Привет, Хабр! В этом посте я хотел бы рассказать вам о том, как мы, Лаборатория новых профессий, вместе с компанией Data-centric Alliance смогли сконструировать несколько лабораторных работ, посвящённых обработке и анализу веб-логов. Эти лабораторные работы являются ключевыми в рамках первого кейса нашей образовательной программы «Специалист по большим данным» и выполняются на основе аудиторных данных DMP Facetz.DCA. Меня зовут Артем Пичугин, и я являюсь её координатором.
Представьте, что вы компания, продающая автомобили. Кому показать рекламу автомобиля? На каких сайтах? Так, чтобы недорого и эффективно? Казалось бы, ответ очевиден: пользователям, которые заходят на страницы покупки автомобилей на сайтах компаний, а также на досках объявлений типа Avito и т д.
Но в этом и заключается проблема: именно в этом месте, ровно этим пользователям показывать рекламу хотят все — большой спрос на маленьком количестве известных площадок, такие показы будут дорогими! Есть второй вариант: найти менее популярные сайты, на которых сидят интересующие вас пользователи (просматривающие страницы покупки автомобилей), и показывать рекламу на этих сайтах. В таком случае стоимость показа рекламы будет ниже, при том, что конверсия может оставаться неплохой. Может даже возникнуть ситуация, когда человек ещё ничего не смотрел на тему покупки авто, а лишь задумывался об этом – и первое, что он увидит – ваше предложение!
Подобную задачу решают компании-игроки RTB-рынка, который сейчас переживает активный рост (на днях платформа GetIntent привлекла раунд инвестиций в $1 млн, в начале года Сбербанк купил платформу Segmento, а новые игроки появляются, как грибы после дождя). Аналитический компонент RTB-платформы, отвечающий за сбор информации о пользователе, выполняет DMP-система. Собственные DMP необходимы не только RTB-компаниям, но и всем, кто обладает большим объемом данных (например, банкам, телекомам, интернет-порталам), а также всем, кто хочет обогатить свои данные с помощью покупки внешних данных в формате веб-логов. В основе DMP-системы лежит работа с большими объёмами данных о посещении пользователями сайтов на основе логов. Эти логи тщательно собираются с привлечением множества партнёров.
Дисклеймер! Ниже мы хотим описать пошаговый сценарий обработки и анализа логов с помощью Hadoop и Python, которые в упрощённом виде повторяют работу ключевого компонента DMP-системы. Мы используем этот сценарий во время обучения обработке и анализу больших данных в Лаборатории новых профессий. При проектировании этого сценария мы старались быть максимально близкими к решению конкретной бизнес-задачи построения DMP-системы. Слушатели курса выполняют эти работы с реальными данными на Hadoop-кластере от 4 до 20 серверов.
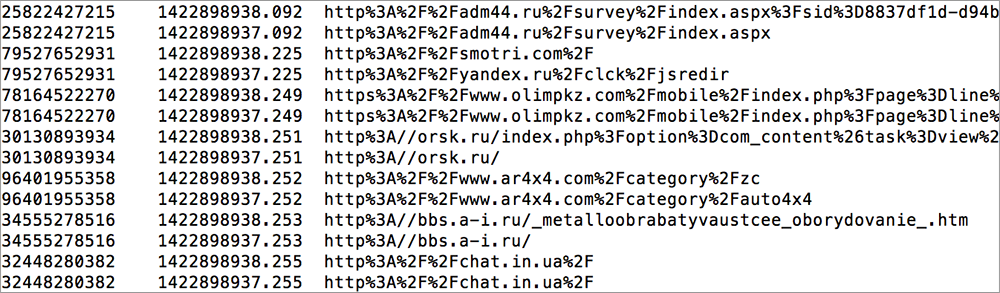
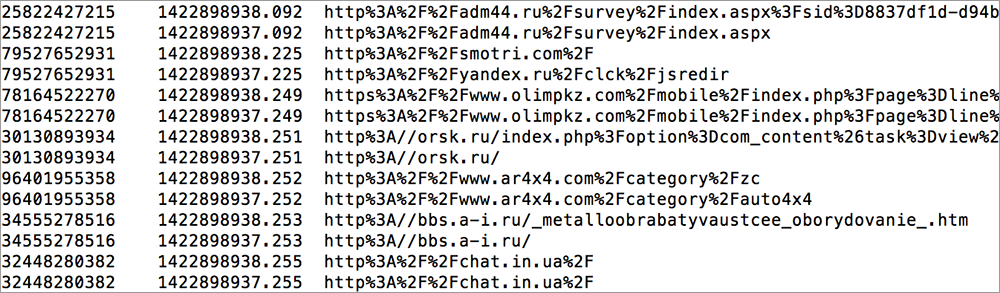
Итак, как можно использовать логи для оптимизации показа рекламы (казалось бы: userid, url, timestamp – скука смертная, только поглядите)? Для этого необходимо проделать несколько операций.
