Comments 100
Плюсанул за DVCS, но сам юзаю hg и очень даже доволен %)
Есть код в репозитории A, его используют в проектах, находящихся в репозиториях B и C. Чтобы избежать дублирования кода и не писать скрипты инсталляции, в svn есть свойство svn:externals, означающая, что svn здесь использует потусторонние силы будет подгружать определённые поддеревья из других репозиториев, причём номер версии можно зафиксировать. Как решается такая проблема в git?
Насчет гита не знаю, но в меркуриале, думаю, это можно решить через hooks
> Chapter 10. Handling repository events with hooks
— это те хуки?
Начиная с версии 1.3 Mercurial (раньше было расширение) может использовать вложенные репозитории. Для внешних репозиториев там же обнаружилась ссылка на расширение hgdeps.
— это те хуки?
Начиная с версии 1.3 Mercurial (раньше было расширение) может использовать вложенные репозитории. Для внешних репозиториев там же обнаружилась ссылка на расширение hgdeps.
git submodule
Ещё есть скрипт git-subtree (появился только нынешней весной), который позволяет хранить в общем репозитории код библиотек, при этом позволяя экспортировать коммиты в другой репозиторий, который содержит только библиотеку. И наоборот.
Правда, также, как и git-submodule, вещь для простых кодеров далеко не очевидная — надо выделять спецчеловека на роль SCM-инженера.
Правда, также, как и git-submodule, вещь для простых кодеров далеко не очевидная — надо выделять спецчеловека на роль SCM-инженера.
можно попробовать gitmodule. вроде оно.
Большое спасибо!!! Как раз сейчас установил git и мне так нехватало нормального руководства на русском языке (для справки, гуглить умею хорошо, но не мог найти именно такого простого и лаконичного объяснения в первых n-цать результатах)
Как насчёт плагина к эклипсе?
а можно сделать, чтобы распределенные репозитории друг с другом автоматически синхронизировались?
планировщик задач?
меня больше интересуют встроенные средства, чтобы после коммита, к примеру. Или еще на каком-то событии. Тоесть, внутренними средствами, с единообразной настройкой для всех ОС
хуки?
Ну, можно хуки использовать.
Там на каждое событие (коммит/пуш/мерж/еще там что) есть отдельный скрипт-обработчик.
В него можно нужные команды положить. У меня таким образом подобие CI сделано:
— один мастер-репозиторий, две ветки — продакшн/стейдж.
— на www два репозитория, которые следят каждый за своей веткой на мастер-репозитории
— хук, который при коммите в мастер-репозиторий говорит git pull для соответсвующего www-репозитория
(да, если кому интересно — могу написать все подробно и пошагово)
Правда, не уверен, что это 100% ОС-независимо, под виндами скорее всего либо баш ставить придется, либо переписывать на батники.
Там на каждое событие (коммит/пуш/мерж/еще там что) есть отдельный скрипт-обработчик.
В него можно нужные команды положить. У меня таким образом подобие CI сделано:
— один мастер-репозиторий, две ветки — продакшн/стейдж.
— на www два репозитория, которые следят каждый за своей веткой на мастер-репозитории
— хук, который при коммите в мастер-репозиторий говорит git pull для соответсвующего www-репозитория
(да, если кому интересно — могу написать все подробно и пошагово)
Правда, не уверен, что это 100% ОС-независимо, под виндами скорее всего либо баш ставить придется, либо переписывать на батники.
спасибо за развернутый ответ
да. очень интересно. допустим, используя redmine приходится вытягивать проект в папку на сервере по крону, (которая доступна для redmine).
Опишите. Когда я искал такие решения, они были с какими-то проблемами и не подходили.
Если вам удалось это сделать удобно — то было бы очень интересно прочитать.
Если вам удалось это сделать удобно — то было бы очень интересно прочитать.
Статья интересна. Я очень приваетствую использование DVCS. В нашей организации перевел весь it на Bazaar и очень доволен.
Был удивлен, касательно, как мне показалось, некоторых лишних телодвижений в git… Например:«Обратите внимание, что, в отличие от SVN, если вы изменили файл, его заново нужно добавить в индекс командой git add.»
Если файл объявлен «версионным» — зачем его опять добавлять? Я не в упрек, просто непонятно.
Из моего личного опыта — перебрал много DVCS и выбрал bazaar как самый логичный. Т.е. я вообще ничего не знающему о dvcs работнику на пальцах объясняю и он просто начинает работать. Даже не возвращаясь в дальнейшем к печатным инструкциям. На втором месте был hg.
bzr init — создали репозиторий
bzr add — добавили все файлы, кроме тех, которые описаны (можно масками) в .bzrignore
bzr ci -m «Initial release» — сделали commit
bzr log — посмотрели что как
bzr branch откуда_сделать_копию — делаем ветку
bzr push — сбросили в центр
bzr pull — взяли из центра…
(естественно есть масса других вариантов организации работы типа update, merge,…
еще :) Предугадывая комментарии — слухи о медленной работе bzr сильно устарели)
Извините, если это никому не покажется интересным — хотел просто поделиться. Если интересно — могу написать о реальном опыте установки и запуска Bazaar
Было интересно прочитать о реальном использовании git. Интересна именно организация работы используя DVCS, ведь именно от этого зависит насколько удобно и полезно будет его использование.
