, где хотел пробежаться по некоторым лекциям курса Алгоритмы, там же были две сводные таблички, которые в процессе изучения курса взял на заметку — отлично помогали запомнить сложность операций. Но, к моему удивлению, материалы пройденного курса стали недоступны. Быстрое гугление, в надежде, что кто-нибудь выложил лекции на торрентах, к сожалению, не дало результатов. В итоге, я нашел полную коллекцию слайдов по данному курсу. Спешу поделиться. Самое главное, что взял из этих слайдов, — это вышеупомянутые сводные таблички. Думаю многим пригодится.

Антон Виноградов @randoom
Java developer
Почему нужно 1000 раз подумать, прежде чем использовать noSQL
6 мин
Зачем я пишу эту статью? Во-первых я хотел бы внести свой вклад в понимание людьми сути nosql и того, почему выбирать такой тип хранилища нужно осознанно. Во-вторых, я буду рад встретить единомышленников, противников и, возможно, подискутировать. А если Вам понравилась эта статья, то буду рад услышать вопросы, которые можно раскрыть более подробно в новых статьях:)
Несмотря на то, что nosql решений сейчас тьма, люди неохотно переходят на новые типы хранилищ. Правильно ли это? На мой взгляд – да. И я постараюсь сказать почему, на примере разных nosql хранилищ, которые встретились на моём профессиональном пути.
Несмотря на то, что nosql решений сейчас тьма, люди неохотно переходят на новые типы хранилищ. Правильно ли это? На мой взгляд – да. И я постараюсь сказать почему, на примере разных nosql хранилищ, которые встретились на моём профессиональном пути.
Структуры данных в картинках. LinkedHashMap
4 мин
Привет Хабрачеловеки!
После затяжной паузы, я попробую продолжить визуализировать структуры данных в Java. В предыдущих статьях были замечены: ArrayList, LinkedList, HashMap. Сегодня заглянем внутрь к LinkedHashMap.
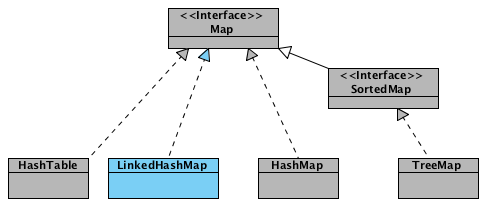
Из названия можно догадаться что данная структура является симбиозом связанных списков и хэш-мапов. Действительно, LinkedHashMap расширяет класс HashMap и реализует интерфейс Map, но что же в нем такого от связанных списков? Давайте будем разбираться.
После затяжной паузы, я попробую продолжить визуализировать структуры данных в Java. В предыдущих статьях были замечены: ArrayList, LinkedList, HashMap. Сегодня заглянем внутрь к LinkedHashMap.
Из названия можно догадаться что данная структура является симбиозом связанных списков и хэш-мапов. Действительно, LinkedHashMap расширяет класс HashMap и реализует интерфейс Map, но что же в нем такого от связанных списков? Давайте будем разбираться.
Размер Java объектов. Используем полученные знания
5 мин
В предыдущей статье много комментаторов были не согласны в необходимости наличия знаний о размере объектов в java. Я категорически не согласен с этим мнением и поэтому подготовил несколько практических приемов, которые потенциально могут пригодится для оптимизации в Вашем приложении. Хочу сразу отметить, что не все из данных приемов могут применяться сразу во время разработки. Для придания большего драматизма, все расчеты и цифры будут приводится для 64-х разрядной HotSpot JVM.
Итак, давайте рассмотрим следующий код:
А теперь проведем денормализацию:
Казалось бы — избавились от композиции и все. Но нет. Объект класса Cursor2 потребляет приблизительно на 30% меньше памяти чем объект класса Cursor (по сути Cursor + Position). Такое вот не очевидное следствие декомпозиции. За счет ссылки и заголовка лишнего объекта. Возможно это кажется не важным и смешным, но только до тех пор, пока объектов у Вас мало, а когда счет идет на миллионы ситуация кардинально меняется. Это не призыв к созданию огромных классов по 100 полей. Ни в коем случаем. Это может пригодится исключительно в случае, когда Вы вплотную подошли к верхней границе Вашей оперативной памяти и в памяти у Вас много однотипных объектов.
