Comments 407
В руби 2 пробела — и никаких проблем) Не очень согласен с тобой — мало кто пользуется «умной табуляцией» — на практике никто не заморачивается настройкой и лепят как хотят.
Ну это проблемы не табов, а горе-программистов) Пробелами тоже ведь можно отступы сделать ужасными ;)
На самом деле у нормальных разработчиков такая проблема не стоит — они используют принятый для языка стандарт кодирования. А вот кривых товарищей так просто не переучить, даже вытутаирав этот самый стандарт кодирования у них на лбу и дав зеркало. Против таких помогают только хуки в SCM и удар молотком по пальцам за кривые отступы.
Допустим у меня в одном проекте код на C, C++, Perl и Bash… по каждому идти читать «принятый» для языка стандарт, а затем в редакторе постоянно переключать с одного на другое?
Не надо выдумывать сложностей. Дома у меня большой дисплей, там таб широкий — это удобно. А на нетбуке в дороге экранчик маленький, там таб узенький — опять же удобно. А те кто делают отступы пробелами лишают меня такой возможности.
Не надо выдумывать сложностей. Дома у меня большой дисплей, там таб широкий — это удобно. А на нетбуке в дороге экранчик маленький, там таб узенький — опять же удобно. А те кто делают отступы пробелами лишают меня такой возможности.
Не важно сколько уровней вложенности код. Там где табы и малая вложенность я могу открыть на нетбуке два листинга сразу. Там где строго 4 пробела — этого уже не сделаешь, ибо не помещается.
Нет ни единого аргумента, чтобы использовать пробелы вместо табов для отступов.
p.s. вы правда считаете, что всякий алгоритм можно отрефакторить до 2-4 уровней?
Нет ни единого аргумента, чтобы использовать пробелы вместо табов для отступов.
p.s. вы правда считаете, что всякий алгоритм можно отрефакторить до 2-4 уровней?
p.s. вы правда считаете, что всякий алгоритм можно отрефакторить до 2-4 уровней?
да, причём не только можно, но и нужно :)
ну и функции декомпозировать, если больше 2х сферических экранов.
На скриншоте типичный кусок кода виртуальной машины. Не мой, но насколько я разбираюсь в виртуальных машинах, и насколько могу оценить код, отрефакторить там что-либо без потери производительности и/или читабельности практически невозможно. Да и не нужно.
И да, 2000 строк кода это одна функция.

p. s. автор этих строк профессионал с огромным опытом, работающий в одной крупной и всем известной ИТ-компании.
И да, 2000 строк кода это одна функция.

p. s. автор этих строк профессионал с огромным опытом, работающий в одной крупной и всем известной ИТ-компании.
>отрефакторить там что-либо без потери производительности и/или читабельности практически невозможно.
Я вот прекрасно вижу ворох if-then-else, которые меняются свичами.
Я вот прекрасно вижу ворох if-then-else, которые меняются свичами.
switch -> call table а внутри функций из этой таблицы будет вложенность 2-3, судя по коду.
На производительности это ни скажется ни разу, ибо современные компиляторы сами используют такой подход при генерации кода.
Единственный минус такой замены в плюсах/си только то, что мы не сможет в case'ах падать вниз, что самом по себе является дурным тоном.
Ну вроде такого:
Ну а насчет «красивости» — мне свитчи совсем не нравятся, использую таблицы вызовов довольно часто. Здесь дело вкуса.
На производительности это ни скажется ни разу, ибо современные компиляторы сами используют такой подход при генерации кода.
Единственный минус такой замены в плюсах/си только то, что мы не сможет в case'ах падать вниз, что самом по себе является дурным тоном.
Ну вроде такого:
case 'a':
doSomeForA();
case 'b'"
doSomeForAB();
break;
Ну а насчет «красивости» — мне свитчи совсем не нравятся, использую таблицы вызовов довольно часто. Здесь дело вкуса.
На производительности это скажется значительно. Могу сказать наверняка, поскольку достаточно поэкспериментировал с интерпретаторами ARM CPU, Java, ECMAScript.
1. Вызов функции сопровождается как минимум сохранением адреса возврата на стеке, а зачастую еще и регистров, что совсем не нужно в случае со switch.
2. Компилятор может соптимизиоровать безусловный переход на начало switch + вычисляемый переход на нужный case в один переход, добавляемый после каждого case. С функциями из call table такая оптимизация невозможна.
3. Со switch «горячие» указатели (Instruction pointer, Stack pointer и т.п.) будут локальными переменными и закэшируются в регистрах. С функциями и таблицей переходов это будут либо глобальные переменные, либо локальные переменные, передаваемые по ссылке. И то, и другое менее эффективно.
В GCC есть computed goto, что хорошо подходит для написания эффективного интерпретатора, однако это не входит в стандарт С, и другими компиляторами не поддерживается.
Мне понравилось решение этой проблемы с помощью макросов CASE/ENDCASE/DISPATCH, которые могут быть раскрыты в switch/case, computed goto или call table в зависимости от условий.
1. Вызов функции сопровождается как минимум сохранением адреса возврата на стеке, а зачастую еще и регистров, что совсем не нужно в случае со switch.
2. Компилятор может соптимизиоровать безусловный переход на начало switch + вычисляемый переход на нужный case в один переход, добавляемый после каждого case. С функциями из call table такая оптимизация невозможна.
3. Со switch «горячие» указатели (Instruction pointer, Stack pointer и т.п.) будут локальными переменными и закэшируются в регистрах. С функциями и таблицей переходов это будут либо глобальные переменные, либо локальные переменные, передаваемые по ссылке. И то, и другое менее эффективно.
В GCC есть computed goto, что хорошо подходит для написания эффективного интерпретатора, однако это не входит в стандарт С, и другими компиляторами не поддерживается.
Мне понравилось решение этой проблемы с помощью макросов CASE/ENDCASE/DISPATCH, которые могут быть раскрыты в switch/case, computed goto или call table в зависимости от условий.
CASE(opcode1)
handle_opcode_1;
DISPATCH(1)
ENDCASE
CASE(opcode2)
handle_opcode_2;
DISPATCH(2)
ENDCASE
хе, вы правы, ~15% разница.
Основная проблема в том, что компилятор не распознаёт то, какую функцию мы вызываем. И не может соптимизировать — инлайн не выполняется, оптимизация по регистрам тоже невозможно, так как не известно в каком окружении вызывается табличная функция, и какие регистры свободны, для case'ов такой проблемы нет.
Действительно, насчет производительности я был не прав.
Основная проблема в том, что компилятор не распознаёт то, какую функцию мы вызываем. И не может соптимизировать — инлайн не выполняется, оптимизация по регистрам тоже невозможно, так как не известно в каком окружении вызывается табличная функция, и какие регистры свободны, для case'ов такой проблемы нет.
Действительно, насчет производительности я был не прав.
Избавиться от дублирования кода — это первое.
Второе — инвертировать if. То есть заменить
И никакой многоступенчатой вложенности.
Второе — инвертировать if. То есть заменить
if (cond) {
// do something
} else {
// error
}if (!cond) {
// error, break
}
// no error
// do somethingИ никакой многоступенчатой вложенности.
А можете объяснить, почему этот коммент минусуют?
Вот сколько уже борюсь с этим — не помогает.
Ваше предложение плохо тем что вы подменяете логику работы кода и ухудшаете его читабельность.
Вместо того чтобы сказать при определенном условии — сделай то-то и то (например — если прошел запрос к базе данных — выведи ответ на веб страницу), а если упало — обработай ошибку. Вы меняете его на если что-то упало — выведи ошибку, а вот если не упало — сделай то-то (если запрос не прошел — выведи ошибку, а если прошел — напечатай информацию). Это намного более непонятно, тк более специфичная или даже исключительная ситуация обрабатывается раньше чем нормальная логика приложения.
Ваше предложение плохо тем что вы подменяете логику работы кода и ухудшаете его читабельность.
Вместо того чтобы сказать при определенном условии — сделай то-то и то (например — если прошел запрос к базе данных — выведи ответ на веб страницу), а если упало — обработай ошибку. Вы меняете его на если что-то упало — выведи ошибку, а вот если не упало — сделай то-то (если запрос не прошел — выведи ошибку, а если прошел — напечатай информацию). Это намного более непонятно, тк более специфичная или даже исключительная ситуация обрабатывается раньше чем нормальная логика приложения.
Читабельность таких замен субъективна, сравните:
и
А представьте, что таких проверок десяток? Даже просто посмотреть какое исключение выбросится для не сработавшего условия где-нить на 5-м уровне вложенности может быть не просто в первом варианте. Да даже выделить глазом сразу где собственно основной код. А во втором, по-моему, проще — глаз пробегает по кучке проверок, не вникая в их суть, и останавливается на основном коде. Главное, чтобы более специфичная или исключительная логика была элементарна — если не получается уложиться в 1-2 строчки, по которым с первого взгляда видно, что они обрабатывают специфическую ситуацию, то надо их выделять в функцию/метод с соответствующим именем.
if ($user)
if ($user.has_right('hello')
if ($name = $user.getNameFromDB())
echo "hello {$name}";
else
throw new DBEcxeption;
else
throw new ForbiddenException;
else
throw new NeedAutenticateException;
и
if (!$user)
throw new NeedAutenticateException;
if (!$user.has_right('hello')
throw new ForbiddenException;
if (!($name = $user.getNameFromDB()))
throw new DBEcxeption;
echo "hello {$name}";
А представьте, что таких проверок десяток? Даже просто посмотреть какое исключение выбросится для не сработавшего условия где-нить на 5-м уровне вложенности может быть не просто в первом варианте. Да даже выделить глазом сразу где собственно основной код. А во втором, по-моему, проще — глаз пробегает по кучке проверок, не вникая в их суть, и останавливается на основном коде. Главное, чтобы более специфичная или исключительная логика была элементарна — если не получается уложиться в 1-2 строчки, по которым с первого взгляда видно, что они обрабатывают специфическую ситуацию, то надо их выделять в функцию/метод с соответствующим именем.
Да, тут это ещё не очень очевидно. Куда очевиднее, когда непосредственно кода больше (много строк) и вложенность повыше.
Слушайте, не могу понять, что это за язык)
Первый пример по мне читабельней тк явно выражает логику кода:
(кстати про доступность информации из базы — вполне можно вынести проверку доступности именно в тот код, кде доступ происходит — более логично)
Вторая запись мне говорит:
вы говорите об абстрактной читаемости и красоте, а я о практической — которая помогает понимать — что код делает и зачем он был написан.
От большой вложенности стоит спасаться — это факт, но для этого есть другие средства:
1) лучшая локализация места в котором происходи ошибка
2) extract method
если пользователь зарегистрирован,
если пользователь имеет право на просмотр записи
если эта запись присутствует в базе данных
то нужно вывести ему эту запись (кстати про доступность информации из базы — вполне можно вынести проверку доступности именно в тот код, кде доступ происходит — более логично)
Вторая запись мне говорит:
если пользователь не зарегистрирован
соощить обо ошибке
если пользователь не имеет прав
сообщить об ошибке (примерно на этом месте я забываю зачем я вообще
полез в эту функцию)
если записи не существует в базе
сообщить об ошибке
вывести результат
вы говорите об абстрактной читаемости и красоте, а я о практической — которая помогает понимать — что код делает и зачем он был написан.
От большой вложенности стоит спасаться — это факт, но для этого есть другие средства:
1) лучшая локализация места в котором происходи ошибка
2) extract method
Вот как раз extract method слабо применимо для улучшения понимаемости кода без такой инверсии условий по-моему. От вложенности if мы перейдём к вложенности методов, да ещё с передачей кучи параметров по цепочке (либо использование глобальных переменных в широком смысле слова) и возвратом значений назад по этой цепочке.
Кончено, код
читабельней любого варианта, но, имхо, как раз читабельней абстрактно.
Кончено, код
if ($user)
echo getNonEmtyNameFromDBIfUserHasRight($user);
else
throw new NeedAutenticateException;
читабельней любого варианта, но, имхо, как раз читабельней абстрактно.
Знаете, сколько раз приходилось таким образом разворачивать логику из семиступенчатых if, читабельность кода только улучшалась. Потому что когда вложенность высокая, читабельность падает катастрофически.
И логику никто не подменяет. Она остаётся прежней. Ведь суть логики — только если все проверки пройдены, выполнить код.
И логику никто не подменяет. Она остаётся прежней. Ведь суть логики — только если все проверки пройдены, выполнить код.
Ну да, тов. Щ мы по его коду узнаем :)
Узнал код, долго смеялся :).
Два листинга нужно чтобы в одном писать код, а второй листинг служит документацией. Особенно удобно в проектах с >100 000 строк кода.
Когда пишу на си и привязываю что-то, то просто необходимо перед глазами видеть хидер. Либо документацию.
Хедер. От слова head. Извините.
Извините, я не знаком с еврейскими традициями. Но хорошо, когда рядом есть знающие люди ;)
«заголовочный файл», так проще :)
А транслитерация и транскрипция английского на русский вообще дело не благодарное. Особенно в ИТ: меня, например, особенно раздражают слова «тег», «кеш», «фреймворк» и т. п., где английская «a» «переводится» на русский как «e».
Странно, что раздражает. Это как раз самый распространенный вариант транслитерации.
Сочетание «ei» (дающее дифтонг) — «ей»,
Буква «a» в закрытом слоге (и это не английское «а», а полудолгий звук, которого в русском вообще нет) — «е», допустимо также «а».
Сочетание «ei» (дающее дифтонг) — «ей»,
Буква «a» в закрытом слоге (и это не английское «а», а полудолгий звук, которого в русском вообще нет) — «е», допустимо также «а».
«каш»!
«Когерентность каша» :)
Меня, лично, очень радует такой вариант заимствования: «читается КАК пишется(ближайшее слово ИЗ ( дословный_перевод(), дословный_перевод_корней(), транслитерация() ))».
Типа: «action» — «акция», «dataform» — «датаформа».
«Когерентность каша» :)
Меня, лично, очень радует такой вариант заимствования: «читается КАК пишется(ближайшее слово ИЗ ( дословный_перевод(), дословный_перевод_корней(), транслитерация() ))».
