Comments 389
— Пора уже перейти на C++ и выкинуть всю эту допотопную C дичь.
— Пора уже перейти на Java/.Net и выкинуть всю эту допотопную дичь.
— Пора уже перейти на Go и выкинуть всю эту допотопную дичь.
Пора уже перейти на Rust и выкинуть всю эту допотопную дичь.© Hedgar2018 — Full-stack Golang & JS developer
Никогда такого не было — и вот опять! Когда на haskell переходить будем с этой допотопной дичи?
2. Стабильный
3. Развивается
4. Структурирован (Сокращает количество ошибок)
5. Мультиплатформенный
6. Общего назначения
Asm — переросли, С — переросли, С++ — переросли, Java/С# медленно и перерастаем… Go отличный кандидат на следующий уровень.
P.S. Да, я на всем перечисленном писал. :)
1. Непродуманный и устаревший синтаксис языка, провоцирующий быдлокод
2. Непоследовательная и плохая стандартная библиотека
3. Плохой менеджер пакетов
Что провоцирует на «быдлокод»?
Что в ней плохого и непоследовательного?
Менеджер пакетов (наверное имеется ввиду менеджер зависимостей) штатный — просто очень удобный по сравнению с Java/C#. Да, есть и лучше, но ни кто не ограничивает их использование.
Хотелось бы пример языка общего назначения с идеальным менеджером (штатным) и лучшей стандартной библиотекой.
Менеджер пакетов (наверное имеется ввиду менеджер зависимостей) штатный — просто очень удобный по сравнению с Java/C#.
По пунктам можно?
На самом деле, я уверен, что большинство аргументов вам знакомы и вы просто хотите в очередной раз похоливарить на эту тему.
Тем не менее я вам отвечу. Отсутствие Дженериков приводит к необходимости копипастить, использовать грязные хаки, делать кодогенерацию, которая ухудшает поддержку. Тот же парсинг JSON из-за этого выглядит как сущая магия. Пример непоследовательности библиотеки — это парсинг JSON и пакет flag, которые заточены на похожую задачу, но выполняют ее настолько кардинально разными способами, насколько можно было придумать. Ну вот что мешало сделать парсинг флагов через теги, как уже сделан парсинг JSON? Только понты.
Из-за странного запрета циклической зависимости многие люди просто пишут весь код приложения в одном пакете. Да, иногда это плохая практика, а иногда — необходимость. Отвратительная работа с ошибками, которая стала уже мемом.
Прекрасный пример ущербности языка Go — это теги. Как можно было придумать такое неюзабельное говно в 21-м веке я вообще не представляю.
Менеджер пакетов недавно обсуждали, пришли к выводу, что стандартный настолько плох, что им никто не пользуется.
С — переросли
Теперь скажите это Линусу. Или любителям микроконтроллеров. Пока что это всё ещё язык по умолчанию, который есть везде.
С++ — переросли
Вот когда всё плюсовое наследие превратится в фортрановое наследие, а в индустрии будет доминировать условный Rust — тогда поговорим. Потенциал есть, интересные языки есть, но пока и близко к цели не приблизились. Условный D революцию 10 лет обещал. От некогда доминирующих всё и вся плюсов отвалилась куча ниш, да, но и у плюсов осталось достаточно.
Java/С# медленно и перерастаем
Не наблюдаю. Весь кровавый интерпрайз там, и особых претензий к платформам JVM и .NET нет. Более того, если посмотреть на статистику опроса Stack Overflow, то .NET Core куда-то там вырывается. Не понимаю, почему, но факт.
Весь кровавый интерпрайз тамА кроме энтерпрайза сейчас 95% геймдева — это один из трех языков: C++, C# или JS.
Сам не так давно вынужден был на asm под ARM кодить. Но это не значит что это тренд…
А что такое "тренд"? В любом Мухосранске можно найти работу по любому из "нетрендовых" языков, а вот найдёте ли по "трендовым" — ещё большой вопрос. И эти языки пользуются спросом на протяжении десятилетий, пока "тренды" с условными руби приходят и уходят. Что-то из "трендов" абсорбируется в "нетренд", и "нетренд" опять побеждает.
У некоторых есть основные проекты «нетренд» и дополнительные, в которых инструментарий не лимитируется.
А вообще по ответам, к сожалению, тенденция всех форумов прослеживается и тут. Только в 1 ответе было показано с примерами что человеку нравится С++. Остальные просто ругают то что не пробовали или вообще, просто, ругают, при этом не говорят где лучше.
Грустно все это, ну да ладно. У каждого свой путь самовыражения.
C++ — это круто, и в современном языке можно выделить разумное красивое подмножество. Проблема в том, что подмножество у всех своё, стадия эволюции у всех своя, компиляторы у всех свои, и вообще чёрт ногу сломит.
Вот сделают модули. Может быть. Через пару лет. Ещё через несколько лет они будут поддерживаться компиляторами. Казалось бы, вот оно счастье. Но как быстро я смогу не знать про инклюды?
И вот так с каждой фичей.
Здесь же уже постили недавно:
- https://habrahabr.ru/post/344356/
- http://nomad.uk.net/articles/why-gos-design-is-a-disservice-to-intelligent-programmers.html
- https://news.ycombinator.com/item?id=9266184
Go позиционируется как простой язык, который может за вечер изучить любой школьник. Это как взять Java и довести многословность до абсурда под лозунгом "так проще". Я бы не строил карьеру вокруг этой идеи. Когда вокруг "простых языков" начинают строить сложную индустрию, получаются франкенштейны.
В конечном счёте это ИМХО, конечно.
Чтобы понять, что мне не подходит Go, мне не надо много программировать на Go. Мне достаточно увидеть, какие решения предлагаются на замену исключениям, дженерикам и прочему, посмотреть на разнообразные исходники, чтобы понять, что я так писать не хочу. Всё.
Точно так же я не хочу писать обфусцированный код на CoffeeScript, вермишель из колбэков на JavaScript или ещё что-то подобное.
У меня есть выбор. У меня есть определённые критерии к эстетическим свойствам кода, который я пишу, и краткость, выразительность и наглядность далеко не на последнем месте. Мне не надо писать много кода на языке, чтобы понять, что он меня не устраивает.
Прежде, чем писать на JavaScript вермишель из колбэков, я лучше спокойно посижу в сторонке и подожду, когда в язык добавят async/await и классы. Что, уже добавили? Ну, теперь язык для меня подходит.
И даже если я не люблю какой-то синтаксис (LISP), я могу понять эстетику и мощь, которые скрываются за бесконечными скобочками. У лиспов есть внутренняя красота, в них вложен инженерный гений, даже если язык мне не нравится и я не собираюсь на нём писать.
Что красивого в Go — я не понимаю. Может быть, вы объясните?
Дженерик — а оно правда необходимо?
1. Это тормозит во всех языках. Не тормозит только при условии кодогенерации. Но именно такая возможность заложена в Go. Просто ее надо вызывать более осмысленно.
2. Парадигма Go — простота. Использование дженериков ведет к усложнению кода. Потенциально есть возможность использовать нечто очень похожее используя интерфейсы и контейнеры, но, опять же, это усложнение.
Async/await — Классический костыль для синхронизации.
В Go используются горутины и общаются они через каналы. Этот костыль просто не нужен при правильном построении программы.
Вермишели из коллбеков вроде тоже нет…
Вообще, на Go как и на многих языках, нельзя писать «как я раньше писал на @@@» (@@@ замените на ваш любимый язык). Надо понять принципы, идеологию, и все станет сильно проще.
А что для вас язык с идеальным синтаксисом?
Дженерик — а оно правда необходимо?В .NET — кодогенерация. Шаблоны в c++ — кодогенерация. Дженерики сделаны для скорости, ну и для проверки типов во время разработки.
1. Это тормозит во всех языках. Не тормозит только при условии кодогенерации.
Парадигма Go — простота. Использование дженериков ведет к усложнению кода
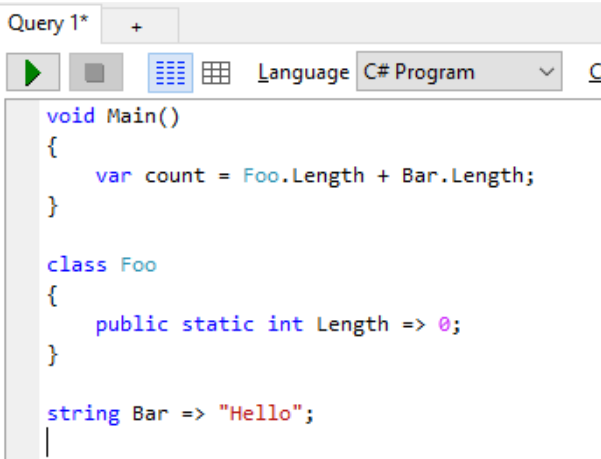
То есть
```go
var identity types.Identity
var err = json.NewDecoder(json).Decode(&identity)
```
Это быстро и просто?
```cs
var identity = JsonConvert.DeserializeObject(json);
```
А это — медленно и сложно?
Использование дженериков, очевидно, ведет к упрощению кода, а не усложнению. Хватит повторять библию Гошников. Есть куча примеров, где отсутствие дженериков ведет или к отсутствию статики или к копипасту.
То что я писал выше — основывается на моем скромном опыте Go. Про «библию» был не в курсе.
Конкретных примеров как в одну сторону так и в другую можно найти массу.
Например я с содроганием вспоминаю как писал в одном из проектов template of template с лямбдами внутри на C++. И там это было обосновано. А потом, через год примерно, отлаживал это.
Так что каждый ищет проблемы соразмерные своей пятой точке в независимости от используемого языка :)
Дженерики уже до предела упрощены.
Конкретных примеров как в одну сторону так и в другую можно найти массуНо это ведь вы категорично заявили, без дополнительных «если»:
Использование дженериков ведет к усложнению кода
Неиспользование дженериков, кроме как из базовых типов, приводит к еще большему усложнению кода.
Про генераторы не надо… Доводилось это "добро" писать и поддерживать.
Async/await — Классический костыль для синхронизации.
В Go используются горутины и общаются они через каналы.
И чем goroutine от async/await принципиально отличается? Те же яйца, только в профиль: потроха разные, диапазон функций разный, синтаксис разный, но суть одна — написание асинхронного кода как синхронного. Что у авторов Go была возможность внедрить асинхронность в язык с самого начала — это хорошо, но async/await в остальных языках — тоже нормальное решение, причём ещё и более гибкое.
А что для вас язык с идеальным синтаксисом?
Из универсального мейнстрима — C# вне конкуренции по сахару. Из того, что я видел, но на чём сам не писал — Haskell. Из того, что теоретически идеально, но я использовать не буду — LISP.
И чем goroutine от async/await принципиально отличается?
Принципиальное отличие: async/await — синтаксический сахар над колбэками (stackless реализация), а горутины — над волокнами (stackfull userspace multithreading).
То есть горутины не только выглядят как синхронные, они и внутри тоже синхронные. Просто планировщик из пространства ядра перенесён в юзерспейс, что значительно сокращает накладные расходы на переключение контекста.
При нормальной реализации оба способа имеют право на жизнь, и асинхронный код выглядит одинаково и работает одинаково за исключением нюансов, связанных со стэком и отладкой.
Почему?
Кроме того, там есть возможность расширения, которая позволяет добавить все что нужно самому (привет тем, кто ждет годами новой версии стандарта или новых фич).
И что из них заменяет выразительную систему типов?
На мой взгляд (я не претендую на правоту) макросы лиспа — это совершенно иной подход к выразительности, по мощности не уступающий системе типов.
как-то лучше пользоваться языками, где это из коробки.
Не сказал бы. За возможность запилить без титанических усилий async/await или горутины или еще какие штуки любители этих штук отдали бы многое. Полагаю, как минимум из-за любви к тому, что выдается в коробке они сидят на игле своих языков. Как насчет получить в коробке кухню и попробовать самому готовить? В коробке там тоже много чего есть, если что…
Я не уверен, что макросы это могут заменить хоть в каком-то виде.
