Comments 29
Странно, в моих инсталляциях PVE, включая ядро почему-то на Debian'е основан.
Ядро PVE основано на ядре проекта OpenVZ, которое, в свою очередь, основано на RedHat-ядре.
А основа системы — да, Debian.
root@srv01-vmx:~# zless /usr/share/doc/pve-kernel-`uname -r`/changelog.Debian.gz
А основа системы — да, Debian.
А по моему у них чистое RH ядро, когда были проблемы с bouding на серверах после обновления ядра, косяк оказался в патчи от RH. Хотя я тут не эксперт, просто на форуме как раз проблему обсуждали и как то врезалось в память.
Они используют ядро от OpenVZ, которое слегка патчат.
OpenVZ берут RedHat-ядро, которое серьезно патчат :)
В /usr/share/doc/pve-kernel-`uname -r`/changelog.Debian.gz все написано.
OpenVZ берут RedHat-ядро, которое серьезно патчат :)
В /usr/share/doc/pve-kernel-`uname -r`/changelog.Debian.gz все написано.
winduzoid, не только вам, но и остальным собравшимся.
Ядро с дистрибутивом не путаете?
Из первых уст: «ядро RH cлишком глючное, чтобы его использовать в Proxmox, но допилить его было проще. Как только появится время, поделки RedHat будут полностью исключены». «Проще» исходит из того, что KVM под крылом RedHat, не более
Ядро с дистрибутивом не путаете?
Из первых уст: «ядро RH cлишком глючное, чтобы его использовать в Proxmox, но допилить его было проще. Как только появится время, поделки RedHat будут полностью исключены». «Проще» исходит из того, что KVM под крылом RedHat, не более
Я вас не понял :)
Ядро с дистрибутивом не путаю.
Ядро с дистрибутивом не путаю.
UFO just landed and posted this here
Вот разработчики что говорят на самом деле.
Скажите, я вот немного не понял. Зачем вам GFS?
Так же не понятно с multipath. У нас проавда не iscsi а fiberchannel и много машин.
Все машинны видят массив общий с FB, а уже при создании самих виртуальных машин используется LVM Group.
Руки добраться до GlusterFS и Ceph, так и не дошли :)
Так же не понятно с multipath. У нас проавда не iscsi а fiberchannel и много машин.
Все машинны видят массив общий с FB, а уже при создании самих виртуальных машин используется LVM Group.
Руки добраться до GlusterFS и Ceph, так и не дошли :)
Все машинны видят массив общий с FB, а уже при создании самих виртуальных машин используется LVM Group.
Кластерная файловая система обычно нужна для того, чтобы можно было диспетчеризовать записи на общее хранилище. Иначе как все доступающиеся к данныи на общем сторадже системы узнают, что одна из них изменила байт в совместно используемых данных?
GFS2. Потому что он работает. И потом, при наличии под рукой работающего RedHat-кластера самое логичное — задействовать их же файловую систему :)
Что вас смутило в multipath? Если у нас есть один и тот же iSCSI-таргет, приходящий по двум разным интерфейсам — грех не задействовать их оба :) Да, без multipath можно было бы обойтись. Но реализация была бы сложнее. Для балансировки нагрузки на хранилище часть машин пришлось бы цеплять на один интерфейс, часть — на другой. К тому же, хранилище умеет при выходе из строя одного из контроллеров переключать его нагрузку на выживший контроллер. В этом случае multipath сильно поможет не упасть всему кластеру.
Что вас смутило в multipath? Если у нас есть один и тот же iSCSI-таргет, приходящий по двум разным интерфейсам — грех не задействовать их оба :) Да, без multipath можно было бы обойтись. Но реализация была бы сложнее. Для балансировки нагрузки на хранилище часть машин пришлось бы цеплять на один интерфейс, часть — на другой. К тому же, хранилище умеет при выходе из строя одного из контроллеров переключать его нагрузку на выживший контроллер. В этом случае multipath сильно поможет не упасть всему кластеру.
Я как то проще сделал.
У нас MSA 2000, FB, Куча машин подключенных к ним. Каждый кластера видит все разделы на MSA — присоединим его LVM GROUP, и уже раздел задействуем для виртуальных машин.
Зачем надо и самое главное ГДЕ? использовать GFS2 я ка кто не могу понять.
storage с тестовой машины.
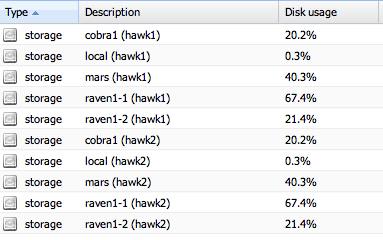
У нас MSA 2000, FB, Куча машин подключенных к ним. Каждый кластера видит все разделы на MSA — присоединим его LVM GROUP, и уже раздел задействуем для виртуальных машин.
Зачем надо и самое главное ГДЕ? использовать GFS2 я ка кто не могу понять.
storage с тестовой машины.

Вы используете OpenVZ в вашем окружении?
нет. Хотя у меня только мысль сейчас проскользнула, что наверно для openvz :)
Именно :)
Да я как всегда по диагонали :)
И как GFS2? Просто года 2 назад, мы отказались от нее в пользу ocfs2. Было с gfs2 очень много проблем, в частности с журналом.
И как GFS2? Просто года 2 назад, мы отказались от нее в пользу ocfs2. Было с gfs2 очень много проблем, в частности с журналом.