Типа: «action» — «акция», «dataform» — «датаформа».
Радует, конечно, в кавычках.
А вообще — добрые, необычные искажения слов при заимствовании идут языку и его носителям только на пользу.
Чего стоит одна только «вьюшка» против монструозного «представления» на устах суровых ораклоидов.
А вообще — добрые, необычные искажения слов при заимствовании идут языку и его носителям только на пользу.
Чего стоит одна только «вьюшка» против монструозного «представления» на устах суровых ораклоидов.
Когерентность кэша :)
Дословный перевод обычно всё же не плох, если переводится нужное значение слова, а не первое попавшееся, особенно если у этого первого попавшегося несколько значений в русском языке, в общем «действие», а не «акция»
Дословный перевод обычно всё же не плох, если переводится нужное значение слова, а не первое попавшееся, особенно если у этого первого попавшегося несколько значений в русском языке, в общем «действие», а не «акция»
Зачастую удобно видеть перед собой заголовочный файл или, к примеру, контекст использования функции, вместо того чтобы постоянно переключаться Ctrl+Tab'ом между вкладками.
Вопрос: вы когда-нибудь писали более-менее серьёзный проект на C?
>Жизнь учит С++ программистов писать простой код, который можно достаточно быстро и легко понять.
К сожалению, не всех. И код приходится читать… хм… всякий.
К сожалению, не всех. И код приходится читать… хм… всякий.
Использование стороннего кода не рассматриваете?
Загляните к примеру stdio.h от glibc… Да вообще в любой GNU'тый исходник. Монитор долго отмывать надо будет.
Можно взять весьма распространённый C++. И таки какой же для него стандарт кодирования принят? Пишут все, кто во что горазд.
Автор, тогда уж отпишись, что раньше появилось: яйцо или курица. Холиварить, так по полной.
А о «проблемах», уж не знаю, для кого это действительно проблема… Наверное для клавиатуры, снашивается всё-таки, можно было клацнуть один раз таб, а кликают 2 раза пробел. Двойная нагрузка как никак, баг ^^
Вопрос читабельности — так это вообще ничего не решает. На собственном опыте, отступ в 1-8 никак не сказывается, пробел это или таб, не важно. Куда страшнее, когда в кривом коде идёт всё без отступов, сплошные черезстрочные пропуски и переменные в алфавитном порядке.
Лично я ушёл с таба на пробел лет 5 назад, по мне так удобней, но как говорится, это дело личных предпочтений. Кстати, о том чтобы настраивать на каждой машине отдельно размер табуляции под свои предпочтения, что мешает:
а) заменить пробелы на табы (решение в 5 сек в любом редакторе кода)
б) клацнуть на выравнивание кода
Имхо, это раздутый на пустом месте спор.
А о «проблемах», уж не знаю, для кого это действительно проблема… Наверное для клавиатуры, снашивается всё-таки, можно было клацнуть один раз таб, а кликают 2 раза пробел. Двойная нагрузка как никак, баг ^^
Вопрос читабельности — так это вообще ничего не решает. На собственном опыте, отступ в 1-8 никак не сказывается, пробел это или таб, не важно. Куда страшнее, когда в кривом коде идёт всё без отступов, сплошные черезстрочные пропуски и переменные в алфавитном порядке.
Лично я ушёл с таба на пробел лет 5 назад, по мне так удобней, но как говорится, это дело личных предпочтений. Кстати, о том чтобы настраивать на каждой машине отдельно размер табуляции под свои предпочтения, что мешает:
а) заменить пробелы на табы (решение в 5 сек в любом редакторе кода)
б) клацнуть на выравнивание кода
Имхо, это раздутый на пустом месте спор.
>можно было клацнуть один раз таб, а кликают 2 раза пробел
в нормальных редакторах нажатие [Tab] вставляет нужное количество пробелов.
для удаления — либо backspace удаляет правильно, если это indent; либо Shift+Tab
в нормальных редакторах нажатие [Tab] вставляет нужное количество пробелов.
для удаления — либо backspace удаляет правильно, если это indent; либо Shift+Tab
Ах да, забыл:
1) Windows vs Linux
2) Apache vs Nginx
3) Firefox vs Opera
4) QIP vs Miranda IM
5) ICQ vs Jabber
6) iPod vs Cowon
7) Яйцо vs Курица
1) Windows vs Linux
2) Apache vs Nginx
3) Firefox vs Opera
4) QIP vs Miranda IM
5) ICQ vs Jabber
6) iPod vs Cowon
7) Яйцо vs Курица
1. Windows для отдыха, Линукс для работы.
2. lighttpd
3. FF + Chrome
4. Skype
5. см. пункт 4
6. не слушаю музыку с портативных устройств, берегу уши
7. Выбираю глазунью и куриный биток
Мне так удобнее, любите запускать игры под вайном, ваше дело. Обожаете Оперу, ну что же, тоже нормальный браузер и т.д. А те кто с пеной у рта доказывают, что надо использовать только «это», просто не умеет выбирать сам.
2. lighttpd
3. FF + Chrome
4. Skype
5. см. пункт 4
6. не слушаю музыку с портативных устройств, берегу уши
7. Выбираю глазунью и куриный биток
Мне так удобнее, любите запускать игры под вайном, ваше дело. Обожаете Оперу, ну что же, тоже нормальный браузер и т.д. А те кто с пеной у рта доказывают, что надо использовать только «это», просто не умеет выбирать сам.
Мне кажется, они просто не уверены в своём выборе и думают, что если докажут кому-то что, скажем Опера круче всех, то так оно и есть. И это прибавит им уверенности в их выборе :)
Скажем так, я к примеру знаю, что Opera круче всех :) Я уверен в своём выборе и поэтому её использую. И табы для отступов мне нравятся больше, чем пробелы. Всё дело в том, что никто не может/не вправе судить о таких вещах объективно.
И почему-то мне кажется, что вы не будете говорить, что Файрфокс/Сафари/Хром отстой — не так ли? Потому что вы знаете, что вам Опера подходит. А те, кто не уверен пытаются таким образом себя обмануть. Может, в психологии это даже как-то называется, потому что встречается повсеместно :)
А я не говорю что Opera круче всех, я просто её юзаю :)
Обычно не обращаю внимания на холивары какой браузер лучше, но меня удивляют товарищи, которые видя у меня например неработоспособность какого-то js, использующего фичи какого-то браузера, сразу констатируют «ну это же опера», при этом в аналогичной ситуации, но когда что-то не работает в «их» браузере, долго возмущаюся на код :)
Ну не знаю. Работаю в том браузере, который мне удобней и в которой по моим «сферам интересов» всё работает нормально, а других учить жить в этом отношении не лезу. Но и другими браузерами пользуюсь при необходимости. Какой смысл с пеной у рта доказывать что-то своё кому-то с противоположным мнением, если сам уверен в своём выборе и почти так же уверен, что оппоненту на твои аргументыпокластьвсё равно, ему важднее тебя убедить в своём…
Обычно не обращаю внимания на холивары какой браузер лучше, но меня удивляют товарищи, которые видя у меня например неработоспособность какого-то js, использующего фичи какого-то браузера, сразу констатируют «ну это же опера», при этом в аналогичной ситуации, но когда что-то не работает в «их» браузере, долго возмущаюся на код :)
Ну не знаю. Работаю в том браузере, который мне удобней и в которой по моим «сферам интересов» всё работает нормально, а других учить жить в этом отношении не лезу. Но и другими браузерами пользуюсь при необходимости. Какой смысл с пеной у рта доказывать что-то своё кому-то с противоположным мнением, если сам уверен в своём выборе и почти так же уверен, что оппоненту на твои аргументы
Apache — веб-сервер; nginx — нет.
А что же такое nginx, простите?
Ну вот, холиварчик уже начался, прям классически :)
Реверсивный прокси-сервер.
Можно даже процитириовать с сайта нжынкса:
— nginx [engine x] is a HTTP and reverse proxy server, as well as a mail proxy server.
Для интереса хотя бы посмотрели что это такое, на сайте очень развернутое описание. Если не умеете даже это гуглить, то вот, пользуйтесь → nginx.org/en/
Можно даже процитириовать с сайта нжынкса:
— nginx [engine x] is a HTTP and reverse proxy server, as well as a mail proxy server.
Для интереса хотя бы посмотрели что это такое, на сайте очень развернутое описание. Если не умеете даже это гуглить, то вот, пользуйтесь → nginx.org/en/
А буквы «HTTP» вы не заметили? ;)
Если попытаться корректно перевести на русский язык (с сохранением смысла), то получится что-то вроде «nginx — это HTTP- и прокси-сервер».
Т.е. он может работать и как HTTP server, и как reverse proxy server.
Если попытаться корректно перевести на русский язык (с сохранением смысла), то получится что-то вроде «nginx — это HTTP- и прокси-сервер».
Т.е. он может работать и как HTTP server, и как reverse proxy server.
and знаете что в английском означает?
nginx [engine x] is a HTTP… server — это в первую очередь.
Реверсивный HTTP-прокси сервер из него не очень. HTTP 1.1 для бэкенда не поддерживает. Лучше уж какой-нибудь squid юзать.
nginx [engine x] is a HTTP… server — это в первую очередь.
Реверсивный HTTP-прокси сервер из него не очень. HTTP 1.1 для бэкенда не поддерживает. Лучше уж какой-нибудь squid юзать.
Сильно просто:
1) MacOS X
2) Nginx
3) Safari/Chrome
4) Miranda IM^W Skype
5) Jabber
6) iPod
7) На завтрак глазунья, на ужин курочка.
1) MacOS X
2) Nginx
3) Safari/Chrome
4) Miranda IM^W Skype
5) Jabber
6) iPod
7) На завтрак глазунья, на ужин курочка.
1) Linux
2) Apache+Nginx
3) Chrome
4) Qutim
5) Skype
6) Cowon
7) Курица в маринаде :)
Холиварный ответ получился только на 2 вопроса )
2) Apache+Nginx
3) Chrome
4) Qutim
5) Skype
6) Cowon
7) Курица в маринаде :)
Холиварный ответ получился только на 2 вопроса )
А у меня вообще компьютера нет. И курицу я не люблю.
В Питоне нужно четкое кол-во оступов…
Редактирую массу исходников на разных языках,
Это дело вкуса notepad ++ или gedit легко настраиваются…
Вот кому тяжко после этой статьи — программистам на White Space
en.wikipedia.org/wiki/Whitespace_%28programming_language%29
Редактирую массу исходников на разных языках,
Это дело вкуса notepad ++ или gedit легко настраиваются…
Вот кому тяжко после этой статьи — программистам на White Space
en.wikipedia.org/wiki/Whitespace_%28programming_language%29
Постоянно ругаюсь с людьми, которые коммитят в репозиторий код с пробелами вместо табов. Хочется взять и расстрелять.
А вы попробуйте ввести стандарт, говорят помогает
и до кучи использовать утилиту вроде Astyle astyle.sourceforge.net
Аналогично, но наоборот ) В питоне стандарты например рекомендуют использовать именно 4 пробела, а не табы.
Рекомендуют не значит принуждают. Есть еще здравый смысл. И он подсказывает принять другие стандарты, пускай и противоречащие PEP8 в данном вопросе.
Собственно Zen of Python:
Special cases aren't special enough to break the rules.
Although practicality beats purity.

Другое дело, что для проверки соответствия стилю кода у python есть модуль pep8 и большинство разработчиков подразумевают, что в сторонних модулях стиль выдержан в духе рекомендаций. Проблемы возникают как раз у таких вот «special case» разработчиков.
В опенсорсе логично придерживаться рекомендаций. В компании — совсем даже не обязательно, т. к. шанс стороннего разработчика — минимален, а свои должны знать правила.
В питоне пусть сначала хотя бы стандартные библиотеки приведут к одному виду. Большая часть имеет идентификаторы с подчерком, но и сamelCase хватает несмотря на все зены и пепы. Сам работаю с питоном и не нравится сильно эта неоднородность.
Отличный ответ, поддерживаю.
Согласен с автором, я за табы (в 4 пробела)
Я обычно пишу с табами. Правда, когда пишу на Pascal/Delphi или там, где нельзя воспользоваться табуляцией (например, в полях ввода на сайтах типа codepad), то ставлю два пробела.
В целом — согласен, но по-моему есть еще вариант твердо прописать правила расстановки табов/пробелов в стандартах кодирования языка.
Например, для PHP есть стандарт Zend/PEAR, где регламентируется ставить 4 пробела вместо табов для отступов — но хорошо, если его придерживается хотя бы 10% разработчиков. Поэтому я для PHP отступы предпочитаю делать табами.
Другое дело — Ruby, где за стандарт принято делать отступы двумя пробелами (и, кстати, самого стандарта я не читал — но сразу это понял по исходникам множества библиотек). И код, который не следует этому правилу выглядит просто чужеродно — я даже подозреваю, что такие библиотеки использовать почти никто не будет. Или будут, но только после того, как переделают табы в пробелы :)
P.S. Кстати, есть аналогичная статья от Дмитрия Котерова (широко известного в узких кругах PHP и JavaScript-гуру).
Например, для PHP есть стандарт Zend/PEAR, где регламентируется ставить 4 пробела вместо табов для отступов — но хорошо, если его придерживается хотя бы 10% разработчиков. Поэтому я для PHP отступы предпочитаю делать табами.
Другое дело — Ruby, где за стандарт принято делать отступы двумя пробелами (и, кстати, самого стандарта я не читал — но сразу это понял по исходникам множества библиотек). И код, который не следует этому правилу выглядит просто чужеродно — я даже подозреваю, что такие библиотеки использовать почти никто не будет. Или будут, но только после того, как переделают табы в пробелы :)
P.S. Кстати, есть аналогичная статья от Дмитрия Котерова (широко известного в узких кругах PHP и JavaScript-гуру).
Ну так для Си существует штук 10 стандартов, и во всех свои требования. Каждая крупная корпорация пытается навязать свой стиль. Взять даже код в стиле исходников Microsoft и сравнить его с кодом в стиле исходников Linux — разница на лицо. т.к. что это дела не стандарта, а их большого кол-ва
Так же, как и для PHP, собственно. Но это уже проблема самого языка — значит, не смогли/не захотели принять единый стандарт кодирования.