А они это не заменяют. Они работают над выразительностью совершенно другим путем.
Чем выразительнее система типов, тем больше всяких полезных инвариантов и свойств вы можете гарантировать статически.
Это верно. Но интересно то, что мы не обязаны сосредотачиваться исключительно на задаче получения статических гарантий инвариантов. Есть и другие подходы, чтобы сделать что-то интересное и полезное
Хаскелевский TH — мощнейшая штука, равно как и идрисовский элаборатор/рефлектор (но с ним я пока ещё не игрался).
Я обязательно изучу и это тоже. Мне нравится рассматривать разные подходы и разные задачи
Вопрос создания интересного и полезного — это совершенно ортогональная верифицируемости штука.
Верификация возможна и без статической системы типов (да, это так, можно верифицировать например control-flow).
А вообще, это уже звучит как hujak-hujak-production-driven development.
Верификация, как и другие подходы, нужна для того чтобы делать что-то интересное и полезное. Не вижу причин называть плохими словами все неизвестное
blog.racket-lang.org/2017/11/adding-refinement-types.html
> И что из них заменяет выразительную систему типов?
Система типов — костыль для языков, в которых нет мощной макросистемы.
> Я не уверен, что макросы это могут заменить хоть в каком-то виде.
Типы по ссылке выше написаны именно на макросах. Более того — там есть макробиблиотека, которая позволяет легко писать свои системы типов и на ходу их расширять (добавлять свои семантические правила). Например, захотели добавить type families — а это просто обычная языковая библиотека, которую может написать кто угодно и которая подключается как любая другая библиотека в конкретный модуль (в разных модулях, с-но, можно иметь разные системы типов). Разве не замечательно?
> Хаскелевский TH — мощнейшая штука
Хаскелевский TH лучше убить не вспоминать. Лучше вообще не иметь макросистемы, чем иметь плохую (то же, кстати, для типов верно — лучше вообще системы типов не иметь, чем иметь плохую).
Система типов — костыль для языков, в которых нет мощной макросистемы.
Наверное вы имели ввиду "встроенные системы типов"?
Типы по ссылке выше написаны именно на макросах. Более того — там есть макробиблиотека, которая позволяет легко писать свои системы
Возможно, это круто, если вы можете выбирать себе мирок, где живут клёвые чуваки, обладающие развитым абстрактным мышлением (типа отдельной фирмешечки с узкой и глубокой задачей). А вот если это дать в руки среднестатистическому кодеру, то настанет хаос и вам и мне придется бороться с уродцами-порождениями этого хаоса.
Как по мне, LISP — это такой ассемблер, у которого в cons-парах может лежать что угодно, как в регистре EAX в x86-ассемблере — хоть число, хоть объект любого типа (указатель). Другое сходство с асмом — что любой кусок памяти можно интерпретировать как исполняемый код и запустить. В LISP-е с этим так же хорошо.
Когда я думаю, какую бы идеальную аппаратную архитектуру я бы хотел иметь, то мне видится именно LISP-машина в минимальном варианте, без CLOS, макросов и типов. А высокоуровневые языки вводили бы свои фичи поверх этого и компилировались бы в LISP-код.
Писать на ассемблере очень круто, особенно с макросами (помню, в конце 90-х в ассемблерах чуть ли не if-while-switch делали макросами, и писали, утверждая, что это по простоте кодирования ничуть не уступает другим языкам). Но со временем хочется чего-то другого.
Я полагал, это понятно из контекста. Как видно — верно полагал.
> А вот если это дать в руки среднестатистическому кодеру
Этому вашему «среднестатистическому кодеру» сложные системы типов в руки в принципе давать нельзя.
> настанет хаос и вам и мне придется бороться с уродцами-порождениями этого хаоса.
Ну вот в хаскеле есть зоопарк расширений и ничего, никто не борется. И было бы гораздо лучше, если бы эти расширения были библиотеками языка, а не плагинами компилятора.
Ну вот в хаскеле есть зоопарк расширений и ничего, никто не борется.
На хаскелле порог вхождения и задачи отличаются от таковых для жабы, ИМХО
Ну так и?
> Да, это хорошо, но зачем делать из Racket Idris, если можно сразу взять Idris?
Racket выразительнее и удобнее. Алсо, там зависимые типы пытаются делать «практико-ориентированные», а не как в идрисе.
> Я не понимаю, как макросистема сама по себе заменяет систему типов.
Она дает возможность цеплять к термам некие данные, и проверять эти данные в термах, подтермами которых являются данные термы. Вообще говоря, при наличии макросистемы для получения статических гарантий вам типы и не нужны. Вы можете реализовать их «напрямую» и проверять любые требуемые инварианты. При этом на этапе проверки у вас есть вся мощь хост-языка -вам не приходится изворачиваться ужом и кодировать эти инварианты в кривом, не предназначенном для подобных задач type-level языке.
> Вот как раз систему типов вообще и тайпчекер в частности (по сравнению с интерполяцией строк какой-нибудь) лучше иметь в ядре языка
Это будет криво и нерасширяемо. Как мы и имеем на практике.
> А я вас ещё с прошлой дискуссии за хаскель помню, я тогда ещё решил, что после вашего утверждения, что хаскель не поддерживает
Но ведь и вправду не поддерживает. Точно в той же мере, в которой, например, js не поддерживает упомянутые зависимые типы. Вы, например, _можете_ использовать js с зависимыми типами (точно также как и в случае определений в хаскеле), язык это формально позволяет. Но делает все, чтобы вы этого не делали.
И? Я не понимаю, к чему вы ведете. Можете полностью как-то цепочку логическую изложить, и указать, чем она должна закончиться? Я из намеков понять не могу, слишком туманно.
> В языке с изначальной поддержкой завтипов (тот же идрис, агда) у вас нет какого-то отдельного type-level-языка.
Вообще-то есть. Еще раз — вы не можете в идрисе написать что-то вроде: «вот этот терм ассоциирован с данными Х, этот с данными Y, а конструкция R добавляет данные Z к терму T в том случае, если X и Y удовлетворяют P»
> Можете пояснить примером?
Там же по ссылке есть пример. Можно просто взять, и написать vector-ref, который проверяет, что индекс не выходит за границы массива. Просто обычным предикатом.
> И в чём нерасширяемость при наличии, например, идрисовского рефлекшона?
Вы не можете в идрисе добавить свои семантические правила.
> Как?
В точности так же, как в вашем примере выше хаскель позволяет писать на отдельных строках. Добавляете ваши типы в комментариях и проверяете руками. Неудобно и вырвиглазно? Именно!
Но вас же никто не заставляет использовать несовместимые. Какие хотите — такие и берете.
> Что значит ассоциирован
То и значит. В прямом смысле.
> что вы называете данными
Данными я называю данные. Любые. У тайпчекера эти данные — это тип терма, частный случай.
> Так кто в идрисе мешает?
Ну, система типов мешает. Не допускает она таких вольностей.
> Но да, нужно будет доказательство:
Так в этом и дело. Вместо того, чтобы просто описать требуемый инвариант в виде предиката, вам приходится его кодировать, причем достаточно нетривиальным способом.
> Могу.
По вашей ссылке ничего нет такого. Может, я не заметил, точнее укажите.
Async/await — Классический костыль для синхронизации.
В Go используются горутины и общаются они через каналы. Этот костыль просто не нужен при правильном построении программы.
Так async/await по сути и есть более удобный синтаксис корутин/горутин/сопроцедур, что есть одно и то же. Тем более, что вообще C# поддерживал в некотором роде сопроцедуры ещё с версии 2.0, когда появилось слово yeild и итераторы. Это уже позволяло (пусть и не так удобно) писать корутины и получать всю прелесть, что сейчас есть с async/await. Так что в этом плане горутины не новость.
Аналогично и слово yeild. Только там генерируется класс, который, по мере надобности, возвращает результат и имеет внутреннюю стейт машину.
В отличии от этих методов горутины это реальные параллельные потоки. Да, количество реально параллельных потоков соотносится с количеством ядер процессора. Но все равно они параллельны.
Тем не менее, что за «линейные относительно процессора вызовы» вы имеете ввиду я так и не понял. async/await разворачиваются в типичную цепочку a.then(b).then©, которая планировщиком где-то выполняется.
На сколько помню, все вызовы будут вполне линейны с точки зрения процессора
Вы неправильно помните. await выделяет весь код после него в continuation, который кладется на планировщик и может быть выполнен где угодно.
Горутины ведь тоже синтаксический сахар, превращённый в killer-фичу языка. Async/await является удобной и приятной штукой, но он не гарантирует исполнение на другом потоке, также как и yeild, но в последнем случае нам приходится больше писать самим и мы можем подготовить свой класс Awaiter'а, который всегда будет делать новый поток как только мы напишем yeild return Yeild.RunAsync(...). Но чего об этом спорить — это всего лишь сахар — кто-то любит крепкий чай, а кто-то послаще :)
Лениться делегировать — это экономия на спичках. Больше огребётесь от огромного количества наследников.
Наследование это не способ писать меньше кода. Это способ выразить отношение is-a (ну и ещё способ сделать discriminated union, в языках где его нет). Более того, я считаю что наследование как раз более вредно — чем чаще вы наследуете, тем более костной становится ваша система.
Примеры:
У вас есть базовый класс, который часто наследуется в вашей системе. Затем, только некоторому числу наследников понадобилось новое поведение — вы меняете базовый класс, но вместе с этим вы также меняете и контракт тех классов, которым это поведение не нужно. Как итог, вам нужно протестировать те компоненты, которые даже не менялись — нарушение OCP. А ещё частенько ведёт и к нарушению LSP.
В укор первому примеру, вы можете сказать — "да я щас наделаю много мелких классов (например, VisibleAndSolid, VisibleAndMovable, VisibleAndSolidAndMovable) с точечным поведением и буду множественно наследовать от них". Ок, но чего вы этим сэкономите? Количество LOC будет примерно сравнимым при композиции. Только в этот раз вы усложнили систему, наделав в ней кучу ненужных сущностей.
Имея некоторый базовый класс, вы делаете вид, что знаете как он будет использоваться. Нарушение инкапсуляции здесь ещё грубее — каждый разработчик должен знать детали реализации в базовом классе (иначе опять можно нарушить LSP).
- Ещё более опасна длинная цепочка наследования. Например, есть у вас некоторая иерархия с некоторым поведением в самом верхнем родителе. Затем, одному или нескольким наследникам нужно отличное поведение. Как итог порождается ещё одна иерархия классов, что в конечном итоге ведёт к сложности системе.
Да и вообще сто раз это исписанно.
ps. В java (и скоро в c#) ведь есть partial interface implementation — пользуйтесь.
Затем, только некоторому числу наследников понадобилось новое поведение — вы меняете базовый класс, но вместе с этим вы также меняете и контракт тех классов
Нет, в таком случае обычно вводится ещё один промежуточный класс в иерархию
что в конечном итоге ведёт к сложности системе
Если существовала бы какая-то «серебряная пуля», которая помогала бы реализовать сложное поведение с помощью простой и очевидной модели, мы бы все ей пользовались :)
Нет, в таком случае обычно вводится ещё один промежуточный класс в иерархиюЧто в свою очередь делает всю систему еще более запутанной. Видел я систему компонентов из 7+ уровней наследования, казалось бы все красиво и круто, но разбираться в этом – то еще удовольствие :(
Если существовала бы какая-то «серебряная пуля», которая помогала бы реализовать сложное поведение с помощью простой и очевидной модели, мы бы все ей пользовались :)Из своего опыта могу сказать, что для меня «серебряная пуля» – это модульный подход (использовать interface и лишь один уровень иерархии).
Да, придется дублировать код в разных модулях, но в результате мы получаем Очевидную реализацию и поведение, легкость в тестировании и следование принципам LSP и SRP, что в свою очередь дает нам взаимозаменяемость модулей.
Более того, я считаю что наследование как раз более вредно — чем чаще вы наследуете, тем более костной становится ваша система.
"Не пользуйтесь ООП в ООП"? Ну круто, теперь заживём.
