Недавно системный аналитик технологического департамента компании ABBYY Егор Будников выступил в «Яндексе» на конференции «Data & Science: закон и делопроизводство». Он рассказал, как работает компьютерное зрение, происходит обработка текстов, на что важно обращать внимание при извлечении информации из юридических документов и о многом другом.
— У компании могут быть развитые методологии анализа данных и электронный документооборот, при этом от клиентов или от соседних отделов в компанию могут приходить документы, созданные в Word, при этом распечатанные, отксерокопированные, отсканированные и принесенные на флешке.
Что же делать с документооборотом, который есть сейчас, с «грязными» документами, с бумажным хранением, вплоть до того, что документы могут храниться до 70 лет, прежде чем они отсканированы и должны быть распознаны?

Компания ABBYY разрабатывает технологии искусственного интеллекта для задач бизнеса. Искусственный интеллект должен уметь примерно то же самое, что делает человек в повседневной или профессиональной деятельности, а именно: по картинке или потоку картинок считывать информацию о реальном мире. Это может быть не только компьютерное зрение, но и слух или распознавание данных с датчиков, например с датчиков задымления или температуры. Дальше данные с этих сенсоров поступают в систему и должны участвовать в принятии решения. Чтобы успешно реализовывать эту функцию, система должна не допускать глупых логических ошибок, как на картинке:

