Пожалуй нет ни одной другой технологии сегодня, вокруг которой было бы столько мифов, лжи и некомпетентности. Врут журналисты, рассказывающие о технологии, врут политики которые говорят о успешном внедрении, врут большинство продавцов технологий. Каждый месяц я вижу последствия того как люди пробуют внедрить распознавание лиц в системы которые не смогут с ним работать.

Тема этой статьи давным-давно наболела, но было всё как-то лень её писать. Много текста, который я уже раз двадцать повторял разным людям. Но, прочитав очередную пачку треша всё же решил что пора. Буду давать ссылку на эту статью.
Итак. В статье я отвечу на несколько простых вопросов:
Большая часть ответов будет доказательной, с сылкой на исследования где показаны ключевые параметры алгоритмов + с математикой расчёта. Малая часть будет базироваться на опыте внедрения и эксплуатации различных биометрических систем.
Я не буду вдаваться в подробности того как сейчас реализовано распознавание лиц. На Хабре есть много хороших статей на эту тему: а, б, с (их сильно больше, конечно, это всплывающие в памяти). Но всё же некоторые моменты, которые влияют на разные решения — я буду описывать. Так что прочтение хотя бы одной из статей выше — упростит понимание этой статьи. Начнём!
Если что, статья 2018 года. Сейчас как минимум 2021. Не то, что что-то принципиально изменилось. Но, точности стали другими (советую смотреть актуальные оригиналы метрик которые я упоминаю в статье). Появилось много новых идей/подходов, которые расширяют области применения распознавания лиц.
А в целом, — советую читать мой канал (vk, telegram) про более новые методы/подходы. Статьи с Хабра свои я там тоже аноншу.
Биометрия — точная наука. Тут нет места фразам «работает всегда», и «идеальная». Все очень хорошо считается. А чтобы подсчитать нужно знать всего две величины:
Эти ошибки могут иметь ряд особенностей и критериев применения. О них мы поговорим ниже. А пока я расскажу где их достать.
Первый вариант. Давным-давно ошибки производители сами публиковали. Но тут такое дело: доверять производителю нельзя. В каких условиях и как он измерял эти ошибки — никто не знает. И измерял ли вообще, или отдел маркетинга нарисовал.
Второй вариант. Появились открытые базы. Производители стали указывать ошибки по базам. Алгоритм можно заточить под известные базы, чтобы они показывали офигенное качество по ним. Но в реальности такой алгоритм может и не работать.
Третий вариант — открытые конкурсы с закрытым решением. Организатор проверяет решение. По сути kaggle. Самый известный такой конкурс — MegaFace. Первые места в этом конкурсе когда-то давали большую популярность и известность. Например компании N-Tech и Vocord во многом сделали себе имя именно на MegaFace.
Всё бы хорошо, но скажу честно. Подгонять решение можно и тут. Это куда сложнее, дольше. Но можно вычислять людей, можно вручную размечать базу, и.т.д. И главное — это не будет иметь никакого отношения к тому как система будет работать на реальных данных. Можете посмотреть кто сейчас лидер на MegaFace, а потом поискать решения этих ребят в следующем пункте.
Четвёртый вариант. На сегодняшний день самый честный. Мне не известны способы там жульничать. Хотя я их не исключаю.
Крупный и всемирно известный институт соглашается развернуть у себя независимую систему тестирования решений. От производителей поступает SDK которое подвергается закрытому тестированию, в котором производитель не принимает участия. Тестирование имеет множество параметров, которые потом официально публикуются.
Сейчас такое тестирование производит NIST — американский национальный институт стандартов и технологий. Такое тестирование самое честное и интересное.
Нужно сказать, что NIST производит огромную работу. Они выработали пяток кейсов, выпускают новые апдейты раз в пару месяцев, постоянно совершенствуются и включают новых производителей. Вот тут можно ознакомиться с последним выпуском исследования.
Казалось бы, этот вариант идеален для анализа. Но нет! Основной минус такого подхода — мы не знаем, что в базе. Посмотрите вот на этот график:
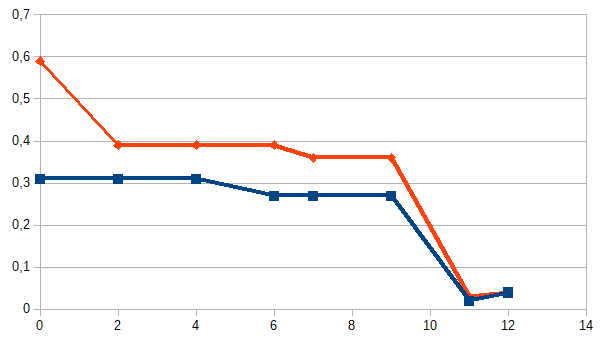
Это данные двух компаний по которым проводилось тестирование. По оси x — месяца, y — процент ошибок. Тест я взял «Wild faces» (чуть ниже описание).
Внезапное повышение точности в 10 раз у двух независимых компаний (вообще там у всех взлетело). Откуда?
В логе NIST стоит пометка «база была слишком сложной, мы её упростили». И нет примеров ни старой базы, ни новой. На мой взгляд это серьёзная ошибка. Именно на старой базу была видна разница алгоритмов вендоров. На новой у всех 4-8% пропусков. А на старой было 29-90%. Моё общение с распознаванием лиц на системах видеонаблюдения говорит, что 30% раньше — это и был реальный результат у гроссмейстерских алгоритмов. Сложно распознать по таким фото:

И конечно, по ним не светит точность 4%. Но не видя базу NIST делать таких утверждений на 100% нельзя. Но именно NIST — это главный независимый источник данных.
В статье я описываю ситуацию актуальную на июль 2018 года. При этом опираюсь на точности, по старой базе лиц для тестов связанных с задачей «Faces in the wild».
Вполне возможно что через пол года всё измениться полностью. А может будет стабильным следующие десять лет.
Итак, нам нужна вот эта таблица:
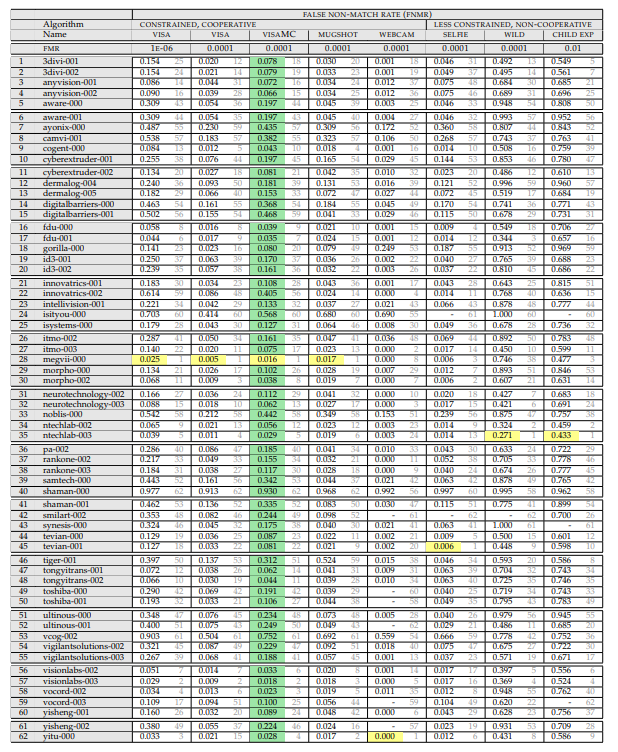
(апрель 2018, т.к. wild тут более адекватный)
Давайте разберём что в ней написано, и как оно измеряется.
Сверху идёт перечисление экспериментов. Эксперимент состоит из:
Того, на каком сете идёт замер. Сеты есть:
Того при каком уровне ошибок первого рода идёт замер (этот параметр рассматривается только для фотогафий на паспорт):
Результат эксперимента — величина FRR. Вероятность того что мы пропустили человека который есть в базе.
И уже тут внимательный читатель мог заметить первый интересный момент. «Что значит FAR 10^-4?». И это самый интересный момент!
Что вообще такая ошибка значит на практике? Это значит, что на базу в 10 000 человек будет одно ошибочное совпадение при проверке по ней любого среднестатистического человека. То есть, если у нас есть база из 1000 преступников, а мы сравниваем с ней 10000 человек в день, то у нас будет в среднем 1000 ложных срабатываний. Разве это кому то нужно?
В реальности всё не так плохо.
Если посмотреть построить график зависимости ошибки первого рода от ошибки второго рода, то получится такая классная картинка (тут сразу для десятка разных фирм, для варианта Wild, это то что будет на станции метро, если камеру поставить где-то чтобы её не видели люди):
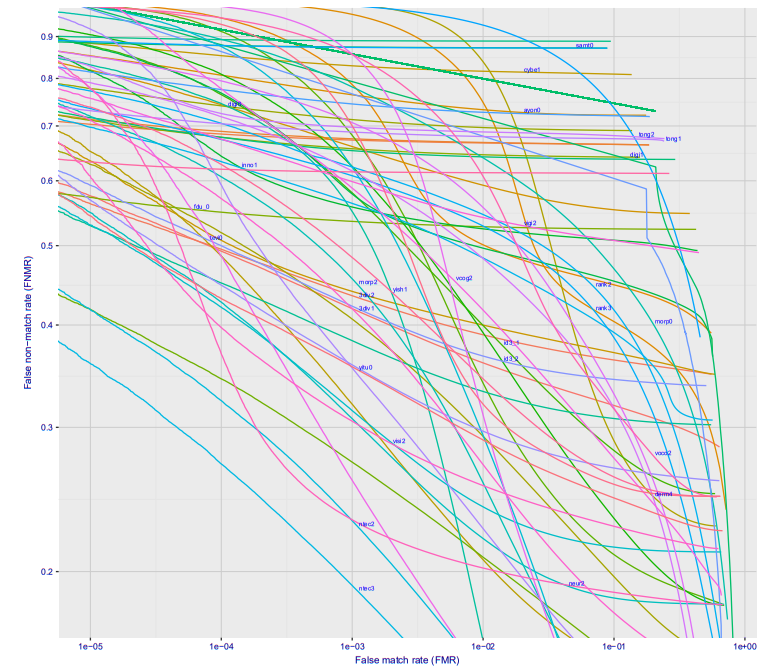
При ошибке 10^-4 27% процентов не распознанных людей. На 10^-5 примерно 40%. Скорее всего на 10^-6 потери составят примерно 50%
Итак, что это значит в реальных цифрах?
Лучше всего идти от парадигмы «сколько ошибок в день можно допустить». У нас на станции идёт поток людей, если каждые 20-30 минут система будет давать ложное срабатывание, то никто не будет её воспринимать всерьёз. Зафиксируем допустимое число ложных срабатываний на станции метро 10 человек в день (по хорошему, чтобы система не была выключена как надоедливая — нужно ещё меньше). Поток одной станции Московского метрополитена 20-120 тысяч пассажиров в сутки. Среднее — 60 тысяч.
Пусть зафиксированное значение FAR — 10^-6 (ниже ставить нельзя, мы и так при оптимистической оценке потеряем 50% преступников). Это значит что допустить 10 ложных тревог мы можем при размере базы в 160 человек.
Много это или мало? Размер базы в федеральном розыске ~ 300 000 человек. Интерпола 35 тысяч. Логично предположить, что где-то 30 тысяч москвичей находятся в розыске.
Это даст уже нереальное число ложных тревог.
Тут стоит отметить, что 160 человек может быть и достаточной базой, если система работает on-line. Если искать тех кто совершил преступление в последние сутки — это уже вполне рабочий объём. При этом, нося чёрные очки/кепки, и.т.д., замаскироваться можно. Но много ли их носит в метро?
Второй важный момент. Несложно сделать в метро систему дающее фото более высокого качества. Например поставить на рамки турникетов камеры. Тут уже будет не 50% потерь на 10^-6, а всего 2-3%. А на 10^-7 5-10%. Тут точности из графика на Visa, всё будет конечно сильно хуже на реальных камерах, но думаю на 10^-6 можно оставить сего 10% потерь:
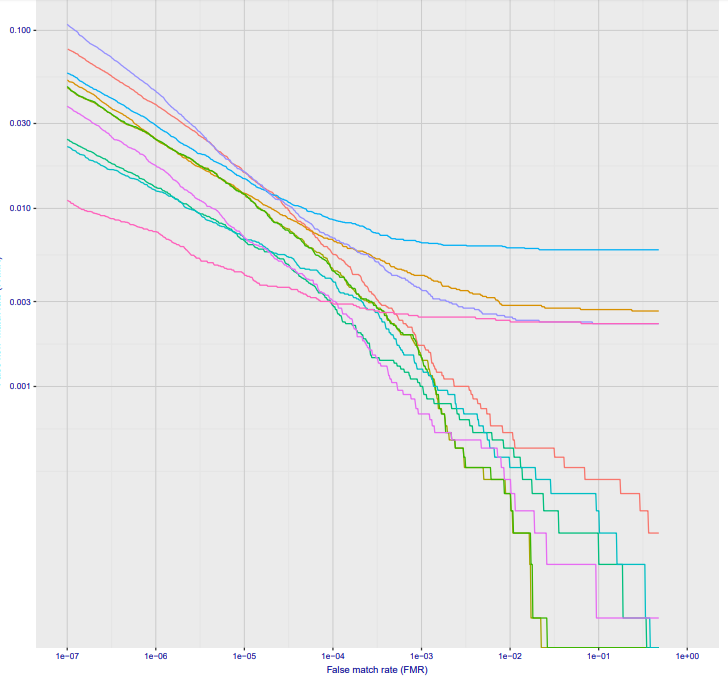
Опять же, базу в 30 тысяч система не потянет, но всё что происходит в реальном времени детектировать позволит.
Похоже время ответить на первую часть вопросов:
Ликсутов заявил что выявили 22 находящихся в розыске человека. Правда ли это?
Тут основной вопрос — что эти люди совершили, сколько было проверено не находящихся в розыске, насколько в задержании этих 22 людей помогло распознавание лиц.
Скорее всего, если это люди которых искали планом «перехват» — это действительно задержанные. И это неплохой результат. Но мои скромные предположения позволяют сказать, что для достижения этого результата было проверено минимум 2-3 тысячи людей, а скорее около десятка тысяч.
Это очень хорошо бьётся с цифрами которые называли в Лондоне. Только там эти числа честно публикуют, так как люди протестуют. А у нас замалчивают…