Автору спасибо.
Был удивлен, касательно, как мне показалось, некоторых лишних телодвижений в git… Например:«Обратите внимание, что, в отличие от SVN, если вы изменили файл, его заново нужно добавить в индекс командой git add.»
Если файл объявлен «версионным» — зачем его опять добавлять? Я не в упрек, просто непонятно.
Из моего личного опыта — перебрал много DVCS и выбрал bazaar как самый логичный. Т.е. я вообще ничего не знающему о dvcs работнику на пальцах объясняю и он просто начинает работать. Даже не возвращаясь в дальнейшем к печатным инструкциям. На втором месте был hg.
bzr init — создали репозиторий
bzr add — добавили все файлы, кроме тех, которые описаны (можно масками) в .bzrignore
bzr ci -m «Initial release» — сделали commit
bzr log — посмотрели что как
bzr branch откуда_сделать_копию — делаем ветку
bzr push — сбросили в центр
bzr pull — взяли из центра…
(естественно есть масса других вариантов организации работы типа update, merge,…
еще :) Предугадывая комментарии — слухи о медленной работе bzr сильно устарели)
Извините, если это никому не покажется интересным — хотел просто поделиться. Если интересно — могу написать о реальном опыте установки и запуска Bazaar
Было интересно прочитать о реальном использовании git. Интересна именно организация работы используя DVCS, ведь именно от этого зависит насколько удобно и полезно будет его использование.
Автору спасибо.
забавно.
смотрю список команд базара и вижу меркуриал — заменив bzr на hg получаем верные команды того же значения.
занятно, надо будет и bzr поглядеть.
hg — прекрасен!
смотрю список команд базара и вижу меркуриал — заменив bzr на hg получаем верные команды того же значения.
занятно, надо будет и bzr поглядеть.
hg — прекрасен!
да, они очень похожи, но не идентичны. Принципиально другой подход, который мне лично более логичным показался у bzr
если интересно — могу дать ссылку на очень достойный русскоязычный блог по bazaar
вернее, не побоюсь, наконец, и дам ссылку ибо она будет очень полезна начинающим…
если интересно — могу дать ссылку на очень достойный русскоязычный блог по bazaar
вернее, не побоюсь, наконец, и дам ссылку ибо она будет очень полезна начинающим…
в свою очередь напомню всем об абсолютно шикарной и свободной(!) книге по меркуриалу, вдруг пригодится: hgbook.
> Если файл объявлен «версионным» — зачем его опять добавлять? Я не в упрек, просто непонятно
На этот случай есть «git commit -a», закоммитит изменения во всех «версионных» файлах.
На этот случай есть «git commit -a», закоммитит изменения во всех «версионных» файлах.
Что можно сделать — понятно. Интересно именно зачем это сделано идеологически.
Т.е. в системе файл объявлен версионным. Зачем его опять добавлять?
Если это необходимо, но долго объяснять — можно этого не делать ибо интерес к git только теоретический — я своей dvcs более чем доволен.
Спасибо
Т.е. в системе файл объявлен версионным. Зачем его опять добавлять?
Если это необходимо, но долго объяснять — можно этого не делать ибо интерес к git только теоретический — я своей dvcs более чем доволен.
Спасибо
Очевидно, чтобы изменения, сделанные в версионных файлах, можно было не коммитить. Скажем, работаешь над новой функциональностью, по ходу дела замечаешь баг и исправляешь его. Делаешь add только тех файлов, в которых исправлялся баг, и недопиленный кусок новой функциональности не коммитится.
Или, что у меня гораздо чаще случается, чем описанное оратором выше: часто начинаешь делать изменения, а потом замечаешь, что коммиттить их в будущем надо будет не в эту, а в другую ветку. Для этого делаешь git add, потом, вроде git reset --soft (я пользуюсь GUI-интерфейсом gitk для этого, не знаю точных ключей) и дальше продолжаешь модифицировать изменения, после чего комиттишь.
Кстати, пользуясь svn я часто тоже делаю аналог git add: есть специальный скриптик, который запускается командой «sv» перед коммитом для того, что бы отследить изменения в текущем каталоге, которые будут закоммитчены.
Кстати, пользуясь svn я часто тоже делаю аналог git add: есть специальный скриптик, который запускается командой «sv» перед коммитом для того, что бы отследить изменения в текущем каталоге, которые будут закоммитчены.
>> Если файл объявлен «версионным» — зачем его опять добавлять? Я не в упрек, просто непонятно.
Файл добавляется не в репозиторий, а только в ближайший коммит. Таким образом, имеется возможность выбрать, какие файлы закоммитить, а какие нет.
Файл добавляется не в репозиторий, а только в ближайший коммит. Таким образом, имеется возможность выбрать, какие файлы закоммитить, а какие нет.
про скорость: www.python.org/dev/peps/pep-0374/#tests-impressions
В тестировании bzr 1.12
Текущая версия 1.17
готовится 2.0, где много внимания уделено именно скорости работы.