Денормализация модели
Итак, давайте рассмотрим следующий код:
class Cursor {
String icon;
Position pos;
Cursor(String icon, int x, int y) {
this.icon = icon;
this.pos = new Position(x, y);
}
}
class Position {
int x;
int y;
Position(int x, int y) {
this.x = x;
this.y = y;
}
}
А теперь проведем денормализацию:
class Cursor2 {
String icon;
int x;
int y;
Cursor2(String icon, int x, int y) {
this.icon = icon;
this.x = x;
this.y = y;
}
}
Казалось бы — избавились от композиции и все. Но нет. Объект класса Cursor2 потребляет приблизительно на 30% меньше памяти чем объект класса Cursor (по сути Cursor + Position). Такое вот не очевидное следствие декомпозиции. За счет ссылки и заголовка лишнего объекта. Возможно это кажется не важным и смешным, но только до тех пор, пока объектов у Вас мало, а когда счет идет на миллионы ситуация кардинально меняется. Это не призыв к созданию огромных классов по 100 полей. Ни в коем случаем. Это может пригодится исключительно в случае, когда Вы вплотную подошли к верхней границе Вашей оперативной памяти и в памяти у Вас много однотипных объектов.
Размеры массивов в Java
2 мин
Размеры объектов в Java уже обсуждались на Хабре, например, здесь или здесь. Мне бы хотелось подробнее остановиться на размерах многомерных массивов — простая вещь, которая для меня стала неожиданной.
Оптимизируя вычислительный алгоритм по памяти, я наткнулся на то, что при определённых (вполне разумных) входных параметрах создаётся массив float[500][14761][2]. Сколько он может занимать в памяти (на HotSpot 1.6.0_26 32bit, если кому интересно)? Я примерно прикинул, что500*14 761*2*sizeof(float) = 500*14 761*2*4 = 59 044 000 байт плюс какой-то оверхед. Решив проверить, как на самом деле, я воспользовался Eclipse Memory Analyzer (невероятно волшебная вещь, рекомендую!) и обнаружил, что «Retained Heap» для этого массива составляет 206 662 016 байт ! Неплохой оверхед — 350%. Посмотрим, почему так получилось.
Оптимизируя вычислительный алгоритм по памяти, я наткнулся на то, что при определённых (вполне разумных) входных параметрах создаётся массив float[500][14761][2]. Сколько он может занимать в памяти (на HotSpot 1.6.0_26 32bit, если кому интересно)? Я примерно прикинул, что
Основы JAX-RS
4 мин
Введение
Выросло данное API из JSR 311: JAX-RS: The Java API for RESTful Web Services и вошло в Java EE 6 (планировалось в Java EE 5). Как видно из названия, предназначено оно для разработки RESTful веб-сервисов.
Основная цель данной статьи — познакомить читателя с основами JAX-RS API. Изначально я планировал написать о некоторых проблемах работы форм при использование JAX-RS сервиса. Не обнаружив на Хабре почти ничего, касающегося данной технологии понял, что введением к статье отделаться не удастся.
Будут представлены основы JAX-RS API, реализация от JBoss и дано небольшое введение в клиентскую часть фреймворка Resteasy.
Аннотации в JAVA: обзор синтаксиса и создание собственных
4 мин
Статья ориентирована больше на новичков, или тех, кто еще не работал с данным механизмом в языке. Я постараюсь рассказать, что это такое, зачем они нужны, и как можно самому создавать удобные для себя аннотации.
Аннотации представляют из себя дескрипторы, включаемые в текст программы, и используются для хранения метаданных программного кода, необходимых на разных этапах жизненного цикла программы.
Информация, хранимая в аннотациях, может использоваться соответствующими обработчиками для создания необходимых вспомогательных файлов или для маркировки классов, полей и т.д.
Аннотации представляют из себя дескрипторы, включаемые в текст программы, и используются для хранения метаданных программного кода, необходимых на разных этапах жизненного цикла программы.
