Comments 72
Что-то я не понимаю...
Вот у нас внутри PromiseHandleWrapper написано следующее:
JSValue result = func.call(context, args, false);
promise.setResult(result);Какое отношение результат вызова функции, переданной в then, имеет к значению, хранящемуся в обещании? Разве тут не должно быть наоборот — значение из обещания должно быть передано в onFulfilled единственным параметром?
Опять же, реализация метода then какая-то странная. Вы вообще в курсе, что в Javascript у одного и того же обещания можно вызвать метод then два раза, и это не будет цепочкой?
const p = Promise.resolve(5);
p.then(x => (console.log(x), 10)); // выведет 5
p.then(x => (console.log(x), 10)); // выведет опять 5
p.then(x => (console.log(x), 10)).then(x => (console.log(x), 10)) // выведет сначала 5, а потом 10Кстати, куда делось требование 2.2.4 стандарта Promises/A+ "onFulfilled or onRejected must not be called until the execution context stack contains only platform code", оно же пункт 25.4.1.8 стандарта ECMAScript 2015:
The abstract operation TriggerPromiseReactions takes a collection of PromiseReactionRecords and enqueues a new Job for each record. Each such Job processes the [[Handler]] of the PromiseReactionRecord, and if the [[Handler]] is a function calls it passing the given argument. [...]
Какое отношение результат вызова функции, переданной в then, имеет к значению, хранящемуся в обещании? Разве тут не должно быть наоборот — значение из обещания должно быть передано в onFulfilled единственным параметром?
Нет, не должно. Вы всё несколько путаете. Значение из onFulfilled должно пойти в следующий onFulfilled. А для этого оно передаётся в текущее (не следующее!) обещание. Это как промежуточное звено. Если Вы про самое первое обещание — там не нужно задействовать поле result, поскольку внутри «рабочей» (как я её условно назвал) функции, переданной в конструктор, resolve и так будет вызван с любыми нужными аргументами напрямую (а это и есть onFulfilled).
Кстати, куда делось требование 2.2.4 стандарта Promises/A+ «onFulfilled or onRejected must not be called until the execution context stack contains only platform code», оно же пункт 25.4.1.8 стандарта ECMAScript 2015
Признаться, полностью стандарт я не изучил :) А Вы не расскажете, почему существует такое требование, и что будет, если его проигнорировать? Про очередь работ (jobs) я мельком читал, но это ведь детали реализации, как именно мы всё это сделаем. Я хочу сказать, что это можно делегировать на отдельный уровень абстракции: создать планировщик потоков, который будет управлять background задачами, в том числе и этими задачами для промисов, а заодно и воркерами, и другими вещами. Пока что ничего этого мой движок не умеет — так к чему заморачиваться. Ведь результат исполнения кода сходится? Детали реализации могут варьироваться, главное, что поведение предсказуемо.
Тут проблема в гонках. Текущий стандарт гарантирует, что вот такой код выполнится корректно независимо от состояния обещаний:
class Foo {
constructor() {
this.a = 5;
this.b = bar().then(x => this.baz());
this.c = 10;
}
}А если вы вызываете onFulfilled синхронно — то продолжение может выполниться раньше чем объект полностью проинициализируется. Причем такой баг может спать в коде очень долго!
Детали реализации могут варьироваться, главное, что поведение предсказуемо.
Но отличается от предписанного стандартом.
Хотя всё-таки не очень понимаю, какой практический смысл ставить обещания в конструктор. Ну да ладно, не мне судить, программист волен писать любой код, который считает нужным.
Давайте просто зайдём с другой стороны: у нас есть функция. Каждая функция в JavaScript (независимо от редакции стандарта) — это объект. Функция может быть вызвана как конструктор. При таком вызове, в числе прочего, у неё принудительно устанавливается this равным объекту, который она вернёт. Сам этот объект создаётся интерпретатором до её запуска (и отдаётся сразу после).
Я просто пытаюсь понять, где здесь гонка: если программист написал в конструкторе обещание, которое исполнится раньше, чем в коде конструктора ниже будет присвоено некое поле объекта — у него в коде обработчика обещания выкинет ошибку Reference Error, и он сам себе злобный Буратино :) Что до объекта this — так он доступен в конструкторе, а значит, доступен и в стрелочной функции в Вашем примере (и будет доступен в обычной, если использовать bind).