Нам нравится. Проблем с журналом не наблюдали. Ну и за два года очень много всего изменилось. GFS2 сейчас признана стабильной RedHat-ом. Они декларируют ее поддержку в RHEL.
ocfs2 мы пока не трогали. В Proxmox ее нет, а пересобирать ядро специально для нее пока не хочется. Но пробовать будем.
ocfs2 мы пока не трогали. В Proxmox ее нет, а пересобирать ядро специально для нее пока не хочется. Но пробовать будем.
Думаю не надо. У OCFS для RH все осталось как и два года назад. :)
oss.oracle.com/projects/ocfs2/files/RedHat/RHEL5/x86_64/1.4.9-1/
Такой подход мне не очень нравится.
Я вот думаю все же осилить и сделать ceph (proxmox его официально планирует поддерживать) и glusterfs — его можно попробовать с proxmox связать через nfs :)
oss.oracle.com/projects/ocfs2/files/RedHat/RHEL5/x86_64/1.4.9-1/
Такой подход мне не очень нравится.
Я вот думаю все же осилить и сделать ceph (proxmox его официально планирует поддерживать) и glusterfs — его можно попробовать с proxmox связать через nfs :)
Ну мы начали с gfs2 потому что она единственная, по сути, без бубна поддерживает работу со standalone-хранилищем. Для всего остального нужны более сложные схемы (серверы журналов, полноценные ОС на стораджах и пр.).
Мы сейчас начинаем раздумывать над реплицируемым между датацентрами хранилищем. Ну и параллельно еще копаем в стороны. :)
Мы сейчас начинаем раздумывать над реплицируемым между датацентрами хранилищем. Ну и параллельно еще копаем в стороны. :)
И я думаю правильно сделали. Хотя с OCFS2 кроме как смена ядра, проблем особых не было.
Ну самый лучший способ репликации, это средствами самого MSA. Правда насколько я помню, MSA не умеет делать snapshot куда то во вне, для этого лучше подходит EVA. Eva вообще вкусная штука.
Еще как вариант у GFS есть возможность делать репликации между ЦОД, умеет ли ceph не знаю.
Если работаете в основном с OpenVZ, то у них есть своя ФС для контейнеров. В последних версиях они научились мигрировать состояние сетевых сокетов итд итп. В общем очень много плюшек.
Ну самый лучший способ репликации, это средствами самого MSA. Правда насколько я помню, MSA не умеет делать snapshot куда то во вне, для этого лучше подходит EVA. Eva вообще вкусная штука.
Еще как вариант у GFS есть возможность делать репликации между ЦОД, умеет ли ceph не знаю.
Если работаете в основном с OpenVZ, то у них есть своя ФС для контейнеров. В последних версиях они научились мигрировать состояние сетевых сокетов итд итп. В общем очень много плюшек.
Вот еще один довыд не использовать ocfs2 :)
forum.proxmox.com/threads/7247-New-2.6.32-Kernel-%28pvetest%29?p=41283#post41283
Может конечно что то поменялось, но лучше побродить по форуму.
forum.proxmox.com/threads/7247-New-2.6.32-Kernel-%28pvetest%29?p=41283#post41283
Может конечно что то поменялось, но лучше побродить по форуму.
Да, мы поэтому пока на ocfs2 и не смотрели. Там все так же до сих пор, мне кажется.
Мне кажется для такого проекта как Proxmox освоить технологию «ocfs2» всё же нужно.
Ведь потенциального пользователя proxmox может устраивать всё, кроме работы с дисковыми хранилищами.
Ещё вопрос в тему: Скажите, а поддержка DRBD есть? Если есть и она работает нормально, то где можно почитать о том, как всё это работает вместе с «fenceing» и как настроена защита от SplitBrain. Спасибо.
Ведь потенциального пользователя proxmox может устраивать всё, кроме работы с дисковыми хранилищами.
Ещё вопрос в тему: Скажите, а поддержка DRBD есть? Если есть и она работает нормально, то где можно почитать о том, как всё это работает вместе с «fenceing» и как настроена защита от SplitBrain. Спасибо.
Там проблема в том, что Оракл перестал поддерживать RedHat-ядра. Из-за этого работа в Proxmox с ocfs2 затруднена.
Поддержка DRBD есть. Мы не пробовали.
Вот здесь написано про fencing в связке c DRBD: pve.proxmox.com/wiki/Two-Node_High_Availability_Cluster
Поддержка DRBD есть. Мы не пробовали.
Вот здесь написано про fencing в связке c DRBD: pve.proxmox.com/wiki/Two-Node_High_Availability_Cluster
Или вы спрашиваете, зачем нам вообще кластерная FS?
Они вообще все такое кластерное и не только выпилили из ядра, оставили только GFS2, модифицированные corosync, cman и drbd.
На все вопросы на форуме отвечают: «извините, у нас другая концепция, мы будем ее придерживаться, и этот модуль мы включать не будем».
Так что если у вас proxmox, ничего другого и не выйдет ))
ploop очень радует, не пробовали его? Его бы еще запилить для ceph, было бы счастье. Для kvm ceph неплохо уже работает.
На все вопросы на форуме отвечают: «извините, у нас другая концепция, мы будем ее придерживаться, и этот модуль мы включать не будем».
Так что если у вас proxmox, ничего другого и не выйдет ))
ploop очень радует, не пробовали его? Его бы еще запилить для ceph, было бы счастье. Для kvm ceph неплохо уже работает.
Sign up to leave a comment.
Кластерное хранилище в Proxmox. Часть вторая. Запуск