Машинное обучение становится доступнее, появляется больше возможностей применять эту технологию, используя «готовые компоненты». Например, Transfer Learning позволяет использовать накопленный при решении одной задачи опыт для решения другой, аналогичной проблемы. Нейросеть сначала обучается на большом объеме данных, затем — на целевом наборе.
В этой статье я расскажу, как использовать метод Transfer Learning на примере распознавания изображений с едой. Про другие инструменты машинного обучения я расскажу на воркшопе «Machine Learning и нейросети для разработчиков».
Если перед нами встает задача распознавания изображений, можно воспользоваться готовым сервисом. Однако, если нужно обучить модель на собственном наборе данных, то придется делать это самостоятельно.
Для таких типовых задач, как классификация изображений, можно воспользоваться готовой архитектурой (AlexNet, VGG, Inception, ResNet и т.д.) и обучить нейросеть на своих данных. Реализации таких сетей с помощью различных фреймворков уже существуют, так что на данном этапе можно использовать одну из них как черный ящик, не вникая глубоко в принцип её работы.
Однако, глубокие нейронные сети требовательны к большим объемам данных для сходимости обучения. И зачастую в нашей частной задаче недостаточно данных для того, чтобы хорошо натренировать все слои нейросети. Transfer Learning решает эту проблему.
Нейронные сети, которые используются для классификации, как правило, содержат
Зачастую в конце классификационных сетей используется полносвязный слой. Так как мы заменили этот слой, использовать предобученные веса для него уже не получится. Придется тренировать его с нуля, инициализировав его веса случайными значениями. Веса для всех остальных слоев мы загружаем из предобученного снэпшота.
Существуют различные стратегии дообучения модели. Мы воспользуемся следующей: будем тренировать всю сеть из конца в конец (end-to-end), а предобученные веса не будем фиксировать, чтобы дать им немного скорректироваться и подстроиться под наши данные. Такой процесс называется тонкой настройкой (fine-tuning).
Для решения задачи нам понадобятся следующие компоненты:
В нашем примере компоненты (1), (2) и (3) я буду брать из собственного репозитория, который содержит максимально легковесный код — при желании с ним можно легко разобраться. Наш пример будет реализован на популярном фреймворке TensorFlow. Предобученные веса (4), подходящие под выбранный фреймворк, можно найти, если они соответствуют одной из классических архитектур. В качестве датасета (5) для демонстрации я возьму Food-101.
В качестве модели воспользуемся классической нейросетью VGG (точнее, VGG19). Несмотря на некоторые недостатки, эта модель демонстрирует довольно высокое качество. Кроме того, она легко поддается анализу. На TensorFlow Slim описание модели выглядит достаточно компактно:
Веса для VGG19, обученные на ImageNet и совместимые с TensorFlow, скачаем с репозитория на GitHub из раздела Pre-trained Models.
В качестве обучающей и валидационной выборки будем использовать публичный датасет Food-101, где собрано более 100 тысяч изображений еды, разбитых на 101 категорию.

Скачиваем и распаковываем датасет:
Пайплайн данных в нашем обучении устроен так, что из датасета нам понадобится распарсить следующее:
Если датасет свой, то на train и validation наборы нужно разбить самостоятельно. В Food-101 такое разбиение уже есть, и эта информация хранится в директории
Все вспомогательные функции, ответственные за обработку данных, вынесены в отдельный файл
Код обучения модели состоит из следующих шагов:
Последний слой графа конструируется с нужным нам количеством нейронов и исключается из списка параметров, загружаемых из предобученного снэпшота.
После запуска обучения можно посмотреть на его ход с помощью утилиты TensorBoard, которая поставляется в комплекте с TensorFlow и служит для визуализации различных метрик и других параметров.
В конце обучения в TensorBoard мы наблюдаем практически идеальную картину: снижение Train loss и рост Validation Accuracy
В результате мы получаем сохранённый снэпшот в
Теперь протестируем нашу модель. Для этого:

Весь код, включая ресурсы для построения и запуска Docker контейнера со всеми нужными версиями библиотек, находятся в этом репозитории — на момент прочтения статьи код в репозитории может иметь обновления.
На воркшопе «Machine Learning и нейросети для разработчиков» я разберу и другие задачи машинного обучения, а студенты к концу интенсива сами представят свои проекты.

В этой статье я расскажу, как использовать метод Transfer Learning на примере распознавания изображений с едой. Про другие инструменты машинного обучения я расскажу на воркшопе «Machine Learning и нейросети для разработчиков».
