В данной статье я хочу рассказать об основных сложностях автоматизации машинного обучения, ее природе и преимуществах, а также рассмотреть и более гибкий подход, позволяющий уйти от части недостатков.

Автоматизация по определению Mikell P. Groover – это технология, при помощи которой процесс или процедура выполняются с минимальным человеческим участием. Автоматизация уже давно позволяет добиться повышения производительности труда, что зачастую ведет к снижению себестоимости единицы продукта. Методы автоматизации, как и области их применения, стремительно совершенствуются и в течение последних столетий развились от простых механизмов до промышленных роботов. Автоматизация начинает затрагивать не только физический труд, но и интеллектуальный, добираясь до сравнительно новых областей, включая и машинное обучение – automated machine learning (auto ml, aml). В то же время, автоматизация машинного обучения уже нашла свое применение в ряде коммерческих продуктов (например, Google AutoML, SAP AutoML и другие).



Задачи в области обработки данных и машинного обучения связаны с множеством факторов, возникающих из-за сложности системы и затрудняющих их решение. К ним можно отнести (согласно Charles Sutton):

Таким образом, процесс получения полного пайплайна обработки и анализа данных можно рассматривать как сложную систему (т.е. complex system).
С одной стороны, наличие перечисленных факторов осложняет как решение задач машинного и глубокого обучения, так и их автоматизацию. С другой стороны, непрерывно растущие и все более доступные вычислительные возможности позволяют приложить к задаче большее количество ресурсов.
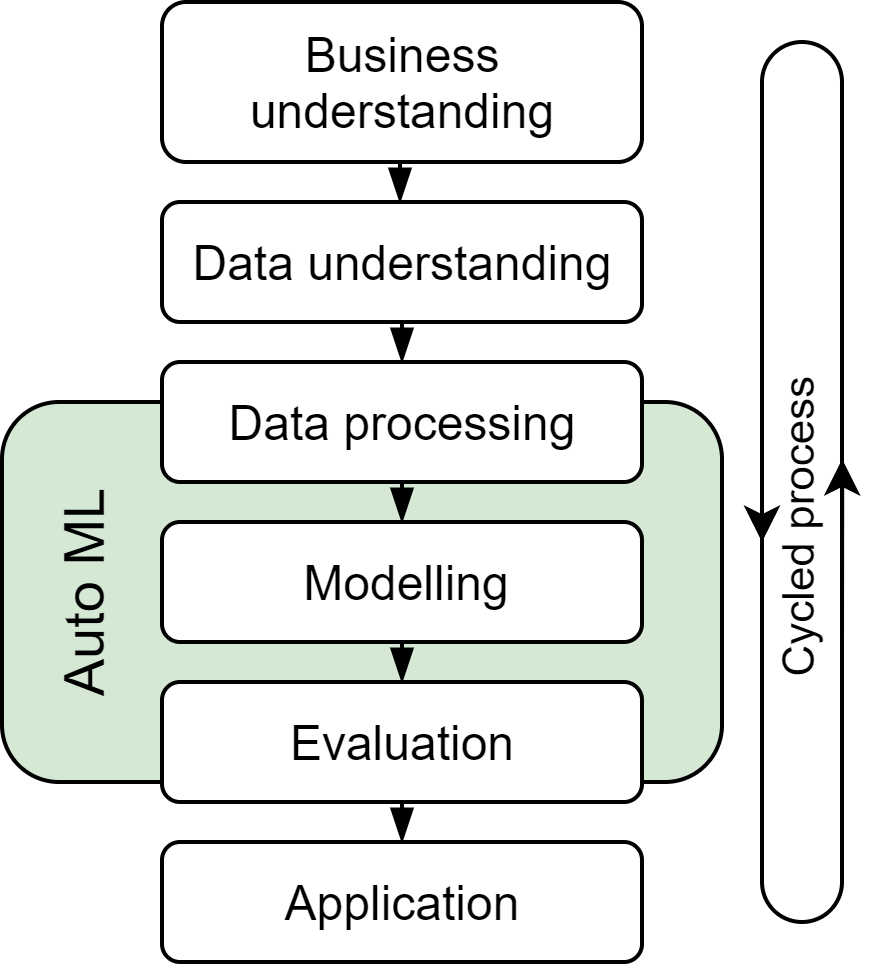 Согласно распространенному стандарту CRISP-DM, жизненный цикл проекта, связанного с анализом данных, итеративно состоит из шести основных этапов: понимание бизнес-задачи (business understanding), понимание и изучение данных (data understanding), обработка данных (data preparation), моделирование (modelling), оценка качества (evaluation) и практические применение (deployment, application). На практике, не все эти этапы на сегодняшний день могут быть эффективно автоматизированы.
Согласно распространенному стандарту CRISP-DM, жизненный цикл проекта, связанного с анализом данных, итеративно состоит из шести основных этапов: понимание бизнес-задачи (business understanding), понимание и изучение данных (data understanding), обработка данных (data preparation), моделирование (modelling), оценка качества (evaluation) и практические применение (deployment, application). На практике, не все эти этапы на сегодняшний день могут быть эффективно автоматизированы.
В большинстве работ или существующих библиотек (h2o, auto-sklearn, autokeras) основной акцент делается на автоматизацию моделирования и отчасти на оценку качества. Однако расширение подхода в сторону автоматизации обработки данных позволяет покрыть большее количество этапов (что, например, было применено в сервисе Google AutoML).
Задачи машинного обучения с учителем могут быть решены различными методами, большинство из которых сводятся к минимизации функции потерь или максимизации функции правдоподобия