Поэтому требование асинхронности во всех случаях ввели в стандарт. А раз оно попало в стандарт — программист уже имеет право на него полагаться.
Нет, асинхронность — это выполнение отдельно от основного (синхронного) кода, и не важно в каком потоке.
промисы отработают гораздо позже, чем могли бы (они ведь вообще на внешний код могут быть не завязаны, например, просто получаем что-то с сервера, парсим, выводим на страницу)
"Гораздо позже" они отработают только в одном случае — если основной поток перегружен вычислительной работой, для чего он попросту не предназначен. Во всех остальных случаях действует правило — от перестановки слагаемых сумма не меняется.
Для того чтобы что-то исполнить раньше — надо что-то исполнить позже! Почему вы отдаете приоритет одному коду перед другим — и считаете что это уменьшит лаги?
Чтобы код не лагал — он должен успевать выполняться за некоторое время. И это время не зависит от того в каком порядке будет выполняться код.
Кстати, мне сегодня в голову пришла очень интересная идея. Мне кажется, главная причина требования исполнения всех промисов после того, как отработает весь синхронный код — это не дать возможность писать вот такой вот сомнительный код. Проблема в другом, я сегодня при модификации кода как раз на неё наткнулся :)
Смотрите, допустим мы создали промис, вызвали метод then. Он добавляет в вектор потомков новый промис (у нас же дерево). И после этого, если у нас состояние уже fulfilled (например, мы вызывали
Promise.resolve()) — мы должны сразу его запустить. И в этом случае, даже если мы выполним добавление в вектор до запуска — у нас потом может идти вызов then через чейнинг уже для того нового промиса. И проблема в том, что он отработает раньше, чем туда что-то будет добавлено. И если в его обработчике onFulfilled произойдёт ошибка, то она не попадёт в обработчик onRejected следующего промиса, потому что следующего у него ещё просто нет (вектор потомков пуст). И она всплывёт наверх.Иными словам, необходимо дать доработать цепочке вызовов then до конца. А это синхронный код. Если этого не сделать — будут не очень приятные последствия.
Вообще, эту проблему можно обойти, вставив в код интерпретатора специальный костыль для выявления этого сценария, но стандарт решает её изящнее и радикальнее.
Ошибка в обработчике никогда не выплывает за пределы обещания.
Или я не прав, что then — это часть синхронного кода, который исполняется в первую очередь?
Да, resolve имеет право произойти раньше, но поведение должно быть предсказуемым. А если бы этого требования в стандарте не было, то поведение могло бы динамически меняться в зависимости от времени исполнения обработчика промиса (я специально привёл пример с ошибкой внутри обработчика для большей наглядности).

Что мы видим? Мы видим 'after', что свидетельствует о том, что строка с resolve().then выполнилась без ошибки. Видим, что наш throw 1 не был никем пойман (uncaught).
Ошибка в обработчике никогда не выплывает за пределы обещания
ЧИТД. Всплыла? Нет. Та же самая картинка если мы швыряем ошибку прямо в new Promise(() => { /* тут */ }.
Мне кажется, главная причина требования исполнения всех промисов после того, как отработает весь синхронный код
Нет. Главная причина очевидна: унификация. Либо всё синхронно, либо всё асинхронно. Естественно выбрали второе (javascript же). Смешанный вариант чрезвычайно багонеустойчив. Уж поверьте, node-js разработчики наелись таких багов просто до отвалу.
Это когда код ломается в тех самых редких случаях, когда он решил выполниться синхронно (какой-нибудь флаг, наличие кеша, да что угодно), а код принимающий на такое рассчитан не был. Состояние гонки возможно даже в однопоточном коде. node-разработчики это хорошо знают. Причём в разных вариантах.
А можно примеры какие-то привести?
const a = {};
api(result => { a.inner.result = result; };
a.inner = anySyncCode();Если api выполнится синхронно всё упадёт. Если асинхронно — не упадёт. И если это зависит от каких-нибудь хитрых неочевидных моментов (да ещё и закопано где-нибудь в глубине stack-trace-а), то выстрельнуть оно может совершенно неожиданно. Может, к примеру, приложение на обе лопатки положить. И анализ stack-trace-а вам особо не поможет, ибо он будет коротким и бесполезным. Здравствуйте часы дебага асинхронного nodejs кода. Бррр.
В данном случае (в примере) очевидно, что можно переписать так, чтобы не падало в любой ситуации. В реальном же коде всё бывает сильно запутанно.