Дано: несколько терабайт логов посещений сайтов.
Что мы делаем:
Наблюдаем, что в топе таких сайтов оказываются сайты «подготовка к ПДД», сайты автошкол. Вы скажете – это очевидный вывод, можно было и так догадаться, безо всяких веб-логов. Тогда ответьте — какие? На каких именно сайтах автошкол и подготовки к ПДД нужно рекламировать Ладу Калину? А Форд Фокус? А Mercedes ML? Именно на этом этапе и требуются более глубокие знания о клиенте, которые «поставляет» DMP-система, о которой немного ниже.
Для того, чтобы выполнить эту, казалось бы, несложную задачу, необходимо уже уметь работать с инструментами Big Data и иметь доступ к данным для анализа. В нашем случае данные были предоставлены DMP Facetz.DCA.
В предыдущей части мы выявили пользователей, которые интересуются автомобилями, нашли, на каких неочевидных сайтах они сидят. Теперь как понять, какую рекламу им показывать? Для этого нам нужно узнать больше о профиле клиента, его возрасте, уровне дохода и других важных для нас как продавца харакетристиках. Конечно, бизнес хорошо знает социо-демографический профиль своих покупателей и знает, кому из них лучше предложить Калину, а кому Mercedes ML.
Задача DMP-системы – обогащать знания о каждом отдельно взятом клиенте, навешивая на него как можно больше «тэгов» — пол, возраст, уровень доходов и т.д. (в частности система Facetz.DCA умеет выделять более 2000 подобных сегментов на материале 650 000 000 кук). Естественно, про каждого человека подробной информации нет, поэтому приходится восстанавливать признаки с высоким уровнем точности с помощью машинного обучения. На этом этапе и появляются элементы «rocket science».
В рамках программы слушатели решают одну из самых важных задач – восстановление пола и возрастной категории клиента по логам его посещения сайтов.
Итак, мы возвращаемся к итоговой задаче – дано несколько терабайт логов посещений сайтов.
Задача 1: для каждого userid определить вероятность, что это мужчина или женщина.
Задача 2 (дополнительной сложности): предсказать пол и возраст для конкретных клиентов.
Первый этап работы – очистка и предобработка данных.
Второй этап – feature engineering.
Это самый интересный и творческий этап работы – необходимо обогатить исходные данные, добавить какие-то дополнительные свойства («фичи»), которые позволят интерпретировать небогатый формат данных!
На этом уровне существует множество подходов и нет однозначной «методички», как делать это правильно. Несколько идей, как подходили к решению этой задачи слушатели программы:
Все эти «фичи» станут основой для алгоритма машинного обучения.
Последний этап – применение машинного обучения.
Следующим шагом необходимо применить машинное обучения для решения задачи. Для решения первой задачи необходимо выбрать целевую переменную – степень уверенности классификатора в поле конкретного userid. Каждый слушатель, проделав предварительную работу по предобработке данных и feature engineering, создаёт модель предсказания, которая в итоге и определяет значение целевой переменной для каждого пользователя. Данная задача является классической задачей бинарной классификации, которая в рамках программы решается с использованием стека Python, где уже реализованы большинство алгоритмов машинного обучения, например, в классической библиотеке scikit-learn. Автоматический скрипт проверки оценивает качество классификатора по показателю AUC.
Задача с дополнительным уровнем сложности наиболее приближена к реальной задаче data scientist’ов, которые разрабатывают аналитический движок DMP-системы. Слушатели должны были сделать предсказания о поле и возрастной категории конкретного человека. Если обе переменные предсказаны правильно, то по данному userid предсказание считается верным. При этом можно было делать предсказание не для всех пользователей, а на своё усмотрение выбрать 50%. Таким образом, сам слушатель мог отсортировать людей по уровню уверенности в предсказании, а потом выбрать лучшую половину.
Это одно из отличий от обычной академической задачи, где зачастую ты должен спрогнозировать заданный парметр для всех наблюдений. В бизнес-подходе мы учитываем, что размещение рекламы стоит денег, поэтому рекламодатель старается оптимизировать затраты и показывать рекламу только тем, про кого наш уровень уверенности в предсказании превышает заданное пороговое значение.
Этот этап работы оказался наиболее творческим и требующим применить здравый смысл, системное мышление и умение итеративно улучшать своё решение.