В Java, Python, и Ruby этой проблемы не существует — за игнорирование стандартов, как тут уже сказали, можно получить молотком по пальцам. :)
В Java, Python, и Ruby этой проблемы не существует — за игнорирование стандартов, как тут уже сказали, можно получить молотком по пальцам. :)
А причем тут JS? В нем также как и в других языках. Всё зависит от опыта(как показывает практика новички всё в одну строку пишут) и пристрастия к определенному оформлению. Если человек много пишет на к примеру на С/С++ с использованием определенного стиля оформления, то он и на JS будет использовать этот же стиль (т.е. ему это будет проще чем перестраиваться от языка к языку).
Ведь много людей, особенно на просторах бывшего ссср, в силу сложившихся обстоятельств занимаются одновременно разного вида работами и используют разные языки, и в таком случае использовать для каждого языка какой-то особенный стиль (рекомендуемый для данного языка) будет очень не удобно.
Ведь много людей, особенно на просторах бывшего ссср, в силу сложившихся обстоятельств занимаются одновременно разного вида работами и используют разные языки, и в таком случае использовать для каждого языка какой-то особенный стиль (рекомендуемый для данного языка) будет очень не удобно.
Так я говорил не про JS, а про Java :)
С JavaScript, увы, все не так радужно — возможно, есть стандарт кодирования ECMA, но если даже он есть — то его судя по всему мало кто придерживается.
Согласен, вполне возможно. Но лично я такой проблемы не вижу — пишу одновременно на Руби, Питоне, и PHP — и везде стараюсь соблюдать стандарты.
С JavaScript, увы, все не так радужно — возможно, есть стандарт кодирования ECMA, но если даже он есть — то его судя по всему мало кто придерживается.
в таком случае использовать для каждого языка какой-то особенный стиль (рекомендуемый для данного языка) будет очень не удобно.
Согласен, вполне возможно. Но лично я такой проблемы не вижу — пишу одновременно на Руби, Питоне, и PHP — и везде стараюсь соблюдать стандарты.
Юмор в том, что у того же Microsoft еще позиция относительно стандартов кодирования менялась диаметрально, насколько я помню, раза 3-4 уже…
Если напишите полезную библиотеку — будут и с табами использовать.
Из опыта, когда начинал только разработки свои, использовал пробелы… В итоге я проклял пробелы, в тот день когда узнал про табы.
Я хочу писать код, блеать, а не думать о пробелах и табуляциях! А то тут всякие несознательные товарищи уже наганом размахивают, за случайно поставленную парочку пробелов.
Правильно размахиваем. Ибо из-за вашей случайной пары пробелов пидорасит форматирование и код выглядит так, что кровавые слёзы из глаз текут.
Меньше красок, мон шер. Иногда идет «поток мысли кода» и тут совсем не хочется думать о правильном оформлении оного. Нет, я не раздолбай и в таких случаях на 95% правильное форматирование все же осуществляю, а на допущенные пробелы можно и потом проверить.
Не будем обобщать
Вот как Вам объяснить, почему не будем? Потому что я пишу код очень давно, всякое было, делал разные выводы и, надеюсь, могу себя считать опытным программистом. И говоря о потоках мыслей я подразумевал адекватный поток мыслей, когда продуманы все детали, потому как для меня по-другому просто невозможно. И Ваш коммент, как следствие, довольно обиден.
Иногда идет «поток мысли кода» и тут совсем не хочется думать о правильном оформлении оного.
Тут та же проблема, что и с грамотностью — есть ведь такая отмазка как «торопился и не думал об ошибках». :) Но грамотные люди пишут грамотно всегда, вне зависимости от того, торопятся они или нет.
Тут то же самое — писать код нужно всегда правильно и по принятому в языке/компании/проекте стандарту.
Заметьте, я не отмазываюсь, и пишу правильно всегда по мере своих сил, Вы вот, например, никогда не совершаете ошибок? Я же говорю о том, что ошибки — это естественно, но да, их надо исправлять. Только без этого фанатизма с кровавыми словами.
Согласен с вами — именно про это и говорю — ошибки надо стараться исправлять, без фанатизма. Но никак не в открытую на них забивать, да еще и гордиться этим (что уже является другой крайностью).
Ну и я говорил не про вас, а про людей, которые руководствуются принципом «всеравно пешу быстра, пра стондарты и грамматнасть можна ващще не думать» (согласитесь, такое читать не особо приятно? :) Вот по-моему то же самое и с кодом).
Ну и я говорил не про вас, а про людей, которые руководствуются принципом «всеравно пешу быстра, пра стондарты и грамматнасть можна ващще не думать» (согласитесь, такое читать не особо приятно? :) Вот по-моему то же самое и с кодом).
На этапе написания или отладки да можно отступить от красивого форматирования. Но написал блок — отладил — привел в порядок форматирование.
>Иногда идет «поток мысли кода» и тут совсем не хочется думать о правильном оформлении оного.
А на хрена об этом думать? Выставил настройки редактора — и пусть код хлещет хоть потоком, хоть водопадом.
А на хрена об этом думать? Выставил настройки редактора — и пусть код хлещет хоть потоком, хоть водопадом.
Спаси (ctrl+f) и сохрани (ctrl+s) нас от этого! :)
PHP_Beautifier привязаный к той системе контроля версий, которую вы используете должен улучшить ситуацию с Вашими глазами, ИМХО
Ура, какое единство мысли и общественное порицание! Что за люди, за выражение собственного мнения, насрать в карму, как будто это я тот злой человек, который пишет все в мире библиотеки с пробельными отступами.
Этот топик — обычный холивар, где слепо кричат: «даешь табуляцую!» и лишь изредка слышаться возгласы, что это не универсальный совет, как бы вам того ни хотелось.
Поверьте, я далеко не новичок в программировании, я занимаюсь этим делом уже 11 лет и могу показать примеры своего кода, там не то что вы, там комар носа не подточит. Я работаю в команде не первый год и понимаю, как это плохо делать что-то под себя не думая о других. Там может не будем хаять налево и направо?
Возможно, мои фразы кажутся разлагающими для новичков, которые могут увидеть за ними призыв к расхлябанности, но я все же надеялся, что уровень хабра много выше и люди понимают, что надо относиться к подобным советам осторожно, но и не отрицать однозначно.
Этот топик — обычный холивар, где слепо кричат: «даешь табуляцую!» и лишь изредка слышаться возгласы, что это не универсальный совет, как бы вам того ни хотелось.
Поверьте, я далеко не новичок в программировании, я занимаюсь этим делом уже 11 лет и могу показать примеры своего кода, там не то что вы, там комар носа не подточит. Я работаю в команде не первый год и понимаю, как это плохо делать что-то под себя не думая о других. Там может не будем хаять налево и направо?
Возможно, мои фразы кажутся разлагающими для новичков, которые могут увидеть за ними призыв к расхлябанности, но я все же надеялся, что уровень хабра много выше и люди понимают, что надо относиться к подобным советам осторожно, но и не отрицать однозначно.
>Этот топик — обычный холивар, где слепо кричат: «даешь табуляцую!»
Слепо? А по-моему автор всё разложил по полочкам, заранее ответив на любое возможное возражение. Вы сам топик-то читали, или только заголовок? ;)
Слепо? А по-моему автор всё разложил по полочкам, заранее ответив на любое возможное возражение. Вы сам топик-то читали, или только заголовок? ;)
Я не из тех кто комментит не прочитав. А автор может разложить хоть по ящичкам, Вы сами то комменты читали, где приводят иные аргументы?
Комментариев со «слепыми» выкриками полно с обеих сторон, поэтому не нужно акцентировать на криках «даёшь табы!» — среди сторонников другого лагеря их тоже достаточно.
Однако позиция «отступы табами» в топике изложена достаточно аргументировано (в отличие от позиции «отступы пробелами» из предыдущего топика).
Однако позиция «отступы табами» в топике изложена достаточно аргументировано (в отличие от позиции «отступы пробелами» из предыдущего топика).
Если вы пишете код для себя, то хоть лесенкой форматируйте. Но если код будет читать кто-то другой, то он хочет код читать, блеать, а не выносить себе мозг, угадывая границы блоков.
Бывает кто для проекта приходится использовать код, который написан другими людьми с использованием пробелов. Тогда просто убивает то, что если начинаешь править код (в частности добавлять/удалять строки) т.к. замучаешься удалять кучу пробелом перед текстом (особенно большой вложенности).
Сам пользуюсь табами, но бывают случае что только пробелы спасают. К примеру: код построен с использованием табов и его надо показать кому-нибудь через сервис в стиле pastebin, то код с вложенность 5 и выше ужа начинает уходить за рамки т.к. сервис использует табы размером 8 пробелов.
Сам пользуюсь табами, но бывают случае что только пробелы спасают. К примеру: код построен с использованием табов и его надо показать кому-нибудь через сервис в стиле pastebin, то код с вложенность 5 и выше ужа начинает уходить за рамки т.к. сервис использует табы размером 8 пробелов.
А причем тут текстовый редактор? Ели имеете в виду про правку кода, то кто его знает что использовал человек при написании кода, а для правки не всегда под рукой есть IDE или редакторы, бывает и notepad'ом приходится пользоваться. А если имеете в кривость редактора при копировании в pastebin, то код берется из Visual Studio или Code::Blocks, зависит от обстоятельств. Так что не наго писать херню.
ответ был о «замучаешься удалять кучу пробелом перед текстом». Каждый цивилизованный редактор позволяет сделать это за 2-3 клика/нажатия клавиш. Если у вас не так — или таки редактор — дурак, или вы недоразобрались в его использовании
>Ели имеете в виду про правку кода, то кто его знает что использовал человек при написании кода
Очень многие редакторы умеют это:
Очень многие редакторы умеют это:

Настройка размера табуляции есть не во всех редакторах, имею введу именно редакторы а не IDE
А я за Кена Арнольда «Стиль есть содержание»
fktrc.livejournal.com/630.html
Не только в отношении пробелов/табов, но и в прочем.
fktrc.livejournal.com/630.html
Не только в отношении пробелов/табов, но и в прочем.
Кажется я начинаю понимать, откуда такое моё несогласие с миром. Я в основном работал и работаю с унаследованным кодом. И мне совершенно не интересны теоретические и идеологические обоснования почему табы лучше. Я практик. Когда я беру код и вижу, что он разъехался, так по мне пробелы в 100 раз лучше. Никто никогда не заворачивается, что такое indentation, alignment. Просто 5-10 лет назад натабили и пошли дальше.
И Вас даже не подкупил тот факт, что на картинке в посте логотип PVS-Studio? :)
Кажется я начинаю понимать, откуда такое моё несогласие с миром.
Ваше несогласие с миром заключается в том, что «много слов — мало дела». Вот давайте посмотрим этот ваш комментарий. Никакого смысла, никаких аргументов, одни эмоции. Сначала выставили себя «борцом против мира», этакий герой.
И мне совершенно не интересны теоретические и идеологические обоснования почему табы лучше. Я практик.
Все мы практики. Но своим сообщением вы всех, кто использует табы обвинили в отсутсвии практики. Без веских оснований.
Когда я беру код и вижу, что он разъехался, так по мне пробелы в 100 раз лучше.
Опять же, никаких аргументов, можно заменить «пробелы» на «табы» и получится ровно тот же смысл:
Когда я беру код и вижу, что он разъехался, так по мне табы в 100 раз лучше.
Дело не в табах и не в пробелах, дело в профессионализме, отступы у новичка поедут что там что там.
Никто никогда не заворачивается, что такое indentation, alignment.
Аналогично. Пустой набор слов. Начнём с того, что он в корне неверен, так как ваше «Никто никогда» уже опровергает мой пример. Ну и даже если бы он был верен, то такое было бы применимо что к табам, что к пробелам.
Просто 5-10 лет назад натабили и пошли дальше.
Это вообще ни к селу ни к городу. «В огороде бузина, а в Киеве — дядька».
Просто у вас поток эмоций, мало информации и аргументов, потому многие люди вас не восприняли.
И еще — вы не поняли основную идею топика.
Начнём с того, что большинство людей (по крайней мере на Хабре) предпочитают табы.
средняя температура по больнице?
А еще дополнительно у пробелов есть такие недостатки, как невозможность быстрого перемещения стрелочками клавиатуры (щёлкает каждый пробел, а не через блок), возможность допустить ошибку (поставить в одном месте 3 пробела вместо 4, чем порушить дальнейшую структуру), увеличение размера файла и куча всего ещё.
Да ну? Вы какой IDE пользуетесь? У меня даже gedit с включенным умным отступом по пробелам в identation быстро переходит. Так же как и умеет если что кусок кода на n пробелов вправо-влево сдвинуть.
ИМХО вы привели единственный (впрочем, объективный) аргумент — возможность настроить отображение табуляции в любое кол-во пробелов. Только расписали в несколько параграфов разными словами.
Я лично вообще ни за то, ни за то. Когда пишу на PHP и C++ отбиваю табом. Когда пишу на Ruby, отбиваю пробелами. Зачем этот топик? Хабр недовыполняет недельную норму холиворов?
также поясню по поводу средней температуры по больнице: мне тот опрос по ссылке напоминает статью о статистике матов в комментариях к коммитам на гитхабе по языкам. На первом месте по количеству стоял Ruby, который занимает где-то половину всего гитхаба, потому и количество большое. По части того опроса: очевидно, что на хабре представители некоторых языков и технологий представлены в меньшем количестве, чем других (при чём часто не из-за статистически меньшего количества этих самых представителей, а из-за сепцифики технологий). В числе прочего, очевидно, что рубиистов (у которых в стандарте де-факто пробелы в отбивке) на хабре представлено меньше, чем любителей PHP, C++, whatever (где используют в основном табы). Потому и опрос этот мало о чём говорит.
Это статистическая выборка, 600 человек — вполне репрезентативно.
Она говорит, что людей, которые предпочитают табы на Хабре больше.