А ещё частенько ведёт и к нарушению LSP.
А если писать код как попало, то это "частенько" ведёт к нарушению всего SOLID. Это не причина.
И вообще, при слепом следовании SOLID и всему зоопарку сокращений с прикольными именами код получается тем ещё говном, так что ненавижу, когда прикрываются коллекциями советов для домохозяк.
Количество LOC будет примерно сравнимым при композиции.
Ага. Все рекламируют композицию и делегирование, а что в большинстве языков нет реализации интерфейса через член, советующих не волнует — ну, крутись как хочешь, плоди сотни строк непродуктивного кода.
Ещё более опасна длинная цепочка наследования.
Жить вообще опасно. Просто если хочешь унаследоваться вместо композиции — подумай 10 раз, унаследоваться глубоко — 100, унаследоваться множественно — 1000.
Глубокое наследование часто можно наблюдать в иерархиях гуёвых контролов. Потому что это работает.
Множественное наследование можно наблюдать в простых реализациях паттернов. Потому что это работает.
Если же пихать везде без разбора — получается чёрт знает что. Но это работает с любой фичей языка. Что угодно можно использовать во вред.
Интерфейсы ни от чего не спасают. Это ужасная сущность с точки зрения развития системы, потому что их изменять вообще невозможно. Любое изменение — всё, система сломана. Чем это лучше классов, где что-то в предках изменилось, и вдруг поломался потомок? Ну, хотя бы есть ненулевой шанс, что оно будет работать. Изменение интерфейса ломает систему всегда.
Впрочем, при желании можно считать это плюсом — но только в лабораторных условиях. В тех же лабораторных условиях, в которых проверяемые исключения работают, а не заставляют писать сомнительный код или мешают работе с лямбдами.
Рассуждение выше про интерфейсы немного устаревает с введением костыля под названием "default interface implementation" — интерфейсы теперь становятся недо-классами. Вот только не понимаю, как проповедник всего чистого в коде и идеализированных принципов построения архитектуры может оправдывать эту фичу. Default interface implementaon, между прочим, тоже вполне себе может ломать наследников, причём именно в непредсказуемом стиле, как и любые классы при наследовании.
Народ, если у вас есть мнение, то, пожалуйста, выразите его словами.
"Не пользуйтесь ООП в ООП"? Ну круто, теперь заживём.
ООП это не только наследование. Я не призываю отказываться от наследования совсем, но мой подход чем реже, тем лучше.
А если писать код как попало, то это "частенько" ведёт к нарушению всего SOLID. Это не причина.
Серебряной пули и правда нет. Но есть best practices и они появились не с пустого места. А насчёт аббревиатур — это удобный способ донести мысль другому человеку по-быстрому.
Ага. Все рекламируют композицию и делегирование, а что в большинстве языков нет реализации интерфейса через член, советующих не волнует — ну, крутись как хочешь, плоди сотни строк непродуктивного кода.
Везде свои компромиссы. Хотите хорошую систему, с которой приятно работать и удобно вносить изменения — делегируйте; проект небольшой — колбасьте код как угодно.
Да и про какие сотни строк вы говорите? Если у вас есть класс, который реализует так много интерфейсов, то проблема возникла раньше. Опять же из-за не следования хорошим практикам.
Жить вообще опасно. Просто если хочешь унаследоваться вместо композиции — подумай 10 раз, унаследоваться глубоко — 100, унаследоваться множественно — 1000.
Об этом и речь — зачем усложнять и думать 10-100-1000 раз, если можно сделать просто?
Интерфейсы ни от чего не спасают. Это ужасная сущность с точки зрения развития системы, потому что их изменять вообще невозможно. Любое изменение — всё, система сломана.
Интерфейсы это ваш контракт. Это ваш api, если хотите. И если контракт меняется, значит на то была причина — изменилось требуемое поведение.
Чем это лучше классов, где что-то в предках изменилось, и вдруг поломался потомок? Ну, хотя бы есть ненулевой шанс, что оно будет работать. Изменение интерфейса ломает систему всегда.
В том и проблема, что оно может будет работать. А может не будет. А может будет работать не так, как надо. А может появиться новое поведение, которое не ожидалось. В любом случае, чтобы быть уверенным придётся проверить всех наследников. С композицией надо проверить только там, где изменилось.
Рассуждение выше про интерфейсы немного устаревает с введением костыля под названием "default interface implementation" — интерфейсы теперь становятся недо-классами.
Согласен, default interface implementation неоднозначная фича. Пока что, я вижу ей применение для добавление утилитарного поведения, вроде того же observer'a.
Кстати, насчёт глубокой цепочки наследования в GUI — тот же реакт построен на High Order Components и там этот подход весьма органичен.
Если у вас есть класс, который реализует так много интерфейсов, то проблема возникла раньше.
Идеальную чистоту интерфейсов можно содержать только в полностью контролируемой кодовой базе, то есть примерно никогда. Во всех остальных случаях интерфейсы плодятся как кролики, потому что они не версионируемые, они в принципе не поддерживают совместимость назад.
В результате в COM мы имеем наследование от IContextMenu1, IContextMenu2, IContextMenu3, IContextMenu4, а в C# имеем ICollection, IReadOnlyCollection, IReadOnlyList (причины разные, результаты разные, но последствия всегда неприятные). И вот никуда от этого не деться. Ну не задизайнить интерфейсы так, чтобы один раз и на всю жизнь.
Интерфейсы это ваш контракт. Это ваш api, если хотите. И если контракт меняется, значит на то была причина — изменилось требуемое поведение.
Ну вот допустим в C# был бы не класс FileStream, а интерфейс IFileStream. Теперь мы хотим добавить поддержку асинхронного чтения. Ваши действия? Добавить новый интерфейс? Расширить существующий? Любое решение с интерфейсами (без default interface implementation) будет неудобным для потребителя.
С композицией надо проверить только там, где изменилось.
Идеализирование. Реализация всего может поменяться в любой момент несовместимым способом. Ломается всё, независимо от архитектуры, поэтому всё равно вы всё будете тестировать, если хотите спокойно спать по ночам.
Интерфейсы это ваш контракт. Это ваш api, если хотите.
Не люблю интерфейсы как раз потому, что они очень грубо описывают контракт. То есть вроде есть контракт, но в то же время он очень-очень общий. С одной стороны, вроде лучше чем ничего, а, с другой, иной раз тратишь много времени на оформление такого контракта, а толку мало: соблюдая его на уровне синтаксиса языка, имплементации полностью рушат все даже задокументированные пред- и постусловия с инвариантами.
Некоторые советуют дополнять реализацию абcтрактными тестами
Ну вот как-то так и приходится выкручиваться.
Там же написано — каждый наследник может иметь свой конструктор + дополнительно свой набор каких-то еще тестов. Абстрактный тест вызвает абстрактный factory method для создания конкретной реализации.
К тому же какие-то ассерты тоже могут быть абстрактными
Народ, если у вас есть мнение, то, пожалуйста, выразите его словами.
Человек, для которого ООП сводится к наследованию ("Не пользуйтесь ООП в ООП") — настолько далёк от понимания предмета, что нет смысла даже тратить время на объяснения — просто ставишь минус и идёшь дальше.
Человек, для которого ООП сводится к наследованию ("Не пользуйтесь ООП в ООП")
Это передёргивание слов. Я нигде не говорил, что наследование — единственное. Но всё-таки наследование и полиморфизм — столпы классического ООП. Заметать их под ковёр странно.
в большинстве языков нет реализации интерфейса через членМожно другими словами или пример кода, что бы стало понятней о чем речь?
Фиче-реквест для C# не нашёл. Идея в том, чтобы писать что-то подобное (синтаксис условный):
class MyCollection : ICollection, ICollection<T>, IReadOnlyCollection<T> {
private IList<T> _collection;
[ ICollection is implemented by _collection ]
[ ICollection<T> is implemented by _collection ]
[ IReadOnlyCollection<T> is implemented by _collection ]
}вместо ручной реализации каждого метода:
// ...
int Count { get { return _collection.Count; } }
bool IsReadOnly { get { return _collection.IsReadOnly; } }
// ...Собственно, сказка для композиции.
Очень похожее есть в PHP — ниже есть пример. Только нет явной привязки "имплементации" к интерфейсу.
В котлине – почти то, что нужно. Но там, я так понял, это возможно только для делегата, определяемого в конструкторе.
Если бы авторы языка такое разрешили — вы бы от каждой новой библиотеки (или нового обновления старой) вздрагивали при попытке использовать. А используют ли там делегацию? А точно ли проставлен дочерний объект?
А так у вас есть гарантии — на not null объекте всегда можно корректно вызывать методы интерфейсов, которые он реализует, и дальнейшее поведение зависит только от реализации.
Хотите поменять вложенный объект, который определяет поведение? Вы всегда можете сделать вместо:
class Derived(b: Base) : Base by bвот так:
class Derived(var b: Base) : Base by bи потом где-то в коде:
derived.b = otherBи компилятор также проверит, что otherB — not null, и поведение останется консистентным.
Если вы хотите это обойти и действительно понимаете, что делаете. Вы всегда можете сделать очень грязный и плохой хак:
derived = Derived(null!!) // не делайте такили даже так:
class Derived(var b: Base = null!!): Base by b // не делайте так тем более!Хотите поменять вложенный объект, который определяет поведение? Вы всегда можете сделать вместо:
class Derived(b: Base): Base by b
вот так:
class Derived(var b: Base): Base by b
и потом где-то в коде:
derived.b = otherB
Как бы не тут-то было. Написать-то вы так можете, и даже компилятор не ругнется, но работать оно не будет:
The by-clause in the supertype list for Derived indicates that b will be stored internally in objects of Derived and the compiler will generate all the methods of Base that forward to b.
Т.е. оно внутри где-то сохранится, и делегировать будет все время одному и тому же объекту. Вот, например, обратите внимание, что в обоих случаях выводится "Hello from A"
В delphi. Как минимум с 7. Не слишком полезная фича, имхо.
Интересно, а в каких языках такое есть?В Delphi есть. Точно есть в 7-й версии (2002 года), а может и раньше появилось.
Не то, чтобы это прям решение для всех, но в решарпере есть возможность делегировать реализацию в один клик.
Да, но несуществующий код лучше сгенерированного.
А вот вещи вроде асинхронных конструкторов, которые нужны то и дело, действительно упростили бы все.
То есть это хорошо, конечно, но есть более ценные фичи.
Это у вас "врапперов" мало. Однако есть сторонники идеологии, что должны быть только интерфейсы и их реализации, наследования быть не должно, только композиция. Не могу сказать, что это плохая идея, но без подобного сахара ей следовать проблематично, и сгенерированный код мало помогает.
Но в реальности я такого кода встречал мало. Все же часто используется отношение is, композиция тоже используется, но тогда вызывающий код просто игнорирует закон Деметры и стучится к нужным свойствам напрямую. По крайней мере кодовая база десятков проектов, что я видел, устроена именно так. Писать однострочные прокси обычно никто не хочет.
Нашёл: C# Feature Request: Expression bodied member syntax for interface implemented by field.
Вот когда эту фичу реализуют, я буду готов рассматривать вариант плоских иерархий и композиции вместо наследования.
— Ну… Не совсем!
— В каком плане?
— Не один из его методов не должен иметь реализации."
В Плане Java и C# — не верно, а в общем плане
public abstract class MyInterface {
public abstract void f();
}— Правда? А что такое интерфейс? Это то же самое что и класс?
— Ну… Не совсем!
— В каком плане?
— Не один из его методов не должен иметь реализации.
Очень уж мне не нравится это определение интерфейса. Лично для себя сформулировал, что интерфейс — это описание контракта, и это не класс со всеми методами без реализаций. Это разные сущности, в том-же C# можно явно реализовать интерфейс, попробуйте сделать то же самое с абстрактным классом.
Интерфейс — это синтетическая сущность, которая переваливает проблемы ромба с «головы» компилятора на программиста.
class CBase
{
public void Foo() { ... }
}
interface IFoo
{
void Foo();
}
class CDerived: CBase, IFoo {}
Попробуйте, не меняя класса CBase, сделать то же самое, но с помощью классов
Foo.Ограничение: метод базового класса не является виртуальным и вообще мы не можем в него лезть.