Базар изначально проектировался как замена dvcs (GNU Arch) и главной целью было создание удобного и дружественного интерфейса пользователя. Оптимизацией скорости работы этой системы начали заниматься несколько позднее, используя в качестве наглядного примера Гит и Меркуриал.
Так что в первую очередь было удобство, а скорость уже оптимизируют. Не скажу, что догнали hg по скорости на данный момент, но bzr очень активно развивается — в среднем минорный релиз ~ раз в месяц.
Я не агитирую, просто попробовав hg и bzr — последний меня устроил значительно больше. Огромных репозиториев у меня нет и затраты на производительность вполне окупаются легкостью обучения разработчиков и удобством пользования. Естественно, это субьективное мнение. Не будем спорить.
Спасибо за ссылку, я это видел, когда выбирал систему. На данный момент она уже не соответствует действительности (по скорости)
Текущая версия 1.17
готовится 2.0, где много внимания уделено именно скорости работы.
Базар изначально проектировался как замена dvcs (GNU Arch) и главной целью было создание удобного и дружественного интерфейса пользователя. Оптимизацией скорости работы этой системы начали заниматься несколько позднее, используя в качестве наглядного примера Гит и Меркуриал.
Так что в первую очередь было удобство, а скорость уже оптимизируют. Не скажу, что догнали hg по скорости на данный момент, но bzr очень активно развивается — в среднем минорный релиз ~ раз в месяц.
Я не агитирую, просто попробовав hg и bzr — последний меня устроил значительно больше. Огромных репозиториев у меня нет и затраты на производительность вполне окупаются легкостью обучения разработчиков и удобством пользования. Естественно, это субьективное мнение. Не будем спорить.
Спасибо за ссылку, я это видел, когда выбирал систему. На данный момент она уже не соответствует действительности (по скорости)
Git разделяет изменение индекса и коммит.
Значение файлов сохраняется при добавлении в индекс, соответственно есть три варианта git diff.
$ echo 'created' >file
$ git add file
$ echo 'updated' >file
$ git diff file # относительно индекса
@@ -1 +1 @@
-created
+updated
$ git diff --cached # в индексе
@@ -0,0 +1 @@
+created
$ git diff HEAD # от последнего коммита
diff --git a/file b/file
@@ -0,0 +1 @@
+updated
При коммите сохраняется текущий индекс. Команда git commit -a эквивалентна
git add -u # добавляем в индекс измененные файлы
git commit
Значение файлов сохраняется при добавлении в индекс, соответственно есть три варианта git diff.
$ echo 'created' >file
$ git add file
$ echo 'updated' >file
$ git diff file # относительно индекса
@@ -1 +1 @@
-created
+updated
$ git diff --cached # в индексе
@@ -0,0 +1 @@
+created
$ git diff HEAD # от последнего коммита
diff --git a/file b/file
@@ -0,0 +1 @@
+updated
При коммите сохраняется текущий индекс. Команда git commit -a эквивалентна
git add -u # добавляем в индекс измененные файлы
git commit
Чем еще Git удобнее чем SVN — это лучшей совместимостью с WebDAV-серверами (когда нужно не через «родной» протокол запускать обмен, а по HTTP). Для Git инструкция по дружбе с веб-сервером умещается в несколько строк — www.eserv.ru/GitEservHowTo
И в mercurial есть встроенный сервер `hg serve`, на который достаточно лишь настроить проксирвоание. Один сервер может работать с как с одним, так и с несколькими репозиториями и именованными коллекциями репозиториев.
Не знаю, что значит лучше: Visual SVN прекрасно работает через http «искаропки» (фактически это — апач с svn-модулем).
вопрос знатокам: в репозитории есть файлик local.properties. его содержимое различается на разных компах, но он должен быть в репозитории. после выполнения git clone правим этот файл, и командой «git update-index --assume-unchanged local.properties» предотвращаем закоммичивание локальных изменений. проблема: как сохранить эти изменения при выполнении команд pull или reset?
Около полугода назад я пытался настроить git под виндой. Почему-то не получилось.
Сейчас с этим получше?
Сейчас с этим получше?
спасибо, интересно
хотелось бы еще про mercurial статью доступным языком
хотелось бы еще про mercurial статью доступным языком
А я всё ещё использую SVN & TFS — довольна. :)
Супер! Спасибо за отличную статью! Я сам недавно перешел на Git, очень прусь и всем рекомендую.
А вот тут translated.by/you/git-community-book/into-ru/trans/ мы переводим лучшую книгу по Git на русский (книга под GPL), присоединяйтесь к нам! Уже переведено 26%!
А вот тут translated.by/you/git-community-book/into-ru/trans/ мы переводим лучшую книгу по Git на русский (книга под GPL), присоединяйтесь к нам! Уже переведено 26%!
Надо отметить, что в SVN, конечно, есть ветки, но сделаны они, видимо, для другого, и поэтому плохо приспособлены для того, чтобы их сливать в trunk.
Ключевое слово выделено жирным. Как бы надо немного разобраться с трехсторонним мерджем и все становится просто супер.