это просто глупость со стороны JS программиста
Я думаю, что мы тут все не особо умные и совершаем ошибки. А ещё ошибки совершают те, чей код мы используем. Особенно если это какой-нибудь вложенный во вложенный во вложенный npm-пакет. Я бы вообще, на вашем месте, да и на своём тоже, воздержался от таких высказываний. Не боги горшки обжигают. Тут порой такую дичь напишешь, особенно если в спешке.
И вообще, я разве где-то говорил, что стандарт плохой? Я просто пытаюсь понять, почему он сделан именно так.
И я нигде не пытался сказать, что лучше смешанный вариант, как писали выше — что то так работает, то этак.
Просто мне видится, что проблема с then-ами, которые не успели назначить обработчики ошибок до того, как ошибка случилась — стали основной причиной, почему в стандарт включили это требование. Можно правда было облегчить его до «не начинать исполнение промисов до завершения обработки цепочки then». Но в итоге решили отложить исполнение всех промисов совсем, пока весь код не отработает. В принципе — наверное, это плюс, then от существующих promise-объектов могут вызываться и ниже в текущей функции, и даже где-нибудь потом, за её пределами. Опять же, это подтверждает верность моей мысли: мы не начинаем исполнять промисы не потому, что нам как авторам стандарта или движка так приспичило, а потому, что мы хотим убедиться, что всё дерево сформировано и на момент начала исполнения не подвергается изменениям.
если бы знал, что в ряде случаев та строчка может выполниться синхронно
Не знали бы. Это бы для вас стало открытием. После 3-х часов дебага.
не начинать исполнение промисов до завершения обработки цепочки then
Вы похоже до сих пор не поняли что такое Promise-ы :) Нет такой стадии "завершение обработки". И быть не может. Точнее может: когда сборщик мусора виртуальной машины выкинет их из памяти. А до тех пор можно повешать свой .then в любую часть цепочку (лишь ссылка туда была). Опять же, это не цепочки. Это деревья. Другая структура данных.
в итоге решили отложить исполнение всех промисов совсем, пока весь код не отработает
что всё дерево сформировано
Это невозможно. Нет такой стадии "сформировано". Никто кроме разработчика не знает когда "весь код отработает". Цепочка начинает отрабатывать просто в рамках event loop. А .then на неё могут вешаться когда угодно и как угодно. Может асинхронно. then может быть повешан после выполнения всего, может в процессе, может до.
Опять же, это не цепочки. Это деревья. Другая структура данных.
Да я это уже понял. Я цепочку вызовов через точку имел в виду, единую строку кода как выражение)
Нет такой стадии «завершение обработки». И быть не может.
Опять же, я писал про завершение интерпретации строки кода с цепочкой вызовов then. такая стадия — не только может быть, но и есть, и на ней можно даже что-то сделать (если мы не говорим про JIT компиляцию, у меня всё-таки интерпретатор обычный).
Цепочка начинает отрабатывать просто в рамках event loop
Поскольку в моём движке пока нет event loop — то это будет просто отдельная стадия, которая вызовется, когда весь скрипт исполнен :)
А .then на неё могут вешаться когда угодно и как угодно. Может асинхронно. then может быть повешан после выполнения всего, может в процессе, может до.
Спасибо за уточнение. В принципе, технически и правда никто не мешает использовать then уже в коде обработчиков наших промисов, или функций, который они вызовут, при наличии ссылок. Просто я думал, что такой вариант не очень желателен, но если это норма — тем лучше.
then может быть повешан после выполнения всего, может в процессе, может до.
Так в том-то и дело: он может быть вызван до, но исполнение начинать ещё нельзя. То есть мы делим нашу интерпретацию на две стадии: основной поток исполнения, и потом исполнение промисов. Если я правильно понял вообще тот пункт из стандарта в том виде, в котором его привели… Есть кстати ещё таймеры, которые в отдельном потоке исполняются, и обработчики событий (в других движках). Но эти потоки работают параллельно с основным. А вот поток исполнения очереди промисов — как я понял, ждёт завершения работы основного потока. Поправьте, если я не прав.
но если это норма — тем лучше.
Да. Это норма. Промисы хороши тем, что нет резона суетиться по поводу его статуса. Он если данные есть уже готовые отработает в следующем тике. Если нет, то когда появятся. В итоге мы полностью отвязаны от внутренней кухни того, что там в этом промисе происходит. Оно просто работает. Как ему там взбрендится. А мы полагаемся на задокументированное поведение и не боимся, что оно в какой-то момент подкинет сюрприз.