Какие этому причины — другой вопрос. Если появится язык, в котором отступы можно будет отбивать при помощи и все три его пользователя будут пользоваться именно этой возможностью, это не значит, что статистика — неверная.
Она говорит, что людей, которые предпочитают табы на Хабре больше.
Какие этому причины — другой вопрос. Если появится язык, в котором отступы можно будет отбивать при помощи и все три его пользователя будут пользоваться именно этой возможностью, это не значит, что статистика — неверная.
ок. по вашей логике, C++ — самый лучший язык среди существующих, потому что на нём больше всех кодят?
То есть по вашей логиге, С++ — самый худший язык среди существующих, потому что на нём больше всех кодят?
Я просто не понимаю, зачем мне приписывать то, чего я не говорил. Я сказал, что «людей, которые предпочитают табы на Хабре больше». Где тут что-то про качество языка?
Я просто не понимаю, зачем мне приписывать то, чего я не говорил. Я сказал, что «людей, которые предпочитают табы на Хабре больше». Где тут что-то про качество языка?
вы используете количество проголосовавших за табы как аргумент о том, что они лучше. отсюда я и сделал этот саркастичный вывод.
Демагогия — Подмена тезиса.
Я не понимаю, зачем вы используете эти грязные приёмы ведения дискуссии, они вас не красят.
Нет, я привожу результаты опроса с выводом о том, что большинство людей предпочитает табы. Я нигде не сказал, что это как-то влияет на их качество.
Я не понимаю, зачем вы используете эти грязные приёмы ведения дискуссии, они вас не красят.
вы используете количество проголосовавших за табы как аргумент о том, что они лучше
Нет, я привожу результаты опроса с выводом о том, что большинство людей предпочитает табы. Я нигде не сказал, что это как-то влияет на их качество.
и кстати, грязные приёмы ведения дискуссии в данном случае у вас. на лицо и применение подмены тезиса (то, что вы явно не написали, что большинство за табы — аргумент, не значит, что это не читается в статье), так же как и обвинение в применении этих приёмов заранее, чтобы в этом не могли обвинить вас.
если серьёзно, оспорьте моё следующее мнение: табы хороши тогда, когда код не выходит за пределы команды/компании. в этом случае просто можно договориться с коллегами о том, какого размера табы и т.п., если код выводится в open source (и тем более выкладывается в online-отображалки, к примеру гитхаб), пробелы в этом случае де-факто.
а по части статистики, мне что-то подсказывает, что на хабре (да и в принципе) большая часть кода остаётся проприетарной. потому и табами большее кол-во человек пользуется. но это всё равно не аргумент за то, что табы чем-то принципиально лучше пробелов. как и наоборот.
а по части статистики, мне что-то подсказывает, что на хабре (да и в принципе) большая часть кода остаётся проприетарной. потому и табами большее кол-во человек пользуется. но это всё равно не аргумент за то, что табы чем-то принципиально лучше пробелов. как и наоборот.
Нет, табы хороши всегда, табы могут быть любого размера, почитайте топик-ответ.
я уже привёл свои аргументы против пропоганды табов выше, не получив на них ни одного ответа, только минусы. посему отступлю от этого спора, т.к. потерял надежду на вразумительный ответ. даже в этом вашем комментарии не было объяснения, почему моя точка зрения, по-вашему, неверна.
У вас в сообщении явно прослеживается, что если вы и читали топик, то невнимательно. В часности, следующее заявление указывает на это:
Я писал об этом в топике и назовите мне хотя бы одну причину повторятся об этом в комментариях, если это уже написано в топике?
просто можно договориться с коллегами о том, какого размера табы и т.п.
Я писал об этом в топике и назовите мне хотя бы одну причину повторятся об этом в комментариях, если это уже написано в топике?
И только лисперы смотрят на холивар с непониманием. :) Код форматируется как дерево и табуляция фиксированной ширины не имеет никакого смысла.
По опыту с другими языками могу сказать что пробелы-табы — разницы никакой. Главное правильно настроить редактор и убедиться что в коде используются либо только пробелы либо только табы. Козёл может и в том и в другом огороде наследить.
По опыту с другими языками могу сказать что пробелы-табы — разницы никакой. Главное правильно настроить редактор и убедиться что в коде используются либо только пробелы либо только табы. Козёл может и в том и в другом огороде наследить.
Ну слава богу. Вы понимающий. :)
А мне правктически всегда приходится равнять код за пробельщиками. Уровни вложения у них очень часто плывут. В HTML, например, это часто влечёт за собой лишние закрытые теги, или незакрытые.
Не сомневайтесь в моем опыте, я скоро буду о таком рассказывать. Отступы — это не самое страшное, т.к. иде всё с легкостью перевела с «рендомного количества пробелов и табов в начале строки» в табы)
Вы просто никогда не писали для open-source проекта и не пытались потом свой код с табами посмотреть в online. Когда перелез на github, то все сконвертил в пробелы и с тех пор даже не думаю об этом.
Я не одинок! Я не одинок! Где вы были, когда меня сейчас били. ;)
а что не так с табами и гитхабом?
Ну вот и решена центральная проблема современного софтостроения!

Спасибо за подсказку про разделение indentation и alignment! Всё сразу встает на свои места.
Ответ я увидел, но к примеру автор предыдущего топика показал пример где идет таб, затем текст, затем таб, затем опять текст и вот подобные конструкции очень порядочно разъежаются при изменении размера таба.
Включите отображение табов/пробелов, иногда меняйте размер табуляции на другой и пробегайте глазами код, чтобы удостоверится, что у вас где-то не вставились пробелы вместо табов или табы вместо пробелов.Это, кстати, важно, что табы приходится проверять. С пробелами код всегда выглядит именно так, как есть на самом деле.
Только когда пишу на Python intendation делаю пробелами, только потому что PEP8 :(
Java/JS/etc — табы, если, конечно до этого они и были. Бывало попадался код вперемешку — вот за такое точно надо казнить.
Полностью согласен с автором, дико неудобно читать\править код, где недостаточные отступы у блоков или наоборот, табуляции всегда можно «подкрутить» под себя.
Java/JS/etc — табы, если, конечно до этого они и были. Бывало попадался код вперемешку — вот за такое точно надо казнить.
Полностью согласен с автором, дико неудобно читать\править код, где недостаточные отступы у блоков или наоборот, табуляции всегда можно «подкрутить» под себя.

По табу вставляется нужное количество пробелов, всегда устраивало)
Кстати, назрел такой вопрос. Есть небольшой php-скрипт, выводящий какую-то инфу в html.
Но одновременно хочется сделать нормальное форматирование готового html, т.е. получается что-то такое:
Получаем нечитабельный php :(
Как быть, когда хочется везде сохранить форматирование? Пытаться избегать таких случаев вообще?
ЗЫ Я только учусь, поэтому такой код у меня встречается сплошь и рядом.
function qwerty(){
for(...){
if(...){
$result = '<div><span>blablabla</span></div>';
}
}
}Но одновременно хочется сделать нормальное форматирование готового html, т.е. получается что-то такое:
function qwerty(){
for(...){
if(...){
$result = '<div>
<span>
blablabla
</span>
</div>
';
}
}
}
* This source code was highlighted with Source Code Highlighter.Получаем нечитабельный php :(
Как быть, когда хочется везде сохранить форматирование? Пытаться избегать таких случаев вообще?
ЗЫ Я только учусь, поэтому такой код у меня встречается сплошь и рядом.
использовать шаблонизатор?
с двойными кавычками ситуация не лучше, т.к. получается что-то вроде
$result = "<div>\r\n\t<span>\r\n\t\tblablabla\r\n\t</span>\r\n</div>\r\n";Используйте heredoc, а лучше — шаблонизатор.
Промазал, ответил ниже.
В вашем случае ответ таков: не надо смешивать логику с отображением
$result = "" +
"<div>" +
" <span>" +
" blablabla" +
" </span>" +
"</div>";
Но лучше использовать шаблонизатор
Вариантов масса. Но лучше MVC — дизайнер спасибо скажет.
function qwerty(){
for(...){
if(...){
$result = \
'<div>
<span>
blablabla
</span>
</div>';
}
}
}
с какой стати надо завязывать с пробелами только от того что где то есть опция для визуализации табов? мне не нравится смесь табов с пробелами а смесь неизбежна… для себя мы просто сделали регламент в котором сказано «никаких табов» и прошлись по исходникам indent-ом.
Ура. Еще один в мою пользу. :)
А с какой стати надо избегать использования для идентации специально придуманного для этой цели символа? Вы часто суп вилкой едите?
спорить не хочу, меня устраивает специально придуманная кнопка Tab, она вставляет столько пробелов сколько мне нужно, кнопка BS удаляет столько сколько нужно (как будто там был tab)…
иногда я пользуюсь утилитой indent на коде который мне надо отъиндентить в соответствии с нашим регламентом.
В любом случае ни вы не я вам не смогу ничего доказать, так что давайте перейдём непосредственно к оскорблениям… чего уж там…
иногда я пользуюсь утилитой indent на коде который мне надо отъиндентить в соответствии с нашим регламентом.
В любом случае ни вы не я вам не смогу ничего доказать, так что давайте перейдём непосредственно к оскорблениям… чего уж там…
M-x indent-region
M-x untabify
M-x delete-trailing-whitespaces
И так будет с каждым. ;)
M-x untabify
M-x delete-trailing-whitespaces
И так будет с каждым. ;)
Почему-то автор забыл про языки, в которых indentation это не просто способ оформления кода, это часть стандарта языка. Помимо упоминавшегося уже здесь Python хочу напомнить о существовании Haskell, в котором «форматирование» табами надолго может затянуть в поиск ошибки, которой не видно на глаз.
Лично я за пробелы. Хотя бы просто потому, что величина отступа, на мой взгляд, наименьшая из проблем с переходом на новый «стандарт» форматирования, с которой может столкнуться программист в новом коллективе. Например, для Java различия между
и
для меня куда большая проблема с читабельностью, чем эти ваши табы.
Лично я за пробелы. Хотя бы просто потому, что величина отступа, на мой взгляд, наименьшая из проблем с переходом на новый «стандарт» форматирования, с которой может столкнуться программист в новом коллективе. Например, для Java различия между
public class Foo {
public void foo() {
return 0;
}
}
и
public class Foo
{
public void foo()
{
return 0;
}
}
для меня куда большая проблема с читабельностью, чем эти ваши табы.
Целиком и полностью поддерживаю TheShock!
Никаких проблем при использовании табов для indent'а и пробелов для выравнивания внутри строки. Размер таба каждый программист может настроить под себя сам, как ему удобно. В чем проблема у людей, которые «кричат» об использовании пробелов в качестве символов для отступа? Они хоть раз большие объемы текста форматировали для удобного чтения и работы с ним?
Но, как говорится: «На вкус и цвет — все фломастеры разные!» (с) услышал от друга, а первичного автора не знаю
Никаких проблем при использовании табов для indent'а и пробелов для выравнивания внутри строки. Размер таба каждый программист может настроить под себя сам, как ему удобно. В чем проблема у людей, которые «кричат» об использовании пробелов в качестве символов для отступа? Они хоть раз большие объемы текста форматировали для удобного чтения и работы с ним?
Но, как говорится: «На вкус и цвет — все фломастеры разные!» (с) услышал от друга, а первичного автора не знаю
Да пожалуйста:
Табами надо уметь пользоваться. Как заметил автор, что-то можно сделать табами, что-то пробелами. Идент надо делать табами, алайн пробелами, но откуда об этом знает Вася Пупкин? Он будет херачить табами внутри кода чтобы сделать «красивенько» (кстати в питоне делать так нельзя), а программист всегда пишет код для другого программиста. Всегда.
Если использовать пробелы, то точно знаешь — все отступы это пробелы. Табы же не видны глазом — сиди потом выковыривай.
Табами надо уметь пользоваться. Как заметил автор, что-то можно сделать табами, что-то пробелами. Идент надо делать табами, алайн пробелами, но откуда об этом знает Вася Пупкин? Он будет херачить табами внутри кода чтобы сделать «красивенько» (кстати в питоне делать так нельзя), а программист всегда пишет код для другого программиста. Всегда.
Если использовать пробелы, то точно знаешь — все отступы это пробелы. Табы же не видны глазом — сиди потом выковыривай.
Если подходить к этому делу серьезно (а мы ведь о серьезных вещах говорим, правильно?), то в проекте обычно используется система контроля версий, для подавляющего большинства из которых есть (придуманы и описаны) предкомиитные хуки, на которые можно вешать авто-анализаторы стиля оформления исходного текста (настраиваемых).
Далее, обычно в закрытых проектах (опять же серьезных, о Васе Пупкине ни слова!), командой перед началом каких-либо работ по написанию кода, ставится серьезный вопрос о применяемых в данном проекте правил оформления.
Для open source проектов, в которые может писать пресловутый Вася, опять же можно использовать хуки, которые просто не позволят человеку закоммитить плохо оформленный код (плохой, но хорошо оформленный, конечно же позволят, тут уж не обесуддьте).
P.S. Ответ скорее не Вам лично, magic4x, а просто — общий взгляд на проблему с моей стороны.
P.P.S. Табы глазом не видны, да… Но зато хорошо прощупываются при наборе текста и перемещению по нему (так сказать — на ощупь).
Далее, обычно в закрытых проектах (опять же серьезных, о Васе Пупкине ни слова!), командой перед началом каких-либо работ по написанию кода, ставится серьезный вопрос о применяемых в данном проекте правил оформления.
Для open source проектов, в которые может писать пресловутый Вася, опять же можно использовать хуки, которые просто не позволят человеку закоммитить плохо оформленный код (плохой, но хорошо оформленный, конечно же позволят, тут уж не обесуддьте).
P.S. Ответ скорее не Вам лично, magic4x, а просто — общий взгляд на проблему с моей стороны.
P.P.S. Табы глазом не видны, да… Но зато хорошо прощупываются при наборе текста и перемещению по нему (так сказать — на ощупь).
В серьезных проектах есть гайдлайны/стандарты. В целом, когда вопрос заходит о серьезных проектах уже не важно кто и чем пользуется, важно что все пользуются одним и тем же.