Информация, хранимая в аннотациях, может использоваться соответствующими обработчиками для создания необходимых вспомогательных файлов или для маркировки классов, полей и т.д.
5 вещей, которых вы не знали о многопоточности
10 мин
Перевод
Хоть от многопоточности и библиотек, которые её поддерживают, отказываются немногие Java-программисты, но тех, кто нашёл время изучить вопрос в глубину ещё меньше. Вместо этого мы узнаём о потоках только столько, сколько нам требуется для конкретной задачи, добавляя новые приёмы в свой инструментарий лишь тогда, когда это необходимо. Так можно создавать и запускать достойные приложения, но можно делать и лучше. Понимание особенностей компилятора и виртуальной машины Java поможет вам писать более эффективный, производительный код.
В этом выпуске серии «5 вещей …», я представлю некоторые из тонких аспектов многопоточного программирования, в том числе synchronized-методы, volatile переменные и атомарные классы. Речь пойдет в особенности о том, как некоторые из этих конструкций взаимодействуют с JVM и Java-компилятором, и как различные взаимодействия могут повлиять на производительность приложений.
В этом выпуске серии «5 вещей …», я представлю некоторые из тонких аспектов многопоточного программирования, в том числе synchronized-методы, volatile переменные и атомарные классы. Речь пойдет в особенности о том, как некоторые из этих конструкций взаимодействуют с JVM и Java-компилятором, и как различные взаимодействия могут повлиять на производительность приложений.
Multithreading in practice
9 мин
Нашел как-то на stack overflow вопрос (link).
Перевод
В общем идея в принципе была не сложная. Т.к. по условию нельзя использовать util.concurrent, то надо реализовать свой пул потоков, плюс написать какие-то таски, которые в этом пуле потоков будут крутиться.
Так же я не был уверен в том, что при многопоточном использовании IO будет увеличение производительности.
Need to create java CLI programm that searchs for specific files matched some pattern. Need to use multi-threading approach without using util.concurrent package and to provide good performance on parallel controllers. Перевод
Нужно написать консольную программу, которая ищет файлы по какому-то паттерну. Программа должна быть многопоточная, но нельзя использовать пакет util.concurrent. Требуется добиться максимальной производительности.
В общем идея в принципе была не сложная. Т.к. по условию нельзя использовать util.concurrent, то надо реализовать свой пул потоков, плюс написать какие-то таски, которые в этом пуле потоков будут крутиться.
Так же я не был уверен в том, что при многопоточном использовании IO будет увеличение производительности.
Hibernate cache
6 мин
Довольно часто в java приложениях с целью снижения нагрузки на БД используют кеш. Не много людей реально понимают как работает кеш под капотом, добавить просто аннотацию не всегда достаточно, нужно понимать как работает система. Поэтому этой статье я попытаюсь раскрыть тему про то, как работает кеш популярного ORM фреймворка. Итак, для начала немного теории.
Прежде всего Hibernate cache — это 3 уровня кеширования:
Кеш первого уровня всегда привязан к объекту сессии. Hibernate всегда по умолчанию использует этот кеш и его нельзя отключить. Давайте сразу рассмотрим следующий код:
Возможно, Вы ожидаете, что будет выполнено 2 запроса в БД? Это не так. В этом примере будет выполнен 1 запрос в базу, несмотря на то, что делается 2 вызова load(), так как эти вызовы происходят в контексте одной сессии. Во время второй попытки загрузить план с тем же идентификатором будет использован кеш сессии.
Один важный момент — при использовании метода load() Hibernate не выгружает из БД данные до тех пор пока они не потребуются. Иными словами — в момент, когда осуществляется первый вызов load, мы получаем прокси объект или сами данные в случае, если данные уже были в кеше сессии. Поэтому в коде присутствует getName() чтобы 100% вытянуть данные из БД. Тут также открывается прекрасная возможность для потенциальной оптимизации. В случае прокси объекта мы можем связать два объекта не делая запрос в базу, в отличии от метода get(). При использовании методов save(), update(), saveOrUpdate(), load(), get(), list(), iterate(), scroll() всегда будет задействован кеш первого уровня. Собственно, тут нечего больше добавить.