Эта же ветка заливалась на продакшн. Главное неудобство здесь — то, что если мы производим какие-то изменения, или разрабатываем новый функционал, мы вынуждены либо сидеть и не коммитить до тех пор, пока задача не будет доделана до конца, либо (если нам нужна помощь коллеги), закоммитить недоделанный функционал, как есть, сделав таким образом trunk непригодным к заливке на продакшн. Особенно это неприятно, если новый функционал делается не один день, а в это время возникает необходимость что-нибудь срочно починить в рабочей системе.
Я бы таких горе-разработчиков уволил на хер. Это НЕ вопрос используемой системы контроля версий, а построенного процесса и дисциплины.
Ключевое слово выделено жирным. Как бы надо немного разобраться с трехсторонним мерджем и все становится просто супер.
Эта же ветка заливалась на продакшн. Главное неудобство здесь — то, что если мы производим какие-то изменения, или разрабатываем новый функционал, мы вынуждены либо сидеть и не коммитить до тех пор, пока задача не будет доделана до конца, либо (если нам нужна помощь коллеги), закоммитить недоделанный функционал, как есть, сделав таким образом trunk непригодным к заливке на продакшн. Особенно это неприятно, если новый функционал делается не один день, а в это время возникает необходимость что-нибудь срочно починить в рабочей системе.
Я бы таких горе-разработчиков уволил на хер. Это НЕ вопрос используемой системы контроля версий, а построенного процесса и дисциплины.
> надо немного разобраться с трехсторонним мерджем и все становится просто супер.
Вы про SVN 1.5, видимо? На тот момент его ещё не было.
Вы про SVN 1.5, видимо? На тот момент его ещё не было.
К сожалению, иногда увольнять надо и горе-менеджеров: часто задача достижения определённого «километрового столба» ставится приоритетной, в trunk происходит активная интеграция, а потом вдруг всё глохнет, а актуальной задачей становится, например, релиз с новой, необходимой бизнесу, функциональностью.
С Subversion`овским мерджем в таком сценарии использования остаётся только курить бамбук и реализовывать в новой интеграционной ветке, в том числе, часть функциональности, которая уже замерджена в заглохший trunk. Даже после версии 1.5, чей мердж иногда сглюкивает (в частности, на репозиториях, которые родились до 1.5 или на которых активно поколдовали с помощью svk) и приходится откатываться на покоммитный мердж. :(
А когда заказчик trunk-а оживёт, придётся синхронить изменения, сделанные в релизной ветке с trunk.
С Subversion`овским мерджем в таком сценарии использования остаётся только курить бамбук и реализовывать в новой интеграционной ветке, в том числе, часть функциональности, которая уже замерджена в заглохший trunk. Даже после версии 1.5, чей мердж иногда сглюкивает (в частности, на репозиториях, которые родились до 1.5 или на которых активно поколдовали с помощью svk) и приходится откатываться на покоммитный мердж. :(
А когда заказчик trunk-а оживёт, придётся синхронить изменения, сделанные в релизной ветке с trunk.
столбы приравниваются к релизам. релиз — это отдельная ветка от транка и он довольно долго обкатывается прежде чем попасть в продакшн
Я больше не о терминологии (в некотором смысле, trunk — это «следующий/планируемый/текущий/нестабильный релиз»). А о том, что на Subversion в силу того, что встроенный механизм слияния имеет серьёзные ограничения и того, что замердживаемые изменения сами могут быть замерджены (причём, возможно, пофайлово, а не целым деревом), сложнее вести два релиз-бренча одновременно.
Приходится либо реализовывать идентичные изменения независимо (что потом приведёт к конфликтам), либо мерджить изменения поштучно (что приведёт к большой ручной работе, если засбоит новый механизм автомерджа в Subversion).
Приходится либо реализовывать идентичные изменения независимо (что потом приведёт к конфликтам), либо мерджить изменения поштучно (что приведёт к большой ручной работе, если засбоит новый механизм автомерджа в Subversion).
не согласен — у нас в SVN репозитории сейчас 3 активных релиз бранча
0908 — это на продакшн сервере
0909 — в выходные будет go-live
0910 — это на следующий месяц, был ответвлён из trunk в эти выходные
по одному на каждый месяц. release maitainer каждое утро сливает все change setы — конфликтов за несколько лет работы практически не было.
выглядит это просто: утром запускается автоматические merges
0910->trunk->0909,0908
0909->trunk->0910,0908
0908->trunk->0909,0910
притом из-за специфика SVN мы переносим все changesets как одну ревизию кода. все разработки ведутся не в trunk а в отдельных ветках, которые потом вливаниются в trunk перед тем как создаётся новая релиз ветка.
0908 — это на продакшн сервере
0909 — в выходные будет go-live
0910 — это на следующий месяц, был ответвлён из trunk в эти выходные
по одному на каждый месяц. release maitainer каждое утро сливает все change setы — конфликтов за несколько лет работы практически не было.
выглядит это просто: утром запускается автоматические merges
0910->trunk->0909,0908
0909->trunk->0910,0908
0908->trunk->0909,0910
притом из-за специфика SVN мы переносим все changesets как одну ревизию кода. все разработки ведутся не в trunk а в отдельных ветках, которые потом вливаниются в trunk перед тем как создаётся новая релиз ветка.
