Comments 12
А у Вас есть какие — нибудь примеры реальной реализации данной теории, например в Matlab? Интересно посмотреть на реальную работу данного алгоритма.
Извиняюсь, промахнулся комментарием. См. ниже
Да, само собой, есть. К сожалению, не в Mathlab. Реализация данной теории является модулем к системе поиска. Этот модуль, в частности, позволяет искать лица в коллекциях изображений. Используется библиотека OpenCV.
Какой процент правильного определения соответствия двух лиц, и конечно какой процент ошибочного определения? Спрашиваю, потом что интересует проф. пригодность алгоритма.
На первом этапе отсекается положенные 90-95% выборки. На втором этапе — уточняющем поиске — используется сравнение гистограмм, процент правильного определения составляет порядка 90%. К сожалению, остались некоторые моменты, из-за которых остается достаточно высокий процент ошибки. Например, тот же уточняющий поиск, а также, что самое главное, нормирование расстояния между двумя моментами.
как определяли пороги распознавания? и чему равно число скрытых состояний? откуда брали эти значения?
что Вы имеете ввиду под порогом распознавания?
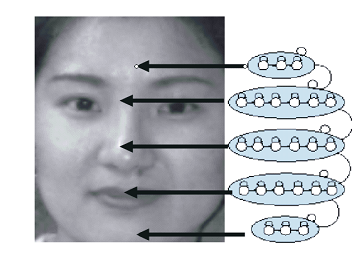
Число скрытых состояний выбиралось, как указано на рисунке. Т.е. 5 суперсотояний, соответственно 3, 6, 6, 6, 3 вложенных. Эти числа являются устоявшимися в задачах распознавания лиц на основе СММ. Опытным путем было установлено (не мной), что такой выбор является одним из самых оптимальных (если не самым оптимальным).
Число скрытых состояний выбиралось, как указано на рисунке. Т.е. 5 суперсотояний, соответственно 3, 6, 6, 6, 3 вложенных. Эти числа являются устоявшимися в задачах распознавания лиц на основе СММ. Опытным путем было установлено (не мной), что такой выбор является одним из самых оптимальных (если не самым оптимальным).
{kind=link}
Я так понимаю есть минимум 2 СММ модели. 1-лицо. 2-не лицо. СММ выдает вероятность принадлежности ей выборки. Для того чтобы выбрать ответ «да лицо» или нет, не лицо — надо сравнивать с порогом выход. Например СММ1 дал 5% а СММ2 дал 3%, то есть рисунок не похож ни на лицо ни на что иное. Или же другой пример. СММ1 дал 75% а СММ2 дал 65%. Достаточно ли 75% для определения что да, наш рисунок содержит лицо? Т.е. стоит вопрос 0.75>K или нет? и чему равно K?
Простите, написал не в то окно. См. ниже
Вот как раз здесь и открывается самый главный недостаток СММ. Эти модели не могут отсечь часть классов, как неподходящие, метод показывает лишь, какая из моделей подходит больше. Возвращаясь, к вашим примерам:
1. «Например СММ1 дал 5% а СММ2 дал 3%, то есть рисунок не похож ни на лицо ни на что иное». С точки зрения СММ на рисунке будет лицо
2. аналогично
Следующее, возможно, не совсем относится к вопросу, но все же поясню.
В моей работе реализовано несколько иначе. Во-первых, на изображениях ищутся лица с помощью классификаторов Хаара. Данный метод показывает довольно большую точность для лиц. Если результат был положительным — следовательно, на изображении присутствуют лица (на этом же этапе получаем и местоположение лиц, что отсекает ненужные шумы). Далее, у нас есть некоторое число натренированных моделей (в терминах поиска по дереву — это ключи). И уже следующим этапом находятся степени соответствия найденных изображений лиц и данных моделей-ключей.
1. «Например СММ1 дал 5% а СММ2 дал 3%, то есть рисунок не похож ни на лицо ни на что иное». С точки зрения СММ на рисунке будет лицо
2. аналогично
Следующее, возможно, не совсем относится к вопросу, но все же поясню.
В моей работе реализовано несколько иначе. Во-первых, на изображениях ищутся лица с помощью классификаторов Хаара. Данный метод показывает довольно большую точность для лиц. Если результат был положительным — следовательно, на изображении присутствуют лица (на этом же этапе получаем и местоположение лиц, что отсекает ненужные шумы). Далее, у нас есть некоторое число натренированных моделей (в терминах поиска по дереву — это ключи). И уже следующим этапом находятся степени соответствия найденных изображений лиц и данных моделей-ключей.
Хм, каждая СММ модель — узел вершины графа дерева, переходя от узла к узлу определяем лучшую модель?
Если так, да и вообще, так или не так — это неплохая идея семантического графа скрытых марковских моделей для решения сложных задач.
Каждая СММ в узле графа может отвечать за свой конкретный вопрос, и передвигаясь по СММ узлам дерева можно реализовать и экспертную систему и нейронные сети (СММ в роли функции нейрона) да и вообще!
Вам + за мысль :)
Если так, да и вообще, так или не так — это неплохая идея семантического графа скрытых марковских моделей для решения сложных задач.
Каждая СММ в узле графа может отвечать за свой конкретный вопрос, и передвигаясь по СММ узлам дерева можно реализовать и экспертную систему и нейронные сети (СММ в роли функции нейрона) да и вообще!
Вам + за мысль :)
Sign up to leave a comment.
Поиск лиц на основе скрытых марковских моделей