Прежде всего Hibernate cache — это 3 уровня кеширования:
- Кеш первого уровня (First-level cache);
- Кеш второго уровня (Second-level cache);
- Кеш запросов (Query cache);
Кеш первого уровня
Кеш первого уровня всегда привязан к объекту сессии. Hibernate всегда по умолчанию использует этот кеш и его нельзя отключить. Давайте сразу рассмотрим следующий код:
SharedDoc persistedDoc = (SharedDoc) session.load(SharedDoc.class, docId);
System.out.println(persistedDoc.getName());
user1.setDoc(persistedDoc);
persistedDoc = (SharedDoc) session.load(SharedDoc.class, docId);
System.out.println(persistedDoc.getName());
user2.setDoc(persistedDoc);
Возможно, Вы ожидаете, что будет выполнено 2 запроса в БД? Это не так. В этом примере будет выполнен 1 запрос в базу, несмотря на то, что делается 2 вызова load(), так как эти вызовы происходят в контексте одной сессии. Во время второй попытки загрузить план с тем же идентификатором будет использован кеш сессии.
Один важный момент — при использовании метода load() Hibernate не выгружает из БД данные до тех пор пока они не потребуются. Иными словами — в момент, когда осуществляется первый вызов load, мы получаем прокси объект или сами данные в случае, если данные уже были в кеше сессии. Поэтому в коде присутствует getName() чтобы 100% вытянуть данные из БД. Тут также открывается прекрасная возможность для потенциальной оптимизации. В случае прокси объекта мы можем связать два объекта не делая запрос в базу, в отличии от метода get(). При использовании методов save(), update(), saveOrUpdate(), load(), get(), list(), iterate(), scroll() всегда будет задействован кеш первого уровня. Собственно, тут нечего больше добавить.
Типичные случаи утечки памяти в Java
4 мин
Большинству разработчиков известно, что сборщик мусора в Java не является универсальным механизмом, позволяющим программисту полностью забыть о правилах использования памяти и о том, в каких случаях осуществляется его работа. Ниже описаны типичные случаи утечки памяти в java-приложениях, встречающиеся повсеместно.
Итак, о чём должен помнить каждый java-программист.
Итак, о чём должен помнить каждый java-программист.
Dependency injection в Java EE 6
9 мин
В рамках JSR-299 “Contexts and Dependency Injection for the Java EE platform” (ранее WebBeans) была разработана спецификация описывающая реализацию паттерна внедрения зависимости, включенная в состав Java EE 6. Эталонной реализацией является фреймворк Weld, о котором и пойдет речь в данной статье.
К сожалению в сети не так много русскоязычной информации о нем. Скорее всего это связано с тем, что Spring IOC является синонимом dependency injection в Java Enterprise приложениях. Есть конечно еще Google Guice, но он тоже не так популярен.
В статье хотелось бы рассказать об основных преимуществах и недостатках Weld.
К сожалению в сети не так много русскоязычной информации о нем. Скорее всего это связано с тем, что Spring IOC является синонимом dependency injection в Java Enterprise приложениях. Есть конечно еще Google Guice, но он тоже не так популярен.
В статье хотелось бы рассказать об основных преимуществах и недостатках Weld.
Размер Java объектов
5 мин
Знаете сколько в памяти занимает строка? Каких только я не слышал ответов на этот вопрос, начиная от «не знаю» до «2 байта * количество символов в строке». А сколько тогда занимает пустая строка? А знаете сколько занимает объект класса Integer? А сколько будет занимать Ваш собственный объект класса с тремя Integer полями? Забавно, но ни один мой знакомый Java программист не смог ответить на эти вопросы… Да, большинству из нас это вообще не нужно и никто в реальных java проектах не будет об этом думать. Но это, ведь, как не знать объем двигателя машины на которой Вы ездите. Вы можете быть прекрасным водителем и даже не подозревать о том, что значат цифры 2.4 или 1.6 на вашей машине. Но я уверен, что найдется мало людей, которые не знакомы со значением этих цифр. Так почему же java программисты так мало знают об этой части своего инструмента?