Проблема как раз чаще всего встречается на «начальных» этапах развития разработчика. Ну и ходить стрелками туда-сюда тоже не хорошо, не будете же вы весь код проверять.
Проблема как раз чаще всего встречается на «начальных» этапах развития разработчика. Ну и ходить стрелками туда-сюда тоже не хорошо, не будете же вы весь код проверять.
Воистину!
Раньше использовала табуляцию, но с тех пор, как лет 5 назад стала использовать qwerty-смарт для правки исходников в дороге, перешла на 2 пробела :)
Поражаюсь способности устраивать холивар из любой мелочи! В команде — работаешь по командным стандартам, в одиночном режиме — так, как _тебе_ удобнее. Казалось бы, о чемм спорить…
Поражаюсь способности устраивать холивар из любой мелочи! В команде — работаешь по командным стандартам, в одиночном режиме — так, как _тебе_ удобнее. Казалось бы, о чемм спорить…
Табы-это круто. Это-обязательно. Любая древовидная структура — XML, функция и т.д. — то, что доктор прописал
Плюс недавно увидел как сделаны отступы в CSS типа
также сделанные табами.
Читается глазом просто великолепно, но на продакшене можно просто вырубать/сжимать
Плюс недавно увидел как сделаны отступы в CSS типа
section {
background: transparent;
font-size: 1.1em;
text-align: left;
height: 100%;
color: #545453;
}
также сделанные табами.
Читается глазом просто великолепно, но на продакшене можно просто вырубать/сжимать
особенно круто этот CSS смотрится, когда надо к примеру под такое background-color вставить. сидишь и как дурак отбиваешь правые части табами, т.к. количества табов не хватило.
Отличный пример, как не надо делать. Кто-то после вас меняет у себя длину таба на 3 символа, и всё превращается в кашу.
В статье же написано про alignment, и почему его нельзя делать табами. А вы тут же берёте и делаете, не слушая никаких аргументов.
В статье же написано про alignment, и почему его нельзя делать табами. А вы тут же берёте и делаете, не слушая никаких аргументов.
в статье как-раз говориться, что для этого не стоит использовать табы, т.к. стоит указать другой размер табуляции и все поедет.
Никуда ничего не поедет, потому что обычно в редакторах моноширинные шрифты
Поедет, непременно поедет. Чтобы стало ясно, почему поедет, достаточно заменить каждый таб видимой стрелочкою:
section {
→background:→transparent;
→font-size:→1.1em;
→text-align:→left;
→height:→→100%;
→color:→→#545453;
}section {
background: transparent;
font-size: 1.1em;
text-align: left;
height: 100%;
color: #545453;
}section {
background: transparent;
font-size: 1.1em;
text-align: left;
height: 100%;
color: #545453;
}Да успокоятся минусующие или нет? Такая штука хороша в презентационных целях, например, когда читаешь статью или учишь кого-то, кто будет пользоваться таким в работе? Да табы откидывать заколебешься — я же написал ЧИТАЕТСЯ ВЕЛИКОЛЕПНО
Отступы (то, что перед background, font-size) — можно делать пробелами, можно табами, выравнивание (то, что после двоеточия) для исходников лучше делать только пробелами.
tab в размером в 2 пробела:


статья супер. всю жизнь форматировал табами. жаль у меня на работе стандарт форматирования пробелами. никак не могу привыкнуть к этому…
Вот мне интересно, а саму статью кто-нибудь читает? Хотел бы попросить нашего милого автора разъясниться по поводу примеров с indentation, в частности 3-ей строки. Это важный момент, который как я понял ставится в ответ предыдущему топику и в нем прекрасно видно то, что все тут и автор в том числе осуждают, а именно смешивание пробелов и табуляций.
Когда делаете вложенность — используете табы, когда делаете выравнивание — пробелы.
То, что используется стиль с табами, не значит,
что теперь везде между переменными надо ставить табы вместо пробелов ;)Значит сложившиеся противоречие вас не смущает? Я прекрасно понимаю, что вы подразумеваете под вложенностью и под выравниванием. Но в конечном счете, в вышеприведенной ситуации человек видит просто _отступ_ в котором _намешаны_ и проблемы и табы. При чем, как там они намешены на самом деле, из листинга естественно не видно.
Совершенно. Табы задают уровень вложенности. Всё) Главное — знать это правило.
Я всегда включаю в редакторе кода отображение табов. И количество стрелочек (обычно так обозначается таб) глаз считает гораздо быстрее. Если включить отображение пробелов, то видать много точек, которые посчитать уже сложнее, и воспринимаются хуже.
Ребята, давайте я вас всех помирю :-). Andrey2008 разрабатывает анализатор кода PVS-Studio и вынужден просматривать большое количество сторонних исходников. И поэтому табы его затра… затрагивают его душу. Но и TheShock привел разумные аргументы. Просто это про две разных ситуации. Да и не знает большинство людей про отличие в отступах и выравниваниях.
Подожди мирить, попкорн еще не кончился =).
А вообще смешно — насколько же бывают эпичными баталии вокруг мелочей. Все время вспоминается Джонатан Свифт с его феерической враждой между тупоконечниками и остроконечниками.
Собственно проблема Andrey2008 — не пробелы или табы, а неорганизованность сторонних программистов и их исходников. Но была «придумана» ( поднята из недр всего и вся) причина этой проблемы — «во всем виноваты табы» и он начал эпохально и публично с ней сражаться. Это достаточно типично для большинствапрограммистов людей. Ну и до кучи решил изложить это в нравственно-поучительном стиле «дАртаньян против мира».
Результат не заставил себя ждать — инста-драма на почти 300+ комментариев. И не думаю что призыв к миру и объяснения ее хотя бы затормозят. Но имхо скоро ожидается прилет НЛО ;), главное чтобы авторов не выпилили — будет обидно.
PS: на всякий случай — я табоконечникфил, т.к.:
1. инструкция программиста в компании (кстати, у нас alignment строго запрещен, «декоративное оформительство» — зло)
2. умею настраивать рабочие инструменты ( не только IDE но и notepad++\notepad2)
3. видел оба подхода и выбрал для себя табы т.к. они настраиваемые, а пробелы нет.
PPS: извините за некоторый луркмоар — жду когда ребята оттуда допилят статью про хабр на тему этой драмы :)
А вообще смешно — насколько же бывают эпичными баталии вокруг мелочей. Все время вспоминается Джонатан Свифт с его феерической враждой между тупоконечниками и остроконечниками.
Собственно проблема Andrey2008 — не пробелы или табы, а неорганизованность сторонних программистов и их исходников. Но была «придумана» ( поднята из недр всего и вся) причина этой проблемы — «во всем виноваты табы» и он начал эпохально и публично с ней сражаться. Это достаточно типично для большинства
Результат не заставил себя ждать — инста-драма на почти 300+ комментариев. И не думаю что призыв к миру и объяснения ее хотя бы затормозят. Но имхо скоро ожидается прилет НЛО ;), главное чтобы авторов не выпилили — будет обидно.
PS: на всякий случай — я табо
1. инструкция программиста в компании (кстати, у нас alignment строго запрещен, «декоративное оформительство» — зло)
2. умею настраивать рабочие инструменты ( не только IDE но и notepad++\notepad2)
3. видел оба подхода и выбрал для себя табы т.к. они настраиваемые, а пробелы нет.
PPS: извините за некоторый луркмоар — жду когда ребята оттуда допилят статью про хабр на тему этой драмы :)
кстати, у нас alignment строго запрещен, «декоративное оформительство» — зло
Ну хоть кто то озвучил эту прекрасную мысль.
Целый холивар развели, а все изза этого гребанного alignment. Всем холиварщикам советую почитать что думает по этому поводу Макконел.
Вот например:
$sample = array(
'dbSettings' => array(
'type' => 'mysql',
'host' => '127.0.0.1',
'password' => '',
'user' => 'root',
'port' => '',
'andSomeLongKey'=> 'foo',
),
'route' => array (
...
),
);
а теперь представьте что вам надо в подмассив 'dbSettings' добавить еще один параметр с очень длинным названием. Вам после этого придется пробежаться по остальным и доофрмить их чтобы все стало ровненько по вертикали. Такие казалось бы мелочи раздражают сильно, а вот читабельность от таких выкрутасов повышается незначительно. Мне например больше по душе вариант такой:
$sample = array(
'db' => array(
'type' => 'mysql',
'host' => '127.0.0.1',
'password' => '',
'user' => 'root',
'port' => '',
'andSomeLongKey' => 'foo',
),
'route' => array (
...
),
);
<.source>Есть вариант использовать «нестрогое выравнивание»:
Особо актуально в css-свойствах:
$sample = array(
'db' => array(
'type' => 'mysql',
'port' => '',
'config' => 'smth else',
'hostname' => '127.0.0.1',
'password' => '',
'username' => 'root',
'andSomeLongKey' => 'foo',
),
'route' => array (
...
),
);
Особо актуально в css-свойствах:
$('#element').css({
color : 'red',
width : 100,
height: 100,
backgroundColor: 'white',
borderRadius : 15
});
Хорошо выглядит когда порядок «ключей» не детерминирован, но в тех же стайл гайдах по CSS может быть указан порядок использования «ключей» (сначала координаты, потом размеры, потом цвета и т. п.) и тут «нестрогое выравнивание» уже не столь актуально, надо либо отказываться от него, либо использовать «строгое».
Всем холиварщикам советую почитать, что думает по этому поводу Макконел.Который? (Надеюсь, не Кэмпбелл Макконел, автор «Экономикс»? Потому что нельзя же принципы его экономической школы без раздумья прилагать ко программированию?)
хороший Вы пример выбрали — в нём столько идентификаторов одинаковой длины…
У нас в конторе принято любой код, перед тем как его пушить в репозиторий, приводить к принятому у нас общему виду. Он не всегда удобен и создан, скорее, не для удобства чтения кода, а для удобства сравнения версий.
Для этой цели имеется спец софт и скрипты для его описывающие форматирование.
Т.е. ни кто не парится по поводу пробелов/табов, стиля расстановки скобок…
каждый пишет как хочет, — всё-равно потом надо будет жмякнуть F12 и код преобразуется к единому стандарту.
Затем, по желанию, можно будет жмякнуть, например, F10 — и едино-стандартизированный код переформатируется в тот вид, который удобен лично мне.
Для этой цели имеется спец софт и скрипты для его описывающие форматирование.
Т.е. ни кто не парится по поводу пробелов/табов, стиля расстановки скобок…
каждый пишет как хочет, — всё-равно потом надо будет жмякнуть F12 и код преобразуется к единому стандарту.
Затем, по желанию, можно будет жмякнуть, например, F10 — и едино-стандартизированный код переформатируется в тот вид, который удобен лично мне.
А что это за софт, если не секрет? Свой проприетарный? Это же вещь будущего! Эх если бы настроечные скрипты представляли из себя куски кода. Тобишь форматируешь его как нравится и сохраняешь как свою настройку. Еще бы эту штуку впилить плагином к IDE… и открываешь любой код и видишь его в своём любимом форматировании, а при сохранении применяется форматирование, принятое в команде. Может начать opensource проект?
могу ошибаться, но кажется это называется
FmtPlus
это форматер SQL.
Но когда я баловался с Aptana находил похожие реализации (плагины) умеющие Ruby, Ruby on Rail, JS и css переформатировать по хот-кеям несколькими способами.
Аптана у меня не прижилась — перешёл на vim, так что даже название этого плагина я не упомню.
Сейчас сижу ищу подобное для Vim'а — уверен, что есть.
Плагин — это хорошо, но нужет обязательно скрипт — шоб повесить Хуком на пуш в репозиторий
FmtPlus
это форматер SQL.
Но когда я баловался с Aptana находил похожие реализации (плагины) умеющие Ruby, Ruby on Rail, JS и css переформатировать по хот-кеям несколькими способами.
Аптана у меня не прижилась — перешёл на vim, так что даже название этого плагина я не упомню.
Сейчас сижу ищу подобное для Vim'а — уверен, что есть.
Плагин — это хорошо, но нужет обязательно скрипт — шоб повесить Хуком на пуш в репозиторий
Насчет хука это уже второе применение этой софтины. Идея была в том, что даже сохраненный файл на диске (еще не закоммиченный) выглядит так как принято в команде, а во время просмотра/редактирования — выглядит так, как удобно конкретному программеру. Получается вещь непривязанная к контролю версий.
Вопрос в том, прийдется ли для изменения форматирования писать полноценный анализатор кода для ЯП… или можно обойтись малой кровью?
Вопрос в том, прийдется ли для изменения форматирования писать полноценный анализатор кода для ЯП… или можно обойтись малой кровью?
для vim'а
нашёл хороший форматер js:
www.vim.org/scripts/script.php?script_id=2727
думаю, что по его принципам можно написать подобное для других языков, если не получится найти.
нашёл хороший форматер js:
www.vim.org/scripts/script.php?script_id=2727
думаю, что по его принципам можно написать подобное для других языков, если не получится найти.
Первое можно делать и табами, и пробелами, но когда делаешь табами — каждый может подстроить ширину indent'а на свой вкус и ничего никуда не едет. А второе — строго пробелами.
Все равно не получится и рыбку съесть и… (ну вы знаете). Если отступы делать табами, а выравнивание пробелами, то, во-первых, задалбывает выравнивать пробелами, ибо в несколько раз больше нажатий на клавиши, во-вторых, есть соблазн жмакнуть таб по привычке, и тогда все поедет при другой ширине табов, ну и, конечно, то, что можно использовать в коде и то, и то (пусть и такими ясными оговорками) в реальной жизни скорее всего приведет к тому, что будет каша и табов и пробелов безо всякой системы.
Какая разница, что использовать? Любой вменяемый стандарт кодирования позволяет не думать о подобной ерунде.
Есть определенные стандарты кодирования, например для php наиболее популярные pear и zend, так вот в них принято использовать пробелы (4 шт) для отступа.
Для питона pep8 настоятельно рекомендует использовать пробелы.
И для ruby рекомендуется использовать 2 пробела (1, 2).
Для javascript Крокфорд рекомендует избегать использования табов.