Тексты сложны для анализа: многообразие и развитие языка делают их красивыми и выразительными, однако это усложняет задачу их автоматической обработки. Обычно многозначность слов преодолевается тем, что по контексту мы можем определить, что значит то или иное слово, однако иногда контекст оставляет простор для интерпретаций. В фразе «Эти типы стали есть на складе» по контексту невозможно понять со стопроцентной точностью: то ли это люди в помещении обедают, то ли это какие-то типы стали, которые хранятся на складе. Для того, чтобы разрешить эту двузначность, необходим более широкий контекст.
 Нижняя часть коллажа — кадр из фильма «Операция «Ы» и другие приключения Шурика».
Нижняя часть коллажа — кадр из фильма «Операция «Ы» и другие приключения Шурика».
В общем случае искусственный интеллект или умный робот должен уметь передвигаться в пространстве и успешно взаимодействовать с объектами – например, раз за разом поднимать коробку, которую выбивает у него из рук инструктор.
Наконец, общий интеллект и представление знаний: знание отличается от информации в том числе и тем, что его части активно взаимодействуют друг с другом, порождая новое знание. Для того чтобы эффективно решать задачу смешивания коктейлей, можно пойти простым путем: перечислить ингредиенты и указать, в каком порядке их смешивать. В этом случае система не сможет отвечать на произвольные вопросы о предмете ее интереса. Например, что будет, если заменить томатный сок на ананас. Для того чтобы система глубже овладела материалом, должны быть добавлены базы данных, таксономии (деревья понятий, логически связанных друг с другом), процедура логического вывода. В этом случае мы действительно сможем говорить, что система понимает, чем она занимается, и она будет способна ответить на произвольный вопрос о процессе.
Искусственный интеллект, который развивает компания ABBYY, обрабатывает документы, то есть превращает бумажные, отсканированные и электронные носители в структурированную информацию, извлеченную из этих документов. Остановимся на двух компонентах, таких как компьютерное зрение и обработка текстов. Компьютерное зрение позволяет превращать PDF, отсканированные изображения, картинки в редактируемые текстовые форматы. Почему эта задача сложная? Во-первых, документы могут иметь произвольную структуру.
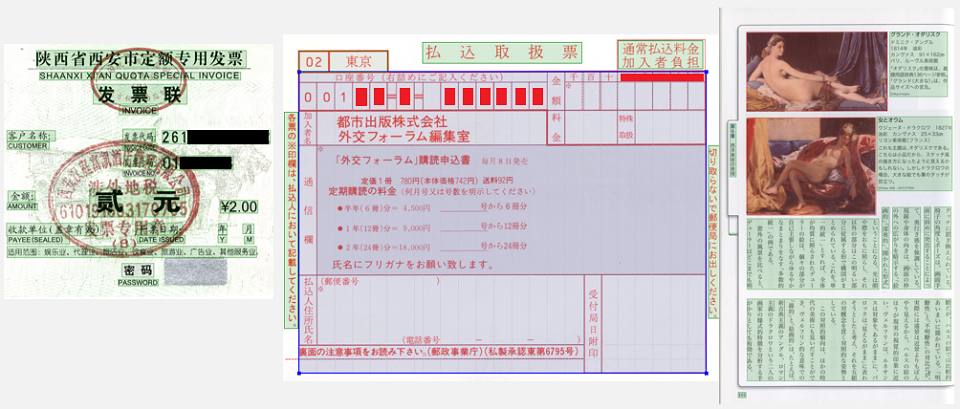
Это значит, что сначала нужно решить задачу структурного анализа документов: понять, где находятся текстовые блоки, картинки, таблицы, списки, а затем – определить, как они взаимодействуют друг с другом. Во-вторых, документы могут быть на разных языках. Это означает, что необходимо поддержать детектирование разных типов письменности и возможность распознавать слова и символы, которые могут сильно отличаться друг от друга. В-третьих, изображения приходят к нам из реального мира, а это означает, что с ними может случиться что угодно. Они могут быть искажены, сфотографированы с неправильной перспективой, на них могут быть пятна от кофе, полосы от принтера и затем от сканера. Со всем этим нужно каким-то образом справляться, чтобы впоследствии извлечь информацию.
Как устроено распознавание изображений у нас? На первом этапе мы получаем и обрабатываем изображения. Документ выравнивается, исправляются искажения. Затем производится анализ структуры страницы, на этом этапе находятся и определяются типы блоков. Когда блоки определены, строчки или столбцы выровнены, можно разделять эти строки на слова и символы – например, по вертикальным и горизонтальным гистограммам распределения черного цвета.
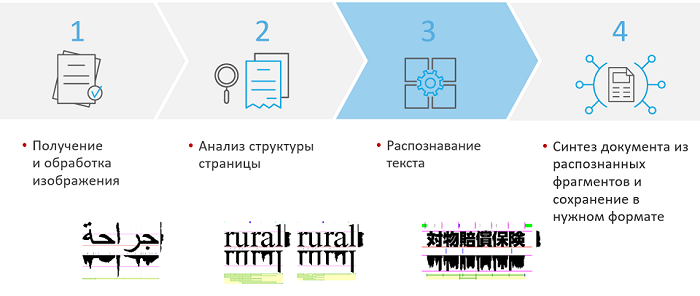
Таким образом, можно определять, где границы символов и слов, а затем распознавать, что это за символы и слова. Наконец, распознанные блоки синтезируются в единые текстовые документы и экспортируются.
На этот процесс можно смотреть с точки зрения сущностей разного уровня. Вначале у нас есть документ, который разбивается на страницы. Затем эти страницы нужно разбить на блоки, блоки на строки, строки на слова, слова на символы, а затем эти символы нужно распознать. После этого мы собираем распознанные символы в слова, слова в строки, строки в блоки, блоки в страницы, страницы – в документ. При этом на обратном пути первоначальное разбиение может меняться. Самый простой пример – если изначально разбитые блоки относились к одному нумерованному списку, значит, они в итоге должны относиться к одному блоку с типом «структурированный список». Иными словами, соседние этапы могут влиять друг на друга с целью улучшения качества распознавания.
Документ распознали, дальше из него нужно извлекать информацию. Документы можно разделить на более структурированные и менее структурированные. К более структурированным относятся визитки, чеки, инвойсы. К менее структурированным относятся доверенности, уставы, статьи в журналах. Если тип документа зафиксирован, он более-менее структурирован и документы внутри этого типа мало отличаются друг от друга структурой, можно применять методы, которые учатся напрямую извлекать необходимые атрибуты из текстового документа, используя текстовые и графические признаки. Например, с помощью рекуррентных нейронных сетей можно извлекать позиции товаров из инвойсов. Инвойсы – это такие документы, в которых представлены позиции товаров и описание способов оплаты этих товаров.
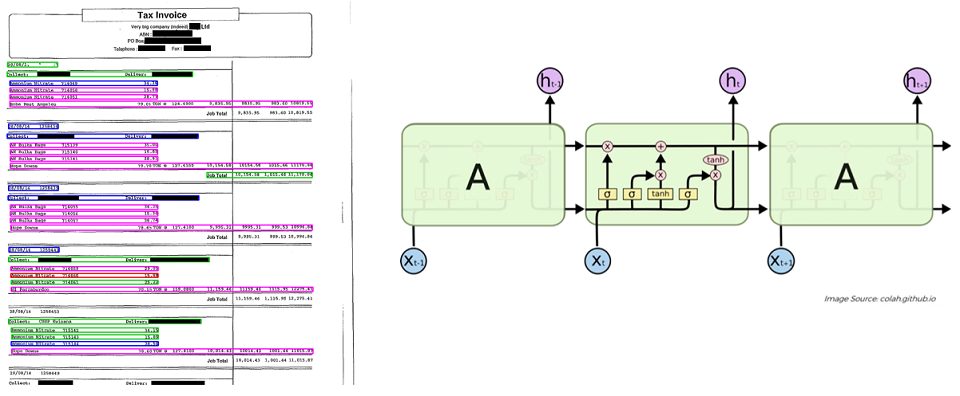
Другой пример – чеки. С помощью сверточных нейронных сетей можно извлекать одиночные атрибуты, такие как ИНН, номер чека, дата-время, итоговый счет. Если говорить откровенно, то и в чеках, и в инвойсах используются и те, и другие методы, но для разных целей. Сверточные нейронные сети хороши для одиночных атрибутов, которые имеют какую-то позицию, а рекуррентные сети – для повторяемых элементов.
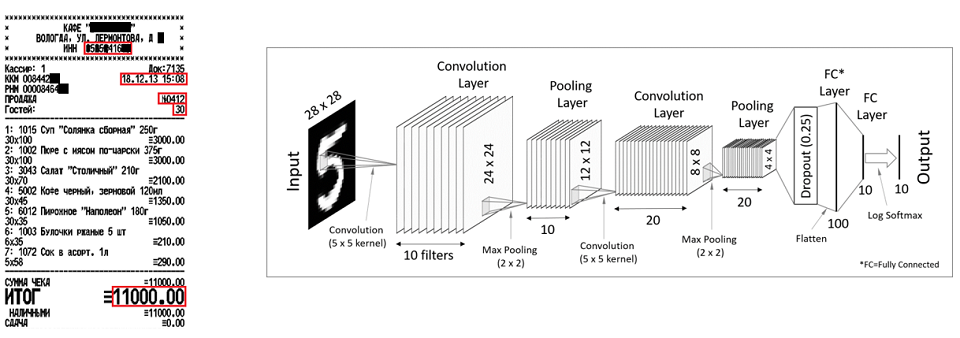
Если документы менее структурированы, в игру вступают методы обработки текстов на естественных языках, natural language processing, или NLP. Почему это сложно? Я уже говорил о многозначности слов. Слово address, к примеру, может означать адрес какой-нибудь компании, а может означать ее обязательства, решать какие-то проблемы заказчика.