Если перед нами встает задача распознавания изображений, можно воспользоваться готовым сервисом. Однако, если нужно обучить модель на собственном наборе данных, то придется делать это самостоятельно.
Для таких типовых задач, как классификация изображений, можно воспользоваться готовой архитектурой (AlexNet, VGG, Inception, ResNet и т.д.) и обучить нейросеть на своих данных. Реализации таких сетей с помощью различных фреймворков уже существуют, так что на данном этапе можно использовать одну из них как черный ящик, не вникая глубоко в принцип её работы.
Однако, глубокие нейронные сети требовательны к большим объемам данных для сходимости обучения. И зачастую в нашей частной задаче недостаточно данных для того, чтобы хорошо натренировать все слои нейросети. Transfer Learning решает эту проблему.
Transfer Learning для классификации изображений
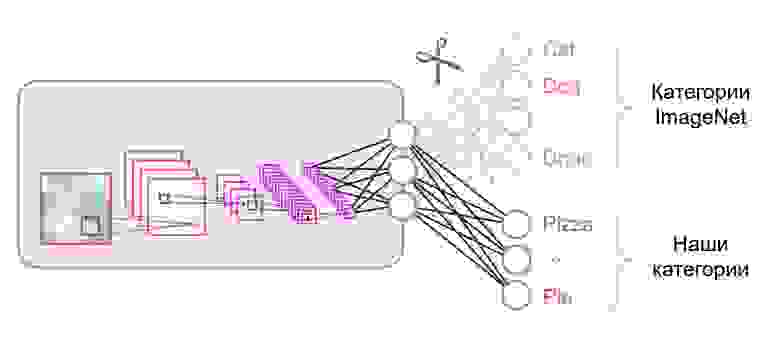
Нейронные сети, которые используются для классификации, как правило, содержат
N выходных нейронов в последнем слое, где N — это количество классов. Такой выходной вектор трактуется как набор вероятностей принадлежности к классу. В нашей задаче распознавания изображений еды количество классов может отличаться от того, которое было в исходном датасете. В таком случае нам придётся полностью выкинуть этот последний слой и поставить новый, с нужным количеством выходных нейронов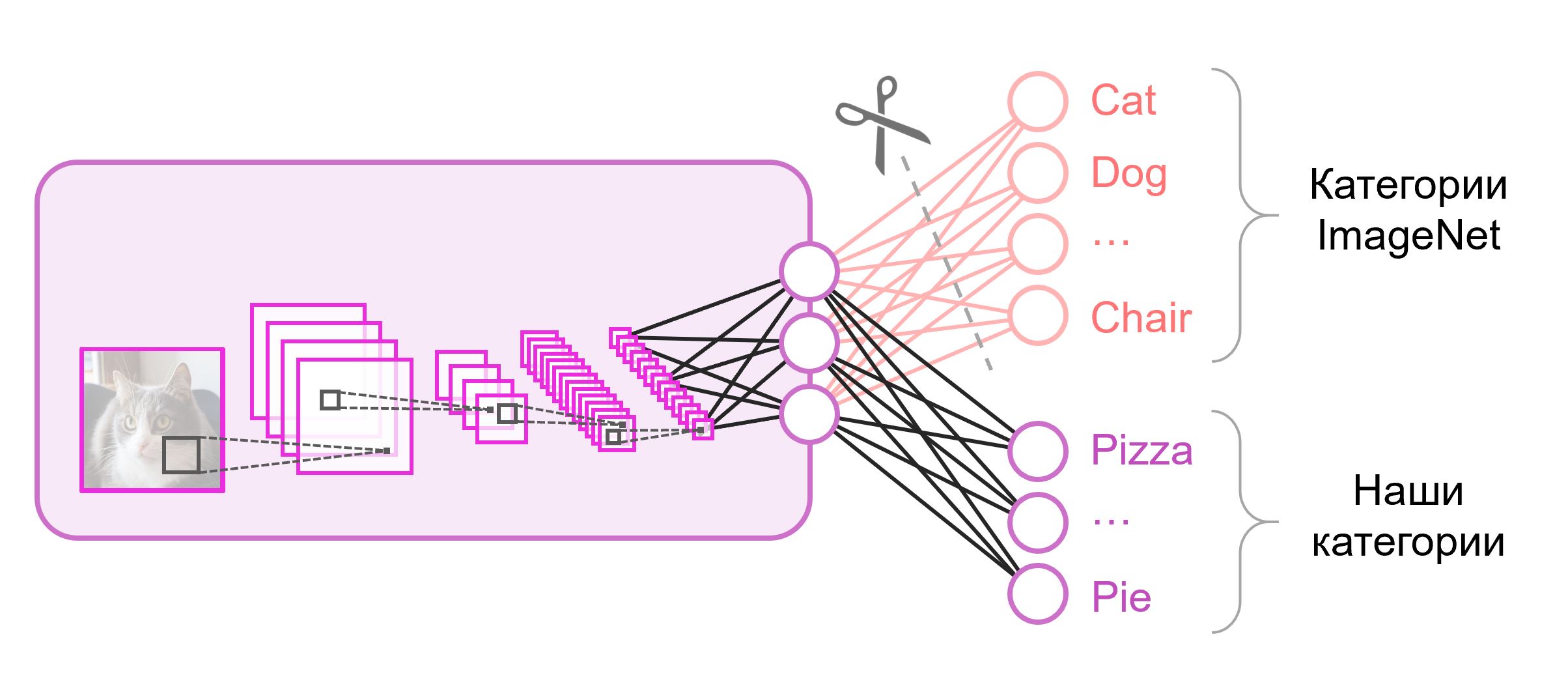
