Comments 79
Полагаю, нужен еще пороговый коэффициент, меньше которого считаем, что число не распознано вообще.


А за статью спасибо, крайне наглядно и информативно.
yadi.sk/i/IijN1bEKsvbmx
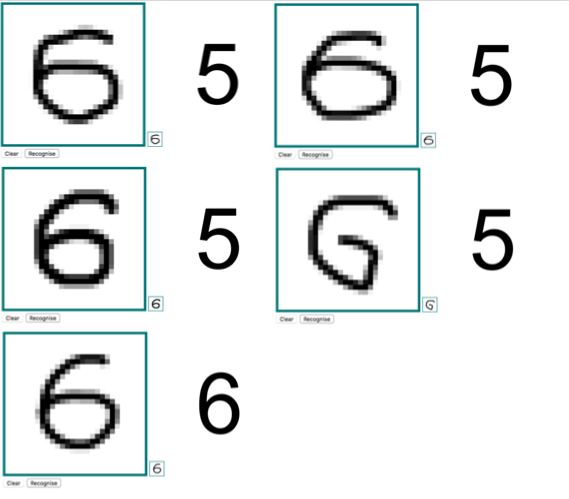


Исходная нарисованная цифра ниачинает видоизменяться, причем сильно. Соотв. и распознавание другое…
Как то так…
Дело видимо в том, что распознаётся не та картинка, которую вы рисуете не холсте, а та, что находится справа-внизу и содержит уменьшенную копию нарисованного вами изображения. По нажатию на кнопку «распознать» картинка с большого холста копируется на маленький, соответственно, она уменьшается, но затем зачем-то эта уменьшенная версия копируется обратно на большой холст. В итоге, после нескольких итераций картинка изменяется до неузнаваемости.
После определения показывается отмасштабированная картинка приведенного исходника ( 28х28 пикселей).
Каждое новое определение снова меняет масштаб, отсюда и разница.
А мне не понравилось, описываете известные факты, а самое интересное заменяете библиотекой. Я думал будет статья по подобию вот этой, где автор вместе с читателем строит сеть на js сам
Тэги: JavaScript*, Big Data*
Ну да.
Есть ли под JS либы с jit-компиляцией? Обычно используют theano+[lasagne|keras] либо torch, caffe, tensorflow. Чем определен выбор JS?
Ладно, на самом деле в статье обычный пример обучения. Просто самого содержания статьи нету. Нейронные сети — это не про программирование, это про машинное обучение и deep learning. Это про то, что скрывается за net.train(). А тут в статье даже слова градиент нету.
>Код будет понятен даже тем программистам, которые не имели дело с нейронными сетями ранее.
Последовательность действий будет понятна даже тем программистам, которые никогда не занимались пайкой ранее.
>В качестве функции f(x) чаще всего используется сигмоидная или пороговая функции
Пороговая функция в качестве функции активации использоваться не может, потому что, внезапно, ее производная не равна нулю на множестве меры 0. Тут скорее надо упомянуть тангенциальную функцию, rectifier, leaky rectifier.
>JS таки заметно быстрее чем py
Есть ли под JS либы с jit-компиляцией? Обычно используют theano+[lasagne|keras] либо torch, caffe, tensorflow. Чем определен выбор JS?
Если этот вопрос ко мне, то мне просто нравиться JavaScript.
Ладно, на самом деле в статье обычный пример обучения. Просто самого содержания статьи нету. Нейронные сети — это не про программирование, это про машинное обучение и deep learning. Это про то, что скрывается за net.train(). А тут в статье даже слова градиент нету.
Да, нету. Нейронные сети это инструмент для решения некоторого класса задач и не всегда разработчику JavaScript нужно хорошо разбираться в том как реализован net.train(), достаточно знать что ему подавать на входы и что будем иметь на выходе.
Следуя вашей логике каждый JavaScript программист должен знать C, чтоб понимать как работает функция сортировки.
>Код будет понятен даже тем программистам, которые не имели дело с нейронными сетями ранее.
Последовательность действий будет понятна даже тем программистам, которые никогда не занимались пайкой ранее.
Очень оригинально.
>В качестве функции f(x) чаще всего используется сигмоидная или пороговая функции
Пороговая функция в качестве функции активации использоваться не может, потому что, внезапно, ее производная не равна нулю на множестве меры 0. Тут скорее надо упомянуть тангенциальную функцию, rectifier, leaky rectifier.
Вы начали искать изъяны в теории? У вас минусовая карма, так вы троль, что ли?
Да, нету. Нейронные сети это инструмент для решения некоторого класса задач и не всегда разработчику JavaScript нужно хорошо разбираться в том как реализован net.train(), достаточно знать что ему подавать на входы и что будем иметь на выходе.
А смысл в подобных знаниях на обезьяньем уровне? Ну т.е. на MNIST'е оно работает, а на более сложных задачах почти наверняка возникает масса проблем при тренировке, которые даже продиагностировать нельзя без понимания того, что находится под капотом у tran'а...
А смысл в подобных знаниях на обезьяньем уровне? Ну т.е. на MNIST'е оно работает, а на более сложных задачах почти наверняка возникает масса проблем при тренировке, которые даже продиагностировать нельзя без понимания того, что находится под капотом у tran'а...
В статье достаточно информации для того чтоб заинтересовать человека, который никогда с этим не сталкивался. Ну Вам не угодил, — бывает.
Да не сочтут за троллинг, но вы путаетесь в показаниях: сначала вы говорите, что JS-разработчик может использовать ML как черный ящик, а сейчас уже говорита о том, что статья вроде как должна заинтересовать к дальнейшему изучению темы, т.е. лезть внутрь train'а :-)
Не слушай этих хейтеров. отличная статья!
Ну это, а что, нельзя что ли? Вы фигню написали, уже нельзя и вам на это указать?
>У вас минусовая карма, так вы троль, что ли?
Я не знаю какая у меня карма. Это второй пост, который я комментирую, второй пост который берет меня за живое, потому что автор постит что-то странное, и я пишу об этом.
А можно подробней, где эти "многие места" можно посмотреть?
Если посмотреть на распознавание изображений, то там мейнстрим как-раз ReLU (причем самое тупое, с нулем в отрицательной области). Во всяких GoogLeNet, ResNet etc. именно такая активация используется.
Сама статья о maxout с теорией и сравнениями:
http://jmlr.csail.mit.edu/proceedings/papers/v28/goodfellow13.pdf
Распознавание лиц с maxout слоями (вернее с его производным — Max-Feature-Map), топовый результат для embedded systems:
http://arxiv.org/pdf/1511.02683v1.pdf
p.s. GoogLeNet это 2014 год и уже не показатель инноваций.
Maxout это более общий случай ReLU и Leaky ReLU.
Да, я в курсе что это такое. Просто в каких-то достаточно знаковых статьях я не встречал чего-то отличного от ReLU при a = 0...
p.s. GoogLeNet это 2014 год и уже не показатель инноваций.
Эмм...GoogLeNet — это уже не одна сетка, а целое семейство и последние версии Inception'а опубликованы уже в 2016 году (та версия, которая с Residual связями).
Интересно, что размер модели меньше более чем в 10 раз при лучшем качестве :)
Точность распознавания визуально оценивать сложно. Измерить можно на выборке для тестирования из базы MNIST. Там 10000 тестовых примеров. Я таких замеров не проделывал, т.к. для демонстации работы сети, того что я сделал — достаточно.
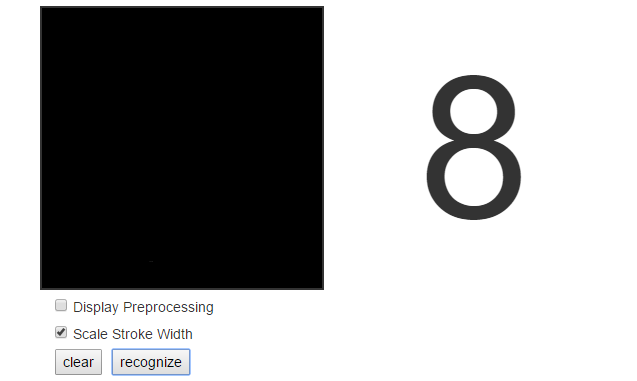
P.S. Кстати оба варианта в черном квадрате распознают восьмерку. Стабильно и без ошибок.