Также в текстах часто пропускаются, но подразумеваются слова. Для того, чтобы извлекать информацию, нужно восстанавливать эти пропущенные слова. Этот эффект в лингвистике называется «эллипсис».
Язык многообразен, и способов выразить одну и ту же мысль, как правило, бесчисленное множество. Для того, чтобы автоматически обрабатывать тексты, необходимо каким-то образом снижать эту вариативность: применение синонимов и подобных конструкций, чтобы заменить одно слово или выражение; перестановка слов или изменение грамматического залога. Например, «компании заключили договор» и «договор был заключен между компаниями», для того чтобы сказать об одном и том же. В случае синонимов можно вводить так называемое семантическое пространство, векторное пространство, в котором слова представляются в виде точек. Близкие точки обозначают близкие понятия, далекие точки обозначают более далекие понятия. Чтобы снижать вариативность формулировок, можно вводить синтаксические и семантические деревья разбора. В этом случае тоже решается подобная проблема, и алгоритм извлечения информации способен извлекать информацию, даже если встречает конструкции или слова, которые ранее не встречались в обучающей выборке.
Каким образом происходит извлечение информации? На первом этапе производится лексический анализ документа. Текст разбивается на параграфы, параграфы на предложения, предложения на слова. Это может быть нетривиально: те из вас, кто знаком с NLP, могут знать, что даже такая, кажется, простая задача, как разбиение текста на предложения, может быть непростой: точки не всегда означают конец предложения. Это могут быть неизвестные сокращения, поэтому в лексическом анализе мы пытаемся перебирать все возможные варианты разбиения предложений на слова и оставлять самые вероятные. С этой проблемой, как правило, мы сталкиваемся в языках, в которых маленькое количество или полное отсутствие пробелов, такие как японский или китайский. Либо у которых богатое словообразование. Это, например, такой язык, как немецкий: в нем есть очень длинные слова, которые состоят из нескольких слов (такие слова называются композитами). Также для всех этих слов вычисляются все возможные интерпретации. Например, если в тексте встречается «г» с точкой, это может означать очень многое: город, год, грамм, господин и даже четвертый пункт (а, б, в, г).

Затем производится сегментация, то есть поиск интересующих нас секций. Он производится по разным причинам, например, чтобы ускорить обработку документа или найти информацию, которая нас интересует; чтобы найти какой-то кусок документа, в котором говорится об обязанностях стороны. Либо это ускорение обработки, например, у нас документ может состоять из нескольких десятков или даже сотен страниц в особо запущенных случаях, при этом интересная информация содержится только в нескольких страницах. Сегментация позволяет найти эти интересные кусочки и анализировать только их. Затем может производиться или не производиться семантический анализ документа, это зависит от задачи, а на этом этапе производится поиск наилучших интерпретаций предложений, всех предложений документа или только тех, которые мы нашли на предыдущем этапе. Также генерируются семантические признаки для классификатора на следующем этапе.
Наконец, этап непосредственного извлечения атрибутов. Здесь применяются машинно-обученные модели или пишутся несложные шаблоны. Так или иначе, они опираются на признаки, порожденные предыдущими этапами. Это и структурные признаки, и лексические, и семантические. В зависимости от сложности задачи, мы применяем много разных методов: и методы машинного обучения, и методы написания шаблонов. На этом этапе мы ищем интересующие нас атрибуты. Это могут быть названия сторон, обязательства, дата подписания и т.д.
Наконец, некоторые атрибуты могут требовать пост-процессинга. Приведение к нормальной форме или приведение к шаблону даты. Некоторые атрибуты могут быть в принципе вычисляемыми, они не извлекаются из договора, а вычисляются на основе тех атрибутов, которые извлекаются из договора. Например, длительность действия договора на основании начала действия и его окончания.
Рассмотрим это на одном из сценариев, он называется «Открытие счета юридическим лицом». В чем заключается задача? В банк приходит юридическое лицо, или, точнее, его представитель, и приносит здоровенную стопку документов. В хорошем случае он эти документы уже отсканировал, но непонятно, с каким качеством. Чтобы оптимизировать процесс, сократить количество ошибок на вводе этой информации в систему, ускорить этот процесс, а следовательно, ускорить принятие решения и повысить лояльность клиентов, была предложена следующая схема:
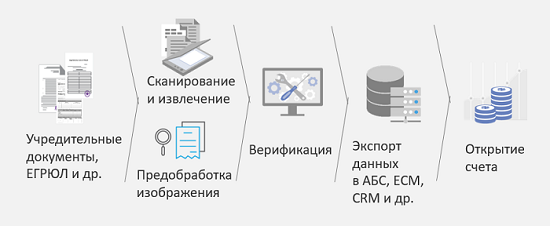
Учредительные документы, в которые входит очень много разных типов, сначала сканируются, затем они распознаются. При этом после распознавания они классифицируются по разным типам, и в зависимости от типа могут быть применены разные алгоритмы для распознавания и извлечения информации. Затем эта извлеченная информация в случае необходимости поступает на верификацию людям, и после этого уже можно принимать решение: открывать счет, или нужны какие-то другие дополнительные документы. Основной результат этого решения – это сокращение затрат в два раза на ввод данных при открытии счета. Результаты на основе замеров нашего клиента.
Какие атрибуты нужно извлекать? Очень много всего. Допустим, у нас на вход поступает какой-то устав. Сначала мы его распознаем. Как мы помним, это может быть достаточно проблематично, если это скан или фотография. Затем у нас определяется тип документа, а это важно, потому что необходимая нам информация может содержаться в какой-то специфической главе или подпункте, и поэтому алгоритму извлечения информации очень сильно помогает знание о том, когда эта глава или подпункт начинаются или заканчиваются.