Зачастую в конце классификационных сетей используется полносвязный слой. Так как мы заменили этот слой, использовать предобученные веса для него уже не получится. Придется тренировать его с нуля, инициализировав его веса случайными значениями. Веса для всех остальных слоев мы загружаем из предобученного снэпшота.
Существуют различные стратегии дообучения модели. Мы воспользуемся следующей: будем тренировать всю сеть из конца в конец (end-to-end), а предобученные веса не будем фиксировать, чтобы дать им немного скорректироваться и подстроиться под наши данные. Такой процесс называется тонкой настройкой (fine-tuning).
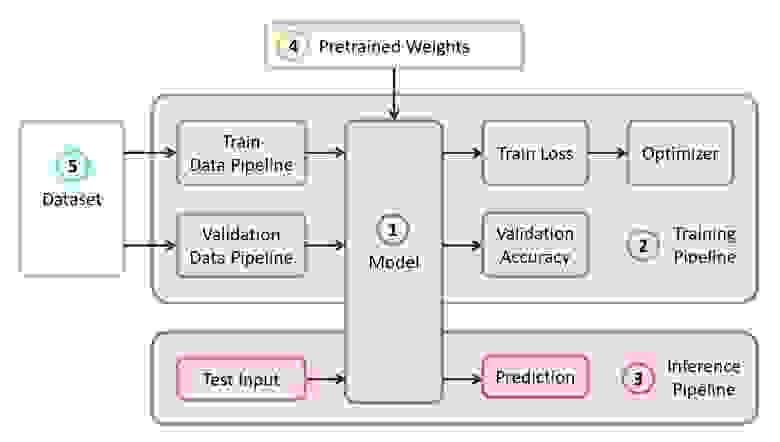
Структурные компоненты
Для решения задачи нам понадобятся следующие компоненты:
- Описание модели нейросети
- Пайплайн обучения
- Инференс пайплайн
- Предобученные веса для этой модели
- Данные для обучения и валидации
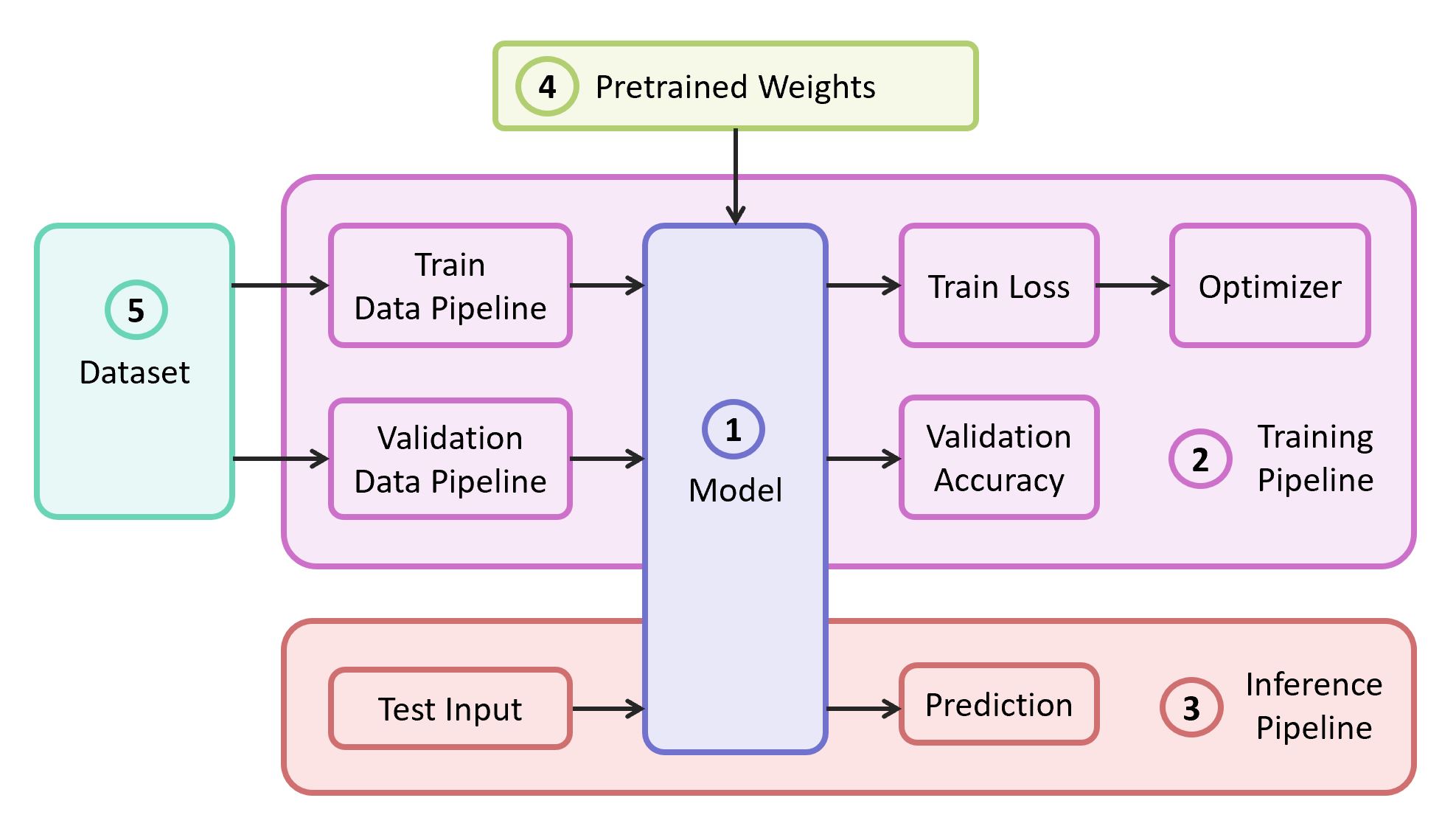
В нашем примере компоненты (1), (2) и (3) я буду брать из собственного репозитория, который содержит максимально легковесный код — при желании с ним можно легко разобраться. Наш пример будет реализован на популярном фреймворке TensorFlow. Предобученные веса (4), подходящие под выбранный фреймворк, можно найти, если они соответствуют одной из классических архитектур. В качестве датасета (5) для демонстрации я возьму Food-101.
Модель
В качестве модели воспользуемся классической нейросетью VGG (точнее, VGG19). Несмотря на некоторые недостатки, эта модель демонстрирует довольно высокое качество. Кроме того, она легко поддается анализу. На TensorFlow Slim описание модели выглядит достаточно компактно:
import tensorflow as tf
import tensorflow.contrib.slim as slim
def vgg_19(inputs,
num_classes,
is_training,
scope='vgg_19',
weight_decay=0.0005):
with slim.arg_scope([slim.conv2d],
activation_fn=tf.nn.relu,
weights_regularizer=slim.l2_regularizer(weight_decay),
biases_initializer=tf.zeros_initializer(),
padding='SAME'):
with tf.variable_scope(scope, 'vgg_19', [inputs]):
net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1')
net = slim.max_pool2d(net, [2, 2], scope='pool1')
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2')
net = slim.max_pool2d(net, [2, 2], scope='pool2')
net = slim.repeat(net, 4, slim.conv2d, 256, [3, 3], scope='conv3')
net = slim.max_pool2d(net, [2, 2], scope='pool3')
net = slim.repeat(net, 4, slim.conv2d, 512, [3, 3], scope='conv4')
net = slim.max_pool2d(net, [2, 2], scope='pool4')
net = slim.repeat(net, 4, slim.conv2d, 512, [3, 3], scope='conv5')
net = slim.max_pool2d(net, [2, 2], scope='pool5')
# Use conv2d instead of fully_connected layers
net = slim.conv2d(net, 4096, [7, 7], padding='VALID', scope='fc6')
net = slim.dropout(net, 0.5, is_training=is_training, scope='drop6')
net = slim.conv2d(net, 4096, [1, 1], scope='fc7')
net = slim.dropout(net, 0.5, is_training=is_training, scope='drop7')
net = slim.conv2d(net, num_classes, [1, 1], scope='fc8',
activation_fn=None)
net = tf.squeeze(net, [1, 2], name='fc8/squeezed')
return net
Веса для VGG19, обученные на ImageNet и совместимые с TensorFlow, скачаем с репозитория на GitHub из раздела Pre-trained Models.