В nodeJS мы не может взять и застопорить весь поток (точнее можем, но за это больно бьют, здесь так нельзя). И ситуация "вчера это могло работать синхронно" легко превращается в "ох, у меня тут теперь сплошные await-ы". Если изначально предполагать такую возможность и всё покрыть promise-like-кодом, то всё будет работать как часы несмотря на внутреннюю реализацию.
Кроме того, Вы ведь сейчас говорите про нативные потоки? А я про логические. Попробуйте в отладчике поставить точку остановки в какой-то функции, и ещё одну в функции, повешенной на таймаут, скажем, в 1000-1500 мс. В итоге Вас прямо в процессе отладки перекинет совсем в другое место, там будет другая функция и другой стек вызовов. Вызов таких отложенных функций, как и вызов хендлеров событий, движок производит время от времени, в некоторые слайсы времени, и это определяет его внутренний планировщик. Можно называть это event-loop, а я для простоты называю это отдельными потоками.
На самом деле, в браузере всё ещё веселее — там «основного» потока нет. Потому что то, что происходит при загрузке страницы — это код, вызванный из обработчика события onload. Это в моём движке есть некий «основной» поток, исполняющий код, переданный на вход :)
Попробуйте в отладчике поставить точку остановки в какой-то функции, и ещё одну в функции, повешенной на таймаут, скажем, в 1000-1500 мс. В итоге Вас прямо в процессе отладки перекинет совсем в другое место, там будет другая функция и другой стек вызовов.
Вот как раз этого в Javascript не бывает. Новый Job не может начать выполняться пока старый не закончился.
Опять же, реализация метода then какая-то странная. Вы вообще в курсе, что в Javascript у одного и того же обещания можно вызвать метод then два раза, и это не будет цепочкой?
Ваш пример нисколько не противоречит статье. Смотрите, Вы создали промис (без основной функции и вообще без new, через Promise.resolve). Он у вас сразу перешёл в fulfilled
состояние. Вы вызвали then — ваша функция сразу исполнилась, а состояние промиса не поменялось. Вы снова вызвали then — но состояние у нас всё ещё fulfilled, и поток исполнения опять пойдёт в первый if. Вот если бы у нас в этом случае создался новый промис в цепочке -тогда было бы плохо, так как у него сразу же вызвался бы метод then, но состояние так и зависло бы в pending.
А Ваш последний пример — это и есть чейнинг. Вы передали результат из первого onFulfilled во второй. Что и требуется по стандарту.
А Ваш последний пример — это и есть чейнинг. Вы передали результат из первого onFulfilled во второй. Что и требуется по стандарту.
Нет! Вы же возвращаете this — а значит, никакого чайнинга не получится, четвертый вызов then пойдет по тому же самому пути что и первые три.
Более того, у вас все 4 вызова выведут на консоль undefined — потому что значение, которое было передано в resolve, нигде не используется...
Окей, в целом согласен. Претензия значит была не к тому, что у меня чейнинг не к месту, а наоборот, к тому, что он не работает, где должен работать :) Но:
1) В примере выше Вы передаёте моментально исполняющиеся функции. При передаче первой же функции, которая вернёт Promise сама, чейнинг начнёт работать. В целом если наши функции исполняются моментально, а состояние у нас fulfilled — то какая разница, делать чейнинг или не делать?
2) Да, и это довольно печально. С другой стороны, так вышло ровно потому, что в момент вызова resolve у нас был стандартный хендлер, а ему пофиг на переданные аргументы. Он поменял состояние объекта и всё. Потом мы вызвали then, установили новый хендлер, но аргумент уже потерян. Не знаю, как часто в жизни используется такой код, делающий моментальный resolve, но стандарт здесь явно нарушен, да.
Замените Promise.resolve(5) на new Promise(resolve => setTimeout(resolve, 0, 5)) — тоже будет проблема.
Не знаю, как часто в жизни используется такой код, делающий моментальный resolve, но стандарт здесь явно нарушен, да.
Очень часто. Это один из паттернов работы с обещаниями.
Кроме того, не забывайте, у вас есть вот такой код:
((Promise)result).then(next.onFulfilled, next.onRejected);В этот момент result запросто может быть уже выполнено, и у вас будет та же проблема.