Понятно что многое из этого просто рекомендации, каждый сам должен для себя решить что использовать, но лично для меня все эти люди и организации являются авторитетными и я свой выбор сделал.
Для питона pep8 настоятельно рекомендует использовать пробелы.
И для ruby рекомендуется использовать 2 пробела (1, 2).
Для javascript Крокфорд рекомендует избегать использования табов.
Понятно что многое из этого просто рекомендации, каждый сам должен для себя решить что использовать, но лично для меня все эти люди и организации являются авторитетными и я свой выбор сделал.
Крайне сомнительно.
В Python, например, пробелы рекомендованы, а в Ruby и вовсе почти обязательны — кроме советов создателей есть такой эффект — при вставке кода с табами в интерактивную консоль сработает автодополнение.
Это будут использовать и в других языках — перенастраивать IDE для разных языков хочется не всем.
Посоветовал бы автору не навязывать такие вещи и указывать область применения (к примеру, конкретные языки или среды разработки).
В Python, например, пробелы рекомендованы, а в Ruby и вовсе почти обязательны — кроме советов создателей есть такой эффект — при вставке кода с табами в интерактивную консоль сработает автодополнение.
Это будут использовать и в других языках — перенастраивать IDE для разных языков хочется не всем.
Посоветовал бы автору не навязывать такие вещи и указывать область применения (к примеру, конкретные языки или среды разработки).
Ваша аргументация разбивается о суровую реальность жизни. С пробелами все-таки проще настроить, поэтому легче добиться соблюдения такого стиля. А, как верно показано на рисунке выше, должен остаться только 1 стиль.
Обычно в стандартах прописывают максимальную длину строки (80 символов, например). Как этот вопрос решается в случае с табами, когда длина строки «плавающая»?
Это не в укор стандартам с табами, просто я не пользовался ими, а в тех что мельком видел, прописывалась ширина таба.
Это не в укор стандартам с табами, просто я не пользовался ими, а в тех что мельком видел, прописывалась ширина таба.
Чуваки, настройте уже один раз себе авто-форматтинг в своей любимой IDE и харе спорить! Я в упор не знаю что там у меня — табы или пробелы. У нас есть ответственный человек, который настроил всем в компании одинаковый авто-форматтинг — проблемы НЕТ ВООБЩЕ!
А когда коммитите в опен-сорс проект — тоже не знаете, какие отступы?
Для open-source проектов принято писать каким стандартом оформления кода пользуются разработчики и какие изменения в эти стандарты они внесли для своего удобства. Так как все нормальные IDE поддерживают per-project настройки, а также все грамотные разработчики указывают в комментариях к файлам настройки для vim, то проблем не возникает ни в случае использования IDE, ни в случае быстрых поправок/разработки через vim. Какие могут возникнуть проблемы и о чём спор — мне не ясно.
Из последнего с чем я работал с опен сорсом — это Android. К нему очень хорошо всё описано — source.android.com/source/code-style.html и по этой доке легко настраивается профиль для Eclipse. В итоге у меня есть два профиля — один корпоративный, который полностью соответствует Java coding conventions и второй для Android с их поправками. Авто-форматирование срабатывает при каждом сохранении, я в него кроме этих конвенций добавил только удаление пробелов в конце строк.
Из последнего с чем я работал с опен сорсом — это Android. К нему очень хорошо всё описано — source.android.com/source/code-style.html и по этой доке легко настраивается профиль для Eclipse. В итоге у меня есть два профиля — один корпоративный, который полностью соответствует Java coding conventions и второй для Android с их поправками. Авто-форматирование срабатывает при каждом сохранении, я в него кроме этих конвенций добавил только удаление пробелов в конце строк.
Спорим не подерётесь? =))
А вообще не мой взгляд, это одна из тех вещей которые должна за программиста решать среда разработки. А именно:
1) Должна быть возможность выбора что используется для выравнивания
2) Должна быть возможность автоматической расстановки отступов в каждом открываемом файле/по некой комбинации клавиш/просто по клавише Tab. В случае когда отступы расставляются автоматом для всех открываемых файлов проекта (именно текущего проекта, то бишь с фильтрами, например не расставляя отступы во всех внешних открываемых заголовочных, текстовых и прочих файлов), программист не должен даже замечать что «тут что-то не так...».
И собственно всё! Любой нормальный *diff и так разберётся что не нужно замечать изменений в табуляции, если это не питон. В этом плане считаю наиболее продвинутым Qt Creator
А вообще не мой взгляд, это одна из тех вещей которые должна за программиста решать среда разработки. А именно:
1) Должна быть возможность выбора что используется для выравнивания
2) Должна быть возможность автоматической расстановки отступов в каждом открываемом файле/по некой комбинации клавиш/просто по клавише Tab. В случае когда отступы расставляются автоматом для всех открываемых файлов проекта (именно текущего проекта, то бишь с фильтрами, например не расставляя отступы во всех внешних открываемых заголовочных, текстовых и прочих файлов), программист не должен даже замечать что «тут что-то не так...».
И собственно всё! Любой нормальный *diff и так разберётся что не нужно замечать изменений в табуляции, если это не питон. В этом плане считаю наиболее продвинутым Qt Creator
Всегда использую табы, однако во всех учебниках, что мне попадались, советуют использовать пробелы.
Табуляция круче пробелов тем, что для отступов быстрее нажать один раз Таб, чем два или четыре раза пробел. И, соответственно, один бэкспейс быстрее нескольких.
Жду аргументов, господа минусующие.
не минусующий, но смените редактор на тот который умеет smart tab, smart backspace… 21-й век уже наступил…
В теории я за табы. По одной простой причине: отступы (обоих типов) в исходниках пробелами… это всё равно что выравнивание пробелами в .doc-файлах. Полная путаница между разными уровнями абстракции, между формой и содержанием, между view и model.
Отступы (обоих типов) — это чисто проблема view, вводимые для этого символы — model, и вводить символы пробела, которые служат для разделения слов, но, в случае, если используется шрифт, у которого почему-то все символы имеют одинаковую ширину, в качестве сайд-эффекта от своего добавления позволяют делать отступы требуемой ширины, для отступов — это глупо и некрасиво.
Всё это форматирование пробелами полетит при смене шрифта на намного более читабельный пропорциональные. Скажу даже больше: уродливые моноширинные шрифты на данный момент требуются едва ли не исключительно из-за выравнивания пробелами. Люди, на дворе 21-ый век, после DOS-ового Лексикона уже вышло штук пятнадцать поколений Word-ов, а потом и опенофисы/гуглдоки, а вы до сих пор используете моноширинные шрифты!
На практике я, к сожалению, за пробелы. Потому что я пишу на языках, где активно использую и indentation, и alignment. При этом alignment с помощью tab-ов тоже можно было бы сделать, и это было бы достаточно красиво (разумеется, даже с пропорциональными шрифтами), но… пока ни одного IDE/редактора с возможностями tab-based alignment нет.
Отступы (обоих типов) — это чисто проблема view, вводимые для этого символы — model, и вводить символы пробела, которые служат для разделения слов, но, в случае, если используется шрифт, у которого почему-то все символы имеют одинаковую ширину, в качестве сайд-эффекта от своего добавления позволяют делать отступы требуемой ширины, для отступов — это глупо и некрасиво.
Всё это форматирование пробелами полетит при смене шрифта на намного более читабельный пропорциональные. Скажу даже больше: уродливые моноширинные шрифты на данный момент требуются едва ли не исключительно из-за выравнивания пробелами. Люди, на дворе 21-ый век, после DOS-ового Лексикона уже вышло штук пятнадцать поколений Word-ов, а потом и опенофисы/гуглдоки, а вы до сих пор используете моноширинные шрифты!
На практике я, к сожалению, за пробелы. Потому что я пишу на языках, где активно использую и indentation, и alignment. При этом alignment с помощью tab-ов тоже можно было бы сделать, и это было бы достаточно красиво (разумеется, даже с пропорциональными шрифтами), но… пока ни одного IDE/редактора с возможностями tab-based alignment нет.
>пока ни одного IDE/редактора с возможностями tab-based alignment нет
Мало того, для активного использования tab-based alignment нужно, чтобы если не все, то хотя бы подавляющее большинство IDE/редакторов их использовало.
Мало того, для активного использования tab-based alignment нужно, чтобы если не все, то хотя бы подавляющее большинство IDE/редакторов их использовало.
alignment вообще считаю бессмысленным украшательством. добавил что-то длинное — и сидишь выравниваешь 33 строчки, зачем?
Не могу полностью согласиться. То, что все символы шрифта имеют одинаковую ширину — это не «почему-то вдруг», это абсолютно осознанное решение, применяемое во всех известным мне средах разработки и всех книгах по программированию, обеспечивающее одинаково удобную читаемость как для любителей табов, так и для любителей пробелов. Если для обычного литературного текста пропорциональный шрифт удобнее, то для кода, наоборот, удобнее моноширинный, и Dos'овый Лексикон тут не при чем.
То, что все символы шрифта имеют одинаковую ширину — это не «почему-то вдруг», это абсолютно осознанное решение, применяемое во всех известным мне средах разработки и всех книгах по программированию, обеспечивающее одинаково удобную читаемость как для любителей табов, так и для любителей пробелов.
Угу, именно. Прочитайте своё предложение ещё раз, убирая всё лишнее: моноширинные шрифты — это решение, обеспечивающее одинаково хорошую читаемость и при tab-based, и при space-based. А теперь ещё раз: моноширинные шрифты — это решение проблемы выравнивания при tab vs spaces. Правда, при грамотном использовании tab этой проблемы нет, так что…
Иначе говоря, итог: моноширинные шрифты нужны для space-based alignment/indentation. ASCII-арта. В 21-ом веке, угу.
При грамотном использовании пробелов проблемы тоже нет :) Так что спор перетекает из «что лучше» в «с чем могут сильнее напортачить идиоты».
И чем вам не нравится ASCII-арт? Судя по тому, что во всех средах разработки по умолчанию стоит моноширинный шрифт, даже в самых навороченных и современных, ему все-таки есть место в 21 веке, и весьма значительное.
И чем вам не нравится ASCII-арт? Судя по тому, что во всех средах разработки по умолчанию стоит моноширинный шрифт, даже в самых навороченных и современных, ему все-таки есть место в 21 веке, и весьма значительное.
Вы помните, с чего началось обсуждение? 27-го апреля 2011-го года TheShock запустил на Хабрахабре очередную итерацию спора tab vs spaces.
Двадцать седьмого апреля две тысячи одиннадцатого года.
У экрана моего ноутбука 145 DPI, у современных планшеток и мобильников может быть и ещё больше. Монитор с экраном размером 1920x1080 пикселей стал чем-то вполне обыденным, и стали распространяться разрешения и выше. Аппаратную текстовую консоль лично я вижу только при загрузке линукса да при редких (с последними обновлениями иксов и драйвера Intel в Дебиане — почему-то частых) падениях иксов; сомневаюсь, что многие обсуждающие видят её чаще. Матричные принтеры ассоциируются разве что с кассовыми чеками. Надобность понятия знакоместо, из которого растёт необходимость моноширинного шрифта, как таковая исчезла полностью.
Почти полностью.
Потому что на двадцать седьмого апреля две тысячи одиннадцатого года, за неимением нормальных IDE для редактирования исходников, некоторые люди (и, как я уже сказал, к сожалению, я сам) выравнивают код пробелами.
Для чего необходимо, чтобы символ пробела имел точно такую же толщину, как и символ любой другой буквы.
Двадцать седьмого апреля две тысячи одиннадцатого года.
У экрана моего ноутбука 145 DPI, у современных планшеток и мобильников может быть и ещё больше. Монитор с экраном размером 1920x1080 пикселей стал чем-то вполне обыденным, и стали распространяться разрешения и выше. Аппаратную текстовую консоль лично я вижу только при загрузке линукса да при редких (с последними обновлениями иксов и драйвера Intel в Дебиане — почему-то частых) падениях иксов; сомневаюсь, что многие обсуждающие видят её чаще. Матричные принтеры ассоциируются разве что с кассовыми чеками. Надобность понятия знакоместо, из которого растёт необходимость моноширинного шрифта, как таковая исчезла полностью.
Почти полностью.
Потому что на двадцать седьмого апреля две тысячи одиннадцатого года, за неимением нормальных IDE для редактирования исходников, некоторые люди (и, как я уже сказал, к сожалению, я сам) выравнивают код пробелами.
Для чего необходимо, чтобы символ пробела имел точно такую же толщину, как и символ любой другой буквы.
Ну так тем более, если у вас такой огромный экран, неужели вам стало жалко нескольких пикселей разницы между шириной моноширинного и пропорционального пробела?
И то, что на пятнадцать часов тридцать три минуты двадцать седьмого апреля две тысячи одиннадцатого года по московскому времени ни одна корпорация и не придумала такую IDE, которую вы бы могли назвать нормальной, описывает разве что ваше хитрое понятие «нормальности», а не нелогичность использования пробелов.
И то, что на пятнадцать часов тридцать три минуты двадцать седьмого апреля две тысячи одиннадцатого года по московскому времени ни одна корпорация и не придумала такую IDE, которую вы бы могли назвать нормальной, описывает разве что ваше хитрое понятие «нормальности», а не нелогичность использования пробелов.
Суть не в пикселях разницы (эту тему я, впрочем, откомментировал ниже). Мне жаль не пикселей, мне жаль глаз. Мировой полиграфический опыт свидетельствует о том, что пропорциональные шрифты читабельнее.
Вообще всю мою мысль, почему в исходниках для indendation желательно использовать пробелы, почему в чём разница между логическими отступами и визуальными, при чём тут view и model, почему можно свести к одной фразе:
Какой вы предпочитаете размер indent-а? Я — 3.0 em.
Какой вы предпочитаете размер indent-а? Я — 3.0 em.
Если написать код приведённый в статье пропорционалным шрифтом, вы его никак не выровняете ни пробелами ни табами.
Черт, я запутался. Кто за табы, а кто за пробелы?
Самое главное, что о табах надо думать, смотреть не пролезли ли пробелы где-то. А пробелы они всегда пробелы. Даже если ты catом напечатал файл.