mkdir data && cd data
wget http://download.tensorflow.org/models/vgg_19_2016_08_28.tar.gz
tar -xzf vgg_19_2016_08_28.tar.gz
Датасет
В качестве обучающей и валидационной выборки будем использовать публичный датасет Food-101, где собрано более 100 тысяч изображений еды, разбитых на 101 категорию.

Скачиваем и распаковываем датасет:
cd data
wget http://data.vision.ee.ethz.ch/cvl/food-101.tar.gz
tar -xzf food-101.tar.gz
Пайплайн данных в нашем обучении устроен так, что из датасета нам понадобится распарсить следующее:
- Список классов (категорий)
- Обучающий набор: список путей к картинкам и список правильных ответов
- Валидационный набор: список путей к картинкам и список правильных ответов
Если датасет свой, то на train и validation наборы нужно разбить самостоятельно. В Food-101 такое разбиение уже есть, и эта информация хранится в директории
meta.DATASET_ROOT = 'data/food-101/'
train_data, val_data, classes = data.food101(DATASET_ROOT)
num_classes = len(classes)
Все вспомогательные функции, ответственные за обработку данных, вынесены в отдельный файл
data.py:data.py
from os.path import join as opj
import tensorflow as tf
def parse_ds_subset(img_root, list_fpath, classes):
'''
Parse a meta file with image paths and labels
-> img_root: path to the root of image folders
-> list_fpath: path to the file with the list (e.g. train.txt)
-> classes: list of class names
<- (list_of_img_paths, integer_labels)
'''
fpaths = []
labels = []
with open(list_fpath, 'r') as f:
for line in f:
class_name, image_id = line.strip().split('/')
fpaths.append(opj(img_root, class_name, image_id+'.jpg'))
labels.append(classes.index(class_name))
return fpaths, labels
def food101(dataset_root):
'''
Get lists of train and validation examples for Food-101 dataset
-> dataset_root: root of the Food-101 dataset
<- ((train_fpaths, train_labels), (val_fpaths, val_labels), classes)
'''
img_root = opj(dataset_root, 'images')
train_list_fpath = opj(dataset_root, 'meta', 'train.txt')
test_list_fpath = opj(dataset_root, 'meta', 'test.txt')
classes_list_fpath = opj(dataset_root, 'meta', 'classes.txt')
with open(classes_list_fpath, 'r') as f:
classes = [line.strip() for line in f]
train_data = parse_ds_subset(img_root, train_list_fpath, classes)
val_data = parse_ds_subset(img_root, test_list_fpath, classes)
return train_data, val_data, classes
def imread_and_crop(fpath, inp_size, margin=0, random_crop=False):
'''
Construct TF graph for image preparation:
Read the file, crop and resize
-> fpath: path to the JPEG image file (TF node)
-> inp_size: size of the network input (e.g. 224)
-> margin: cropping margin
-> random_crop: perform random crop or central crop
<- prepared image (TF node)
'''
data = tf.read_file(fpath)
img = tf.image.decode_jpeg(data, channels=3)
img = tf.image.convert_image_dtype(img, dtype=tf.float32)
shape = tf.shape(img)
crop_size = tf.minimum(shape[0], shape[1]) - 2 * margin
if random_crop:
img = tf.random_crop(img, (crop_size, crop_size, 3))
else: # central crop
ho = (shape[0] - crop_size) // 2
wo = (shape[0] - crop_size) // 2
img = img[ho:ho+crop_size, wo:wo+crop_size, :]
img = tf.image.resize_images(img, (inp_size, inp_size),
method=tf.image.ResizeMethod.AREA)
return img
def train_dataset(data, batch_size, epochs, inp_size, margin):
'''
Prepare training data pipeline
-> data: (list_of_img_paths, integer_labels)
-> batch_size: training batch size
-> epochs: number of training epochs
-> inp_size: size of the network input (e.g. 224)
-> margin: cropping margin
<- (dataset, number_of_train_iterations)
'''
num_examples = len(data[0])
iters = (epochs * num_examples) // batch_size
def fpath_to_image(fpath, label):
img = imread_and_crop(fpath, inp_size, margin, random_crop=True)
return img, label
dataset = tf.data.Dataset.from_tensor_slices(data)
dataset = dataset.shuffle(buffer_size=num_examples)
dataset = dataset.map(fpath_to_image)
dataset = dataset.repeat(epochs)
dataset = dataset.batch(batch_size, drop_remainder=True)
return dataset, iters
def val_dataset(data, batch_size, inp_size):
'''
Prepare validation data pipeline
-> data: (list_of_img_paths, integer_labels)
-> batch_size: validation batch size