Затем машина извлекает все базовые сущности, до которых может дотянуться:
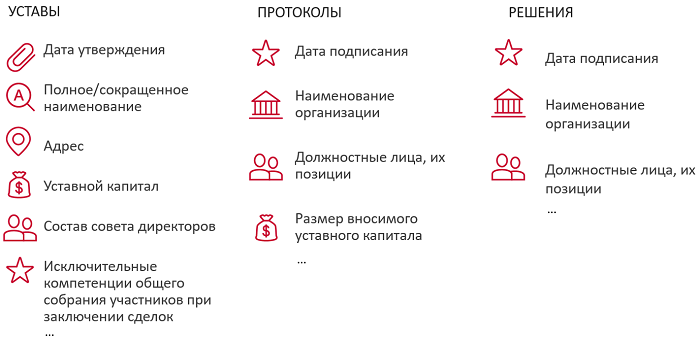
Это нужно для того, чтобы на следующем этапе извлечения атрибутов или определения ролей алгоритм мог пользоваться не только контекстом, но и признаками, которые были сгенерированы на предыдущих этапах. Например, может сильно упростить задачу определения, кто является директором юридического лица, информация о том, что это какая-то персона. Соответственно, среди набора персон, которые встречаются в документе, мы должны их расклассифицировать, директор это или не директор. Когда у нас ограниченное количество объектов, это сильно упрощает задачу.
За последние два года мы сталкивались еще с несколькими задачами клиентов и успешно их решали. Например, мониторинг СМИ для корпоративных рисков.
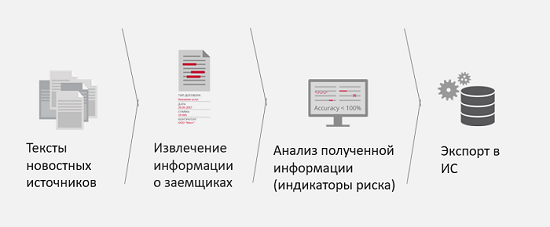
Какая здесь задача у бизнеса? Например, у вас есть потенциальный партнер или клиент, который хочет у вас взять кредит. Для того чтобы ускорить обработку данных этого клиента и снизить риски плохого партнерства, или будущего банкротства этого юридического лица, предлагается мониторить СМИ на предмет наличия там упоминаний этого физического или юридического лица и на предмет наличия в этих новостях так называемых индикаторов риска. То есть, если, например, в новостях постоянно всплывает, что юридическое лицо участвует в судебных разбирательствах или компанию разрывают конфликты акционеров, лучше узнать об этом пораньше, чтобы передать эту информацию аналитикам или аналитической системе и понять, насколько это плохо или хорошо для вашего бизнеса. Результатом решения этой задачи является получение более полной и точной информации о заемщике, а также уменьшается количество времени на получение этой информации.

Еще один пример применения, в котором необходимо снижать количество рутины и количество ошибок при вводе информации в систему, — это извлечение данных из договоров. Предлагается договоры распознавать, извлекать из них информацию и отправлять ее сразу в систему. После этого отдел кадров вас слезно благодарит и горячо приветствует при каждой встрече.

Не только отдел кадров страдает от большого количества рутинной работы с входящей документацией, также страдают и бухгалтерия, отделы продаж, отделы закупок. Сотрудникам приходится тратить очень много времени на ввод информации из счетов-фактур, приходящих актов и так далее.

На самом деле, все эти документы структурированные, и поэтому несложно их распознавать и извлекать из них информацию. Скорость ввода данных увеличивается до 5 раз, и при этом уменьшается количество ошибок, потому что исключается человеческий фактор. Условно, если сотрудник вернулся после обеда, он может начать вводить данные невнимательно. Наши собственные замеры и индустрия, которая так или иначе занимается ручным вводом информации в системы, говорит о том, что, если человек вводит данные из документа, причем делает это на постоянной основе и в потоке, у него редко получается качество больше 95%, а чаще и больше 90%. Поэтому за человеком нужно пересчитывать, перепроверять даже больше, чем за машиной.
При этом если машина выдает какую-то оценку уверенности в том, что она не извлекла – например, какой-то документ может быть грязным – и машина не уверена, что извлекла, но может просигнализировать верификатору о том, что не очень уверена в этом результате: «Пожалуйста, перепроверь». И человек перепроверяет отдельную информацию, чтобы она была высокого качества. Это не является столь рутинной операцией: он проверяет только действительно важные и сложные моменты, у него глаз не замыливается.
Если из документов можно извлекать информацию, эту информацию можно и сравнивать.
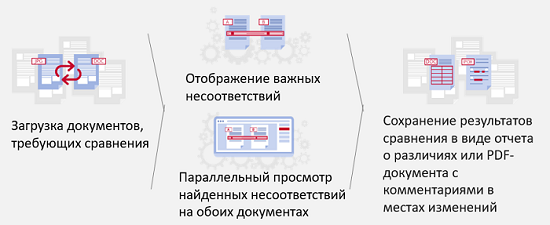
Это важно в двух случаях. Во-первых, для сравнения разных версий одного документа, например, договора, который долго согласуется, в него постоянно вносятся правки с обеих сторон. Во-вторых, это сопоставление документов разного типа, например, если есть договор, который указывает, что нам должно приходить от нашего партнера, с другой стороны, есть разные накладные и отчеты, сметы и т.д. Нам нужно соотносить их и понимать, что все в порядке, а если не в порядке, то каким-то образом сигнализировать об этом ответственным людям.
Текущее развитие технологий в компьютерном зрении, обработке структурированных и неструктурированных документов настолько высоко, что уже сейчас и в ближайшие годы будет ощущаться цифровая трансформация рутинных процессов в компаниях, потому что это дешевле, быстрее и зачастую качественнее.
При этом все эти методы ни в коем случае не призваны заменять людей. Скорее, мне нравится пример сравнения с инструментом Excel, в котором можно очень много делать и этот инструмент не призван заменить ни аналитиков, ни менеджеров, ни кого-либо еще. Он призван расширить возможности человека и упростить для него решение задач.