Замените Promise.resolve(5) на new Promise(resolve => setTimeout(resolve, 0, 5)) — тоже будет проблема.
Вы про то, что задержка нулевая? А, ну в этом плане да. И правда баг очень глупый. Но хотя бы обработчик будет выполнен))
Смысл в том, чтобы протестировать другую ветку кода. Вместо 0 можно записать любое другое число — от этого ничего не должно поменяться, кроме времени выполнения теста.
Должно быть 5, 5, 5, 10 с точностью до порядка. А получится фигня какая-то.
А, вы про это. Я говорил про ваш код. Он выполнит продолжения с неправильными аргументами.
Что же до Promise.resolve(...) — он часто используется для того чтобы отловить синхронную ошибку и обработать ее так же как асинхронную:
// Неправильно
foo()
.then(bar)
.catch(baz); // Поймает ошибку в bar - но не поймает в foo!
// Правильно
Promise.resolve()
.then(foo)
.then(bar)
.catch(baz); // Поймает все ошибкиnew Promise(function() { throw "Error"; })
.catch(function(e) { console.log(e) })
Я думаю, что имелось ввиду, что если foo внутри себя имеет где-нибудь return promise (от которого потом можно сделать .then()), но упадёт ещё в процессе, то никакой catch вызван не будет. Почему не будет? А почему должен? Ведь вызов foo() это просто вызов какой-то функции. Она может вообще к promise-ам никакого отношения не иметь. А может иметь. А может упасть в процессе выполнения.
А вот положенные внутрь .then() методы выполняются внутри try catch и их ошибки уже отлавливаются.
Нельзя вызвать foo() как new Promise(foo) если foo — это обычная асинхронная функция которая возвращает обещание.
А вот как Promise.resolve().then(foo) ее вызвать можно!
Для new Promise(fn) сигнатура: fn(resolve, reject). В то время как в .then(fn) можно передать любую вообще функцию. И сигнатура у неё уже будет fn(resultOfPrev), никаких resolve и reject. Точнее там даже .then(successFn, failureFn). И если наша fn не может быть выполнена синхронно, то она должна вернуть новый promise, который она должна создать уже самостоятельно и вернуть его в return. Если эта наша fn является async fn, то этим займётся сам интерпретатор языка. Помимо прочего, если нам не нужно делать никаких асинхронных запросов, то мы можем сразу в этой fn вернуть нужный результат. Например:
.then(prev =>
{
if(some(prev))
return 42;
else return new Promise((resolve, reject) => { /* ... */ });
})Следующая функция в цепочке-древе получит либо 42 либо результат от new Promise. Такая вот автоматика. Удобно.
И если наша fn не может быть выполнена синхронно, то она должна вернуть новый promise, который она должна создать уже самостоятельно и вернуть его в return
Ну да, я про это знаю) Всё правильно.
Если эта наша fn является async fn, то этим займётся сам интерпретатор языка.
А вот про эту возможность не знал, надо будет почитать, что это и как оно работает.
Асинхронная функция в широком смысле — это любая функция которая совершает асинхронную операцию.
В более узком смысле асинхронная функция — это функция которая возвращает обещание.
Конструктор new Promise предназначен для создания базовых асинхронных функций или для перехода от кода на колбеках к коду на обещаниях — т.н. "промисификации".
Составные же асинхронные функции так не делаются. Вместо этого используется один из двух подходов:
- создание цепочек методами .then и .catch;
- использование механизма async/await.
Ну вот кстати про этот механизм в той же статье было сказано, что он потерял свою актуальность
Какой? async-await oO? Скорее вытеснил ручную работу с promise на далёкие окраины.
Насчёт цитаты — я перепутал, там сравнение с генераторами было, а не с промисами :)
Возможно вам поможет эта старая статья.
Мы встретили здесь новый метод — Promise.resolve. Он создает промис, который будет выполнен в любом случае, вне зависимости от значений, ему переданных. Если вы передадите ему нечто промисообразное (имеющее метод then), будет создан новый промис, который выполнится или будет отклонен, так же, как и начальный промис.
Означает ли это, что движок должен непрерывно мониторить состояние такого объекта — ведь неизвестно, когда оно может смениться, если оно на момент передачи pending?