-> inp_size: size of the network input (e.g. 224)
<- (dataset, number_of_val_iterations)
'''
num_examples = len(data[0])
iters = num_examples // batch_size
def fpath_to_image(fpath, label):
img = imread_and_crop(fpath, inp_size, 0, random_crop=False)
return img, label
dataset = tf.data.Dataset.from_tensor_slices(data)
dataset = dataset.map(fpath_to_image)
dataset = dataset.batch(batch_size, drop_remainder=True)
return dataset, iters
Обучение модели
Код обучения модели состоит из следующих шагов:
- Построение train/validation пайплайнов данных
- Построение train/validation графов (сетей)
- Надстраивание классификационной функция потерь (cross entropy loss) поверх train графа
- Код, необходимый для вычисления точности предсказания на валидационной выборке во время обучения
- Логика загрузки предобученных весов из снэпшота
- Создание различных структур для обучения
- Непосредственно сам цикл обучения (итерационная оптимизация)
Последний слой графа конструируется с нужным нам количеством нейронов и исключается из списка параметров, загружаемых из предобученного снэпшота.
Код обучения модели
import numpy as np
import tensorflow as tf
import tensorflow.contrib.slim as slim
tf.logging.set_verbosity(tf.logging.INFO)
import model
import data
###########################################################
### Settings
###########################################################
INPUT_SIZE = 224
RANDOM_CROP_MARGIN = 10
TRAIN_EPOCHS = 20
TRAIN_BATCH_SIZE = 64
VAL_BATCH_SIZE = 128
LR_START = 0.001
LR_END = LR_START / 1e4
MOMENTUM = 0.9
VGG_PRETRAINED_CKPT = 'data/vgg_19.ckpt'
CHECKPOINT_DIR = 'checkpoints/vgg19_food'
LOG_LOSS_EVERY = 10
CALC_ACC_EVERY = 500
###########################################################
### Build training and validation data pipelines
###########################################################
train_ds, train_iters = data.train_dataset(train_data,
TRAIN_BATCH_SIZE, TRAIN_EPOCHS, INPUT_SIZE, RANDOM_CROP_MARGIN)
train_ds_iterator = train_ds.make_one_shot_iterator()
train_x, train_y = train_ds_iterator.get_next()
val_ds, val_iters = data.val_dataset(val_data,
VAL_BATCH_SIZE, INPUT_SIZE)
val_ds_iterator = val_ds.make_initializable_iterator()
val_x, val_y = val_ds_iterator.get_next()
###########################################################
### Construct training and validation graphs
###########################################################
with tf.variable_scope('', reuse=tf.AUTO_REUSE):
train_logits = model.vgg_19(train_x, num_classes, is_training=True)
val_logits = model.vgg_19(val_x, num_classes, is_training=False)
###########################################################
### Construct training loss
###########################################################
loss = tf.losses.sparse_softmax_cross_entropy(
labels=train_y, logits=train_logits)
tf.summary.scalar('loss', loss)
###########################################################
### Construct validation accuracy
### and related functions
###########################################################
def calc_accuracy(sess, val_logits, val_y, val_iters):
acc_total = 0.0
acc_denom = 0
for i in range(val_iters):
logits, y = sess.run((val_logits, val_y))
y_pred = np.argmax(logits, axis=1)
correct = np.count_nonzero(y == y_pred)
acc_denom += y_pred.shape[0]
acc_total += float(correct)
tf.logging.info('Validating batch [{} / {}] correct = {}'.format(
i, val_iters, correct))
acc_total /= acc_denom
return acc_total
def accuracy_summary(sess, acc_value, iteration):
acc_summary = tf.Summary()
acc_summary.value.add(tag="accuracy", simple_value=acc_value)
sess._hooks[1]._summary_writer.add_summary(acc_summary, iteration)
###########################################################
### Define set of VGG variables to restore
### Create the Restorer
### Define init callback (used by monitored session)
###########################################################
vars_to_restore = tf.contrib.framework.get_variables_to_restore(
exclude=['vgg_19/fc8'])
vgg_restorer = tf.train.Saver(vars_to_restore)
def init_fn(scaffold, sess):
vgg_restorer.restore(sess, VGG_PRETRAINED_CKPT)
###########################################################