Таким образом, и решения, связанные с искусственным интеллектом, также призваны уменьшить количество повторяющихся рутинных операций, в которых человек зачастую допускает больше ошибок, чем машина, чтобы разгрузить ресурсы компании и направить их на решение более творческих и интеллектуальных задач. И кажется, мы туда движемся на всех парах. Спасибо.
— У компании могут быть развитые методологии анализа данных и электронный документооборот, при этом от клиентов или от соседних отделов в компанию могут приходить документы, созданные в Word, при этом распечатанные, отксерокопированные, отсканированные и принесенные на флешке.
Что же делать с документооборотом, который есть сейчас, с «грязными» документами, с бумажным хранением, вплоть до того, что документы могут храниться до 70 лет, прежде чем они отсканированы и должны быть распознаны?

Компания ABBYY разрабатывает технологии искусственного интеллекта для задач бизнеса. Искусственный интеллект должен уметь примерно то же самое, что делает человек в повседневной или профессиональной деятельности, а именно: по картинке или потоку картинок считывать информацию о реальном мире. Это может быть не только компьютерное зрение, но и слух или распознавание данных с датчиков, например с датчиков задымления или температуры. Дальше данные с этих сенсоров поступают в систему и должны участвовать в принятии решения. Чтобы успешно реализовывать эту функцию, система должна не допускать глупых логических ошибок, как на картинке:

Тексты сложны для анализа: многообразие и развитие языка делают их красивыми и выразительными, однако это усложняет задачу их автоматической обработки. Обычно многозначность слов преодолевается тем, что по контексту мы можем определить, что значит то или иное слово, однако иногда контекст оставляет простор для интерпретаций. В фразе «Эти типы стали есть на складе» по контексту невозможно понять со стопроцентной точностью: то ли это люди в помещении обедают, то ли это какие-то типы стали, которые хранятся на складе. Для того, чтобы разрешить эту двузначность, необходим более широкий контекст.

В общем случае искусственный интеллект или умный робот должен уметь передвигаться в пространстве и успешно взаимодействовать с объектами – например, раз за разом поднимать коробку, которую выбивает у него из рук инструктор.
Наконец, общий интеллект и представление знаний: знание отличается от информации в том числе и тем, что его части активно взаимодействуют друг с другом, порождая новое знание. Для того чтобы эффективно решать задачу смешивания коктейлей, можно пойти простым путем: перечислить ингредиенты и указать, в каком порядке их смешивать. В этом случае система не сможет отвечать на произвольные вопросы о предмете ее интереса. Например, что будет, если заменить томатный сок на ананас. Для того чтобы система глубже овладела материалом, должны быть добавлены базы данных, таксономии (деревья понятий, логически связанных друг с другом), процедура логического вывода. В этом случае мы действительно сможем говорить, что система понимает, чем она занимается, и она будет способна ответить на произвольный вопрос о процессе.
Искусственный интеллект, который развивает компания ABBYY, обрабатывает документы, то есть превращает бумажные, отсканированные и электронные носители в структурированную информацию, извлеченную из этих документов. Остановимся на двух компонентах, таких как компьютерное зрение и обработка текстов. Компьютерное зрение позволяет превращать PDF, отсканированные изображения, картинки в редактируемые текстовые форматы. Почему эта задача сложная? Во-первых, документы могут иметь произвольную структуру.
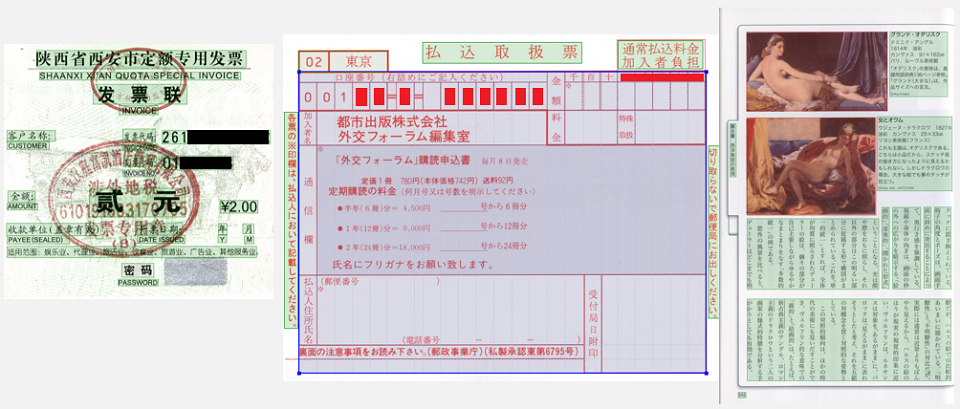
Это значит, что сначала нужно решить задачу структурного анализа документов: понять, где находятся текстовые блоки, картинки, таблицы, списки, а затем – определить, как они взаимодействуют друг с другом. Во-вторых, документы могут быть на разных языках. Это означает, что необходимо поддержать детектирование разных типов письменности и возможность распознавать слова и символы, которые могут сильно отличаться друг от друга. В-третьих, изображения приходят к нам из реального мира, а это означает, что с ними может случиться что угодно. Они могут быть искажены, сфотографированы с неправильной перспективой, на них могут быть пятна от кофе, полосы от принтера и затем от сканера. Со всем этим нужно каким-то образом справляться, чтобы впоследствии извлечь информацию.
Как устроено распознавание изображений у нас? На первом этапе мы получаем и обрабатываем изображения. Документ выравнивается, исправляются искажения. Затем производится анализ структуры страницы, на этом этапе находятся и определяются типы блоков. Когда блоки определены, строчки или столбцы выровнены, можно разделять эти строки на слова и символы – например, по вертикальным и горизонтальным гистограммам распределения черного цвета.
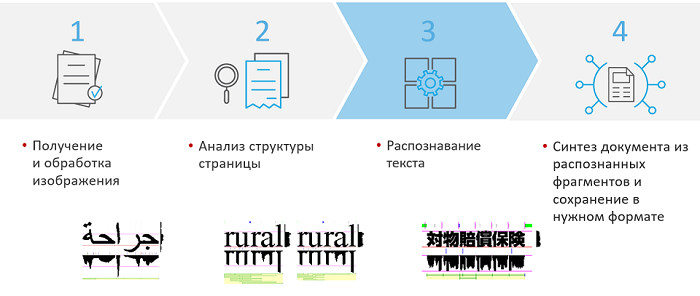
Таким образом, можно определять, где границы символов и слов, а затем распознавать, что это за символы и слова. Наконец, распознанные блоки синтезируются в единые текстовые документы и экспортируются.
На этот процесс можно смотреть с точки зрения сущностей разного уровня. Вначале у нас есть документ, который разбивается на страницы. Затем эти страницы нужно разбить на блоки, блоки на строки, строки на слова, слова на символы, а затем эти символы нужно распознать. После этого мы собираем распознанные символы в слова, слова в строки, строки в блоки, блоки в страницы, страницы – в документ. При этом на обратном пути первоначальное разбиение может меняться. Самый простой пример – если изначально разбитые блоки относились к одному нумерованному списку, значит, они в итоге должны относиться к одному блоку с типом «структурированный список». Иными словами, соседние этапы могут влиять друг на друга с целью улучшения качества распознавания.
Документ распознали, дальше из него нужно извлекать информацию. Документы можно разделить на более структурированные и менее структурированные. К более структурированным относятся визитки, чеки, инвойсы. К менее структурированным относятся доверенности, уставы, статьи в журналах. Если тип документа зафиксирован, он более-менее структурирован и документы внутри этого типа мало отличаются друг от друга структурой, можно применять методы, которые учатся напрямую извлекать необходимые атрибуты из текстового документа, используя текстовые и графические признаки. Например, с помощью рекуррентных нейронных сетей можно извлекать позиции товаров из инвойсов. Инвойсы – это такие документы, в которых представлены позиции товаров и описание способов оплаты этих товаров.