Когда мы прерываем выполнение промиса, spawn ждет выполнения промиса и возвращает окончательное значение. Если промис отклонен, точка выхода (yield) выбрасывает исключение, которое мы можем поймать в блоке try/catch
Возможно, кривой перевод, но я здесь практически не понял ничего в этом абзаце. yield вернёт промис, потому что за ним стоит вызов функции, возвращающей промис. Каким образом он кинет нам исключение? Имеется в виду то исключение, что возникло в функции промиса getJSON и не было поймано там же? Если так, то да, но имхо если мы хотим подробный вывод ошибки в консоль, логичнее такое ловить на месте. Хотя стек вызова мы и так получим)
Мне кажется, что 99.9% пишут как раз foo().then(). Проще и нагляднее, а try-catch уровнем выше какой-нибудь итак лежит. Но да, когда-нибудь кому-нибудь это сильно аукнется (и я буду в первых рядах :D). Кстати, если foo сделан через async, то проблемы нет. Сейчас async это скорее правило, нежели исключение (имхо).
Проблема обычно именно с тем чтобы отловить ошибки именно в отложенных сценариях, а не в синхронных. Например какое-нибудь не promise-api какой-нибудь библиотеки с callback-ом. Это когда нотация для callback-а такая: fn(error, result). И вот если ошибка не была в той библиотеке отловлена и помещена в этот error, то ошибка просто падает и никем не отлавливается. А отлавливаются только те ошибки, которые автором библиотеки были отловлены целенаправленно. Но он же (автор), наверное, не идеален…
А вот стандартно написанный код поверх async-await от таких проблем обычно спасает. Ты что-то протупил, непредусмотрел, но т.к. try-catch "из коробки", а проброс ошибок встроен в promise-систему, то трагедии не будет.
Но самое главное, чем мне кажется текущий подход лучше — это тем, что следующего промиса в цепочке может просто не быть. А формальное значение всегда пригодится для интерпретатора, чтобы куда-нибудь его вывести (так же, как сейчас для блока кода return value — это ни что иное как return value последнего исполненного выражения в нём). То есть результатом работы промиса (его значением) будем считать результат работы сработавшего хэндлера, как-то так.

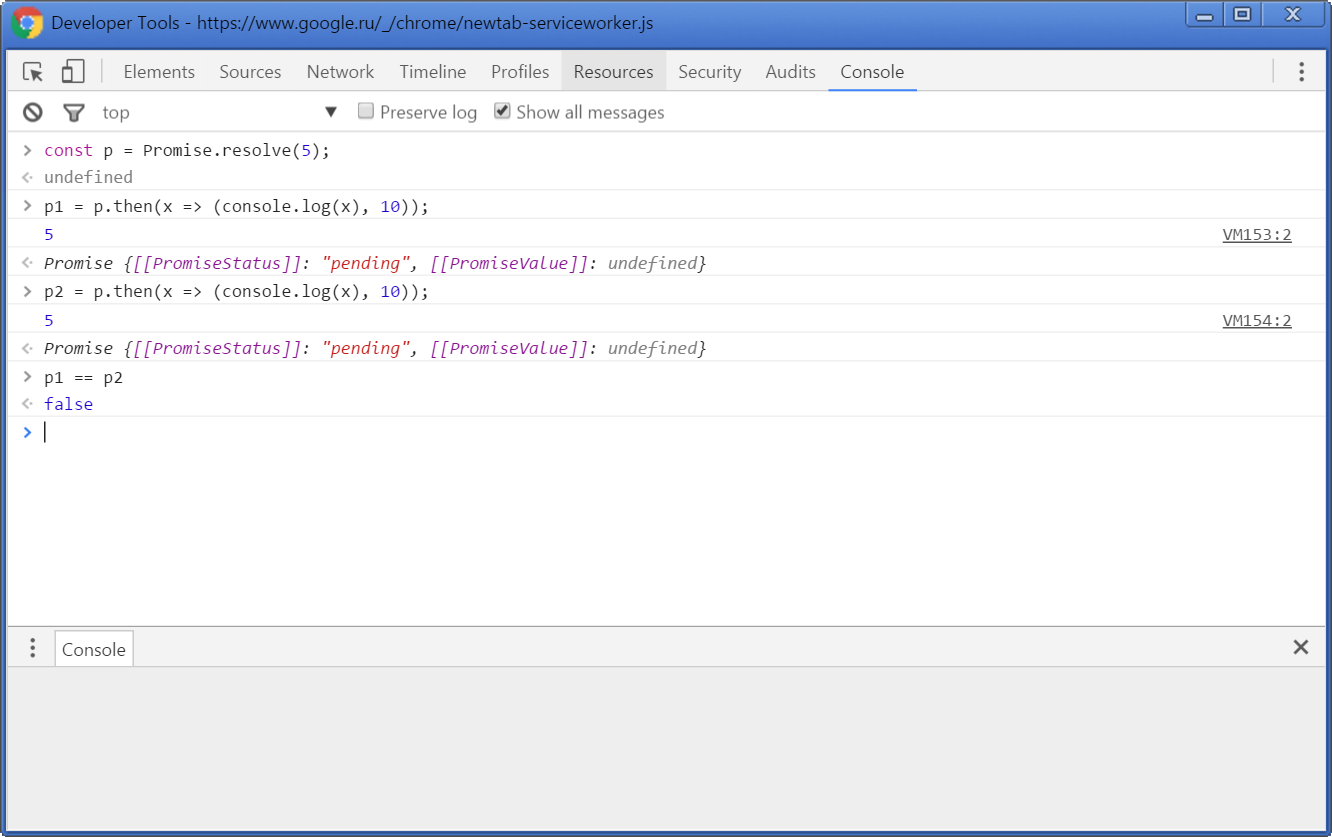
Видите, у нас при вызове then создаются новые промисы, причём при каждом новом вызове они разные.