### Create various training structures
###########################################################
global_step = tf.train.get_or_create_global_step()
lr = tf.train.polynomial_decay(LR_START, global_step, train_iters, LR_END)
tf.summary.scalar('learning_rate', lr)
optimizer = tf.train.MomentumOptimizer(learning_rate=lr, momentum=MOMENTUM)
training_op = slim.learning.create_train_op(
loss, optimizer, global_step=global_step)
scaffold = tf.train.Scaffold(init_fn=init_fn)
###########################################################
### Create monitored session
### Run training loop
###########################################################
with tf.train.MonitoredTrainingSession(checkpoint_dir=CHECKPOINT_DIR,
save_checkpoint_secs=600,
save_summaries_steps=30,
scaffold=scaffold) as sess:
start_iter = sess.run(global_step)
for iteration in range(start_iter, train_iters):
# Gradient Descent
loss_value = sess.run(training_op)
# Loss logging
if iteration % LOG_LOSS_EVERY == 0:
tf.logging.info('[{} / {}] Loss = {}'.format(
iteration, train_iters, loss_value))
# Accuracy logging
if iteration % CALC_ACC_EVERY == 0:
sess.run(val_ds_iterator.initializer)
acc_value = calc_accuracy(sess, val_logits, val_y, val_iters)
accuracy_summary(sess, acc_value, iteration)
tf.logging.info('[{} / {}] Validation accuracy = {}'.format(
iteration, train_iters, acc_value))
После запуска обучения можно посмотреть на его ход с помощью утилиты TensorBoard, которая поставляется в комплекте с TensorFlow и служит для визуализации различных метрик и других параметров.
tensorboard --logdir checkpoints/
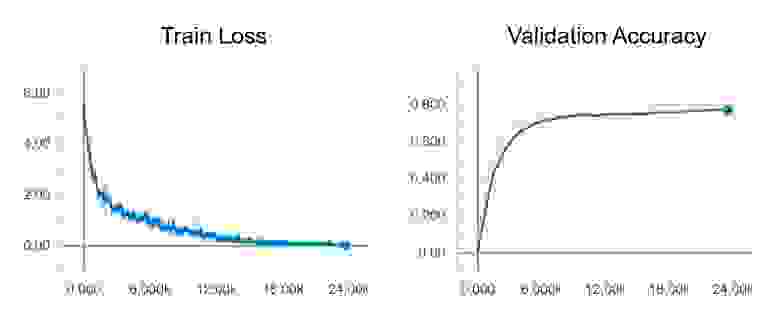
В конце обучения в TensorBoard мы наблюдаем практически идеальную картину: снижение Train loss и рост Validation Accuracy

В результате мы получаем сохранённый снэпшот в
checkpoints/vgg19_food, который будем использовать во время тестирования нашей модели (inference).Тестирование модели
Теперь протестируем нашу модель. Для этого:
- Cконструируем новый граф, предназначенный специально для инференса (
is_training=False) - Загрузим обученные веса из снэпшота
- Загрузим и предобработем входное тестовое изображение
- Прогоним изображение через нейронную сеть и получим предсказание
inference.py
import sys
import numpy as np
import imageio
from skimage.transform import resize
import tensorflow as tf
import model
###########################################################
### Settings
###########################################################
CLASSES_FPATH = 'data/food-101/meta/labels.txt'
INP_SIZE = 224 # Input will be cropped and resized
CHECKPOINT_DIR = 'checkpoints/vgg19_food'
IMG_FPATH = 'data/food-101/images/bruschetta/3564471.jpg'
###########################################################
### Get all class names
###########################################################
with open(CLASSES_FPATH, 'r') as f:
classes = [line.strip() for line in f]
num_classes = len(classes)
###########################################################
### Construct inference graph
###########################################################
x = tf.placeholder(tf.float32, (1, INP_SIZE, INP_SIZE, 3), name='inputs')
logits = model.vgg_19(x, num_classes, is_training=False)
###########################################################
### Create TF session and restore from a snapshot
###########################################################
sess = tf.Session()
snapshot_fpath = tf.train.latest_checkpoint(CHECKPOINT_DIR)
restorer = tf.train.Saver()
restorer.restore(sess, snapshot_fpath)
###########################################################
### Load and prepare input image
###########################################################
def crop_and_resize(img, input_size):
crop_size = min(img.shape[0], img.shape[1])
ho = (img.shape[0] - crop_size) // 2
wo = (img.shape[0] - crop_size) // 2
img = img[ho:ho+crop_size, wo:wo+crop_size, :]
img = resize(img, (input_size, input_size),
order=3, mode='reflect', anti_aliasing=True, preserve_range=True)
return img
img = imageio.imread(IMG_FPATH)
img = img.astype(np.float32)
img = crop_and_resize(img, INP_SIZE)
img = img[None, ...]