Все мы знаем, что в java — everything is an object. Кроме, пожалуй, примитивов и ссылок на сами объекты. Давайте рассмотрим две типичных ситуации:
В этих простых строках разница просто огромна, как для JVM так и для ООП. В первом случае, все что у нас есть — это 4-х байтная переменная, которая содержит значение из стека. Во втором случае у нас есть ссылочная переменная и сам объект, на который эта переменная ссылается. Следовательно, если в первом случае мы определено знаем, что занимаемый размер равен:
то во втором:
Забегая вперед скажу — во втором случае количество потребляемой памяти приблизительно в 5 раз больше и зависит от JVM. А теперь давайте разберемся, почему разница настолько огромна.
Прежде чем определять объем потребляемой памяти, следует разобраться, что же JVM хранит для каждого объекта:
Integer vs int
Все мы знаем, что в java — everything is an object. Кроме, пожалуй, примитивов и ссылок на сами объекты. Давайте рассмотрим две типичных ситуации:
//первый случай
int a = 300;
//второй случай
Integer b = 301;
В этих простых строках разница просто огромна, как для JVM так и для ООП. В первом случае, все что у нас есть — это 4-х байтная переменная, которая содержит значение из стека. Во втором случае у нас есть ссылочная переменная и сам объект, на который эта переменная ссылается. Следовательно, если в первом случае мы определено знаем, что занимаемый размер равен:
sizeOf(int)
то во втором:
sizeOf(reference) + sizeOf(Integer)
Забегая вперед скажу — во втором случае количество потребляемой памяти приблизительно в 5 раз больше и зависит от JVM. А теперь давайте разберемся, почему разница настолько огромна.
Из чего же состоит объект?
Прежде чем определять объем потребляемой памяти, следует разобраться, что же JVM хранит для каждого объекта:
- Заголовок объекта;
- Память для примитивных типов;
- Память для ссылочных типов;
- Смещение/выравнивание — по сути, это несколько неиспользуемых байт, что размещаются после данных самого объекта. Это сделано для того, чтобы адрес в памяти всегда был кратным машинному слову, для ускорения чтения из памяти + уменьшения количества бит для указателя на объект + предположительно для уменьшения фрагментации памяти. Стоит также отметить, что в java размер любого объекта кратен 8 байтам!
Миграция java-приложения на Fork/Join или о чём нужно помнить
3 мин
С выходом седьмой версии JDK нам, счастливым разработчикам на Java, стал доступен из коробки фреймворк Fork/Join, о котором уже писали на хабре тут. Фреймворк в плане API очень похож на уже привычный ExecutorServices, но даёт весьма ощутимый прирост производительности и действительную «легковесность» потоков.
Здесь, я бы хотел рассмотреть на что стоит обратить внимание при переходе на Fork/Join.
Здесь, я бы хотел рассмотреть на что стоит обратить внимание при переходе на Fork/Join.
Малоизвестные особенности Java
4 мин
Готовясь к собеседованию, я решил освежить память да и вообще поискать каверзные и малоизвестные нюансы языка Java. Выборку пяти наиболее интересных на мой взгляд моментов я вам и предлагаю.
Вот уже подоспела и вторая часть статьи.
1. Нестатические блоки инициализации.
Всем, я думаю, известно, что в Java существуют статические блоки инициализации (class initializers), код которых выполняется при первой загрузке класса.
Но существуют также и нестатические блоки инициализации (instance initializers). Они позволяют проводить инициализацию объектов вне зависимости от того, какой конструктор был вызван или, например, вести журналирование:
Такой метод инициализации весьма полезен для анонимных внутренних классов, которые конструкторов иметь не могут. Кроме того, вопреки ограничению синтаксиса Java, используя их, мы можем элегантно инициализировать коллекцию:
Очень даже мощное средство, не находите?
Остальные четыре пункта под катом.
Вот уже подоспела и вторая часть статьи.
1. Нестатические блоки инициализации.