Другое дело, что они не цепляются в цепочку к исходному промису «намертво», иначе обработчик не отрабатывал бы. Они как бы создаются и всё.
Так что у меня и правда ошибка в логике: если у нас идёт вызов then и следующий промис установлен, мы не имеем права вызывать then от него, мы должны его заменить на новый. А вызов then(...).then(...) будет работать всё равно правильно потому, что там промис возвращается дочерний, а не текущий.
Почему это неправы оказали мы оба? Вы правда думаете что я свой пример в консоль Хрома не копировал? :-)
Вы вообще в курсе, что в Javascript у одного и того же обещания можно вызвать метод then два раза, и это не будет цепочкой?
Но подождите, если Вы его копировали, Вы же должны были видеть, что создаётся новый промис. Что это по-вашему, если не цепочка?
Это две цепочки. Более строго, ожидающие обещания образуют не цепочки, а деревья.
С точки зрения кода — это ведь линейная цепь вызовов then и catch.
Где вы видите тут линейную цепь вызовов?
p.then(... /* 1 */);
p.then(... /* 2 */).then(... /* 3 */);
p.then(... /* 4 */);Порядок вызовов важен! Значение p должно попасть в обработчики 1, 2 и 4, значение которое вернул обработчик 2 — должно попасть в обработчик 3.
Но как по мне — это излишнее усложнение… Можно было сделать принудительное приведение к линейному списку, как у меня. Тем более, в статье Ильи Кантора, которую я читал (она правда совсем для новичков), этот момент не был освещён. Надеюсь, хоть автор про него знал :)
Но как по мне — это излишнее усложнение… Можно было сделать принудительное приведение к линейному списку, как у меня
Ну и кому они были бы нужны в таком виде? Поверьте и то, что .then создаёт деревья, а не продолжение списка, и то, что оно всегда отрабатывает асинхронно ― очень правильные архитектурные решения. Вы это достаточно быстро поймёте если будете писать много promise-js кода.
Ваше "упрощение" нарушает абстракцию.
Смысл обещаний — в том, что они ведут себя как значения: их можно передавать из метода в метод, сохранять где-нибудь, или забывать. Важно, что чтобы ни происходило с обещанием — на него это уже никак не повлияет, если есть обещание — всегда можно вызвать у него метод then и асинхронно получить лежащее в нем значение, независимо от того сколько раз этот метод уже вызывался.
Кстати, по поводу статей Ильи Кантора и подобных… Они хороши для тех кто использует обещания, а не для тех кто их делает.
Первую же свою реализацию обещаний проще всего писать непосредственно по спецификации: http://www.ecma-international.org/ecma-262/6.0/#sec-promise-constructor
Там уже описаны все структуры данных и все алгоритмы над ними, надо лишь аккуратно перенести это все в код.
Что же до приспособления этого механизма для Java — в Java давно уже есть CompletableFuture
Честно, тоже ожидал это в статье встретить. Ждем комментария автора.
Могу ещё добавить что до 8й джавы была существовала Google Guava, в которой есть ListenableFuture со схожей семантикой.
Реализуем промисы на Java