###########################################################
### Run inference
###########################################################
out = sess.run(logits, feed_dict={x:img})
pred_class = classes[np.argmax(out)]
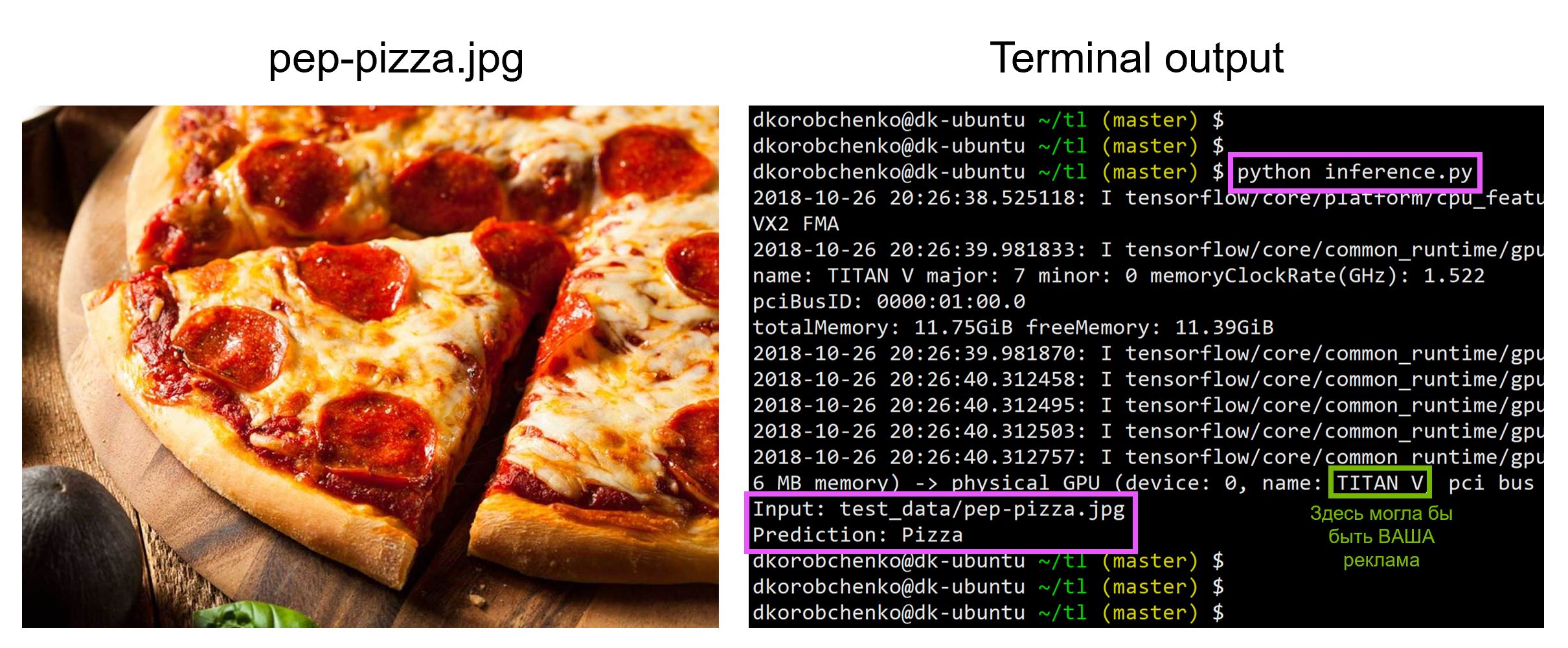
print('Input: {}'.format(IMG_FPATH))
print('Prediction: {}'.format(pred_class))
Весь код, включая ресурсы для построения и запуска Docker контейнера со всеми нужными версиями библиотек, находятся в этом репозитории — на момент прочтения статьи код в репозитории может иметь обновления.
На воркшопе «Machine Learning и нейросети для разработчиков» я разберу и другие задачи машинного обучения, а студенты к концу интенсива сами представят свои проекты.