Вчера на Хабре была статья на счёт ложняков по распознаванию лиц. Но это пример манипуляций в обратную сторону. У Амазона никогда не было хорошей системы распознавания лиц. Плюс вопрос того как настроить пороги. Я могу хоть 100% ложняков сделать, подкрутив настройки;)
Про Китайцев, которые распознают всех на улице — очевидный фэйк. Хотя, если они сделали грамотный трекинг, то там можно сделать какой-то более адекватный анализ. Но, если честно, я не верю что пока это достижимо. Скорее набор затычек.
Поехали дальше. Давайте оценим другой момент. Поиск человека с хорошо известной биографией и хорошим профилем в соцсетях.
NIST проверяет распознавание лица к лицу. Берётся два лица одного/разных людей и сравнивается насколько они близки друг к другу. Если близость больше порога, тогда это один человек. Если дальше — разные. Но есть другой подход.
Если вы почитали статьи, которые я советовал в начале — то знаете, что при распознавании лица формируется хэш-код лица, отображающий его положение в N-мерном пространстве. Обычно это 256/512 мерное пространство, хотя у всех систем по разному.
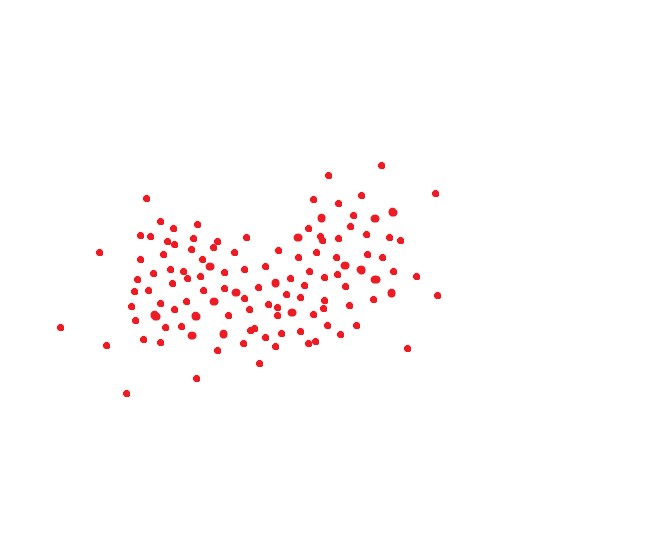
Идеальная система распознавания лиц переводит одно и то же лицо в один и тот же код. Но идеальных систем нет. Одно и то же лицо обычно занимает какую-то область пространства. Ну, например, если бы код был двумерным, то это могло бы быть как-то так:
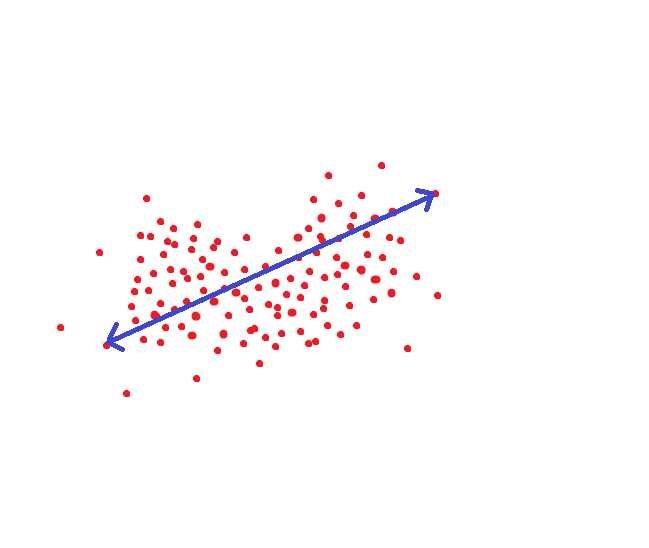
Если мы руководствуемся методом который принимается в NIST, то вот это расстояние было бы целевым порогом, чтобы мы могли распознать человека как одного и того же индивида с вероятностью под 95%:
Но ведь можно поступить по другому. Для каждого человека настроить область гиперпространства где хранятся достоверные для него величины:
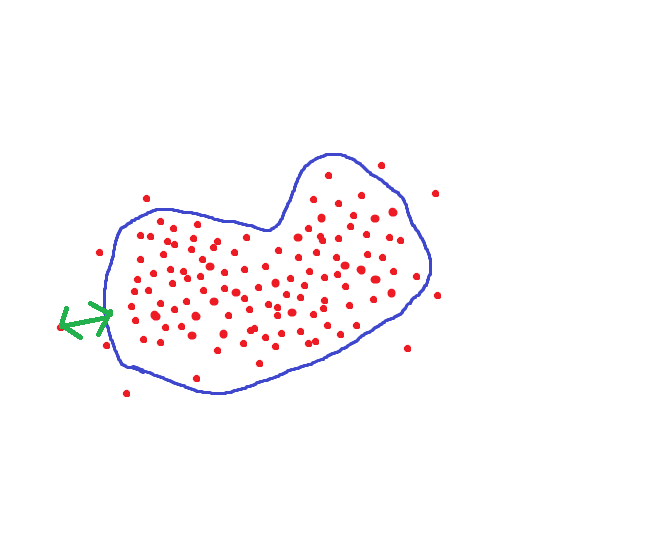
Тогда пороговое расстояние при сохранении точности уменьшится в несколько раз.
Только нам нужно очень много фотографий на каждого человека.
Если у человека есть профиль в социальных сетях / база его снимков разного возраста, то точность распознавания можно повысить очень сильно. Точной оценки того как вырастает FAR|FRR я не знаю. Да и оценивать уже некорректно такие величины. У кого-то в такой базе 2 фото, у кого-то 100. Очень много обёрточной логики. Мне кажется, что максимальная оценка — один/полтора порядка. Что позволяет дострелить до ошибок 10^-7 при вероятности не распознавания 20-30%. Но это умозрительно и оптимистично.
Вообще, конечно, с менеджментом данного пространства проблем не мало (возрастные фишки, фишки редакторов изображений, фишки шумов, фишки резкости), но как я понимаю большая часть уже успешно решена у крупных фирм кому было нужно решение.
К чему это я. К тому, что использование профилей позволяет в несколько раз поднять точность алгоритмов распознавания. Но она далека от абсолютной. С профилями требуется много ручной работы. Похожих людей много. Но если начинать задавать ограничения по возрасту, местонахождению, и.т.д., то этот метод позволяет получить хорошее решение. На пример того как нашли человека по принципу «найти профиль по фото»->«использовать профиль для поиска человека» я давал ссылку в начале.
Но, на мой взгляд, это сложно масштабируемый процесс. И, опять же, людей с большим числом фоток в профиле дай бог 40-50% в нашей стране. Да и многие из них дети, по которым всё плохо работает.
Но, опять же — это оценка.
Так вот. Про вашу безопасность. Чем меньше у вас фото в профиле — тем лучше. Чем более многочисленный митинг куда вы идёте — тем лучше. Никто не будет разбирать 20 тысяч фотографий в ручную. Тем кто заботиться о своей безопасности и приватности — я бы советовал не делать профилей со своими картинками.
На митинге в городе с 100 тысячным населением вас легко найдут, просмотря 1-2 совпадения. В Москве — задолбаются. Где-то пол года назад Vasyutka, с которым мы работаем вместе, давал рассказывал на эту тему:
Тут я позволю себе сделать небольшой экскурс в сторону. Качество обучения алгоритма распознавания лиц зависит от трёх факторов:
По п.2 вроде как сейчас достигнут предел. В принципе, математика развивается по таким вещам очень быстро. Да и после triplet loss остальные функции потерь не давали драматического прироста, лишь плавное улучшение и понижение размера базы.
Выделение лица — это сложно, если надо найти лица под всеми углами, потеряв доли процента. Но создание такого алгоритма — это достаточно предсказуемый и хорошо управляемый процесс. Чем более всё синее, тем лучше, большие углы корректно обрабатываются:

А полгода назад было так:

Видно, что потихоньку всё больше и больше компаний проходят этот путь, алгоритмы начинают распознавать всё более и более повёрнутые лица.
А вот с размером базы — всё интереснее. Открытые базы — маленькие. Хорошие базы максимум на пару десятков тысяч человек. Те что большие — странно структурированы / плохие (megaface, MS-Celeb-1M).
Как вы думаете, откуда создатели алгоритмов взяли эти базы?
Маленькая подсказка. Первый продукт NTech, который они сейчас сворачивают — Find Face, поиск людей по вконтакту. Думаю пояснения не нужны. Конечно, вконтакт борется с ботами, которые выкачивают все открытые профили. Но, насколько я слышал, народ до сих пор качает. И одноклассников. И инстаграмм.
Вроде как с Facebook — там всё сложнее. Но почти уверен, что что-то тоже придумали.
Так что да, если ваш профиль открыт — то можете гордиться, он использовался для обучения алгоритмов;)
Тут можно гордиться. Из 5 компаний-лидеров в мире сейчас два — Российские. Это N-Tech и VisionLabs. Пол года назад лидерами был NTech и Vocord, первые сильно лучше работали по повёрнутым лицам, вторые по фронтальным.
Сейчас остальные лидеры — 1-2 китайских компании и 1 американская, Vocord что-то сдал в рейтингах.
Еще российские в рейтинге itmo, 3divi, intellivision. Synesis — белорусская компания, хотя часть когда-то была в Москве, года 3 назад у них был блог на Хабре. Ещё про несколько решений знаю, что они принадлежат зарубежным компаниям, но офисы разработки тоже в России. Ещё есть несколько российских компаний которых нет в конкурсе, но у которых вроде неплохие решения. Например есть у ЦРТ. Очевидно, что у Одноклассников и Вконтакте тоже есть свои хорошие, но они для внутреннего пользования.
Короче да, на лицах сдвинуты в основном мы и китайцы.
NTech вообще первым в миру показал хорошие параметры нового уровня. Где-то в конце 2015 года. VisionLabs догнал NTech только только. В 2015 году они были лидерами рынка. Но их решение было прошлого поколения, а пробовать догнать NTech они стали лишь в конце 2016 года.
Если честно, то мне не нравятся обе этих компании. Очень агрессивный маркетинг. Я видел людей которым было впарено явно неподходящее решение, которое не решало их проблем.
С этой стороны Vocord мне нравился сильно больше. Консультировал как-то ребят кому Вокорд очень честно сказал «у вас проект не получится с такими камерами и точками установки». NTech и VisionLabs радостно попробовали продать. Но что-то Вокорд в последнее время пропал.
В выводах хочется сказать следующее. Распознавание лиц это очень хороший и сильный инструмент. Он реально позволяет находить преступников сегодня. Но его внедрение требует очень точного анализа всех параметров. Есть применения где достаточно OpenSource решения. Есть применения (распознавание на стадионах в толпе), где надо ставить только VisionLabs|Ntech, а ещё держать команду обслуживания, анализа и принятия решения. И OpenSource вам тут не поможет.
На сегодняшний день нельзя верить всем сказкам о том, что можно ловить всех преступников, или наблюдать всех в городе. Но важно помнить, что такие вещи могут помогать ловить преступников. Например чтобы в метро останавливать не всех подряд, а только тех кого система считает похожими. Ставить камеры так, чтобы лица лучше распознавались и создавать под это соответствующую инфраструктуру. Хотя, например я — против такого. Ибо цена ошибки если вас распознает как кого-то другого может быть слишком велика.
В последнее время делаю много мелких статей/видеороликов. Но так как это не формат Хабра — то публикую их в блоге или на ютубе. Трансляция всего есть в телеге и вк.
На Хабре обычно публикую, когда рассказ становится уже более самозамкнутым, иногда собрав 2-3 разных мини-рассказа на соседние темы.