Всем, я думаю, известно, что в Java существуют статические блоки инициализации (class initializers), код которых выполняется при первой загрузке класса.
class Foo {
static List<Character> abc;
static {
abc = new LinkedList<Character>();
for (char c = 'A'; c <= 'Z'; ++c) {
abc.add( c );
}
}
}Но существуют также и нестатические блоки инициализации (instance initializers). Они позволяют проводить инициализацию объектов вне зависимости от того, какой конструктор был вызван или, например, вести журналирование:
class Bar {
{
System.out.println("Bar: новый экземпляр");
}
}Такой метод инициализации весьма полезен для анонимных внутренних классов, которые конструкторов иметь не могут. Кроме того, вопреки ограничению синтаксиса Java, используя их, мы можем элегантно инициализировать коллекцию:
Map<String, String> map = new HashMap<String, String>() {{
put("паук", "арахнид");
put("птица", "архозавр");
put("кит", "зверь");
}};Очень даже мощное средство, не находите?
JFrame frame = new JFrame() {{
add(new JPanel() {{
add(new JLabel("Хабрахабр?") {{
setBackground(Color.BLACK);
setForeground(Color.WHITE);
}});
add(new JButton("Торт!") {{
addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent event) {
System.out.println("Хабрахабр - торт!");
}
});
}});
}});
}};Остальные четыре пункта под катом.
Плохая Java или как не надо делать
5 мин
Во время работы мне, как, наверное, и каждому из Вас, иногда приходится замечать мелкие недочеты Java. Маленькие и редкие, но присущие. К написанию этой статьи меня подвиг один из комментариев к моему первому посту. Тема показалась мне очень интересной и я решил припомнить все то, что мне не нравится в моем любимом языке программирования. Итак, начнем:
Не знаю почему было принято такое решение, но HashSet реализован на HashMap, да — сэкономили время на создание, но это же одна из основных коллекций, почему к ее созданию не подошли более ответственно — не понятно. Всё-таки, можно было создать HashSet более оптимально. HashMap несет излишнюю архитектуру в контексте задач HashSet. Например, внутри HashSet есть следующий код:
Это значит, что любое ваше значение внутри HashSet будет ассоциироваться со ссылкой на этот обьект. Это тоже самое, что:
Казалось бы, подумаешь — 8 байт, который будут использоваться всеми. Но не забывайте что при каждой вставке в HashSet, создается Map.Entry, в котором 4 ссылки (еще 16 лишних байт на каждый элемент). Расточительно, не находите? Почему так? Большая загадка… Спасибо хоть не унаследовались.
Кто в проекте не использует log4j? А можете сходу назвать библиотеки, которые тоже обходятся без него? Думаю это трудные вопросы. Понимаю, java не может подстраиваться под каждую конкретную задачу, но добавили же стандартный Logger, так почему за 10 лет существования log4j, java так и не взяла лучшее из него? Представьте на сколько бы уменьшились все приложения, особенно сложные, где в конечной сборке может оказаться несколько разных версий логера.
HashSet
Не знаю почему было принято такое решение, но HashSet реализован на HashMap, да — сэкономили время на создание, но это же одна из основных коллекций, почему к ее созданию не подошли более ответственно — не понятно. Всё-таки, можно было создать HashSet более оптимально. HashMap несет излишнюю архитектуру в контексте задач HashSet. Например, внутри HashSet есть следующий код:
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
Это значит, что любое ваше значение внутри HashSet будет ассоциироваться со ссылкой на этот обьект. Это тоже самое, что:
Map.put(key, PRESENT);
Казалось бы, подумаешь — 8 байт, который будут использоваться всеми. Но не забывайте что при каждой вставке в HashSet, создается Map.Entry, в котором 4 ссылки (еще 16 лишних байт на каждый элемент). Расточительно, не находите? Почему так? Большая загадка… Спасибо хоть не унаследовались.
Default logger
Кто в проекте не использует log4j? А можете сходу назвать библиотеки, которые тоже обходятся без него? Думаю это трудные вопросы. Понимаю, java не может подстраиваться под каждую конкретную задачу, но добавили же стандартный Logger, так почему за 10 лет существования log4j, java так и не взяла лучшее из него? Представьте на сколько бы уменьшились все приложения, особенно сложные, где в конечной сборке может оказаться несколько разных версий логера.