Другой пример – чеки. С помощью сверточных нейронных сетей можно извлекать одиночные атрибуты, такие как ИНН, номер чека, дата-время, итоговый счет. Если говорить откровенно, то и в чеках, и в инвойсах используются и те, и другие методы, но для разных целей. Сверточные нейронные сети хороши для одиночных атрибутов, которые имеют какую-то позицию, а рекуррентные сети – для повторяемых элементов.
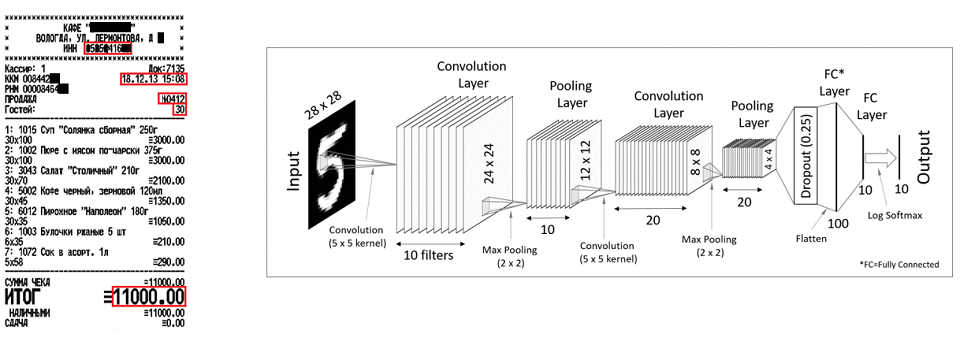
Если документы менее структурированы, в игру вступают методы обработки текстов на естественных языках, natural language processing, или NLP. Почему это сложно? Я уже говорил о многозначности слов. Слово address, к примеру, может означать адрес какой-нибудь компании, а может означать ее обязательства, решать какие-то проблемы заказчика.