Еще один аргумент в пользу пробелов. Не мой. В icq знакомый прислал:
Лично мне довольно часто приходится что-то искать в коде. при этом средства поиска в разных IDE обычно не блещут интеллектуальностью, нормально работает только поиск подстроки.
Да, есть во многих редакторах поиск по регэкспам, но честно говоря — мне лень вспоминать и отлаживать регэксп если мне просто нужно что-то найти.
так вот… если я хочу найти, например, строку:
Я ввожу в поиске " first " (с пробелом спереди и сзади) и нихрена не нахожу, если для выравнивания после first стоит таб.
Может быть это не самый удачный пример… это просто то что пришло в голову. Но с такой фигнёй я реально сталкивался не раз, когда не можешь что-то найти в коде если после или перед переменной стоял tab. А поиск по подстроке «first» может давать 1000 ложных срабатываний.
Конечно, когда речь идёт именно об имени переменной — может спасти поиск использования этой переменной в коде средствами IDE. Но нахрен это надо, если можно просто использовать пробелы?.. :)
Лично мне довольно часто приходится что-то искать в коде. при этом средства поиска в разных IDE обычно не блещут интеллектуальностью, нормально работает только поиск подстроки.
Да, есть во многих редакторах поиск по регэкспам, но честно говоря — мне лень вспоминать и отлаживать регэксп если мне просто нужно что-то найти.
так вот… если я хочу найти, например, строку:
someVariable = a + first + b; // <--- вот что я хочу найти
anotherVariable = a + 100500 + second;
Я ввожу в поиске " first " (с пробелом спереди и сзади) и нихрена не нахожу, если для выравнивания после first стоит таб.
Может быть это не самый удачный пример… это просто то что пришло в голову. Но с такой фигнёй я реально сталкивался не раз, когда не можешь что-то найти в коде если после или перед переменной стоял tab. А поиск по подстроке «first» может давать 1000 ложных срабатываний.
Конечно, когда речь идёт именно об имени переменной — может спасти поиск использования этой переменной в коде средствами IDE. Но нахрен это надо, если можно просто использовать пробелы?.. :)
И ещё золотые слова:
плюс, то что там люди негодуют от необходимости использовать backspace многократно. не могу прокомментировать на хабре, т.к. не зарегистрирован там. но звучит это как полный бред ленивого стажёра.
большую часть времени мы читаем уже написанный код. и лишь небольшую часть времени — правим и пишем новый. так не надо лениться оформлять код так чтоб его легко и удобно было читать. какая разница, сколько раз там придётся нажать backspace, если это делается раз в час? главное чтоб код был удобночитаем везде и всегда
плюс, то что там люди негодуют от необходимости использовать backspace многократно. не могу прокомментировать на хабре, т.к. не зарегистрирован там. но звучит это как полный бред ленивого стажёра.
большую часть времени мы читаем уже написанный код. и лишь небольшую часть времени — правим и пишем новый. так не надо лениться оформлять код так чтоб его легко и удобно было читать. какая разница, сколько раз там придётся нажать backspace, если это делается раз в час? главное чтоб код был удобночитаем везде и всегда
большую часть времени мы читаем хабр, немного читаем код и совсем редко его пишем
Вы, случаем, ещё не оформляете комментарии рамками из звёздочек? Это же так красиво! И какая разница, сколько раз там придётся нажать *, если это делается 100500 раз в час. Главное не лениться.
большую часть времени мы читаем уже написанный код. и лишь небольшую часть времени — правим и пишем новый. так не надо лениться оформлять код так чтоб его легко и удобно было читать. какая разница, сколько раз там придётся нажать backspace, если это делается раз в час? главное чтоб код был удобночитаем везде и всегда
Глупость какая-то. Когда я открываю код — я загоняю его в свою «оперативную память» — проглядываю и запоминаю и работаю с ним уже из памяти (где на отступы наплевать), я код почти не читаю — помню все с чем работаю наизусть. Правда, стоит задать даже примитивный вопрос, как память вываливается.
В вашем примере имеет место быть как раз alignment, который всегда делается пробелами.
Вы нас не слышите. :) Какой уж достался код, такой достался. И надо с ним жить. Многие работают больше не со своим кодом, а с чужими. А там как бог надушу положит. Например, это ситуация в компаниях, занимающихся outsource. Если повсеместно рекомендовать использовать пробелы, в целом мир станет лучше. Да, это спорная, но уж такая моя точка зрения на этот вопрос.
Да, это все понятно. Как вы правильно заметили, с чужим кодом ничего и не поделаешь, где-то будет два пробела, где-то четыре, где-то табы. Но для меня, например, мир, в котором отступы сделаны пробелами — не лучше, а хуже, он мешает мне подстроить отступ под конкретное устройство, с конкретным разрешением и размером экрана.
Уж лучше научить всех правильно пользоваться табами, т. е. делать отступы ими, а выравнивание пробелами, как положено. Чему и посвящена данная статья.
Уж лучше научить всех правильно пользоваться табами, т. е. делать отступы ими, а выравнивание пробелами, как положено. Чему и посвящена данная статья.
«Whole words only» же
Кстати, а в FF, в частности в Firebug, можно настроить размер таба? А то по умолчанию вроде = 8 и соответственно отступы в коде просто ужасающе велики.
а что делать с такими отступами? Они не кратны размеру таба… Половина отступа — табы, половина пробелы? Обязательно все разъедется при изменении размера таба.
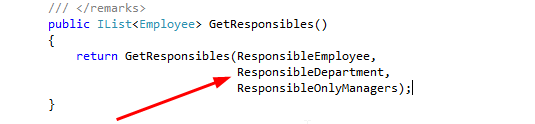
Вы статью читали? Есть отступ, а есть выравнивания. Отступ делаете табами, а выравниваете пробелами, и ничего у вас не разъедется.
руками что-ли натыкивать? IDE разве сами понимают где отступ, а где выравнивание?
Зависит от вашей IDE и настроек. Обычное ей не нужно ничего понимать. Моя, например, просто копирует такой же отступ как и был на предыдущей строчке. При первом переводе скопирует табы, далее выравниваешь пробелами как тебе необходимо, и при следующим она уже копирует и табы (отступ) и пробелы (выравнивание). Зато когда закончил, закрыл скобку, поставил двоеточие, очень легко спуститься четко до уровня отступа, достаточно убить все пробелы.
Я в Студии для такого просто ставлю точку с запятой в конце строки (для длинного метода). И я не уверен, что она настолько умна, чтобы расставить сначала табы, а потом пробелы.
Если умна, то да, ничего не мешает использовать табы в принципе. Только вот в блокноте уже не отредактируешь по-быстрому. Сам-то я не хочу задумываться в каждой строке: где тут отступ, где тут выравнивание…
Если умна, то да, ничего не мешает использовать табы в принципе. Только вот в блокноте уже не отредактируешь по-быстрому. Сам-то я не хочу задумываться в каждой строке: где тут отступ, где тут выравнивание…
И когда вступает в игру «основное преимущество» табов — возможно настройки их ширины, всем красивым отступам наступает конец.
Отчего же?
У вас таб = 4 пробела.
> При первом переводе скопирует табы, далее выравниваешь
> пробелами как тебе необходимо и при следующим она уже
> копирует и табы (отступ) и пробелы (выравнивание)
Сдвиг, например, равен 4 таба + 1 пробел. Сдвиг второго аргумента = 17 символов, все смотрится хорошо.
Я на маленьком мониторе хочу воспользоваться огромным преимуществом табов и для более компактного отображение у меня установлен таб = 2 пробела. В итоге второй аргумент сдвинут на 9 символов.
> При первом переводе скопирует табы, далее выравниваешь
> пробелами как тебе необходимо и при следующим она уже
> копирует и табы (отступ) и пробелы (выравнивание)
Сдвиг, например, равен 4 таба + 1 пробел. Сдвиг второго аргумента = 17 символов, все смотрится хорошо.
Я на маленьком мониторе хочу воспользоваться огромным преимуществом табов и для более компактного отображение у меня установлен таб = 2 пробела. В итоге второй аргумент сдвинут на 9 символов.
Сдвиг не может быть равен 4 таба + пробел. Вы статью читали? Отступ делается только табами. Выравнивание пробелами.
В приведенном у Pilot34 фрагменте все три строчки внутри функции относятся к одному блоку кода, очевидно, с одинаковым отступом. Одинаковый отступ значит одинаковое число табов. И сколько бы вы не поставили размер таба, все строчки будут сохранять одинаковый отступ.
Вам в конце статьи автор даже пример привел. На одном и том же фрагменте кода изменял размер табов от 2 до 9, и ничего не поехало.
В приведенном у Pilot34 фрагменте все три строчки внутри функции относятся к одному блоку кода, очевидно, с одинаковым отступом. Одинаковый отступ значит одинаковое число табов. И сколько бы вы не поставили размер таба, все строчки будут сохранять одинаковый отступ.
Вам в конце статьи автор даже пример привел. На одном и том же фрагменте кода изменял размер табов от 2 до 9, и ничего не поехало.
Делайте проще:
ну или
public IList<Employee> GetResponsibles()
{
→ return GetResponsibles(
→ → ResponsibleEmployee,
→ → ResponsibleDepartment,
→ → ResponsibleOnlyManagers
→ );
}
ну или
public IList<Employee> GetResponsibles()
{
→ return GetResponsibles(
→ → ResponsibleEmployee,
→ → ResponsibleDepartment,
→ → ResponsibleOnlyManagers);
}
Мне кажется, что у табов есть одно весомое преимущество. Любой исходник с табами можно конвертировать в пробельный с нужным количеством «пробел/таб», обратная конверсия зачастую невозможна.
Разве тяжело заменить n пробелов на один таб?
Проблема в том, что не все n пробелов «в девичестве» могли быть табами.
Но ведь автор напирает на некую фичу в ИДЕ с 'умными' табами, которая ставит пробелы вместо табов там где это нужно, я уверен можно и обратную задачу решить.
Вспоминаются слова некогда популярной песни:
Фарш невозможно провернуть назад.
И мясо из котлет не восстановишь.
)
Фарш невозможно провернуть назад.
И мясо из котлет не восстановишь.
)
врут… можно
Чисто логически, если умный редактор знает где ставить пробелы вместо табов — очевидно он различает где тут несколько пробелов, а где таб.
Как правило, редакторы ставят пробелы тогда, когда юзер нажал кнопку Tab, а не просто везде, где табы в тексте увидел. А так, чтоб он все табы ранее бывшие в тексте сам позаменял — это его ещё уговаривать как правило надо.
Но ведь разницы то нет. Вот представьте нам дали исходник с пробелами и мы забыв про копи паст перепечатываем его в другом окне, заменяя подряд идущие пробелы — табами. Где редактору с такой функцией здесь ошибиться?
даже если не все пачки пробелов табами заменять, а только те, что в начале строки — получится лажа при смешении отступов с выравниванием, типа как тут: habrahabr.ru/blogs/programming/118208#comment_3852633
А если вообще все — то с выравниванием лажа точно вылезет…
А если вообще все — то с выравниванием лажа точно вылезет…
только вот нужное количество хранится в настройках редактора у автора кода, и где их взять, если автор умер?
sed 's/^ /\t/g' from > toТам 4 пробела должно быть :)
Хотя конечно такое сработает только с хорошо отформатированными исходниками.
Хотя конечно такое сработает только с хорошо отформатированными исходниками.
Операция преобразования табы->пробелы не ассоциативна, если выражаться математическим языком, поэтому результат такой комманды непредсказуем.
Самое простое:
function () {
var foo = 123,
bar = 234,
function () {
if (foo < bar) {
var xxx = 'qux',
yyy = 'qwe';
alert( xxx + yyy );
}
}
}Однажды, регулярные выражения спасут мир!
Если делать табы видимымы в редакторе (как на ваших скриншотах), появляется лишняя проблема за которой программист должен следить. А у него и так голова забита.
Если делать табы невидимымы — можно получить невидимый баг.
Что выведет эта программа? 32 или 9?
void main() {
std::cout << (int)(" "[0]);
}
Если делать табы невидимымы — можно получить невидимый баг.
Что выведет эта программа? 32 или 9?
void main() {
std::cout << (int)(" "[0]);
}
В vim (и емакс тоже, но я синтаксис не знаю) есть такая вещь как modeline.
Прописываешь в первых N строчках файла настройки для данного файла, и vim сам использует принятый в данном коде формат.
Пример
# vim: set ts=4 sts=4 sw=4 et:
Прописываешь в первых N строчках файла настройки для данного файла, и vim сам использует принятый в данном коде формат.
Пример
# vim: set ts=4 sts=4 sw=4 et:
товарищи, вы о чём? номальные иде самостоятельно определяют тип отступов в файле и используют его не нарушая стиля. таб вставляет пробелы, бэкспейс удаляет их пачками. проблемы с использованием пробелов нет никакой. а вот с табами проблемы есть, ибо если косяк с пробелами виден сразу и всем, то косяк с табами может быть незаметен у тебя, но вылиться в проблемы у другого. я сам люблю табы, и если бы хоть одна иде могла бы их использовать для выравнивания, используя табы как разделители колонок в группе подряд идущих непустых строк, — я бы обязательно ими пользовался. а то выравнивать пробелами уж очень сильно напрягает. а отступы в нормальных иде — не важно чем делать. монопесуально.
tab использую когда пишу текст в word ) В коде — только пробелы!
Боксеры по-переписке, блин. Прямо смешно
Какая то надуманная проблема. Пробелы как пробелы. Табы как табы.
пробел не сломается 100500раз жать его??
Поиском здесь не нашёл слов, начинающихся на «муд», а проблема как раз в них, мудаках.
Не так важно, как оформлен код, табами или пробелами. В большом проекте всегда найдутся мудаки, которые не в состоянии оценить стиль файла и настроить редактор. Патчат исходники как попало, внося хаос. И кроме как indent'ом каким-нибудь к единому стилю уже не привести. Приходится иногда шерстить весь код, внося лишние диффы.
Конечно, когда все умные, как вы, проблема только проголосовать за какой-нибудь стиль.