или максимизации функции правдоподобия  , с целью получения оценки параметров
, с целью получения оценки параметров  на основе имеющейся выборки — обучающего набора данных
на основе имеющейся выборки — обучающего набора данных  :
:
 или
или  , где
, где  – обучаемые параметры модели (например, коэффициенты в случае регрессии).
– обучаемые параметры модели (например, коэффициенты в случае регрессии).
Чтобы не ограничивать автоматизацию только моделированием, можно распространить область применения метода и на другие этапы пайплайна. Например, автоматизировать принятие решений о том, какие методы обработки данных применить, о выборе модели или их комбинаций, а также подбору близких к оптимальным гиперпараметров.
Проиллюстрируем описанное на простом примере, в рамках которого происходит выбор между двумя методами обработки данных (standard scaler и quantile scaler) и двумя моделями (random forest и neural network), включая подбор некоторых гиперпараметров. Структуру выбора можно представить как дерево:
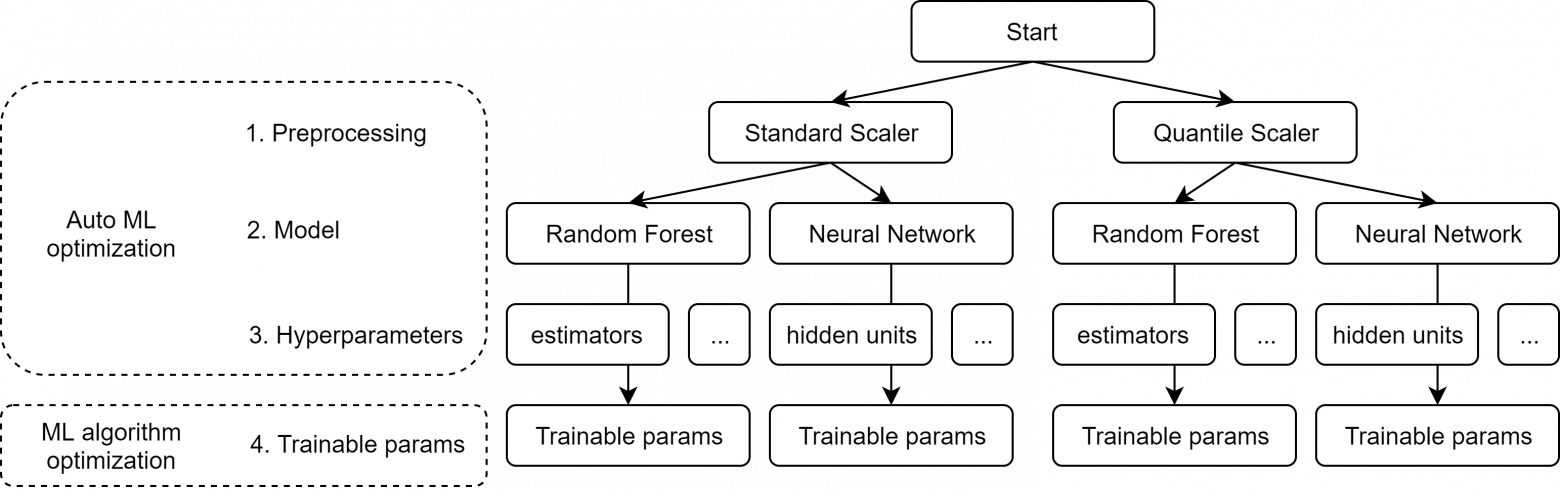
Каждый осуществляемый выбор является параметром системы, а само дерево при этом становится пространством возможных параметров. Такой взгляд на проблему позволяет подняться выше на уровень абстракции и сформулировать задачу получения итогового пайплайна, включающего методы обработки данных, модели и их параметры, как процесс минимизации или максимизации функции:
 или
или  , где
, где  – необучаемые параметры,
– необучаемые параметры,  – выборка отложенного контроля (набор данных для кросс-валидации).
– выборка отложенного контроля (набор данных для кросс-валидации).
К основным достоинствам подобной автоматизации обучения можно отнести:
Однако автоматизация не лишена недостатков:
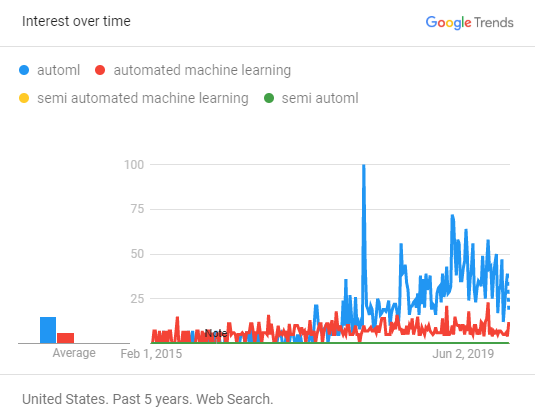
Пытаясь сохранить как можно больше достоинств и уйти при этом от ряда недостатков, в частности, из-за желания получить дополнительный контроль над решением, мы пришли к подходу, который носит название semi-auto ml. Это сравнительно новое явление в области, о чем может косвенно свидетельствовать быстрый анализ Google Trends:
Достижение такого компромисса можно условно сравнить с различными способами переключения передач в автомобильных трансмиссиях (именно способами переключения, но не их внутренним устройством):
В ходе работ над внутренними проектами нами был создан инструмент, позволяющий решать задачу полуавтоматического машинного обучения на основе гибридной функционально-декларативной системы конфигурации. Такой подход к конфигурации использует не только стандартные типы данных, но и функции из распространенных современных библиотек для машинного и глубокого обучения. Инструмент позволяет автоматизировать создание простых методов обработки данных, базовое конструирование признаков (feature engineering), выбор моделей и их гиперпараметров, а также выполнять расчет на Spark или GPU кластере. В листинге приводится формализация примера, приведенного ранее в статье. Пример использует простые модели из sk-learn и hyperopt (в открытый код которого даже удалось внести незначительный вклад в ходе работы) для распределения параметров и оптимизации.