Тема этой статьи давным-давно наболела, но было всё как-то лень её писать. Много текста, который я уже раз двадцать повторял разным людям. Но, прочитав очередную пачку треша всё же решил что пора. Буду давать ссылку на эту статью.
Итак. В статье я отвечу на несколько простых вопросов:
- Можно ли распознать вас на улице? И насколько автоматически/достоверно?
- Позавчера писали, что в Московском метро задерживают преступников, а вчера писали что в Лондоне не могут. А ещё в Китае распознают всех-всех на улице. А тут говорят, что 28 конгрессменов США преступники. Или вот, поймали вора.
- Кто сейчас выпускает решения распознавания по лицам в чём разница решений, особенности технологий?
Большая часть ответов будет доказательной, с сылкой на исследования где показаны ключевые параметры алгоритмов + с математикой расчёта. Малая часть будет базироваться на опыте внедрения и эксплуатации различных биометрических систем.
Я не буду вдаваться в подробности того как сейчас реализовано распознавание лиц. На Хабре есть много хороших статей на эту тему: а, б, с (их сильно больше, конечно, это всплывающие в памяти). Но всё же некоторые моменты, которые влияют на разные решения — я буду описывать. Так что прочтение хотя бы одной из статей выше — упростит понимание этой статьи. Начнём!
NB!
Если что, статья 2018 года. Сейчас как минимум 2021. Не то, что что-то принципиально изменилось. Но, точности стали другими (советую смотреть актуальные оригиналы метрик которые я упоминаю в статье). Появилось много новых идей/подходов, которые расширяют области применения распознавания лиц.
А в целом, — советую читать мой канал (vk, telegram) про более новые методы/подходы. Статьи с Хабра свои я там тоже аноншу.
Введение, базис
Биометрия — точная наука. Тут нет места фразам «работает всегда», и «идеальная». Все очень хорошо считается. А чтобы подсчитать нужно знать всего две величины:
- Ошибки первого рода — ситуация когда человека нет в нашей базе, но мы опознаём его как человека присутствующего в базе (в биометрии FAR (false access rate))
- Ошибки второго рода — ситуации когда человек есть в базе, но мы его пропустили. (В биометрии FRR (false reject rate))
Эти ошибки могут иметь ряд особенностей и критериев применения. О них мы поговорим ниже. А пока я расскажу где их достать.
Характеристики
Первый вариант. Давным-давно ошибки производители сами публиковали. Но тут такое дело: доверять производителю нельзя. В каких условиях и как он измерял эти ошибки — никто не знает. И измерял ли вообще, или отдел маркетинга нарисовал.
Второй вариант. Появились открытые базы. Производители стали указывать ошибки по базам. Алгоритм можно заточить под известные базы, чтобы они показывали офигенное качество по ним. Но в реальности такой алгоритм может и не работать.
Третий вариант — открытые конкурсы с закрытым решением. Организатор проверяет решение. По сути kaggle. Самый известный такой конкурс — MegaFace. Первые места в этом конкурсе когда-то давали большую популярность и известность. Например компании N-Tech и Vocord во многом сделали себе имя именно на MegaFace.
Всё бы хорошо, но скажу честно. Подгонять решение можно и тут. Это куда сложнее, дольше. Но можно вычислять людей, можно вручную размечать базу, и.т.д. И главное — это не будет иметь никакого отношения к тому как система будет работать на реальных данных. Можете посмотреть кто сейчас лидер на MegaFace, а потом поискать решения этих ребят в следующем пункте.
Четвёртый вариант. На сегодняшний день самый честный. Мне не известны способы там жульничать. Хотя я их не исключаю.
Крупный и всемирно известный институт соглашается развернуть у себя независимую систему тестирования решений. От производителей поступает SDK которое подвергается закрытому тестированию, в котором производитель не принимает участия. Тестирование имеет множество параметров, которые потом официально публикуются.
Сейчас такое тестирование производит NIST — американский национальный институт стандартов и технологий. Такое тестирование самое честное и интересное.
Нужно сказать, что NIST производит огромную работу. Они выработали пяток кейсов, выпускают новые апдейты раз в пару месяцев, постоянно совершенствуются и включают новых производителей. Вот тут можно ознакомиться с последним выпуском исследования.
Казалось бы, этот вариант идеален для анализа. Но нет! Основной минус такого подхода — мы не знаем, что в базе. Посмотрите вот на этот график:

Это данные двух компаний по которым проводилось тестирование. По оси x — месяца, y — процент ошибок. Тест я взял «Wild faces» (чуть ниже описание).
Внезапное повышение точности в 10 раз у двух независимых компаний (вообще там у всех взлетело). Откуда?
В логе NIST стоит пометка «база была слишком сложной, мы её упростили». И нет примеров ни старой базы, ни новой. На мой взгляд это серьёзная ошибка. Именно на старой базу была видна разница алгоритмов вендоров. На новой у всех 4-8% пропусков. А на старой было 29-90%. Моё общение с распознаванием лиц на системах видеонаблюдения говорит, что 30% раньше — это и был реальный результат у гроссмейстерских алгоритмов. Сложно распознать по таким фото:

И конечно, по ним не светит точность 4%. Но не видя базу NIST делать таких утверждений на 100% нельзя. Но именно NIST — это главный независимый источник данных.
В статье я описываю ситуацию актуальную на июль 2018 года. При этом опираюсь на точности, по старой базе лиц для тестов связанных с задачей «Faces in the wild».
Вполне возможно что через пол года всё измениться полностью. А может будет стабильным следующие десять лет.
Итак, нам нужна вот эта таблица:
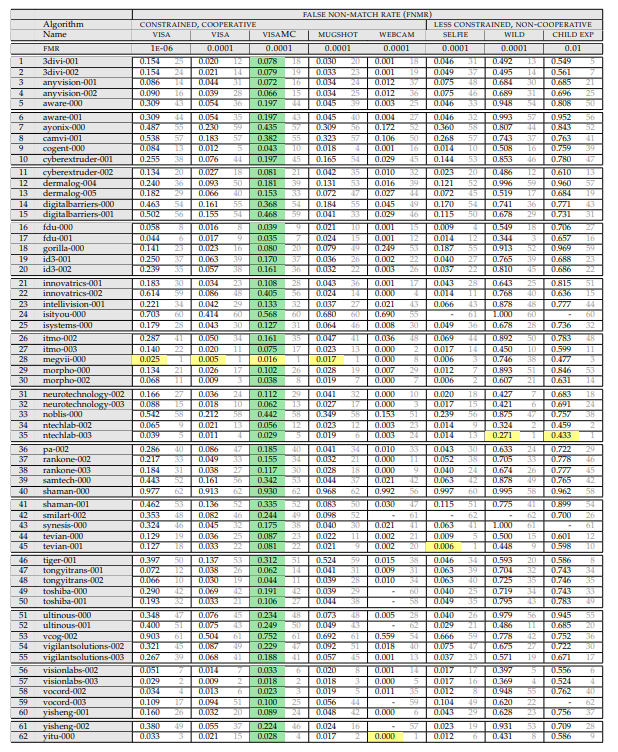
(апрель 2018, т.к. wild тут более адекватный)
Давайте разберём что в ней написано, и как оно измеряется.
Сверху идёт перечисление экспериментов. Эксперимент состоит из:
Того, на каком сете идёт замер. Сеты есть:
- Фотография на паспорт (идеальная, фронтальная). Задний фон белый, идеальные системы съёмки. Такое иногда можно встретить на проходной, но очень редко. Обычно такие задачи — это сравнение человека в аэропорту с базой.

- Фотография хорошей системой, но без топового качества. Есть задние фоны, человек может немного не ровно стоять/смотреть мимо камеры, и.т.д.

- Сэлфи с камеры смартфона/компьютера. Когда пользователь оказывает кооперацию, но плохие условия съёмки. Есть два подмножества, но много фото у них только в «сэлфи»

- «Faces in the wild» — съёмка практически с любой стороны/скрытая съёмка.Максимальные углы поворота лица к камере — 90 градусов. Именно тут NIST ооочень сильно упростил базу.
- Дети. Все алгоритмы работают плохо по детям.




Того при каком уровне ошибок первого рода идёт замер (этот параметр рассматривается только для фотогафий на паспорт):
- 10^-4 — FAR (одно ложное срабатывание первого рода) на 10 тысяч сравнений с базой
- 10^-6 — FAR (одно ложное срабатывание первого рода) на миллион сравнений с базой
Результат эксперимента — величина FRR. Вероятность того что мы пропустили человека который есть в базе.
И уже тут внимательный читатель мог заметить первый интересный момент. «Что значит FAR 10^-4?». И это самый интересный момент!
Главная подстава
Что вообще такая ошибка значит на практике? Это значит, что на базу в 10 000 человек будет одно ошибочное совпадение при проверке по ней любого среднестатистического человека. То есть, если у нас есть база из 1000 преступников, а мы сравниваем с ней 10000 человек в день, то у нас будет в среднем 1000 ложных срабатываний. Разве это кому то нужно?
В реальности всё не так плохо.
Если посмотреть построить график зависимости ошибки первого рода от ошибки второго рода, то получится такая классная картинка (тут сразу для десятка разных фирм, для варианта Wild, это то что будет на станции метро, если камеру поставить где-то чтобы её не видели люди):
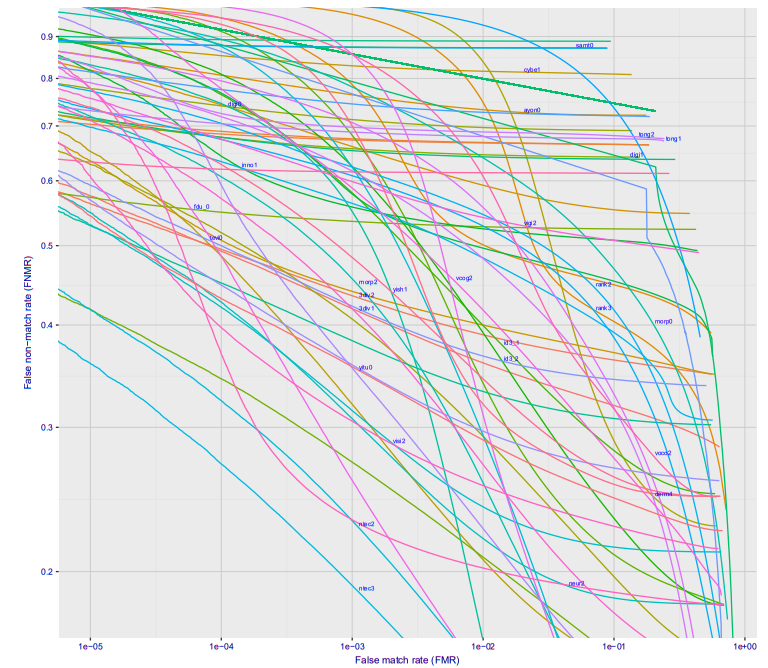
При ошибке 10^-4 27% процентов не распознанных людей. На 10^-5 примерно 40%. Скорее всего на 10^-6 потери составят примерно 50%
Итак, что это значит в реальных цифрах?
Лучше всего идти от парадигмы «сколько ошибок в день можно допустить». У нас на станции идёт поток людей, если каждые 20-30 минут система будет давать ложное срабатывание, то никто не будет её воспринимать всерьёз. Зафиксируем допустимое число ложных срабатываний на станции метро 10 человек в день (по хорошему, чтобы система не была выключена как надоедливая — нужно ещё меньше). Поток одной станции Московского метрополитена 20-120 тысяч пассажиров в сутки. Среднее — 60 тысяч.
Пусть зафиксированное значение FAR — 10^-6 (ниже ставить нельзя, мы и так при оптимистической оценке потеряем 50% преступников). Это значит что допустить 10 ложных тревог мы можем при размере базы в 160 человек.
Много это или мало? Размер базы в федеральном розыске ~ 300 000 человек. Интерпола 35 тысяч. Логично предположить, что где-то 30 тысяч москвичей находятся в розыске.
Это даст уже нереальное число ложных тревог.
Тут стоит отметить, что 160 человек может быть и достаточной базой, если система работает on-line. Если искать тех кто совершил преступление в последние сутки — это уже вполне рабочий объём. При этом, нося чёрные очки/кепки, и.т.д., замаскироваться можно. Но много ли их носит в метро?
Второй важный момент. Несложно сделать в метро систему дающее фото более высокого качества. Например поставить на рамки турникетов камеры. Тут уже будет не 50% потерь на 10^-6, а всего 2-3%. А на 10^-7 5-10%. Тут точности из графика на Visa, всё будет конечно сильно хуже на реальных камерах, но думаю на 10^-6 можно оставить сего 10% потерь:

Опять же, базу в 30 тысяч система не потянет, но всё что происходит в реальном времени детектировать позволит.
Первые вопросы
Похоже время ответить на первую часть вопросов:
Ликсутов заявил что выявили 22 находящихся в розыске человека. Правда ли это?
Тут основной вопрос — что эти люди совершили, сколько было проверено не находящихся в розыске, насколько в задержании этих 22 людей помогло распознавание лиц.
Скорее всего, если это люди которых искали планом «перехват» — это действительно задержанные. И это неплохой результат. Но мои скромные предположения позволяют сказать, что для достижения этого результата было проверено минимум 2-3 тысячи людей, а скорее около десятка тысяч.
Это очень хорошо бьётся с цифрами которые называли в Лондоне. Только там эти числа честно публикуют, так как люди протестуют. А у нас замалчивают…
Вчера на Хабре была статья на счёт ложняков по распознаванию лиц. Но это пример манипуляций в обратную сторону. У Амазона никогда не было хорошей системы распознавания лиц. Плюс вопрос того как настроить пороги. Я могу хоть 100% ложняков сделать, подкрутив настройки;)
Про Китайцев, которые распознают всех на улице — очевидный фэйк. Хотя, если они сделали грамотный трекинг, то там можно сделать какой-то более адекватный анализ. Но, если честно, я не верю что пока это достижимо. Скорее набор затычек.
А что с моей безопасностью? На улице, на митинге?
Поехали дальше. Давайте оценим другой момент. Поиск человека с хорошо известной биографией и хорошим профилем в соцсетях.
NIST проверяет распознавание лица к лицу. Берётся два лица одного/разных людей и сравнивается насколько они близки друг к другу. Если близость больше порога, тогда это один человек. Если дальше — разные. Но есть другой подход.
Если вы почитали статьи, которые я советовал в начале — то знаете, что при распознавании лица формируется хэш-код лица, отображающий его положение в N-мерном пространстве. Обычно это 256/512 мерное пространство, хотя у всех систем по разному.
Идеальная система распознавания лиц переводит одно и то же лицо в один и тот же код. Но идеальных систем нет. Одно и то же лицо обычно занимает какую-то область пространства. Ну, например, если бы код был двумерным, то это могло бы быть как-то так:
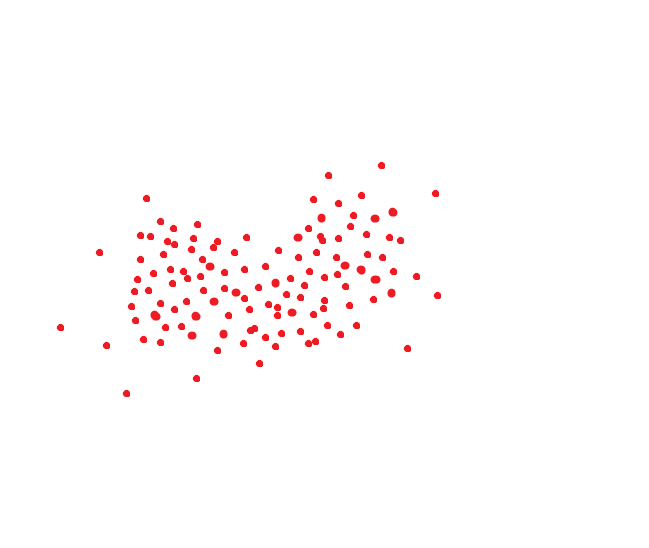
Если мы руководствуемся методом который принимается в NIST, то вот это расстояние было бы целевым порогом, чтобы мы могли распознать человека как одного и того же индивида с вероятностью под 95%:
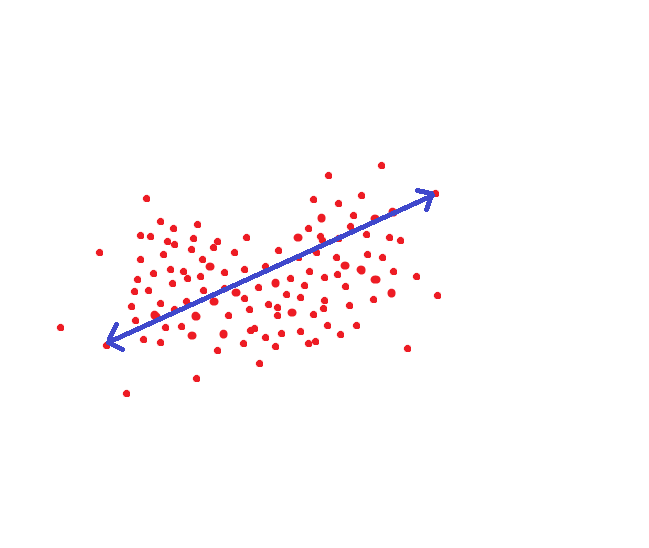
Но ведь можно поступить по другому. Для каждого человека настроить область гиперпространства где хранятся достоверные для него величины:

Тогда пороговое расстояние при сохранении точности уменьшится в несколько раз.
Только нам нужно очень много фотографий на каждого человека.
Если у человека есть профиль в социальных сетях / база его снимков разного возраста, то точность распознавания можно повысить очень сильно. Точной оценки того как вырастает FAR|FRR я не знаю. Да и оценивать уже некорректно такие величины. У кого-то в такой базе 2 фото, у кого-то 100. Очень много обёрточной логики. Мне кажется, что максимальная оценка — один/полтора порядка. Что позволяет дострелить до ошибок 10^-7 при вероятности не распознавания 20-30%. Но это умозрительно и оптимистично.
Вообще, конечно, с менеджментом данного пространства проблем не мало (возрастные фишки, фишки редакторов изображений, фишки шумов, фишки резкости), но как я понимаю большая часть уже успешно решена у крупных фирм кому было нужно решение.
К чему это я. К тому, что использование профилей позволяет в несколько раз поднять точность алгоритмов распознавания. Но она далека от абсолютной. С профилями требуется много ручной работы. Похожих людей много. Но если начинать задавать ограничения по возрасту, местонахождению, и.т.д., то этот метод позволяет получить хорошее решение. На пример того как нашли человека по принципу «найти профиль по фото»->«использовать профиль для поиска человека» я давал ссылку в начале.
Но, на мой взгляд, это сложно масштабируемый процесс. И, опять же, людей с большим числом фоток в профиле дай бог 40-50% в нашей стране. Да и многие из них дети, по которым всё плохо работает.
Но, опять же — это оценка.
Так вот. Про вашу безопасность. Чем меньше у вас фото в профиле — тем лучше. Чем более многочисленный митинг куда вы идёте — тем лучше. Никто не будет разбирать 20 тысяч фотографий в ручную. Тем кто заботиться о своей безопасности и приватности — я бы советовал не делать профилей со своими картинками.
На митинге в городе с 100 тысячным населением вас легко найдут, просмотря 1-2 совпадения. В Москве — задолбаются. Где-то пол года назад Vasyutka, с которым мы работаем вместе, давал рассказывал на эту тему:
Кстати, про соцсети
Тут я позволю себе сделать небольшой экскурс в сторону. Качество обучения алгоритма распознавания лиц зависит от трёх факторов:
- Качество выделения лица.
- Используемая метрика близости лиц при обучения Triplet Loss, Center Loss, spherical loss, и.т.д.
- Размер базы
По п.2 вроде как сейчас достигнут предел. В принципе, математика развивается по таким вещам очень быстро. Да и после triplet loss остальные функции потерь не давали драматического прироста, лишь плавное улучшение и понижение размера базы.
Выделение лица — это сложно, если надо найти лица под всеми углами, потеряв доли процента. Но создание такого алгоритма — это достаточно предсказуемый и хорошо управляемый процесс. Чем более всё синее, тем лучше, большие углы корректно обрабатываются:

А полгода назад было так:

Видно, что потихоньку всё больше и больше компаний проходят этот путь, алгоритмы начинают распознавать всё более и более повёрнутые лица.
А вот с размером базы — всё интереснее. Открытые базы — маленькие. Хорошие базы максимум на пару десятков тысяч человек. Те что большие — странно структурированы / плохие (megaface, MS-Celeb-1M).
Как вы думаете, откуда создатели алгоритмов взяли эти базы?
Маленькая подсказка. Первый продукт NTech, который они сейчас сворачивают — Find Face, поиск людей по вконтакту. Думаю пояснения не нужны. Конечно, вконтакт борется с ботами, которые выкачивают все открытые профили. Но, насколько я слышал, народ до сих пор качает. И одноклассников. И инстаграмм.
Вроде как с Facebook — там всё сложнее. Но почти уверен, что что-то тоже придумали.
Так что да, если ваш профиль открыт — то можете гордиться, он использовался для обучения алгоритмов;)
Про решения и про компании
Тут можно гордиться. Из 5 компаний-лидеров в мире сейчас два — Российские. Это N-Tech и VisionLabs. Пол года назад лидерами был NTech и Vocord, первые сильно лучше работали по повёрнутым лицам, вторые по фронтальным.
Сейчас остальные лидеры — 1-2 китайских компании и 1 американская, Vocord что-то сдал в рейтингах.
Еще российские в рейтинге itmo, 3divi, intellivision. Synesis — белорусская компания, хотя часть когда-то была в Москве, года 3 назад у них был блог на Хабре. Ещё про несколько решений знаю, что они принадлежат зарубежным компаниям, но офисы разработки тоже в России. Ещё есть несколько российских компаний которых нет в конкурсе, но у которых вроде неплохие решения. Например есть у ЦРТ. Очевидно, что у Одноклассников и Вконтакте тоже есть свои хорошие, но они для внутреннего пользования.
Короче да, на лицах сдвинуты в основном мы и китайцы.
NTech вообще первым в миру показал хорошие параметры нового уровня. Где-то в конце 2015 года. VisionLabs догнал NTech только только. В 2015 году они были лидерами рынка. Но их решение было прошлого поколения, а пробовать догнать NTech они стали лишь в конце 2016 года.
Если честно, то мне не нравятся обе этих компании. Очень агрессивный маркетинг. Я видел людей которым было впарено явно неподходящее решение, которое не решало их проблем.
С этой стороны Vocord мне нравился сильно больше. Консультировал как-то ребят кому Вокорд очень честно сказал «у вас проект не получится с такими камерами и точками установки». NTech и VisionLabs радостно попробовали продать. Но что-то Вокорд в последнее время пропал.
Выводы
В выводах хочется сказать следующее. Распознавание лиц это очень хороший и сильный инструмент. Он реально позволяет находить преступников сегодня. Но его внедрение требует очень точного анализа всех параметров. Есть применения где достаточно OpenSource решения. Есть применения (распознавание на стадионах в толпе), где надо ставить только VisionLabs|Ntech, а ещё держать команду обслуживания, анализа и принятия решения. И OpenSource вам тут не поможет.
На сегодняшний день нельзя верить всем сказкам о том, что можно ловить всех преступников, или наблюдать всех в городе. Но важно помнить, что такие вещи могут помогать ловить преступников. Например чтобы в метро останавливать не всех подряд, а только тех кого система считает похожими. Ставить камеры так, чтобы лица лучше распознавались и создавать под это соответствующую инфраструктуру. Хотя, например я — против такого. Ибо цена ошибки если вас распознает как кого-то другого может быть слишком велика.
P.S.
В последнее время делаю много мелких статей/видеороликов. Но так как это не формат Хабра — то публикую их в блоге или на ютубе. Трансляция всего есть в телеге и вк.
На Хабре обычно публикую, когда рассказ становится уже более самозамкнутым, иногда собрав 2-3 разных мини-рассказа на соседние темы.