Не так важно, как оформлен код, табами или пробелами. В большом проекте всегда найдутся мудаки, которые не в состоянии оценить стиль файла и настроить редактор. Патчат исходники как попало, внося хаос. И кроме как indent'ом каким-нибудь к единому стилю уже не привести. Приходится иногда шерстить весь код, внося лишние диффы.
Конечно, когда все умные, как вы, проблема только проголосовать за какой-нибудь стиль.
Ну как бы вы меня почти вынудили вернуться обратно на табы. Но в Ruby сообществе принято использовать софт-табы в 2 пробела. На гитхабе один там это 8 пробелов, а это не читабельно. Для меня основное преимущество табов это то, что их можно отображать и сразу видно уровень вложености. И в принципе для меня этого достаточно, если бы не первых 2 «но».
Хм, а Netbeans позволяет применять такое решение с пробелами только для alignment (не ставя кучу пробелов вручную, естественно)?
Не нахожу, к сожалению.
Не нахожу, к сожалению.
В общем, насколько я понял комменты, в дискриминации табов виноват блокнот и ему подобные редакторы, сервисы и смотрелки, не дающие настраивать ширину таба, и издревле отображающие его шириной 8 пробелов. В связи с тем, что многим программерам код через них смотреть приходится весьма часто, эти многие предпочитают пробелы. Те, кому посчастливилось пользоваться только табо-настраиваемыми средствами просмотра кода, их никогда не поймут.
> А еще дополнительно у пробелов есть такие недостатки, как невозможность быстрого перемещения стрелочками клавиатуры
Проблема надумана. Откройте для себя комбинацию клавиш ctrl+стрелочка.
Проблема надумана. Откройте для себя комбинацию клавиш ctrl+стрелочка.
Если кому-то удалось подружить Vim-плагин Smart Tabs a.k.a. ctab (согласно wiki именно этот плагин реализует описанное в статье разделение indent и align) с плагинами SuperTab и snipMate — поделитесь своим .vimrc, плз. Ну или подскажите альтернативный способ это настроить без Smart Tabs, но чтобы SuperTab и snipMate продолжали работать.
Вот возник вопрос.
Использую табы, в гуглокоде при просмотре кода через веб-интерфейс он растягивает их аж до 8 пробелов.
Переходить на пробелы, игнорировать?
Использую табы, в гуглокоде при просмотре кода через веб-интерфейс он растягивает их аж до 8 пробелов.
Переходить на пробелы, игнорировать?
Респект автору. Полностью поддерживаю Вашу точку зрения!
Когда-то и я был сторонником табов.
PEP8 переучил :)
PEP8 переучил :)
Нам приходится много пользоваться WinDBG, в котором ширина таба 8 символов и перенастроить можно лишь на одну сессию, а потом сбивается обратно (WinDBG это вообще пример как нельзя делать GUI, но к сожалению аналогов ему нет).
В тоже время в студии ширина таба по умолчанию 4 символа.
Мы решили эту проблему использованием 4-х пробелов вместо табов.
Разделение на indentation и alignment может быть и решило бы эту проблему, но как это контролировать?
Есть ли для этого что-нибудь в Visual Studio?
В тоже время в студии ширина таба по умолчанию 4 символа.
Мы решили эту проблему использованием 4-х пробелов вместо табов.
Разделение на indentation и alignment может быть и решило бы эту проблему, но как это контролировать?
Есть ли для этого что-нибудь в Visual Studio?
у меня лишь один вопрос. Как заставит снифер(к примеру phpcs) не ругаться на табы?
TheShock Тут на самом деле большая проблема в том, что многие (иногда и я) ленятся правильно поставить место, откуда нужно делать табуляцию/интендацию. Ткнул куда-то примерно в нужное место, промахнулся на пару пикселей и не заметил, выровнял все, написал код… А для компилятора там табы + пробелы + снова табы + опять пробелы. И при другом размере таба все съезжает нафиг.
С пробелами такой фигни нет. Вообще не вижу, в чем проблема с пробелами. Ну да, чуть труднее стирать уровень интенданции, но лично я все равно руками этого никогда не делаю, format block и студия сама уберет все ненужные символы, что пробелы, что табы.
Преимущество того, что каждый может использовать таб своего размера — ну не знаю. Имхо в C# есть стандарт на 4 пробела, и это нужно фиксировать в код стайле. Не вижу большой пользы от того, чтобы каждый имел свой таб, кроме эстетического наслаждения. То есть это конечно прикольно, но проблема миксов табов и пробелов мне кажется существеннее.
С пробелами такой фигни нет. Вообще не вижу, в чем проблема с пробелами. Ну да, чуть труднее стирать уровень интенданции, но лично я все равно руками этого никогда не делаю, format block и студия сама уберет все ненужные символы, что пробелы, что табы.
Преимущество того, что каждый может использовать таб своего размера — ну не знаю. Имхо в C# есть стандарт на 4 пробела, и это нужно фиксировать в код стайле. Не вижу большой пользы от того, чтобы каждый имел свой таб, кроме эстетического наслаждения. То есть это конечно прикольно, но проблема миксов табов и пробелов мне кажется существеннее.
промахнулся на пару пикселей
И попал или слева или справа от таба. Не понимаю, как могут появится пробелы.
Ткнул куда-то примерно в нужное место, промахнулся на пару пикселей и не заметил, выровнял все, написал код…
А вот с пробелами как раз такая проблема есть. Стоит пустая строка, где у тебя
function test() {
....var a, b;
....
....a = doSomeA();
....b = doSomeB();
}
Хочешь что-то дописать, нажимаешь, промахиваешься на пару пикселей и пишешь такое:
function test() {
....var a, b;
...doSomeC();.
....a = doSomeA();
....b = doSomeB();
}
Як, кстати, вот щас прям писал и попал со второго раза куда хотел.
Ну возможно. Полагаю если IDE всегда правильно определяет таб или интенданцию то такого не может произойти, но у меня на практике подобное возникало миллион раз. Насчет «промахивания на пару пикселей» обычно ставлю каретку на конец строки (в данном случае под точкой запятой под b), и оно всегда устанавливается после последнего символа в строке.
Так еще можно промахнуться. С пробелами по всякому можно:
function test() {
----doSomeC();
}
// =>
function test() {
---this.-doSomeC();
}
Полагаю если IDE всегда правильно определяет таб или интенданцию то такого не может произойти, но у меня на практике подобное возникало миллион раз
Я не могу понять, как такое может возникнуть? ТОЛЬКО с пробелами. Ибо не может курсор быть в середине символа таба. Или слева или справа, тут нечего определять.
Например, WebStorm позволяет поставить курсор посреди пробело-таба, но не позволяет посреди нормального пробела.
Запоздалый ответ:
1) В студии не всегда правильно работают смарт табы, и вставляет пробелы (или табы) не там, где надо. Вывод — всё едет
2) В нормальном проекте куча разработчиков, не всегда получается синхронизировать настройки инструментов. В таком случае пробелы — лучше.
Но я согласен, что лучше на уровне код-стайла команды зафиксировать один вид отступов (лучше — табы), и всегда им пользоваться. За прошедший год моё видение несколько изменилось
Странно, но в обеих статьях не заметили, что если вставить оттабленый код в среднестатистический чат, будет так:
ЗЫ я знаю про тег <code>, но в чатах его нет. Для меня это главная причина использовать пробелы вместо табуляции.
if(1) {
if(2) {
if(3) {
console.log('Yeah! It is third level!')
}
}
}
ЗЫ я знаю про тег <code>, но в чатах его нет. Для меня это главная причина использовать пробелы вместо табуляции.
С пробелами та же фигня. В браузере много пробелов заменяются на один или вообще удаляются. Вот, к примеру:
if(1) {
if(2) {
if(3) {
console.log('Yeah! It is third level!')
}
}
}
Да — вы правы, HTML схлопывает пробелы. Но в условных вазапах\телеграмах всё в порядке.
Для HTML (например чат вКонтакте) не комильфо, но альтернатива — использовать неразрывные пробелы. Их браузер не схлопывает.
Для HTML (например чат вКонтакте) не комильфо, но альтернатива — использовать неразрывные пробелы. Их браузер не схлопывает.
if(1) {
if(2) {
if(3) {
console.log('Yeah! It is third level!')
}
}
}
В большинстве чатов есть возможность вставить код, в т.ч. с табами через
```, проверил в телеграме и в дискорде. Если нету, то все-равно нету смысла код вставлять напрямую, а не через какой-то пастбин``` — классная возможность, которая пришла из маркдауна сравнительно недавно. Сам стараюсь всегда его использовать, но бывает, что — нет. А других людей убедить его использовать на постоянной основе — задача и вовсе нетривиальная.
Куда проще убедить их, что на проекте у нас отступы в два пробела и в очередной раз, получив абзац в общий чат, не копировать код к себе в редактор, чтобы об него не сломались глаза.
Но это конечно мои личные переживания и если вас окружают исключительно дисциплинированные программисты и вам не приходится читать куски кода прямо в общих чатах, то ни коим образом не призываю, что то менять. Используйте — что удобно. Главное чтобы команда приняла это за стандарт.
ЗЫ отдельно хотелось бы рассказать о лайфхаке для
Похожие возможности полагаю и до чатов дойдут. Не знаю хорошо это или плохо. Разумеется изыски в темах оформления IDE тоже могут заставить глаза лить кровавые слёзы, но комментируя код автора можно быть ближе к тому, что видит он. В целом вижу здесь возможность для улучшения коммуникации.
Куда проще убедить их, что на проекте у нас отступы в два пробела и в очередной раз, получив абзац в общий чат, не копировать код к себе в редактор, чтобы об него не сломались глаза.
Но это конечно мои личные переживания и если вас окружают исключительно дисциплинированные программисты и вам не приходится читать куски кода прямо в общих чатах, то ни коим образом не призываю, что то менять. Используйте — что удобно. Главное чтобы команда приняла это за стандарт.
ЗЫ отдельно хотелось бы рассказать о лайфхаке для
contenteditable полей ввода. Например если в Gmail вставить кусок кода напрямую из редактора — форматирование сохранится. Тоже касается например Word или Google Docsпример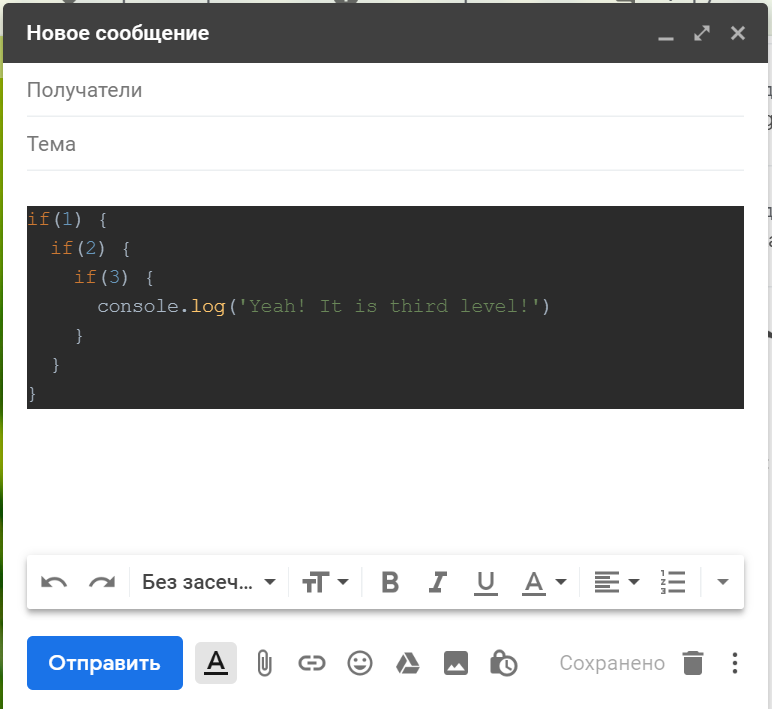
Похожие возможности полагаю и до чатов дойдут. Не знаю хорошо это или плохо. Разумеется изыски в темах оформления IDE тоже могут заставить глаза лить кровавые слёзы, но комментируя код автора можно быть ближе к тому, что видит он. В целом вижу здесь возможность для улучшения коммуникации.
А других людей убедить его использовать на постоянной основе — задача и вовсе нетривиальная.Ну с такими людьми вообще работать задача нетривиальная.
А вообще убедить очень просто — код, который не оформлен как код — считать просто мусором и просить, чтобы кинули его нормально. 3 раза кинут неправильно — потом нормально.
не приходится читать куски кода прямо в общих чатахКонечно приходится. Но я ведь работаю с программистами, а не бухгалтерами — а они знают, как вставить код правильно.
Интересно в 2021 Вы всё ещё считаете что табы лучше? Для алигмента 10 раз пробел жмакаете?
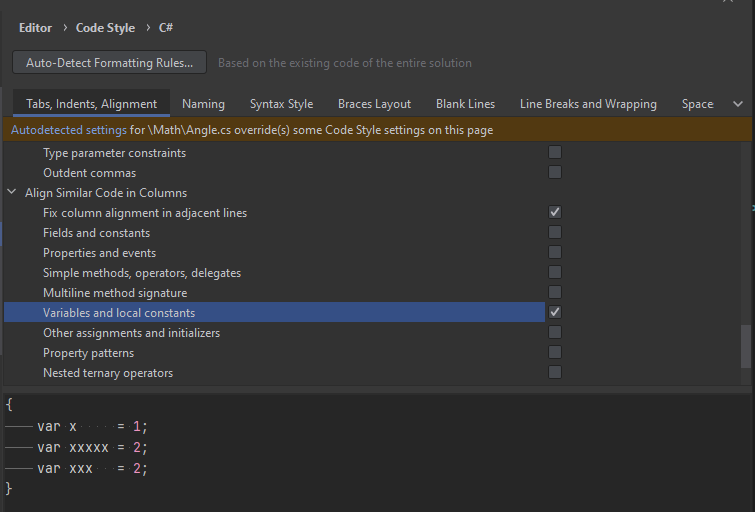
Sign up to leave a comment.
Пора завязывать использовать пробелы вместо табуляции в коде