1) А если высшее руководство попросит часть изменений, запланированных в ветке 0910, срочно сделать и включить на выходных, а изменения 0909 притормозить до неизвестных времён, то что вы будете делать?
2)
> выглядит это просто: утром запускается автоматические merges
> 0910->trunk->0909,0908
> 0909->trunk->0910,0908
Т.е. 0908 содержит все изменения из свежих веток? А в чём тогда разница между ними? Или merge не автоматические, а, таки, выборочные?
2)
> выглядит это просто: утром запускается автоматические merges
> 0910->trunk->0909,0908
> 0909->trunk->0910,0908
Т.е. 0908 содержит все изменения из свежих веток? А в чём тогда разница между ними? Или merge не автоматические, а, таки, выборочные?
1) Ситуация исключена на организационном уровне. Клиентов готовят к тому, что их проект будет частью определённого релиза.
2) Релиз ветки, как явление, не содержат изменений вообще, только баг-фиксы. Все изменения в отдельных ветках, которые попадаю в trunk. Из него раз в месяц ответвляется новый релиз. Баг фиксы, соответственно, делаются только в релиз ветках (один раз) и пропагируют оттуда в trunk и другие ветки. Этим занимаются branch managers.
Вообще это стандартная практика. Release Driven Development.
2) Релиз ветки, как явление, не содержат изменений вообще, только баг-фиксы. Все изменения в отдельных ветках, которые попадаю в trunk. Из него раз в месяц ответвляется новый релиз. Баг фиксы, соответственно, делаются только в релиз ветках (один раз) и пропагируют оттуда в trunk и другие ветки. Этим занимаются branch managers.
Вообще это стандартная практика. Release Driven Development.
1) Вот-вот. Я как раз и писал (выше по треду), что определённые орг. проблемы порождают определённые сложности при работе с Subversion, которые перестают быть таковыми при использовании Git. Эти орг. проблемы, конечно, решаются, но слишком уж мелкими шажками.
Собственно, я для основных проектов git использую в совокупности с оставшимся в наследство svn хранилищем. При этом перенос коммитов между ветками делается без потери семантики «коммит»/«изменение»/«фича» с помощью rebase. И в этом и заключается основная крутизна Git, как DVCS/DSCM: независимость своей ветки кода от чужой. И этим активно пользуются open source проекты, т.к. у них ситуация, когда «пропадает» разработчик (он же часто и заказчик) той или иной фичи, случается гораздо чаще, чем в процессе «нормальной разработки». И семь остальных фич заглохшую ждать при релизе не будут.
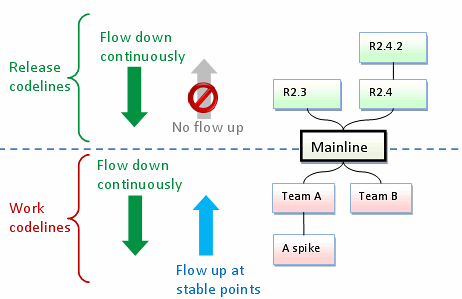
Кстати, в приведённом в (1) сценарии использования основная засада — не «быстро-быстро» внедрить 0910 (любой мало-мальски грамотный руководитель такого никогда не попросит, хотя у нас и так бывает иногда), а отказаться в ближайшей версии (и в trunk) от некоторых изменений, которые уже оттестированы (и замерджены в trunk) в ближайшем накате (см. пункт 0909->trunk->0910,0908). Этот сценарий гораздо более част в жизни из-за real life забот (политика, юр. обязательства и т.п.). В Subversion этому поможет только политика «стабильный trunk», когда изменения в trunk попадают только после успешного деплоя фича-брэнча (спасибо за картинку в комменте внизу — как раз иллюстрирует этот подход). Иначе в trunk придётся делать малокрасивый коммит «обратного диффа». С которым потом (когда части заблокированных изменений, наконец, дадут зелёный свет) непонятно, что делать, т.к. всё, что при этом остаётся в trunk — это коммит с текстовым changelog (в лучшем случае) и кучей каких-то непонятных изменений: какие изменения надо накатывать из «забаненного» фича-бренча — непонятно.
(2)
> Релиз ветки, как явление, не содержат изменений вообще, только баг-фиксы.
Т.е. у вас, на самом деле, изменения не автоматические, как на картинке, а выполняются SCM-инженером (или тимлидом) по необходимости. Тогда понятно — это единственный нормальный подход при наличии хотя бы минимального управления/vision/предсказания у проекта (и описано везде, включая svn book). Проблема, что не все проекты такие — в частности, многие задачи поддержки/эксплуатации существующих систем жёстко привязаны к реальной жизни и изменения, происходящие в ней мгновенно сказываются на проекте, не позволяя ждать следующего цикла.
Собственно, я для основных проектов git использую в совокупности с оставшимся в наследство svn хранилищем. При этом перенос коммитов между ветками делается без потери семантики «коммит»/«изменение»/«фича» с помощью rebase. И в этом и заключается основная крутизна Git, как DVCS/DSCM: независимость своей ветки кода от чужой. И этим активно пользуются open source проекты, т.к. у них ситуация, когда «пропадает» разработчик (он же часто и заказчик) той или иной фичи, случается гораздо чаще, чем в процессе «нормальной разработки». И семь остальных фич заглохшую ждать при релизе не будут.