Напишите подобное на C++C++ — плохой пример, там куча проблем с дизайном. Я могу на C#-подобном псевдокоде написать, хотите?
Представьте, что оно есть.
class CBase {
public void Foo() { ... }
}
abstract class BaseFoo {
abstract void Foo();
}
class CDerived: CBase, BaseFoo {}class CDerived: CBase, BaseFoo
{
// Compiler generated
public sealed override void Foo() { CBase.Foo(); }
}CBase.Foo.Гораздо проще раздить интерфейсы и абстрактные классы. Интерфейсы требуют объявление методов в текущем классе или любом из родителей, тогда как абстрактные классы объявляют метод здесь и сейчас.
Гораздо проще раздить интерфейсы и абстрактные классы.Выделить чистые контракты в API — вполне съедобная идея, но только не ценой множественного наследования, ИМХО.
Тем, что в него можно добавить реализацию, состояние и вообще почти всё, что угодно :)
Если говорить в терминах С++, то эта «плата» — таблица виртуальных функций. Если объект унаследован от N абстрактных классов, то, в зависимости от того, под каким из N типов вы на него смотрите, this сможет принимать до N+1 значения. В случае с интерфейсами — это один объект, который реализует N интерфейсов и this там одинаковый. Учитывая то, что мы захотим виртуальный деструктор — вот вам и пачка смешений.
Например, если посмотреть на __declspec(interface), то он подразумевает под собой novtable, из-за чего мы не можем удалить объект по указателю на интерфейс.
интерфейс — это принципиальная схема какого-то устройства, а абстрактный класс — это, если хотите, печатная плата, в которую надо впаять нужные деталиЭто справедливо лишь в случае, если абстрактный класс содержит состояние. Тогда интерфейс, как синтаксическая конструкция, избыточен.
Если говорить в терминах С++Да, в C++ плохая реализация множественного наследования. Другие языки вводят специальные «правила разруливания», позволяющие использовать одного родителя, а не таскать за собой топу зачастую идентичных состояний.
Но есть одно «но». Никто вам не гарантирует, что завтра какой-нибудь абстрактный програмист не решит добавить в этот базовый абстрактный класс маленький флажочек/кэш, и тогда код скомпилируется, но если где-то упаси боже (увидел, что вы C#/C++ разработчик), при маршалинге из нативных плюсов в Managed-мир вы решите кастануть указатель к IntPtr, а потом где-то обратно передать в нативный мир, кастанув к указателю на базовый класс, то this поедет и код будет мазать по памяти (понятно, что это легко решается типизацией IntPtr до какого-то своего типа в managed-мире, но всё же).
Пример, конечно, надуманный, но я хочу донести то, что ЯП предоставляет гарантии и уменьшает количество способов стрельнуть в ногу. И понятие интерфейса в том же самом С++ дало бы гарантию того, что в этой сущности не может быть состояния.
Никто вам не гарантирует, что завтра какой-нибудь абстрактный программист не решитЯ правильно понимаю, что человек лезет изменять контракты и не знает, как они работают?
ЯП предоставляет гарантии и уменьшает количество способов стрельнуть в ногуНе бесплатно. Сужая возможности язык вынуждает писать больше кода. Больше кода — больше багов, как известно.
Я правильно понимаю, что человек лезет изменять контракты и не знает, как они работают?
Нет, речь не про это, эти изменения можно осуществить без изменения контракта.
Сужая возможности язык вынуждает писать больше кода
Мы же вроде бы с вами говорим о случае, когда вы хотите именно интерфейс, но вместо этого используете абстрактный класс со всеми чисто виртуальными методами? Как гарантия того, что интерфейс останется интерфейсом вынудит писать вас больше кода?
Нет, речь не про это, эти изменения можно осуществить без изменения контракта.Согласен. Но для этого отдельное понятие «интерфейс» не необходимо.
Мы говорим о плохом сценарии — попытке заменить интерфейсами множественное наследование. Там где контракт и должен быть контрактом — лишь одна претензия за избыточность конструкции. Просто как гарантия — это не самый лучший аргумент, кмк, ведь есть тесты.
Боль в том, что мы сейчас занимаемся противопоставлением, в то время как обе возможности могли бы соседствовать.
Проблема с виртуальным деструктором тоже решаема, но это тема для отдельной дискуссии, уходящей в итоге в наличие «object» в языке.
Источник знания покажете?
Ну, ГОСТ 27.002—89 и https://ru.wikipedia.org/wiki/Вероятность_безотказной_работы
Вероятность безотказной работы группы объектов равна произведению вероятностей безотказной работы каждого объекта в этой группе.
Чем больше объектов в группе, тем ниже надежность всей группы
Для кода тоже работает.
Так это разное. Блоки кода — последовательно соединенные элементы, каждый со своей вероятностью отказа.
P — вероятность отказа системы. p — вероятность отказа узла системы. n — кол-во узлов
Последовательное соединение узлов: P=p^n
Параллельное: P=1-(1-p)^n
Для p=0,99 n = 5,
P последовательного ~= 0.95
P параллельного = 0,9999999999
Последовательное соединение теряет надёжность. Параллельное — приобретает.
http://lib.alnam.ru/book_rdm.php?id=204
Когда вы свой продукт деплоите в 4 инстанса — вы параллельно их соединяете. Повышаете надёжность.
Когда вы пишете код — вы последовательно соединяете блоки — с каждой новой строчкой надёжность падает, даже если вероятность отказа каждой конкретной строчки (бредово, но допустим) равна 0.999999999999999
Почему вы считаете, что у любых строк кода одинаковая вероятность отказа?
Потому что это всего лишь пример. Я ещё считаю что строчек кода всего 5, это не смутило?
По ссылке в книге полная формула приведена для общего случая.
Меня смутило другое. Правило "Чем больше объектов в группе, тем ниже надежность всей группы" работает только при постоянной вероятности отказа объекта.
Главное, что при ненулевой вероятности отказа.
Нет, совсем не главное. Сравните что меньше: 1 — 0,93 или 1 — 0,995?
Условия разные, в одном случае 5 в 10 раз более надёжных элементов, а в другом 3 очень ненадёжных.
Очевидно же, что говорить о снижении надёжности системы с увеличением кол-ва элементов в ней можно только при прочих равных условиях, а именно что элементы те же самые.
Аналогия: Как сравнить надёжность 3х строк на C# и 100 строках на asm?
Я думаю надо сравнивать 3 строки на C# и 100 строк на C#
Правило "Чем больше объектов в группе, тем ниже надежность всей группы" работает только при постоянной вероятности отказа объекта.
Я думаю в этом случае только подсчёт вероятности отказа сложнее — через цепи Маркова (редирект на пдф). Придётся мучаться либо с интегралами по времени, либо измерять вероятность отказа в определённом состоянии (с учётом того как объект попал в это состояние).
Интуитивно должно работать так же: сложнее система (больше последовательных элементов) — надёжность меньше. Дублирование системы (больше параллельных элементов) — повышает надёжность.
Классическая ситуация — нарушение LSP при наследовании квадрата от прямоугольника.
Насчёт LSP, квадрата и прямоугольника есть иные мнения: одно, второе. Первое — верно с любой точки зрения. Второе — спорное, но я придерживаюсь его. Интерфейс IRectangle никак не запрещает свойствам меняться по желанию левой пятки, в том числе при изменении другого свойства. Какую конкретно логику и контракты вы вкладываете в этот интерфейс — большинством языков программирования не описывается.
Скажем, я опишу IWindow с IsMinimzed, присвою значение, потом вдруг окажется, что там не то значение, которое я присвоил, а в BoundingRect вообще непонятно что. Это нарушение контракта? Нет, это юзер нажал кнопочку.
И это всё очень нетривиально для строк кода.
Инженерия делает проще.
Берём тысячу плат и тестируем час. Отказало 2 из 1000? Эмпирическая вероятность отказа одной платы (как целого объекта) в течении часа — 0.2% (а надёжность — 99.8%)
Повторяем с прочими элементами, считаем суммарную надёжность.
С программными продуктами можно сделать похоже.
Выкатываем web application, нагружаем час, считаем кол-во out of service, service deny, timeout, 502 и пр. на общее кол-во запросов.
Абстрактно всё то же самое, программирование та же инженерия.
Область и условия применения: Настоящий стандарт устанавливает основные понятия, термины и определения понятий в области надежности.
Настоящий стандарт распространяется на технические объекты
Ну если вы считаете, что это про код…
Даже не знаю, то ли у вас тогда спросить «как вы тройное резервирование в исходном коде делать предлагаете?», то ли предложить попробовать глючность программы по количеству опкодов в .exe считать.
Даже не знаю, то ли у вас тогда спросить «как вы тройное резервирование в исходном коде делать предлагаете?», то ли предложить попробовать глючность программы по количеству опкодов в .exe считать.
Ну если в маразм впадать, то да, можно и опкоды считать.
А вообще люди придумали кластеры, рейд массивы, зоопарки всякие, облака с динамическим масштабированием — это всё примеры параллелизации вашего кода с целью повышения надёжности.
Ну, и банальный
retry 5 (fun () -> saveOnDisk ())в коде, где saveOnDisk может завалиться с ненулевой вероятностью.
Ваша теория или работает, или не работает. Если вы в ГОСТе ограничений не покажете — значит должно быть можно по опкодам считать.
> retry 5 (fun () -> saveOnDisk ())
О да, такое по надежности явно превосходит одиночный вызов как раз в (1-(1-p)^n)/p раз. Особенно, когда дескриптор закрыт строкой выше.
И не надо подменять надежность и параллелизацию кода на установку дополнительных железок.
Ваша теория или работает, или не работает. Если вы в ГОСТе ограничений не покажете — значит должно быть можно по опкодам считать.
Конечно можно, кто ж мешает. Если заняться нечем в ближайшие пару лет.
О да, такое по надежности явно превосходит одиночный вызов как раз в (1-(1-p)^n)/p раз. Особенно, когда дескриптор закрыт строкой выше.
Если вы не знаете зачем применяют ретраи в IO, ничем не могу помочь. Не от закрытого дескриптора строкой выше, нет.
И не надо подменять надежность и параллелизацию кода на установку дополнительных железок.
Почему же? Дополнительные фейловер инстансты моей системы — это как раз оно самое, что не так? Одна упадёт, другая подхватит.
Так вы вручную считать хотите?
> Не от закрытого дескриптора строкой выше, нет.
То есть закрытый дескриптор под вашу формулу пересчёта кода в баги не подходит? Ок, вопросов больше не имею.
> Дополнительные фейловер инстансты моей системы — это как раз оно самое, что не так?
Всё хорошо, кроме того, что вы приравняли «код» и «систему».
Так вы вручную считать хотите?
Я вообще не хочу считать.
То есть закрытый дескриптор под вашу формулу пересчёта кода в баги не подходит?
Передёргивание. Я такую "формулу" не приводил. Но приводил ту, которая может посчитать надёжность системы из надёжностей её элементов.
И она не моя, вы мне льстите.
Всё хорошо, кроме того, что вы приравняли «код» и «систему».
Ну пожалуйста, объясните чего ж такого магического в коде, что его нельзя рассматривать как систему объектов, друг с другом взаимодействующих.
Ну, главное разобрались, что к моему вопросу о происхождении «Больше кода — больше багов» ваш ответ отношения никакого не имеет.
> Ну пожалуйста, объясните чего ж такого магического в коде, что его нельзя рассматривать как систему объектов, друг с другом взаимодействующих.
У меня ощущение, что у вас есть собственное понимание «кода», «системы», «объектов», «баг» и «взаимодействующих». Или вы троллите.
Давайте так: научный подход — это не «объясните чего ж такого магического», а подтверждение гипотеза экспериментом. А расчёты по результатам вашего рассмотрения в отношении кода не сойдутся с реальностью. Вот покажете эксперимент — будет повод для разговора.