Ан нет…



P.S. Не ругайтесь это ж пятница )) Смысл жизни 42, это факт.
Не уверен что это задача для JavaScript. При распознавании изображений во входном слое будет очень много нейронов, а nodejs и др. реализации js однопоточные. (Это означает что в один момент времени будет задействовано только одно ядро). Но натренированную модель для классификации фото загрузить в js реально.
Не уверен что это задача для JavaScript.
Ну какже? С одной стороны баррикад желающие распознавать капчу прямо в броузере (например на фантоме), с другой стороны — желающие определять ботов по отличию в поведении от человека (выделения текста, поведение курсора — в общем паттерны поведения), и это идеальная задача для нейросетей, а решение ее прямо в броузере — бизнесом востребовано.
А опыт Америки в второй мировой показывает что торговать оружием с обеими сторонами — выгодно )
c2n.me/3zQaWvF
почему на выходе 10 нейронов по числу вариантов ответа, а не 4 по количеству фактической информации?
В первом примере с XOR написано:
У нас 2 входящих нейрона и один нейрон на выходе
Один нейрон «голосует» за результат XOR-а, т.е. за 0 или 1, и возвращаемое значение из интервала [0,1] мы интерпретируем как 0 или 1 в зависимости от того, к какому краю интервала ближе, а отклонение — как меру возможной ошибки. Скажем, чем ближе к 0.5, тем сложнее коррекно интерпретировать результат. Верно?
Во входном слое нам необходимо 28x28=784 нейрона, на выходе 10 нейронов
В задаче с цифрами есть 10 различных вариантов, то есть мы хотим получить чуть больше 3 битов информации.
Если делать по аналогии с тем, что написал выше, то должно быть 4 выхода по числу бит, которые мы хотим получить.
Если же мы говорим, что каждому варианту должен соответствовать свой выход и нейросеть голосует за каждый вариант отдельно, то в задаче с XOR должно быть 2 выхода.
Если мы говорим, что в задаче с XOR достаточно одного выхода, потому что «голос за 0» = 1 — «голос за 1» и нечего подавать на выход избыточную информацию, то в задаче с цифрами должно быть 9 выходов.
В общем, не получается у меня согласовать два примера, отсюда и вопрос.
Вот то, что ф-ия обучения справилась с таким вот сложным случаем — XOR на сети с одним выходом — нередко показывают в качестве демонстрации крутости алгоритма обучения (эдакий канонический пример). В реальных задачах так делать не нужно.
Нейронные сети на Javascript