Также в текстах часто пропускаются, но подразумеваются слова. Для того, чтобы извлекать информацию, нужно восстанавливать эти пропущенные слова. Этот эффект в лингвистике называется «эллипсис».
Язык многообразен, и способов выразить одну и ту же мысль, как правило, бесчисленное множество. Для того, чтобы автоматически обрабатывать тексты, необходимо каким-то образом снижать эту вариативность: применение синонимов и подобных конструкций, чтобы заменить одно слово или выражение; перестановка слов или изменение грамматического залога. Например, «компании заключили договор» и «договор был заключен между компаниями», для того чтобы сказать об одном и том же. В случае синонимов можно вводить так называемое семантическое пространство, векторное пространство, в котором слова представляются в виде точек. Близкие точки обозначают близкие понятия, далекие точки обозначают более далекие понятия. Чтобы снижать вариативность формулировок, можно вводить синтаксические и семантические деревья разбора. В этом случае тоже решается подобная проблема, и алгоритм извлечения информации способен извлекать информацию, даже если встречает конструкции или слова, которые ранее не встречались в обучающей выборке.
Каким образом происходит извлечение информации? На первом этапе производится лексический анализ документа. Текст разбивается на параграфы, параграфы на предложения, предложения на слова. Это может быть нетривиально: те из вас, кто знаком с NLP, могут знать, что даже такая, кажется, простая задача, как разбиение текста на предложения, может быть непростой: точки не всегда означают конец предложения. Это могут быть неизвестные сокращения, поэтому в лексическом анализе мы пытаемся перебирать все возможные варианты разбиения предложений на слова и оставлять самые вероятные. С этой проблемой, как правило, мы сталкиваемся в языках, в которых маленькое количество или полное отсутствие пробелов, такие как японский или китайский. Либо у которых богатое словообразование. Это, например, такой язык, как немецкий: в нем есть очень длинные слова, которые состоят из нескольких слов (такие слова называются композитами). Также для всех этих слов вычисляются все возможные интерпретации. Например, если в тексте встречается «г» с точкой, это может означать очень многое: город, год, грамм, господин и даже четвертый пункт (а, б, в, г).

Затем производится сегментация, то есть поиск интересующих нас секций. Он производится по разным причинам, например, чтобы ускорить обработку документа или найти информацию, которая нас интересует; чтобы найти какой-то кусок документа, в котором говорится об обязанностях стороны. Либо это ускорение обработки, например, у нас документ может состоять из нескольких десятков или даже сотен страниц в особо запущенных случаях, при этом интересная информация содержится только в нескольких страницах. Сегментация позволяет найти эти интересные кусочки и анализировать только их. Затем может производиться или не производиться семантический анализ документа, это зависит от задачи, а на этом этапе производится поиск наилучших интерпретаций предложений, всех предложений документа или только тех, которые мы нашли на предыдущем этапе. Также генерируются семантические признаки для классификатора на следующем этапе.
Наконец, этап непосредственного извлечения атрибутов. Здесь применяются машинно-обученные модели или пишутся несложные шаблоны. Так или иначе, они опираются на признаки, порожденные предыдущими этапами. Это и структурные признаки, и лексические, и семантические. В зависимости от сложности задачи, мы применяем много разных методов: и методы машинного обучения, и методы написания шаблонов. На этом этапе мы ищем интересующие нас атрибуты. Это могут быть названия сторон, обязательства, дата подписания и т.д.
Наконец, некоторые атрибуты могут требовать пост-процессинга. Приведение к нормальной форме или приведение к шаблону даты. Некоторые атрибуты могут быть в принципе вычисляемыми, они не извлекаются из договора, а вычисляются на основе тех атрибутов, которые извлекаются из договора. Например, длительность действия договора на основании начала действия и его окончания.
Рассмотрим это на одном из сценариев, он называется «Открытие счета юридическим лицом». В чем заключается задача? В банк приходит юридическое лицо, или, точнее, его представитель, и приносит здоровенную стопку документов. В хорошем случае он эти документы уже отсканировал, но непонятно, с каким качеством. Чтобы оптимизировать процесс, сократить количество ошибок на вводе этой информации в систему, ускорить этот процесс, а следовательно, ускорить принятие решения и повысить лояльность клиентов, была предложена следующая схема:
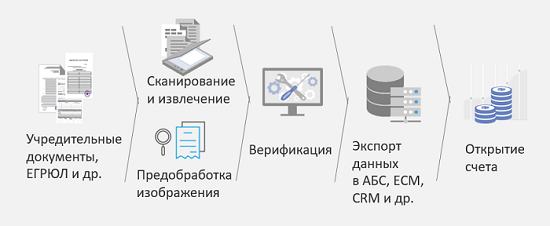
Учредительные документы, в которые входит очень много разных типов, сначала сканируются, затем они распознаются. При этом после распознавания они классифицируются по разным типам, и в зависимости от типа могут быть применены разные алгоритмы для распознавания и извлечения информации. Затем эта извлеченная информация в случае необходимости поступает на верификацию людям, и после этого уже можно принимать решение: открывать счет, или нужны какие-то другие дополнительные документы. Основной результат этого решения – это сокращение затрат в два раза на ввод данных при открытии счета. Результаты на основе замеров нашего клиента.
Какие атрибуты нужно извлекать? Очень много всего. Допустим, у нас на вход поступает какой-то устав. Сначала мы его распознаем. Как мы помним, это может быть достаточно проблематично, если это скан или фотография. Затем у нас определяется тип документа, а это важно, потому что необходимая нам информация может содержаться в какой-то специфической главе или подпункте, и поэтому алгоритму извлечения информации очень сильно помогает знание о том, когда эта глава или подпункт начинаются или заканчиваются.