Есть такая штука — Borland C++ Builder, так вот он абстрактные классы, не имеющие полей, реализует именно как интерфейсы, без заведения дополнительного поля vtable. И при этом никаких __declspec указывать не надо — он сам определяет по семантике, является ли сущность полноценным классом или легковесным интерфейсом.
А вообще, такое поведение связано с бинарной совместимостью с Delphi, как раз таки имеющего интерфейсы, и желанием Borland остаться в рамках стандарта C++.
так вот он абстрактные классы, не имеющие полей, реализует именно как интерфейсыОтлично! Это то, что и нужно, чтобы называться интерфейсом. А теперь давайте в идельном мире закрепим это явно на уровне языка, чтобы это происходило всегда по спецификации, а когда не происходило — не компилировалось. И вот мы получаем ключевое слово interface.
Я php-шник и могу делать еще большее зло выводя общий код в трейты, описывать под них интерфейсы и вообще отказываться от базовых классов, тупо подмешивая функционал в нужные объекты.
interface ObservableInterface {
public function addObserve(ObserverInterface $observer);
public function notify();
}
trait Observable {
protected $observers = [];
public function addObserve(ObserverInterface $observer)
$this->observers[] = $observer;
}
public function notify(){
array_map(function($observer){ $observer->update(); }, $this->observers)
}
}
class MySomeWidget implements ObservableInterface, WidgetInterface {
use Observable, WidgetUx, WidgetSupport, WidgetConfigs;
}
class MyParser implements ObservableInterface {
use Observable;
}
class MyCollection extends Illuminatie\Support\Collection implements ObservableInterface{
use Observable;
}Лучше бы от наследования отказались в Collection, а не в Widget. :)
Если бы я описывал свою коллекцию со всей этой фигней то да.
Но так как я использую один из бесполезных и ненужных и тормознутых фреймворков то мне проще тупо использовать его коллекции а не писать собственные велосипеды.
Хотя в данном случае, если мне хочется чтобы любое изменение в коллекции генерировало событие update мне конечно придется переопределить некоторые методы.
А теперь добавим в эту солянку default-методы в интерфейсах в Java 8. Вот уж костыль из костылей...
— появляется возможность множественного наследования с проверками отсутствия неочевидного кода во время компиляции (unrelated defaults)
— кодогенераторы вроде immutables.github.io позволяют очень сильно очистить кодовую базу от всякого шлака вроде equals и toString, в результате чего остаётся практически чистая бизнес-логика
— накнец-то можно замокать любой(!) оъект, что существенно облегчает написание автотестов
По-моему, лучше чем interfaces + defaults было бы только иметь возможность добавлять реализацию классом произвольного интерфейса без изменения самого класса.
Самое интересное, что в MyObservableWidget вы должны будете переопределить все методы MyWidget, изменяющие состояние, чтобы вызвать в них notify(). При этом вы попадаете на жёсткую зависимость от реализации MyWidget. При добавлении нового метода в MyWidget, который изменяет состояние, вам придётся изменять MyObservableWidget, иначе ничего вас не спасёт от багов. А если метод вроде addAll вместо ручной реализации в новой версии начнёт в цикле вызывать add, вы пришлёте миллион эвентов вместо одного (либо обратное произойдёт, тогда вы в новой версии вообще не пришлёте эвент). В этой ситуации невозможность множественного наследования и необходимость вручную делегировать пару методов к какому-нибудь подобию javax.swing.event.EventListenerList — это наименьшая из ваших проблем. Я считаю, если вы не используете аспекты или что-то аналогичное (а я совсем не призываю их использовать), то вы не сможете сделать изменяемую структуру данных отдельно от нотификаций, а потом прикрутить нотификации в дочернем классе. Вообще наследование конкретных классов плохо пахнет. Если вам при этом приходится переопределить реализацию N методов (например, "все методы, которые изменяют состояние"), вы точно ищете себе проблемы. На это напоролся, например, EclipseLink, который расширил ArrayList, переопределив все методы, а в Java 8 — сюрприз — появились новые методы.
При добавлении нового метода в MyWidget, который изменяет состояние, вам придётся не забыть добавить куда-то нотификацию, да.
Если у вас нет привычки смотреть на происходящее в наследниках при правке базового класса — вас ничего не спасёт от багов (к сожалению).
Доступа к наследникам может вообще не быть.
Я против такого определения «контракта». Если у вас приложение сломалось — кто-то нарушил контракт. Или это не контракт, а undefined behaviour.
Вот полагаться, что addAll в родителе дергает/не дергает add, если это отдельно не прописано — не стоит.
Не знаю как в java но в php можно тупо сделать wrapper который будет прозрачно проксировать вызов любого метода да и еще и notify вызывать при этом.
— Да, но этот класс их не имеет. Тогда почему его нельзя назвать интерфейсом?
— Абстрактный класс может иметь нестатические поля, а интерфейс не может.
Дальше не читал. Основное отличие интерфейса — поддержка "множественного наследования".
Ого. Это за "дальше не читал" или за основное отличие интерфейса? Если второе, то хотелось бы критики :-)
За остальных говорить не буду, но лично от меня – за пафосно высказанную глупость. Некоторые языки запрещают множественное наследование классов, но разрешают множественное наследование интерфейсов. К самой сущности интерфейса это относится чуть менее, чем никак, и уж претендовать на основное отличие явно не может.
Можно пример языков, где есть и множественное наследование, и интерфейсы? Я знаю только два языка с множественным наследованием — C++ и Scala. И там, и там интерфейсов нет.
Эм… ну Вы не путайте причину и следствие. Это не интерфейс нужен для поддержки множественного наследования, это некоторые языки, которые запрещают множественное наследование классов, разрешают множественное наследование интерфейсов, потому что оно не имеет побочных эффектов. Соответственно, в таких языках как Java вводится ключевое слово interface, чтобы синтаксически различать эти сущности. В таких же языках как python в этом ключевом слове нет необходимости, поскольку разница чисто семантическая.
В общем же случае интерфейсы – это вообще не про наследования. Это отдельная семантическая сущность, контракт, если хотите, которому должен следовать класс. Поэтому, на мой взгляд, в Java как раз правильно "наследование" интерфейсов идет через implements – класс реализует интерфейс, а не наследует его. А наследование классов – это вообще про is-a отношение. Так что использовать интерфейсы, чтобы обойти ограничение во множественном наследовании, это не очень правильно.
С моей же точки зрения, реализация по умолчанию, определенная непосредственно в интерфейсе – это некий компромисс в угоду краткости кода. Строго говоря, это еще одна, отдельная, сущность "Интерфейс с частичной реализацией", но вводить для этого отдельное ключевое слово (насколько я помню, сначала в котлине так и было, какое-то время существовал trait) может быть уже перебором. Но семантически это именно "интерфейс" + "его реализация по умолчанию" в одном флаконе.
C++ и Scala. И там, и там интерфейсов нет.Microsoft ввела ключевое слово interface в свою реализацию компилятора, и это никак не повлияло на множественное наследование. msdn.microsoft.com/en-us/library/50h7kwtb.aspx
В Borland C++ Builder тоже были интерфейсы, тоже compiler-specific.
— Не один из его методов не должен иметь реализации.
Если я не ошибаюсь, в C# 8.0 интерфейсы смогут определять реализацию по умолчанию, так что это заявление скоро будет неактуальным.
Интерфейсы в понятие опп, никогда не имели и не будут иметь реализацию
Банальная победа прагматизма над идеализмом. Идеалы работают, если есть возможность в любой момент переписать весь код. В остальных случаях приходится заботиться об обратной совместимости и чистоте кода потребителя.
Интерфейсы в понятие опп, никогда не имели и не будут иметь реализацию
Осталось найти это "понятие ООП" и выяснить, почему оно — правильное, а любое другое, в котором интерфейсов нет вообще или они могут иметь реализацию, — неправильное.
interface IFoo
{
}
public static class IFooExtensions
{
public static void Foo(this IFoo @this) {}
}лучше, чем просто написать
interface IFoo
{
public default void Foo() {}
}?
Не надо про архитектурную чистоту и независимость интерфейса в первом случае, на самом деле они точно так же связаны.
Второй способ лучше, потому что default interface implementation полноценно участвует в полиморфизме. Первый способ — синтаксический сахар над неполиморфным вызовом статического метода.
Ну а вы, например, вынесите IFooExtensions в отдельную сборку — развяжутся?
Интерфейс — нет.
Да, в Java 8 добавили
default-методы и статические методы, а в Java 9 — приватные default-методы и приватные статические методы, но с состоянием это не имеет ничего общего.Если не ошибаюсь, в C# вошло в моду называть интерфейсы с префиксом
I, т.к. этот костыль помогает глядя в код понять, что после : находится класс или интерфейс. А использование implements / extends делает код лучше для восприятия (субъективно).Если не ошибаюсь, в C# вошло в моду называть интерфейсы с префиксом I
Этому правилу уже лет 15, начиная с версий 1.Х и он описан в древнейших официальных гайдлайнах. Не очень похоже на «моду».
т.к. этот костыль помогает глядя в код понять, что после: находится класс или интерфейс. А использование implements / extends делает код лучше для восприятия (субъективно).
Что делать с ипользованиями вне наследования? Например, когда это поля/параметры/…
Это не больший «костыль», чем писать название переменных с маленькой буквы, а имена классов — с большой.
Это не больший «костыль», чем писать название переменных с маленькой буквы, а имена классов — с большой.
А чем это правило плохо? Часто же бывает, когда и переменную, и имя класса хочется называть одинаково. Уж лучше различие в регистре первой буквы, чем всякие мерзкие префиксы-постфиксы.
То же самое и с интерфейсами, когда имя интерфейса и класса совпадает: List и IList, Dictionary и IDictionary и т.д.
Все эти правила именования — не более, чем способы разрешения коллизии имён, ставшие со временем гайдлайнами.
Container.Bind<IFoo>().To<IBar>().FromResolve();Всмысле типом может быть намекающий new? Это вполне может быть статический метод класса
Зачем отличать от локальных переменных? Методы обычно очень короткие — всегда видно локальные переменные и так. Тем более свойства, которые не get-set пишутся с маленькой буквы, хотя разницы не должно быть никакой. Бред какой-то. Это такая мелочь, но, пожалуй, бесит меня больше всего в C#
Какой привычки? Я уже два года на шарпах пишу, сколько еще ждать, пока привыкну?
Всмысле типом может быть намекающий new? Это вполне может быть статический метод класса
В угловых скобках? Не может.
Самое простое — покажите код, где может быть как тип, так и не тип, и из-за стиля именования непонятно, что где.
Зачем отличать от локальных переменных? Методы обычно очень короткие — всегда видно локальные переменные и так. Тем более свойства, которые не get-set пишутся с маленькой буквы, хотя разницы не должно быть никакой. Бред какой-то. Это такая мелочь, но, пожалуй, бесит меня больше всего в C#
Свойства всегда пишутся с большой буквы, не знаю, откуда эта информация про «не гет сет». Решарпер на дефолтных настройках как раз следует стандартному гайдлайну. Ну, разве что я предпочитаю еще у приватнах переменных префикс "_" писать. Но тут уже вопрос привычки.
Методы обычно очень короткие — всегда видно локальные переменные и так.
Когда короткие, а когда нет. Я не замерял, но в сложных продуктах средняя длина метода 50-100 строк. Типичный такой пример.
Ну и да, тут нет варианта писать или не писать — как-то писать надо. Текущие правила, как я уже сказал, уменьшают количество коллизий.