Что в особенности удивило наших слушателей:
Задача
Представьте, что вы компания, продающая автомобили. Кому показать рекламу автомобиля? На каких сайтах? Так, чтобы недорого и эффективно? Казалось бы, ответ очевиден: пользователям, которые заходят на страницы покупки автомобилей на сайтах компаний, а также на досках объявлений типа Avito и т д.
Но в этом и заключается проблема: именно в этом месте, ровно этим пользователям показывать рекламу хотят все — большой спрос на маленьком количестве известных площадок, такие показы будут дорогими! Есть второй вариант: найти менее популярные сайты, на которых сидят интересующие вас пользователи (просматривающие страницы покупки автомобилей), и показывать рекламу на этих сайтах. В таком случае стоимость показа рекламы будет ниже, при том, что конверсия может оставаться неплохой. Может даже возникнуть ситуация, когда человек ещё ничего не смотрел на тему покупки авто, а лишь задумывался об этом – и первое, что он увидит – ваше предложение!
Анализ логов
Подобную задачу решают компании-игроки RTB-рынка, который сейчас переживает активный рост (на днях платформа GetIntent привлекла раунд инвестиций в $1 млн, в начале года Сбербанк купил платформу Segmento, а новые игроки появляются, как грибы после дождя). Аналитический компонент RTB-платформы, отвечающий за сбор информации о пользователе, выполняет DMP-система. Собственные DMP необходимы не только RTB-компаниям, но и всем, кто обладает большим объемом данных (например, банкам, телекомам, интернет-порталам), а также всем, кто хочет обогатить свои данные с помощью покупки внешних данных в формате веб-логов. В основе DMP-системы лежит работа с большими объёмами данных о посещении пользователями сайтов на основе логов. Эти логи тщательно собираются с привлечением множества партнёров.
Дисклеймер! Ниже мы хотим описать пошаговый сценарий обработки и анализа логов с помощью Hadoop и Python, которые в упрощённом виде повторяют работу ключевого компонента DMP-системы. Мы используем этот сценарий во время обучения обработке и анализу больших данных в Лаборатории новых профессий. При проектировании этого сценария мы старались быть максимально близкими к решению конкретной бизнес-задачи построения DMP-системы. Слушатели курса выполняют эти работы с реальными данными на Hadoop-кластере от 4 до 20 серверов.
Последовательность действий
Итак, как можно использовать логи для оптимизации показа рекламы (казалось бы: userid, url, timestamp – скука смертная, только поглядите)? Для этого необходимо проделать несколько операций.
Дано: несколько терабайт логов посещений сайтов.
Что мы делаем:
- Простейшей эвристикой определяем «нужных пользователей», например, по числу заходов на сайт auto.ru за неделю или две. В итоге получаем список нужных пользователей.
- Теперь для каждого сайта считаем его посещаемость нужными пользователями и всеми пользователями вообще. И долю «правильных» от числа всех посетителей сайта. У каких-то сайтов это будет 0.01% (мало нашей целевой аудитории), а у каких-то 5% (много нашей целевой аудитории).
- Сортируем сайты по убыванию расчитанного показателя и выбираем топ-300 сайтов, на которых находится наша целевая аудитория. Смотрим их глазами.
Наблюдаем, что в топе таких сайтов оказываются сайты «подготовка к ПДД», сайты автошкол. Вы скажете – это очевидный вывод, можно было и так догадаться, безо всяких веб-логов. Тогда ответьте — какие? На каких именно сайтах автошкол и подготовки к ПДД нужно рекламировать Ладу Калину? А Форд Фокус? А Mercedes ML? Именно на этом этапе и требуются более глубокие знания о клиенте, которые «поставляет» DMP-система, о которой немного ниже.
Инструменты Big Data
Для того, чтобы выполнить эту, казалось бы, несложную задачу, необходимо уже уметь работать с инструментами Big Data и иметь доступ к данным для анализа. В нашем случае данные были предоставлены DMP Facetz.DCA.
- Логи нужно где-то хранить – можно положить их напрямую в HDFS, причём таким образом, чтобы с ними мог хорошо работать MapReduce.
- Необходимо уметь эти логи обрабатывать – сортировать по разным параметрам, находить топ-100/300/1000 сайтов, определять долю целевых пользователей в общем трафике. Тут уже понадобится парадигма MapReduce и умение писать распредёленные алгоритмы с использованием:
– фильтрации (map-only jobs)
– оптимизации: соединения map-join (использование distributed cache)
– оптимизации: применения combiner (требования реализации reducer)
– соединения reduce-join
– поиск top-100 (single reducer)
- Хотя это верно и не только для Big Data, но для большого объёма данных становится особенно критично, необходимо построить грамотный процесс предобработки данных.