Как работает ConcurrentHashMap
5 мин
В октябре на хабре появилась замечательная статья про работу HashMap. Продолжая данную тему, я собираюсь рассказать о реализации java.util.concurrent.ConcurrentHashMap.
Итак, как же появился ConcurrentHashMap, какие у него есть преимущества и как он был реализован.
Итак, как же появился ConcurrentHashMap, какие у него есть преимущества и как он был реализован.
Секреты JDK
4 мин

Про Unsafe в Java не слышал только ленивый, однако это не единственный магический класс в Sun/Oracle JDK, стирающий границы Java платформы и открывающий тропинки, не нанесенные на карту публичного API. Я расскажу про некоторые из них, принесшие пользу в реальных проектах. Но помните: недокументированные возможности лишают ваше приложение переносимости на другие Java платформы и, кроме того, являются потенциальным источником нетривиальных ошибок. Я даже зря написал слово «приложение». Лучше сказать, что описанные ниже классы вовсе не годятся для приложений! Скорее, они представляют интерес лишь для системного ПО и для любознательных программистов, т.е. для вас :)
Маленькие хитрости Java. Часть 2
5 мин
В продолжение первой статьи я добавлю еще несколько штрихов о наиболее часто встречающихся ошибках и просто плохом коде, с которым часто приходится иметь дело при работе с уже написанными проектами. Я не выносил это в первую часть, так как эти ситуации встречаются гораздо реже, но поскольку первая часть вызвала много позитивных отзывов, решил продолжить. Спасибо всем комментаторам, отзывам и замечаниям. Я постараюсь избежать допущенных ошибок. Итак, продолжим:
Казалось бы — очевидная истина, неправда ли? Но как показал чужой код и опыт собеседования кандидатов, часть разработчиков определенно не понимает в чем преимущество буферизованных стримов. Кто до сих пор не разобрался — метод read() класса FileInputStream:
Согласитесь, каждый раз делать системный вызов, чтобы считать один байт несколько расточительно. Собственно для того, чтобы избежать этой проблемы и были созданы оболочки-буферы. Все что они делают — при первом вызове системного read() считывают несколько больше (в зависимости от указанного размера буфера, котрый по умолчанию равен 8 кб) и при следующем вызове read() считывают данные уже из буфера. Прирост производительности — на порядок. Системные вызовы, на самом деле, это не всегда плохо, например:
В случае копированния массива — системный метод будет гораздо быстрей реализованного на java. И еще — считывайте данные порциями, а не по байтам, это тоже позволит прилично сэкономить.
Buffered Streams
//медленно
InputStream is = new FileInputStream(file);
int val;
while ((val = is.read()) != -1) {
}
//быстро
InputStream is = new BufferedInputStream(new FileInputStream(file));
int val;
while ((val = is.read()) != -1) {
}
Казалось бы — очевидная истина, неправда ли? Но как показал чужой код и опыт собеседования кандидатов, часть разработчиков определенно не понимает в чем преимущество буферизованных стримов. Кто до сих пор не разобрался — метод read() класса FileInputStream:
public native int read() throws IOException;
Согласитесь, каждый раз делать системный вызов, чтобы считать один байт несколько расточительно. Собственно для того, чтобы избежать этой проблемы и были созданы оболочки-буферы. Все что они делают — при первом вызове системного read() считывают несколько больше (в зависимости от указанного размера буфера, котрый по умолчанию равен 8 кб) и при следующем вызове read() считывают данные уже из буфера. Прирост производительности — на порядок. Системные вызовы, на самом деле, это не всегда плохо, например:
System.arraycopy(src, srcPos, dest, destPos, length);В случае копированния массива — системный метод будет гораздо быстрей реализованного на java. И еще — считывайте данные порциями, а не по байтам, это тоже позволит прилично сэкономить.
Выполнение кода по расписанию в Spring Framework
2 мин
Тут приспичило мне периодически запускать некоторый код в небольшом проектике написанном на Spring Framework. Я уж было приготовился по старой памяти (еще со спринга 2.x) к долгому прикручиванию quartz-а и написании кучи конфигов на xml, как оказалось все значительно проще