Затем машина извлекает все базовые сущности, до которых может дотянуться:
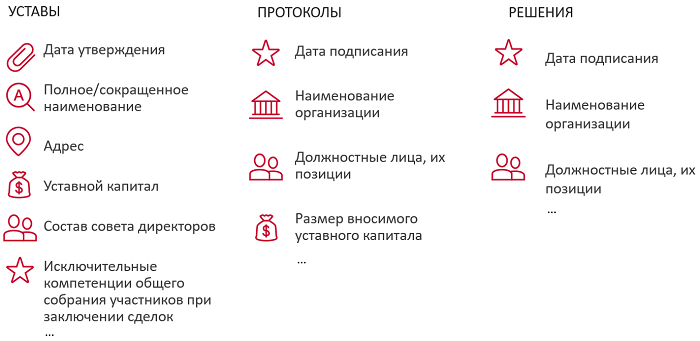
Это нужно для того, чтобы на следующем этапе извлечения атрибутов или определения ролей алгоритм мог пользоваться не только контекстом, но и признаками, которые были сгенерированы на предыдущих этапах. Например, может сильно упростить задачу определения, кто является директором юридического лица, информация о том, что это какая-то персона. Соответственно, среди набора персон, которые встречаются в документе, мы должны их расклассифицировать, директор это или не директор. Когда у нас ограниченное количество объектов, это сильно упрощает задачу.
За последние два года мы сталкивались еще с несколькими задачами клиентов и успешно их решали. Например, мониторинг СМИ для корпоративных рисков.
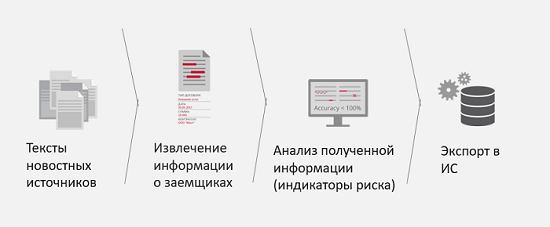
Какая здесь задача у бизнеса? Например, у вас есть потенциальный партнер или клиент, который хочет у вас взять кредит. Для того чтобы ускорить обработку данных этого клиента и снизить риски плохого партнерства, или будущего банкротства этого юридического лица, предлагается мониторить СМИ на предмет наличия там упоминаний этого физического или юридического лица и на предмет наличия в этих новостях так называемых индикаторов риска. То есть, если, например, в новостях постоянно всплывает, что юридическое лицо участвует в судебных разбирательствах или компанию разрывают конфликты акционеров, лучше узнать об этом пораньше, чтобы передать эту информацию аналитикам или аналитической системе и понять, насколько это плохо или хорошо для вашего бизнеса. Результатом решения этой задачи является получение более полной и точной информации о заемщике, а также уменьшается количество времени на получение этой информации.

Еще один пример применения, в котором необходимо снижать количество рутины и количество ошибок при вводе информации в систему, — это извлечение данных из договоров. Предлагается договоры распознавать, извлекать из них информацию и отправлять ее сразу в систему. После этого отдел кадров вас слезно благодарит и горячо приветствует при каждой встрече.

Не только отдел кадров страдает от большого количества рутинной работы с входящей документацией, также страдают и бухгалтерия, отделы продаж, отделы закупок. Сотрудникам приходится тратить очень много времени на ввод информации из счетов-фактур, приходящих актов и так далее.

На самом деле, все эти документы структурированные, и поэтому несложно их распознавать и извлекать из них информацию. Скорость ввода данных увеличивается до 5 раз, и при этом уменьшается количество ошибок, потому что исключается человеческий фактор. Условно, если сотрудник вернулся после обеда, он может начать вводить данные невнимательно. Наши собственные замеры и индустрия, которая так или иначе занимается ручным вводом информации в системы, говорит о том, что, если человек вводит данные из документа, причем делает это на постоянной основе и в потоке, у него редко получается качество больше 95%, а чаще и больше 90%. Поэтому за человеком нужно пересчитывать, перепроверять даже больше, чем за машиной.
При этом если машина выдает какую-то оценку уверенности в том, что она не извлекла – например, какой-то документ может быть грязным – и машина не уверена, что извлекла, но может просигнализировать верификатору о том, что не очень уверена в этом результате: «Пожалуйста, перепроверь». И человек перепроверяет отдельную информацию, чтобы она была высокого качества. Это не является столь рутинной операцией: он проверяет только действительно важные и сложные моменты, у него глаз не замыливается.
Если из документов можно извлекать информацию, эту информацию можно и сравнивать.
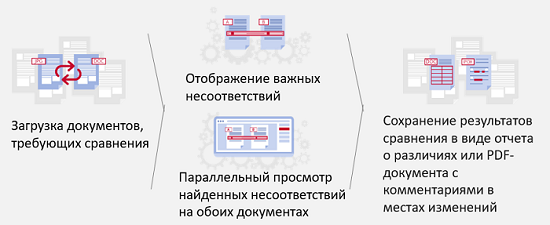
Это важно в двух случаях. Во-первых, для сравнения разных версий одного документа, например, договора, который долго согласуется, в него постоянно вносятся правки с обеих сторон. Во-вторых, это сопоставление документов разного типа, например, если есть договор, который указывает, что нам должно приходить от нашего партнера, с другой стороны, есть разные накладные и отчеты, сметы и т.д. Нам нужно соотносить их и понимать, что все в порядке, а если не в порядке, то каким-то образом сигнализировать об этом ответственным людям.
Текущее развитие технологий в компьютерном зрении, обработке структурированных и неструктурированных документов настолько высоко, что уже сейчас и в ближайшие годы будет ощущаться цифровая трансформация рутинных процессов в компаниях, потому что это дешевле, быстрее и зачастую качественнее.
При этом все эти методы ни в коем случае не призваны заменять людей. Скорее, мне нравится пример сравнения с инструментом Excel, в котором можно очень много делать и этот инструмент не призван заменить ни аналитиков, ни менеджеров, ни кого-либо еще. Он призван расширить возможности человека и упростить для него решение задач.

Таким образом, и решения, связанные с искусственным интеллектом, также призваны уменьшить количество повторяющихся рутинных операций, в которых человек зачастую допускает больше ошибок, чем машина, чтобы разгрузить ресурсы компании и направить их на решение более творческих и интеллектуальных задач. И кажется, мы туда движемся на всех парах. Спасибо.