Свойства всегда пишутся с большой буквы, не знаю, откуда эта информация про «не гет сет».В вашем же примере куча свойств с маленькой буквы:
private int[] buckets;
private Entry[] entries;
private int count;
private int version;
private int freeList;
private int freeCount;
private IEqualityComparer<TKey> comparer;
private KeyCollection keys;
private ValueCollection values;Самое простое — покажите код, где может быть как тип, так и не тип, и из-за стиля именования непонятно, что где.Я ведь выше давал уже пример, вот:

Это может быть как и статический метод
Bind класса Container, так и динамический метод свойства. И невозможно определить, что именно это.Вот Hello World пример:
using Zenject;
using UnityEngine;
using System.Collections;
public class TestInstaller : MonoInstaller
{
public override void InstallBindings()
{
Container.Bind<string>().FromInstance("Hello World!");
Container.Bind<Greeter>().AsSingle().NonLazy();
}
}
public class Greeter
{
public Greeter(string message)
{
Debug.Log(message);
}
}Я искренне считал первое время, что этот пример означает следующее:
Zenject.Container.Bind<string>().FromInstance("Hello World!");
Zenject.Container.Bind<Greeter>().AsSingle().NonLazy();И суть в том, что нельзя узнать, как именно оно есть на самом деле. А вот если бы все свойства были с маленькой буквы — было бы очевидно, потому что. Ну вот вам пример. Это корректный код на C#. Я в нем обращаюсь как к классу, так и к свойству. Так вот — какой вариант правильный:
1. ProjectContext — это класс, а LazyInstanceInjector — это свойство, или
2. LazyInstanceInjector — класс, а ProjectContext — свойство?
Вы можете ответить на этот вопрос без дополнительного контекста?
using Zenject;
public class TestInstaller : MyClass
{
public IEnumerable<object> MyMethod ()
{
return ProjectContext.HasInstance
? LazyInstanceInjector.Instances
: null;
}
}Название свойств с маленькой буквы полностью убрало бы этот гемор
Я не замерял, но в сложных продуктах средняя длина метода 50-100 строк
Не средняя, а максимальная. Вы ведь нашли метод побольше, а не средний. А вот количество файлов — сотни и в каждом сотни строк. Вот уж где место для коллизий.
Текущие правила, как я уже сказал, уменьшают количество коллизий.
С нуля вверх? Это невозможно. И если ваши слова бы имели логику, то как вы избегаете коллизий локальных переменных и приватных свойств?
Это может быть как и статический метод Bind класса Container, так и динамический метод свойства.
Более того, "Container" может быть и свойством, и классом одновременно, и что вызывается — зависит и от инстансных членов класса свойства, и от статических членов класса. Это не баг, это фича.
Если хотите знать, что используете, то поставьте решарпер и включите расширенную подсветку.
Ну или на VB немного код попишите. Там вообще всё с большой буквы. Потом будете с радостью вспоминать C#, где хоть какое-то разнообразие.
И если ваши слова бы имели логику, то как вы избегаете коллизий локальных переменных и приватных свойств?
Приватные свойства и методы тоже пишутся с большой буквы. Что касается приватных полей, то им часто дают префикс "_", чтобы не заморачиваться с this.
Это не баг, это фича.
В чем фича?
Решарпер у меня стоит. С IDE, конечно, значительно меньше проблем, но это не значит, что я не имею права считать такую идею плохой — она реально мешает пониманию кода, в чем я лично убедился совершенно недавно. Значительно лучше, если бы все публичные/защищенные поля и свойства были с маленькой буквы (какого они вообще разделяются, это нарушение инкапсуляции). Но я понимаю, что так, к сожалению, уже не будет. А жаль.
Если бы были CClass, PProperty, MMethod, FField в дополнение к IInterface, было бы лучше? Не думаю. Если что-то непонятно, есть IDE. C R# вопрос про разновидность идентификатора не возникает никогда, потому что всё видно по цвету. Проблемы нет.
было бы лучше?
Я же написал как было бы лучше. Зачем вы мне отвечаете, если не читаете мои сообщения? Вот что я писал:
Значительно лучше, если бы все публичные/защищенные поля и свойства были с маленькой буквыДальше
вопрос про разновидность идентификатора не возникает никогда
Еще раз — у меня вопрос возник, когда я читал документацию с примерами. К ГитХабу решарпер не подключишь. Вы странный.
В вашем же примере куча свойств с маленькой буквы:
Это поля, а не свойства!
Есть стратегия, где поля пишут с подчеркивания. Как раз для уменьшения таких коллизий, особенно в конструкторах.
Вот это мне, кстати, и не понятно. Ведь поля и свойства лучше называть одинаково. Когда ты обращаешься к array.length — тебя не должно интересовать — поле это или свойство, инкапсуляция ведь. А в результате разработчик библиотеки должен иметь легкую возможность подменить поле свойством.
Сейчас это решили тем, что поля вообще никогда в паблик не выходят, только свойства.
Если в C# синтаксис работы с полями и свойствами похож — это ещё не инкапсуляция.
Ну и на практике это тоже не работает. Начиная с того, что с полями и свойствами через Reflection надо работать отдельно (а это куча тулинга).
Насчет «не должно быть разницы» — поля всегда приватные, а поля как правило публичные. Так что видеть разницу в видимости в названии переменной часто полезно. Ну и всякие мелочи вроде использования с `ref` и все такое прилагается.
Когда ты обращаешься к array.length — тебя не должно интересовать — поле это или свойство
А вас и не интересует. Публичные поля запрещены всеми кодостилями, поэтому при обращении к члену-значению имя всегда с большой буквы.
А в результате разработчик библиотеки должен иметь легкую возможность подменить поле свойством.
Не должен. Ломается бинарная и даже сорцовая совместимость.
Что касается вашего примера, то тут есть два способа разрешить его:
1. Подсветка в IDE подсвечивает тип аквамариновым, а поле оставляет белым. Решарпер тут не нужен, это дефолтная подсветка во всех связанных тулзах, даже менее мощных, чем студия
2. Если ВДРУГ подсветки нет, то можно использовать следующую логику: методы очевидно являются мутабельными, а изменять глобальную статическую переменную из инстансного метода это… запашок. Так что это свойство с таким именем, скорее всего protected в базовом классе.
Да, и благодаря префиксу I я сразу вижу тут в этом коде ошибку, потому что биндить интерфейс можно только к классу, но никак не к другому интерфейсу.
Не средняя, а максимальная. Вы ведь нашли метод побольше, а не средний. А вот количество файлов — сотни и в каждом сотни строк. Вот уж где место для коллизий.
Тут я нашел побольше, да. В продакшн коде, где не специлисты уровня майкрософт код пишут средний размер кода поболее будет.
С нуля вверх? Это невозможно. И если ваши слова бы имели логику, то как вы избегаете коллизий локальных переменных и приватных свойств?
Как это с нуля? Окей, пишем с маленькой, как теперь без контекста понять, локальная это переменная или свойство? «Ну метод маленький, там все видно» — не аргумент, ибо он не отменяет коллизии, а переводит стрелки в стиле «самдурак» на программиста.
Выше уже ответили, что это поля, а не свойства. Разница существенная, но для разрешения я как раз и написал про "_".
Вы их переменными назвали, не полями:
приватнах переменных префикс "_" писать
Да, и благодаря префиксу I я сразу вижу тут в этом коде ошибку, потому что биндить интерфейс можно только к классу, но никак не к другому интерфейсу.
Нету там ошибки
В продакшн коде, где не специлисты уровня майкрософт код пишут средний размер кода поболее будет.
Сомнительно. Я специалист далекий до МС, но методы у меня корокие.
«Ну метод маленький, там все видно» — не аргумент,
Почему не аргумент? Метод значительно меньше, чем все файлы, а значит значительно уменьшает влияние коллизий.
Сомнительно. Я специалист далекий до МС, но методы у меня корокие.
Значит, у вас достаточно простая область вроде написания WebAPI прокси для другого сервиса. При сложной логике, например при работе с компилятором, получается что-то в таком духе. Разбить его на кучу мелких методов можно, но читаемости это не добавит.
Нету там ошибки
Я про этот код:
Container.Bind<IFoo>().To<IBar>().FromResolve();Судя по официальной доке, эта запись означает, что вместо интерфейса IFoo прокидывать инстанс IBar, инстанс IBar создать нельзя, значит ошибка.
Значит, у вас достаточно простая область вроде написания WebAPI прокси для другого сервиса
GameDev.
При сложной логике, например при работе с компилятором, получается что-то в таком духе
Вы берете какие-то крайности и ставите в качестве примеров. А раньше вы, вроде, про среднестатистический код говорили. И я посмотрел всю либу. Это единственный файл, в котором только два таких метода. И вы хотите мне это выдать за среднестатистический код? Несерьезно. Это исключение, а далеко не правило
Я про этот код:
Да, я понял. Там нету ошибки.
Вы берете какие-то крайности и ставите в качестве примеров. А раньше вы, вроде, про среднестатистический код говорили. И я посмотрел всю либу. Это единственный файл, в котором только два таких метода. И вы хотите мне это выдать за среднестатистический код? Несерьезно. Это исключение, а далеко не правило
Какие крайности? Это единственный класс с логикой, все остальное — просто ДТО, которые и считать-то не обязательно.
Да, я понял. Там нету ошибки.
Окей, а в этом коде — есть:
builder.RegisterType<IFoo>.As<IBar>();При сложной логике, например при работе с компилятором, получается что-то в таком духе.
Я не вижу сложной логики, я вижу сложный API (AddModifiers(Token(SyntaxKind.PublicKeyword)) вместо public). Реальных ветвлений в коде метода мало.
Вполне логичное правило, чтобы отличать свойства класса от локальных переменных.Спасибо, интересное объяснение. Сегодня, правда, для этого есть IDE с подсветкой синтаксиса и с переходом к декларации по ссылке. Как и для отличения класса от интерфейса.
А чем это правило плохо? Часто же бывает, когда и переменную, и имя класса хочется называть одинаково. Уж лучше различие в регистре первой буквы, чем всякие мерзкие префиксы-постфиксы.
Не понял этого утверждения. Намешано про типы, префиксы, регистры…
То же самое и с интерфейсами, когда имя интерфейса и класса совпадает: List и IList, Dictionary и IDictionary и т.д.
IList реализует не только List, и не только в стандартной библиотеке.
Имхо это костыль:
- Классы, префиксы энамы и прочее — это типы и находятся в одном адресном пространстве. Их не надо разделять.
- Получается что даже тот код, который использует интерфейс, а не реализует, связан с тем, что это именно интерфейс. Т.е. убрав эту I можно было бы уменьшить compile time dependency
- Если у нас класс называется так же как интерфейс, это значит, что мы что-то не выразили в имени (IList это список вообще, а List — это конкретная реализация, которая уже не список вообще, но называется как список вообще. До дженериков ее назвали ArrayList — что, имхо, более явно отличает абстрактный список от конкретной реализации)
Получается что даже тот код, который использует интерфейс, а не реализует, связан с тем, что это именно интерфейс. Т.е. убрав эту I можно было бы уменьшить compile time dependency
Не могли бы, потому что тесты
Если у нас класс называется так же как интерфейс, это значит, что мы что-то не выразили в имени (IList это список вообще, а List — это конкретная реализация, которая уже не список вообще, но называется как список вообще. До дженериков ее назвали ArrayList — что, имхо, более явно отличает абстрактный список от конкретной реализации)
Наоборот, в 99% случаев у интерфейса одна реализация, а интерфейс нужен для того, чтобы подсовывать моки.
Получается что даже тот код, который использует интерфейс, а не реализует, связан с тем, что это именно интерфейс. Т.е. убрав эту I можно было бы уменьшить compile time dependency
Тесты это другой код.
Наоборот, в 99% случаев у интерфейса одна реализация, а интерфейс нужен для того, чтобы подсовывать моки.
Не явлюятся ли моки другой реализацией?
Не являются ли моки другой реализацией?Да, являются — единственной другой реализацией, создаваемой на лету и не имеющей нормального имени класса.
Итого
- IFoo это на самом деле "какая-то фигня для тестирования" а не "Foo вообще"
- Foo это "Foo вообще" (но пользователь использует IFoo в качестве "Foo вообще")
- Тест подсовывает неименованную частичную реализацию IFoo
Лично я предпочитаю так не делать. По поводу моков была продуктивная дискуссия c lair
Получается что даже тот код, который использует интерфейс, а не реализует, связан с тем, что это именно интерфейс.