Кстати, в приведённом в (1) сценарии использования основная засада — не «быстро-быстро» внедрить 0910 (любой мало-мальски грамотный руководитель такого никогда не попросит, хотя у нас и так бывает иногда), а отказаться в ближайшей версии (и в trunk) от некоторых изменений, которые уже оттестированы (и замерджены в trunk) в ближайшем накате (см. пункт 0909->trunk->0910,0908). Этот сценарий гораздо более част в жизни из-за real life забот (политика, юр. обязательства и т.п.). В Subversion этому поможет только политика «стабильный trunk», когда изменения в trunk попадают только после успешного деплоя фича-брэнча (спасибо за картинку в комменте внизу — как раз иллюстрирует этот подход). Иначе в trunk придётся делать малокрасивый коммит «обратного диффа». С которым потом (когда части заблокированных изменений, наконец, дадут зелёный свет) непонятно, что делать, т.к. всё, что при этом остаётся в trunk — это коммит с текстовым changelog (в лучшем случае) и кучей каких-то непонятных изменений: какие изменения надо накатывать из «забаненного» фича-бренча — непонятно.
(2)
> Релиз ветки, как явление, не содержат изменений вообще, только баг-фиксы.
Т.е. у вас, на самом деле, изменения не автоматические, как на картинке, а выполняются SCM-инженером (или тимлидом) по необходимости. Тогда понятно — это единственный нормальный подход при наличии хотя бы минимального управления/vision/предсказания у проекта (и описано везде, включая svn book). Проблема, что не все проекты такие — в частности, многие задачи поддержки/эксплуатации существующих систем жёстко привязаны к реальной жизни и изменения, происходящие в ней мгновенно сказываются на проекте, не позволяя ждать следующего цикла.
Если у вас есть трудности с svn, возможно, имеет смысл посмотреть сюда — не исключено, что будет полезно (если вы еще не видели, конечно): www.infoq.com/articles/agile-version-control
отличный материал. на хабре, кстати, не хватает статей именно на тематику теоретического использования систем контроля версий
Да, я читал, хороший текст. Но, тем не менее, описанный подход всё равно требует определённого разумного планирования, к примеру, в том, что бы Stories не пересекались. Вообще, может, по комменту, на который вы отвечали, не очень заметно, но в комментах
habrahabr.ru/blogs/development/68341/#comment_1939100
habrahabr.ru/blogs/development/68341/#comment_1939795
речь пошла о том, что вопросы плохой организации/проектирования/архитектуры осложняют работу с Subversion. Конечно, такие моменты осложнят и работу с git, но, как мне кажется, с конкретной задачей подготовки двух релизов в условиях гонки лучше справляется git, чем svn, т.к. встроенные механизмы rebase и merge сохраняют семантику «коммит» и благодаря этому людям, ответственным за каждый из релизов проще управлять изменениями, наработанными во время гонки другой командой (для другого релиза).
habrahabr.ru/blogs/development/68341/#comment_1939100
habrahabr.ru/blogs/development/68341/#comment_1939795
речь пошла о том, что вопросы плохой организации/проектирования/архитектуры осложняют работу с Subversion. Конечно, такие моменты осложнят и работу с git, но, как мне кажется, с конкретной задачей подготовки двух релизов в условиях гонки лучше справляется git, чем svn, т.к. встроенные механизмы rebase и merge сохраняют семантику «коммит» и благодаря этому людям, ответственным за каждый из релизов проще управлять изменениями, наработанными во время гонки другой командой (для другого релиза).
А подскажите, пожалуйста, меня, как человека, настраивавшего гит, мучают вопросы по более приземленным вещам, чем просто работа с ним:
Есть проект на некотором удаленном сервере. Есть ряд разработчиков, которым предпочтителен HTTP/HTTPS-доступ. И есть необходимость ограничивать различным разработчикам доступ в различные ветки(т.е., например, в master что-то коммитить может только head developer). Доступ через DAV не позволяет ограничивать доступ какими-то ветками, т.е. любой может спокойно накоммитить всякого куда угодно, если у него вообще есть права на запись.
Я не понял, предоставляет ли возможность делать такие ограничения gitosis, но в любом случае не хотелось бы связываться с доступом через ssh, введением ключей вместо паролей и т.п.
Можно ли как-нибудь реализовать такие ограничения?
Есть проект на некотором удаленном сервере. Есть ряд разработчиков, которым предпочтителен HTTP/HTTPS-доступ. И есть необходимость ограничивать различным разработчикам доступ в различные ветки(т.е., например, в master что-то коммитить может только head developer). Доступ через DAV не позволяет ограничивать доступ какими-то ветками, т.е. любой может спокойно накоммитить всякого куда угодно, если у него вообще есть права на запись.
Я не понял, предоставляет ли возможность делать такие ограничения gitosis, но в любом случае не хотелось бы связываться с доступом через ssh, введением ключей вместо паролей и т.п.
Можно ли как-нибудь реализовать такие ограничения?