Машинное обучение
В предыдущей части мы выявили пользователей, которые интересуются автомобилями, нашли, на каких неочевидных сайтах они сидят. Теперь как понять, какую рекламу им показывать? Для этого нам нужно узнать больше о профиле клиента, его возрасте, уровне дохода и других важных для нас как продавца харакетристиках. Конечно, бизнес хорошо знает социо-демографический профиль своих покупателей и знает, кому из них лучше предложить Калину, а кому Mercedes ML.
Задача DMP-системы – обогащать знания о каждом отдельно взятом клиенте, навешивая на него как можно больше «тэгов» — пол, возраст, уровень доходов и т.д. (в частности система Facetz.DCA умеет выделять более 2000 подобных сегментов на материале 650 000 000 кук). Естественно, про каждого человека подробной информации нет, поэтому приходится восстанавливать признаки с высоким уровнем точности с помощью машинного обучения. На этом этапе и появляются элементы «rocket science».
В рамках программы слушатели решают одну из самых важных задач – восстановление пола и возрастной категории клиента по логам его посещения сайтов.
Итак, мы возвращаемся к итоговой задаче – дано несколько терабайт логов посещений сайтов.
Задача 1: для каждого userid определить вероятность, что это мужчина или женщина.
Задача 2 (дополнительной сложности): предсказать пол и возраст для конкретных клиентов.
Первый этап работы – очистка и предобработка данных.
- Работа с аномальными значениями
- Удалить мусор (технические посещения)
- Нормализовать url (например, c www и без www)
- Работа с пропущенными значениями (заполняешь, если пропущен timestamp или url, либо удаляешь совсем если пропущен userid)
Второй этап – feature engineering.
Это самый интересный и творческий этап работы – необходимо обогатить исходные данные, добавить какие-то дополнительные свойства («фичи»), которые позволят интерпретировать небогатый формат данных!
На этом уровне существует множество подходов и нет однозначной «методички», как делать это правильно. Несколько идей, как подходили к решению этой задачи слушатели программы:
- Можно проанализировать сам домен и сгруппировать сайты по нему;
- Можно скачать описательную часть страницы (title, keywords, метаописания) и проанализировать их;
- Самый тяжёлый, но глубокий вариант – это перейти по ссылке и скачать весь код страницы и постараться определить тематику страницы;
- Ещё один подход, это связать посещения пользователем сайтов в цепочку и определить логику в последовательности переходов;
- Отдельной «фичей» могут стать мобильные домены (m.facebook.com), они тоже могут быть полезны для определения категории пользователя.
Все эти «фичи» станут основой для алгоритма машинного обучения.
Последний этап – применение машинного обучения.
Следующим шагом необходимо применить машинное обучения для решения задачи. Для решения первой задачи необходимо выбрать целевую переменную – степень уверенности классификатора в поле конкретного userid. Каждый слушатель, проделав предварительную работу по предобработке данных и feature engineering, создаёт модель предсказания, которая в итоге и определяет значение целевой переменной для каждого пользователя. Данная задача является классической задачей бинарной классификации, которая в рамках программы решается с использованием стека Python, где уже реализованы большинство алгоритмов машинного обучения, например, в классической библиотеке scikit-learn. Автоматический скрипт проверки оценивает качество классификатора по показателю AUC.
Задача с дополнительным уровнем сложности наиболее приближена к реальной задаче data scientist’ов, которые разрабатывают аналитический движок DMP-системы. Слушатели должны были сделать предсказания о поле и возрастной категории конкретного человека. Если обе переменные предсказаны правильно, то по данному userid предсказание считается верным. При этом можно было делать предсказание не для всех пользователей, а на своё усмотрение выбрать 50%. Таким образом, сам слушатель мог отсортировать людей по уровню уверенности в предсказании, а потом выбрать лучшую половину.
Это одно из отличий от обычной академической задачи, где зачастую ты должен спрогнозировать заданный парметр для всех наблюдений. В бизнес-подходе мы учитываем, что размещение рекламы стоит денег, поэтому рекламодатель старается оптимизировать затраты и показывать рекламу только тем, про кого наш уровень уверенности в предсказании превышает заданное пороговое значение.
Этот этап работы оказался наиболее творческим и требующим применить здравый смысл, системное мышление и умение итеративно улучшать своё решение.
Что в особенности удивило наших слушателей:
- Даже простые алгоритмы дают неплохой результат на достаточно большой выборке
- Важнее предобработка + feature engineering (генерирование «фич» на основе данных), чем построение всё более сложных алгоритмов или моделей предсказания
- Приемлемое решение можно получить простыми способами, однако, повышение точности предсказания требует непропорциональных усилий и использования нетривиальных подходов.