Интерфейс на класс в стандартной библиотеке никто никогда менять не будет, потому что это сломает бинарную совместимость. Особенно подобное изменение убийственно для языков без множественного наследования, потому что очень усложнит миграцию даже при сорцах. Сорцовая совместимость в частном случае — слишком слабое требование для большого количества библиотек.
И в случае List<T> сильный упор был сделан на производительность, а не на красоту абстракций. В этом классе нет виртуальных методов, а вызов через интерфейс полиморфен всегда, причём в ранних версиях дотнета заметно медленнее обычного полиморфного вызова, если не изменяет память.
Я скорее про саму нотацию, а не про использование ее в публичных типах стандартной библиотеки.
а вызов через интерфейс полиморфен всегда, причём в ранних версиях дотнета заметно медленнее обычного полиморфного вызова, если не изменяет память.
Сейчас однаково.
Разница есть только при навешивании ограничений на generic-параметры: Foo<T>(T param) where T: ISomething будет чуть (но только совсем чуть!) медленнее, чем Foo(ISomething param).
Для структур делается в компайл тайм. На дотнексте целый доклад был про то, как превращать if (typeof(T) == typeof(SomeType)) в if (true).
А для всех классов вообще используется одна-единственная реализация Foo__Cannon
Кстати, такое поведение позволяет делать виртуальные дженерик методы, что невозможно в случае шаблонных методов C++.
Примечание: когда T — структура, а не класс возможна генерация отдельного кода для каждого из типов — это приводит к code bloating, но позволяет избавиться от боксинга.
Если бы проблема была только в interface a.k.a. protocol… Чтобы не прикасаться к проклятому ромбу, дизигнеры языков плодят сущности, придумывая всякие trait a.k.a mixin, кроме того сами интерфейсы мутируют в недо-абстрактные классы добавлением default interface implementation, а поверх всего этого добра сбоку прикрепляются extension methods a.k.a. helper classes a.k.a protocol extensions.
Остапа понесло. Он почувствовал прилив новых сил и шахматных ООП идей.
При этом сама статья — тоже тот ещё бред.
Никаких "специальных случаев" быть не может. Ты или полноценно реализуешь множественное наследование, как в C++, или не делаешь этого вообще. Иначе возникает момент, когда нельзя наследоваться из-за того, что где-то в предках кто-то решил унаследоваться от чего-то другого.
Кроме высосанной из пальца причины про "невозможность" ромба и "лени" у авторов языков были объективные причины не реализовывать множественное наследование: авторы джавы упарывались по "простоте", а множественное наследование — "сложно"; авторы шарпа делали "джаву по-нормальному", и не нашли достаточно оправданий отступить от разделения типов базовых классов, ну и плюс упирали на "изменение базы должно ломать как можно меньше".
- Изменение interface на class — это ломающее изменение что в Java, что в C#. Более того, любое изменение интерфейса — ломающее изменение. Это ужасно. Костыль с default interface implementation — попытка замести эту проблему под ковёр и сделать из интерфейсов более гибкие и послушные абстрактные классы.
На самом деле я тоже так думал, пока не додумался об одной маленькой проблеме — трейт не самостоятельный объект и если к нему привязывать интерфейс тогда у нас 3 варианта.
1) Интерфейс не должен влиять на исходный объект куда примешивается никак — тогда собственно зачем он нужен
2) Необходимо выдавать ошибку если класс не реализует интерфейс трейта, что усложнит код
3) Необходимо делать магию что у объекта как бы есть интерфейс но он не описан явно, что будет выдавать еще больше юмора, особенно если методы интерфейса переопределяются родительским объектом или другим интерфейсом.
— Правда? А что такое интерфейс? Это то же самое что и класс?
— Ну… Не совсем!
— В каком плане?
— Ни один из его методов не должен иметь реализации.
В этом месте ответ невнятный, а дальше все как на неудачном собеседовании, все цепляется одно за другое. Интерфейс — договор, описание функционала. Класс — реализация, которая может быть частичной или не быть вообще (абстракный класс). Если кто-то использует отсутствие реализации как договор, это его личные трудности (как в примере).
Ладно, получается что "Смертельный Бриллиант Смерти" это проблема, которую решили еще в прошлом веке, и она не фатальна и даже не ведёт к смерти.
Нет, нет, и еще раз нет! Эта проблема так и не была толком решена в C++. На нее просто закрыли глаза, порекомендовав программистам так не делать. (Это вообще популярный способ борьбы с языковыми проблемами в С++)
Проблема тут не только в переменных полях, она в методах.
Рассмотрим простейший "бриллиант":
class B {
void foo() { /* ... */ }
}
class D1 extends B {
void foo() { super.foo(); }
}
class D2 extends B {
void foo() { super.foo(); }
}
class M extends D1, D2 {
void foo() { ??? }
}Как теперь в классе M переопределить метод foo так, чтобы базовая реализация была вызвана не два раза, а один?
В языке C++ это можно сделать только копированием логики из D2 в M (или из D1 в M).
В языке Python это попытались решить "выпрямлением" наследования — что тоже не лишено проблем, поскольку позволяет писать код с неочевидным поведением.
Это не "простейший" бриллиант, это бриллиант с виртуальным методом в виртуальном базовом классе, с переопределением метода на нескольких уровнях.
Если происходит что-то подобное, и надо разруливать хитросплетения из B.foo, D1.foo, D2.foo и вызывать это всё в нужной последовательности, и в этом есть какой-то смысл, то, вероятно, авторам всего этого добра стоило выделить основную логику foo в D1 и D2 в отдельные методы doFoo.
Более того, проблема с вызовом базовых методов в нужный момент в нужной последовательности возникает и без множественного наследования, если в виртуальных методах очень хитрая логика, которая зависит от порядка выполнения отдельных частей на разных уровнях иерархии. Один из способов разруливания этой ситуации окрестили паттерном "шаблонный метод". Всё уже изобретено.
Разумеется, если у вас подобная хитрая ситуация, и автор этих трёх классов не побеспокоился, что делать наследникам, то у вас проблемы. Но это просто непродуманный дизайн, а не какая-то концептуально неразрешимая ситуация.
Как теперь в классе M переопределить метод foo так, чтобы базовая реализация была вызвана не два раза, а один?
в с++: M::foo() { D1::foo(); }
И теряем ту логику, которая была добавлена в D2::foo.
Какая именно проблема является "точно той же"?
Разумеется, когда "бриллиант" уже начал рисоваться (классы B, D1 и D2) — правильно замкнуть его никакая композиция уже не поможет. Композицию надо применять с самого начала, вместо наследования.
struct Point {
float x, y;
};
class Ellipse
{
Point p1, p2;
public:
// set/get/whatever
};
class Rectangle
{
Point p1, p2;
public:
// set/get/whatever
};
// А теперь я хочу вписанный в прямоугольник овал
class EllipseInRectangle
{
Ellipse _ellipse;
Rectangle _rect;
// Тут четыре Point, но необходимо и достаточно две точки
public:
// И что делать будем?
};
По аналогии могут быть ситуации с лишними методами. Композиция как правило намного лучше реализует отношение «много в одном», а наследование позволяет переопределять поведение базовых классов. Паттерн «состояние», например, реализуется посредством синергии композиции с наследованием. Так объясните мне пожалуйста, зачем ограничиваться одним инструментом?
Аналогично можно пытаться создавать какой-либо класс, который наследуется от базового, если базовый не описан в include.
Компилятор просто не знает что за символ использовать и ему надо об этом рассказать.
А если будет другая ситуация: в методе foo() класса M вызвать аналогичный метод предка (super.foo()), то какой метод вызовется?
Тот факт, что в вашем абстрактом классе нет публичных переменных и реализаций методов, не означает, что их туда никто не добавит потом.
interface Repr {
default String repr() {
return getClass().getSimpleName() + "(" + value() + ")";
}
String value();
}
?
Точно такой-же метод вы могли бы написать в каком-нибудь классе Utils.
А чем она хороша, зачем это надо?
А вот агрегация на пару с DI, а далее и IoC решают все описанные проблемы.
— Ну… Не совсем!
— В каком плане?
— Не один из его методов не должен иметь реализации.
Самое печальное, что здесь если даже «не» убрать, все равно получается белиберда.
class A
{
public void MethodA(int val){
return val+1;
}
}
class B{
A _a;
B(A a){
_a = a;
}
public int MethodB(int val){
val +=3;
return _a.MethodA(val);
}
}
Так вот, если в конструктор B передать вместо типа A интерфейс (через который реализован Mock), то можно легко закрыть тестами два класса, а вот если один — то в тесте нужно будет учитывать логику поведения логики двух одновременно классов.
2) Экономить везде на спичках тоже не очень хорошо, всегда открываю профайлер и смотрю где находятся участки, которые нужно «подмазать» и на моей памяти еще ни разу не приходилось править виртуальные методы.
Вот я ещё в С# и джаве не задумывался на эту тему. Если начинаются такие мысли, то надо подумать, а то ли ты делаешь.
Эх…
Я вот считаю, что указатели и pointer arithmetic — это важные фичи, и не пишу на Java. Но Java сознательно спроектированна так, что «может быть полезные» фичи приносятся в жертву простоте и унификации.
Кто мешает игнорировать опасные фичи? Зачем сознательно сужать сферу применимости инструмента?
А кто мешает пользоваться ядерным оружием только для полезных вещей (вроде изменения ланшафта), зачем запрещать любое. его использование? Очевидно, потому что слишком сильные последствия.
1. В Java программе может использоваться сотни разных библиотек, как вы сможете гарантировать, что автор одной из них не добавит опасную фичу?
2. Придется контролировать всех junior'ов и самоучек, чтобы они не использовали эти фичи. Зачем опытным разработчикам тратить на это время?
3. В мире полоно дилетантов и самоучек, для которых даже циклы что-то сложное (реально видел код состоящий из сотен копипащенных строчек, потому что цикл это думать надо). Если у них будет опасный инструмент — в какой-то момент появится куча кривого и глючного софта. который будет ассоцироваться с языком,
4. Если опасную фичу не стоит использовать никому — то зачем она нужна? Если бы можно было сказать — а теперь игнорируем опасные фичи и их не используем — то Java и C# оказались бы не нужны, хватило C++, где все игноруют опасые фичи,
5. Каждая ненужная фича усложняет язык и порог вхождения сильно увеличивается. И получается, что изучить Java нужно полгода, изучить на том же уровне C++ — 2 года, и хуже многие программисты просто не осилят такую сложность, а значит дефицит кадров,
как вы сможете гарантировать, что автор одной из них не добавит опасную фичу?Я не должен заботиться об этом, ибо сфера ответственности разработчика библиотеки.
Придется контролировать всех junior'ов и самоучек, чтобы они не использовали эти фичи.То есть без этого никого контролировать не нужно? Код-ревью, статические анализаторы и прочие линтеры. Банальные документы-соглашения о процессе разработки.
В мире полоно дилетантов и самоучек, для которых даже циклы что-то сложноеЭто будет проблемой инструмента лишь в случае, если опасная фича будет необходимой. В остальном же это будет «terra incognita» для избранных.
Если опасную фичу не стоит использовать никомуЕсли звезды зажигают, значит кому-то это нужно. Даже если это не вы.
Каждая ненужная фича усложняет язык и порог вхождения сильно увеличиваетсяТуда же. Насчет порога вхождения: если вы ее не используете в повседневной работе, то порог не изменяется.
Я не должен заботиться об этом, ибо сфера ответственности разработчика библиотеки.
Да ладно. Вы сдали программу заказчику, а она во время продашена начала падает и вызывает синий экран смерти ОС каждые 15 минут. Чья это проблема ваша или разработчика опенсорс библиотеки? Заказчика не будет волновать чья это сфера ответвенности, его будет волновать вопрос почему он несет миллионые убытки. А даже просто обнаружить какая библиотека использует опасные фичи — нетревиальная задача, тем более заменить ее во время продакшена.
То есть без этого никого контролировать не нужно? Код-ревью, статические анализаторы и прочие линтеры. Банальные документы-соглашения о процессе разработки.
Нужно, но чем меньше у начинающих выстрелить в ногу — тем лучше.