Можно закрыть определённые файлы ref`ов (т.е., по сути, ветки) средствами DAV сервера.
Ну, у меня работа с DAV идёт средствами апачевского mod_dav, приблизительно так:
То есть, DAV позволяет разрешить чекауты всем, но любая операция коммита требует авторизации из файла паролей. Насколько я вижу в access-логе апача, для ограничения коммита мне придётся на "/myrepo.git/refs/heads/master" поставить ограничение на LOCK отдельным файлом паролей. Это довольно неудобно и требует перечитывания конфига апача при каждом добавлении/изменении веток с ограничениями.
В dav_svn я могу в authz-файле указать права просто как:
И изменять права доступа к любым веткам, не касаясь апача.
А у гита получается непосредственная работа с апачевским конфигом, плюс дублирование записей о паролях для каждого отдельного проекта/каталога, к которому разработчик имеет доступ.
Если второе еще можно пережить, то первое как-то очень неудобно.
<Directory "/home/git/myrepo.git/">
Dav on
Order Allow,Deny
Allow from all
AuthType Basic
AuthName Git
AuthUserFile "/path/to/dav_git.passwd"
<LimitExcept GET PROPFIND OPTIONS REPORT>
Require valid-user
</LimitExcept>
</Directory>
То есть, DAV позволяет разрешить чекауты всем, но любая операция коммита требует авторизации из файла паролей. Насколько я вижу в access-логе апача, для ограничения коммита мне придётся на "/myrepo.git/refs/heads/master" поставить ограничение на LOCK отдельным файлом паролей. Это довольно неудобно и требует перечитывания конфига апача при каждом добавлении/изменении веток с ограничениями.
В dav_svn я могу в authz-файле указать права просто как:
[myrepo:/trunk]
headdev=rw
seconddev=rw
*=r
[myrepo:/branches/mybranch]
headdev=rw
someoneelse=rw
*=r
И изменять права доступа к любым веткам, не касаясь апача.
А у гита получается непосредственная работа с апачевским конфигом, плюс дублирование записей о паролях для каждого отдельного проекта/каталога, к которому разработчик имеет доступ.
Если второе еще можно пережить, то первое как-то очень неудобно.
Можно также прикрутить к апачу модуль (например, mod_perl) и навесить обработчик на стадию аутентификации и авторизации (по такому же пути можно осуществить авторизацию через LDAP). Наверняка это уже где-то есть в гугле — к сожалению именно сопряжением webdav с гитом я не занимался, что бы более адресно помочь.
Вот я искал что-то и решений не нашёл…
Вам, может, будет проще прописать не полные урлы для ограничения, а маски путей. Тогда не придётся менять конфиг каждый раз. Или посмотрите на другие DAV сервера, например на nginx`овский (я с ним не работал, но судя по примерам конфигов в гугле, он довольно тонко настраивается).
Ещё попробуйте посмотреть, как это сделано в github/gitweb для mob веток (я не смотрел).
В общем, это не проблема git, а проблема выбранного способа доступа к файлам.
Лучше, конечно, сделать, как предложил maxcom ниже — это и нагляднее, и привычнее (вспомним систему интеграции, которой придерживается проект linux ядра).
Ещё попробуйте посмотреть, как это сделано в github/gitweb для mob веток (я не смотрел).
В общем, это не проблема git, а проблема выбранного способа доступа к файлам.
Лучше, конечно, сделать, как предложил maxcom ниже — это и нагляднее, и привычнее (вспомним систему интеграции, которой придерживается проект linux ядра).
В gitweb я возможности подобных ограничений тоже не нашел, а гитхаб, если я ничего не путаю, сам по себе закрытый.
Другого способа доступа к файлам без привлечения ssh я, увы, не нашел :) Есть, конечно, git-daemon, но он работает только на чекауты, а не на коммиты.
Устраивать отдельные репозитории для «закрытых» и «общих» веток — это всё-таки, имхо, бардак. Проще сказать: «разрабатывайте, как хотите, а мне присылайте патчи».
Другого способа доступа к файлам без привлечения ssh я, увы, не нашел :) Есть, конечно, git-daemon, но он работает только на чекауты, а не на коммиты.
Устраивать отдельные репозитории для «закрытых» и «общих» веток — это всё-таки, имхо, бардак. Проще сказать: «разрабатывайте, как хотите, а мне присылайте патчи».
> разрабатывайте, как хотите, а мне присылайте патчи
В общем-то, Торвальдс так и сделал, за исключением того, что у него есть доверенные замы (как он выражается, лейтенанты) по разным подсистемам, с которых он мерджит.
Кстати, ваши люди вполне могут сами работать с master демократичным образом, но «официальная» версия master будет только у вас и вы её будете регулярно накатывать на репозиторий (push -f). Это, конечно, плохо тем, что тем разработчикам, кто ранее склонировал master с общего сервера придётся rebase-ить его на за-push-еный вами.
В общем, если сложно настроить DAV, то выходов куча.
Я бы всё-таки сделал иерархию ref`ов с ограничением доступа в конфиге апача, если ничего лучшего нет. Либо найдите перловика, который ограничит доступ через mod_perl. Ещё лучше, конечно поставить ssh, а для людей, сидящих под файрволом вывесить ssh на 443 порту.
