
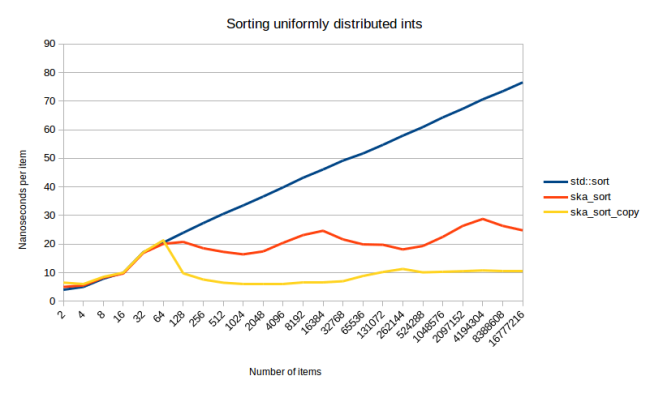
Может показаться откровенной наглостью в наши дни утверждать, что Вы изобрели алгоритм сортировки, который на 30% быстрее, чем лучший существующий. Увы, я должен сделать гораздо более наглое заявление: я написал алгоритм сортировки, который в два раза быстрее, чем std :: sort для многих входных данных. И за исключением случаев, когда я специально конструирую воспроизведение нахудших для него ситуаций, алгоритм никогда не бывает медленнее, чем std :: sort (и даже когда попадаются эти худшие случаи, они обнаруживаются и происходит автоматический возврат к std :: sort).
Почему это утверждение неудачное? Потому что мне, вероятно, будет сложно убедить вас в том, что я ускорил сортировку в два раза. Однако, чтобы всех убедить, всё это должно теперь оказаться описанным довольно длинным сообщением в блоге, а весь исходный код - открытым кодом, чтобы вы могли опробовать его на любых данных. Так что я либо могу убедить вас множеством аргументов и измерений, либо вы можете просто опробовать алгоритм сами.