Туда же. Насчет порога вхождения: если вы ее не используете в повседневной работе, то порог не изменяется.
Нет, вы не можете считаться опытным разработчиком, если не знаете все фичи языка и возможные проблемы. Иначе какой вы сеньер, если не можете прочитать обычный код на этом языке и не понимаете его проблем?
Если звезды зажигают, значит кому-то это нужно. Даже если это не вы.
А их не зажигают, на C# и Java большинстом разрабатывающих язык от них отказались. Для тех кому нужно оставили возможность писать небезопасный код на C++ или небезопасные блоки на C#.
Это будет проблемой инструмента лишь в случае, если опасная фича будет необходимой. В остальном же это будет «terra incognita» для избранных.
Тогда ответьте зачем появилась Java и C# вместо С++? Можно было бы просто сказать, а теперь мы не используем опасные фичи. Любая фича влечет в себя проблемы поддержки и обратной совместимости, необходимости ее знать всем пользователям. Зачем нужно было придумывать Java смысл которой убрать из С++ самые спорные и опасные фичи (вроде указателей), если можно было просто не использовать?
Чья это проблема ваша или разработчика опенсорс библиотеки?Какое отношение низкое качество библиотеки имеет к фичам в языке?) Самый очевидный ответ — архитектора, который решил, что использование конкретной библиотеки будет уместно, ибо есть куча софта, код которого вам недоступен или защищен он фиксиков лицензионным соглашением.
чем меньше у начинающих выстрелить в ногу — тем лучше.Хорошее — хорошо, плохое — плохо. Только если эта простота вызвана меньшей гибкостью системы, то это будет больше кода, багов и… сложность поддержки)
Нет, вы не можете считаться опытным разработчиком, если не знаете все фичи языка и возможные проблемы.«Порог вхождения» — это про джуниоров. Опытные его преодолевают.
на C# и Java большинством разрабатывающих язык от них отказалисьТолько те и другие сейчас костылями себе миксины изобретают, а Java-сообщество воет, что unsafe у них забрать хотят. Это так, навскидку.
Тогда ответьте зачем появилась Java и C# вместо С++?Затем, что не было стандартизации C++ и язык долгое время загибался. Сейчас он вполне позволяет регулировать уровень красноглазия и писать годный высокоуровневый код. Битву за десктопную кроссплатформенность Java проиграла старшему брату к настоящему моменту.
Какое отношение низкое качество библиотеки имеет к фичам в языке?)К фичам — косвенное, а к степени опасности «виртуальной машины» — прямое. Одно дело, когда библиотека иногда, раз в полчаса, не работает и пишет сообщения со стек-трейсами в лог, другое — когда раз в полчаса вмест этого происходит BSOD.
На более низкий порог вхождения откликнутся еще более бестолковые разработчики.
Одно дело, когда библиотека иногда, раз в полчаса, не работает и пишет сообщения со стек-трейсами в лог, другое — когда раз в полчаса вмест этого происходит BSOD.Прикладной софт при всём желании не сделает вам BSOD.
Разработчик ПО несет ответственность за свое ПО, включая использование сторонних библиотек (за используемые библиотеки, по прежнему, несут ответственность поставщики этих библиотек).
Если опустить формальности, то нет никакой лишней ответственности. Курение мануалов, апдейтов и прочих легальных смесей — это обязанность и зона ответственности разработчика ПО.
Контракт, контракт без реализации и т.п. — не очень хорошее определение интерфейса. Дело в том, что интерфейс не возникает исторически как контракт — так декларируется в учебниках, но рассуждать так — идеализм. Интерфейс определяется в процессе разработки. Если вы его определили как "контракт", то с высокой долей вероятности еще не раз перепишете его детали, когда погрузитесь в разработку. Так что, если и "контракт" — то "контракт, написанный задним числом".
Вот неплохое определение, на мой взгляд: "Интерфейс — это общая граница между двумя функциональными объектами".
@Override public T[] values() => container::values;Плюс минус вариации…
— Правда? А что такое интерфейс? Это то же самое что и класс?Определение в стиле «утиной» типизации. Более правильно было бы «класс, который не может иметь состояния», «класс, который не может содержать данные».
— Ну… Не совсем!
— В каком плане?
— Ни один из его методов не должен иметь реализации.
Повторяю, они нужны в первую очередь для того, чтоб иметь возможность эффективно использовать статическую типизацию.
Героям диалога из поста, так как они, судя по всему, не понимают зачем нужна статическая типизация, лучше использовать динамически типизируемые языки вроде Javascript.
— Абстрактный класс может иметь нестатические поля, а интерфейс не может.Потому что в реальном мире в следующей версии никакие правила языка не мешают их добавить в абстрактный класс. А в интерфейс — мешают.
— У моего класса их тоже нет, почему он не интерфейс?
Просто автор видимо не дебажил часами падающие на C++ программы, в которых такой же студент сваял ажурные конструкции из множественного/виртуального наследования, потом запутался в выборе нужного cast при проведении типов и получил UB по лбу.
К слову, в большинстве проектах на C++, на которых я работал, множественное наследование было тупо запрещено. Это к вопросу о том, насколько «успешно» решили эту задачу в C++
Ну, знаете, C++ — не показатель. В нём UB можно получить от любого чиха, и дебажь потом. Что в каком-то случае оно вылезло из-за множественного наследования и неправильного приведения типа — случайность.
В чем реальное отличие от интерфейса?
Абстрактный класс может в себе хранить состояние, а интерфейс — нет
Эта статья — отличный пример того, как нужно строить аргументацию при общении с коллегами! Сохранил в закладки.
Отдельное спасибо за классный перевод!
И это не проблема C++, это проблема любого компилируемого языка: хотите высокую производительность — платите за неё временем компиляции.
Ну окей, отключите -flto или что там у вас на вашей платформе
А зачем? Я пишу на С++ исключительно ради производительности, поэтому LTO мне нужно. Там же, где производительность не критична, я пишу на других языках, а не отключаю LTO.
Насколько я знаю, крупные проекты с LTO часто не собирают даже в релизе — слишком долго. Максимум — компилят так отдельные компоненты.
К слову, а модули не померли вообще? В соответствующей гугл группе мёртвая тишина уже с полгода как. Мои попытки спросить в общей группе isocpp привели к "иди в группу модулей". На заявку вступления в гугл-группу модулей я ответа так и не получил. Или там открытое обсуждение не приветствуется?
Категорически прошу внимательно читать и не подтасовывать. Я не сказал, что она редко _нужна_, я сказал, что она редко _используется_. А используется она редко, в частности, из-за того, что мало где адекватно реализована, и из-за критиканства неосиляторов. Я её использовал и в Python, и в C++ (без общего базового класса), и как-то программы не рухнули и работают без проблем.
Остальной ваш пафос пропускаю мимо за непрактичной банальностью.
В итоге приходится весь код пихать в один файл на несколько тысяч строк, а не удобно разбивать по куче мелких файлов.
В итоге приходится весь код пихать в один файл на несколько тысяч строк, а не удобно разбивать по куче мелких файлов.
Во-первых, самый долгий этап сборки как правило в LTO, а не парсинг заголовочников. Тем более что он не параллелится. Во-вторых, многократный парсинг хедеров чаще связан с тем, что нерадивые кодеры инклюдят много лишнего в хедеры вместо forward declaration. В-третьих, даже в отсутствие модулей, призванных решить эту проблему, существуют PCH.
Во-первых, самый долгий этап сборки как правило в LTO, а не парсинг заголовочников
Даже с отключенным LTO, если объединить все c/cpp файлы в один, скорость компиляции вырастет в разы.
Во-вторых, многократный парсинг хедеров чаще связан с тем, что нерадивые кодеры инклюдят много лишнего в хедеры вместо forward declaration.
И что же делать, если нужен какой-нибудь монструозный Windows.h?
Плюс сам стандарт C++ не одобряет forward declaration для библиотечных типов.
В-третьих, даже в отсутствие модулей, призванных решить эту проблему, существуют PCH.
Это неудобный костыль. Но приходится пользоваться из-за отсутствия других вариантов.
Даже с отключенным LTO, если объединить все c/cpp файлы в один, скорость компиляции вырастет в разы.
В перспективе такой подход лишь усугубляет проблему, т.к. при изменении малейшего участка кода пересобирается не один TU с изменением, а весь проект.
И что же делать, если нужен какой-нибудь монструозный Windows.h?
Можно инклюдить хедеры в *.c/*.cpp файлах — тогда они используются только в тех TU, где они нужны. Иногда большие хедеры являются лишь коллекцией из include'ов хедеров поменьше, лишь некоторые из которых востребованы, классический пример — QtWidgets.
Плюс сам стандарт C++ не одобряет forward declaration для библиотечных типов.
за интерфейс библиотек должны отвечать их авторы. В собственном коде советую «всегда инклюдить аскетичный минимум»
В перспективе такой подход лишь усугубляет проблему, т.к. при изменении малейшего участка кода пересобирается не один TU с изменением, а весь проект.
Редко бывает ситуация, когда меняется только c/cpp без h. А при изменении заголовочного файла пересобирается вообще всё. И тогда будет лучше, если TU будет один, а не несколько.
Можно инклюдить хедеры в .c/.cpp файлах — тогда они используются только в тех TU, где они нужны.
Это подразумевается по умолчанию. Но такое далеко не всегда возможно, и многое придётся инклюдить в заголовочном файле.
за интерфейс библиотек должны отвечать их авторы. В собственном коде советую «всегда инклюдить аскетичный минимум»
Речь о стандартной библиотеке. Forward declarations есть только в виде iosfwd, а вот для всяких vector, algorithm и т.д. их просто нет.
Редко бывает ситуация, когда меняется только c/cpp без h. А при изменении заголовочного файла пересобирается вообще всё. И тогда будет лучше, если TU будет один, а не несколько.
Редкие хедеры нужны в проекте повсеместно, и такие хедеры как правило меняются очень редко. Наиболее подверженные изменениям обычно влияют на 2-3 TU. Возможно, в проекте слишком сильно связанный код? Банальное разделение классов на интерфейс и реализацию оставляет изменяемую часть одному TU. А при разбиении проекта на небольшие библиотеки/плагины инкрементальная сборка проходит быстро и при включенном LTO.
Речь о стандартной библиотеке. Forward declarations есть только в виде iosfwd, а вот для всяких vector, algorithm и т.д. их просто нет.
Я конечно понимаю, что это всё относительно, но лично я не считаю стандартные заголовочники громоздкими.
Наиболее подверженные изменениям обычно влияют на 2-3 TU. Возможно, в проекте слишком сильно связанный код?
Да, код сильно связан, а проекты совсем маленькие — 30-40 файлов, около 10 TU, 100-200 кб сырцов, около 3к SLOC. Там просто нечего разделять.
Банальное разделение классов на интерфейс и реализацию оставляет изменяемую часть одному TU.
Да, это тоже камень в огород C++. Необходимость описания приватных кишков классов в .h вынуждает подключать хедеры не в .cpp, а в .h. Избавиться от этого можно разве что костылём (PImpl).
Я конечно понимаю, что это всё относительно, но лично я не считаю стандартные заголовочники громоздкими.
Компиляторы разные бывают. Intel Compiler, например, генерит очень быстрый код, но делает это очень долго, и добавление и использование джентельменского набора (vector, algorithm, memory и т.д.) увеличивает время компиляции файла в разы.
Полностью не согласен с выводом в конце этого монодиалога. Это абстрактные классы — вредны. Следует из вредности наследнования.
Абстрактный класс — не полностью определенный класс, «полуфабрикат» для наследования.
А интерфейс — контракт.
Лучше в тему подходит тайпскрипт. Любой класс, который удовлетворяет контракту, может быть использован, необязательно чтобы в этом классе было упомянуто «implements». Утиная типизации тоже, конечно, палка о двух концах, но она как раз таки иллюстрирует, что такое контракт, что такое интерфейс, и чем это отличается от класса, который надо наследовать, ака писать «extends»
Вредный Кейворд «Interface»