В общем-то, Торвальдс так и сделал, за исключением того, что у него есть доверенные замы (как он выражается, лейтенанты) по разным подсистемам, с которых он мерджит.
Кстати, ваши люди вполне могут сами работать с master демократичным образом, но «официальная» версия master будет только у вас и вы её будете регулярно накатывать на репозиторий (push -f). Это, конечно, плохо тем, что тем разработчикам, кто ранее склонировал master с общего сервера придётся rebase-ить его на за-push-еный вами.
В общем, если сложно настроить DAV, то выходов куча.
Я бы всё-таки сделал иерархию ref`ов с ограничением доступа в конфиге апача, если ничего лучшего нет. Либо найдите перловика, который ограничит доступ через mod_perl. Ещё лучше, конечно поставить ssh, а для людей, сидящих под файрволом вывесить ssh на 443 порту.
git не поддерживает такие ограничения. Можно хранить master в отдельном репозитарии, в который писать может только head developer, а остальные разработчики — только читать. Соответственно остальным выдать репозиторой «песочницу», в которой они будут жить, и из которой будет вытягивать нужные изменения head developer.
Честно говоря меня ветки в svn полностью устраивают. Trunk всегда готов к загрузке на продакшн, любые серьёзные изменения делаются в ветках, мердж, за исключением некоторых ситуаций, происходит без проблем. При необходимости версию на продакшн можно отделить от транка.
При этом в ветку можно комитить часто, даже если результат будет не совсем стабильным. Правда у нас над одной веткой редко работает больше двух человек, иначе подобное было бы невозможно. Если же требуется показать изменения коллеге, можно воспользоватся патчем.
При этом в ветку можно комитить часто, даже если результат будет не совсем стабильным. Правда у нас над одной веткой редко работает больше двух человек, иначе подобное было бы невозможно. Если же требуется показать изменения коллеге, можно воспользоватся патчем.
Попробуйте заменить слово «svn» на hg, bzr, git.
Статья отражает функционал git для пользователей svn. Не стоит по ней судить о возможностях git.
Git выбирают за то чего в svn нет.
Статья отражает функционал git для пользователей svn. Не стоит по ней судить о возможностях git.
Git выбирают за то чего в svn нет.
у нас trunk — это даже не продакшн, а просто основа кода. из него раз в месяц отделяем release branch который в течении месяца тестируется со всем сторон и потом она же попадает в продакшн; все новые разработки делаются в отдельных ветках, которые по завершению попадают в транк; таким образом минимальный срок тестирования любой новой фишки составляет 4 недели. стандартная release driven парадигма
Господа! Как начать пользоваться гитом я уже встретил несколько инструкций, но как сделать репозиторий публичным — ни одной :( Может ли кто-нибудь расписать простым языком как это сделать? Плюс какие порты надо открыть на файерволе, как расшарить по родному протоколу и по хттп.
Возможно вас устроит github.com?
Спасибо, я про него знаю. Я все-таки имею ввиду свой сервер.
Я имею ввиду не совсем уж публичным доступным всем подряд, а когда есть 2-3-5… разработчиков, в локалке и вне ее.
В платных аккаунтах на гитхабе можно сделать репозиторий приватным и указать Repository Collaborators.
Что касается тонкостей настройки гитозиз, к сожалению, не знаю.
Что касается тонкостей настройки гитозиз, к сожалению, не знаю.
Простейший вариант — доступ по SSH к общему репозитарию login@domain:~/repo.git
Сложнее — gitosis — предоставляет управление правами доступа
Сложнее — gitosis — предоставляет управление правами доступа
Если у вас линукс почитайте эту статью.
Ести немножко донатроить SSH можно удет иметь github подобную авторизацию с помощью ключей доступа.
Ести немножко донатроить SSH можно удет иметь github подобную авторизацию с помощью ключей доступа.
> Надо отметить, что в SVN, конечно, есть ветки, но сделаны они, видимо, для другого, и поэтому плохо приспособлены для того, чтобы их сливать в trunk.
это вы какую-то фигню написали. вся суть репозитория — в ветках. всем разработчикам сидеть в транке — дурдом. к правилам создания веток хочу так же добавить ветки релизов, как без этого работать мне сложно понять. SVN прекрасно работает с ветками во всех направлениях, дайте мне кейс, кто она с ними не справляется как должно.
в пользу GIT говорит только распределённость.
это вы какую-то фигню написали. вся суть репозитория — в ветках. всем разработчикам сидеть в транке — дурдом. к правилам создания веток хочу так же добавить ветки релизов, как без этого работать мне сложно понять. SVN прекрасно работает с ветками во всех направлениях, дайте мне кейс, кто она с ними не справляется как должно.
в пользу GIT говорит только распределённость.
$ git checkout master
Switched to branch «master»
$ git rebase feature
First, rewinding head to replay your work on top of it…
HEAD is now at 9bfac0a feature1
Applying file2
Одному мне кажется, что ребэйзить мастер на что-то не очень хорошая идея?
Sign up to leave a comment.
Про Git на пальцах (для переходящих с SVN)