Подобная полуавтоматическая система, включающая механизм конфигурации, дает возможность создавать заранее подготовленные типовые сценарии в случаях, когда, например, определенное семейство моделей лучше подходит для решения каких-либо задач. К ним, в частности, может относиться кредитный скоринг, однако подобный шаг требует дополнительных исследований на широком спектре схожих задач. Также при работе над механизмом поиска возможно автоматически поддерживать баланс в дилемме смещения-дисперсии (bias-variance tradeoff) за счет одновременного учета значений оптимизируемой функции как на обучающей, так и кросс-валидационной выборке.
Полное отсутствие автоматизации на практике встречается довольно редко, поскольку даже перебор значений одного гиперпараметра в цикле – уже шаг к автоматизации. В то же время, полная автоматизация всего процесса построения пайплайна также практически недостижима на сегодняшний день. Соответственно, при разработке большинства современных проектов осознанно или неосознанно применяются подходы автоматизации.
Применение полуавтоматического машинного обучения позволяет более эффективно использовать ресурсы исследователя или разработчика за счет автоматизации рутины, не отбирая при этом значительную часть гибкости в работе. Как мы видим, предложенное решение требует участия человека, ограничивающего пространство возможных параметров системы. При этом введение типовых сценариев, полученных на основе системы конфигурации, позволяет использовать не только подходы частичной автоматизации, но и полной, не требующей участия человека.

Автоматизация по определению Mikell P. Groover – это технология, при помощи которой процесс или процедура выполняются с минимальным человеческим участием. Автоматизация уже давно позволяет добиться повышения производительности труда, что зачастую ведет к снижению себестоимости единицы продукта. Методы автоматизации, как и области их применения, стремительно совершенствуются и в течение последних столетий развились от простых механизмов до промышленных роботов. Автоматизация начинает затрагивать не только физический труд, но и интеллектуальный, добираясь до сравнительно новых областей, включая и машинное обучение – automated machine learning (auto ml, aml). В то же время, автоматизация машинного обучения уже нашла свое применение в ряде коммерческих продуктов (например, Google AutoML, SAP AutoML и другие).



Disclaimer
Данная заметка не претендует на догматичность в области и является ви́дением автора.
Automated Machine Learning
Задачи в области обработки данных и машинного обучения связаны с множеством факторов, возникающих из-за сложности системы и затрудняющих их решение. К ним можно отнести (согласно Charles Sutton):
- Наличие неопределенности и неизвестности, к которым ведет недостаток априорных знаний о данных и искомых зависимостях. Таким образом, всегда присутствует исследовательский элемент.
- «Смерть от тысячи порезов». На практике при построении пайплайна обработки и анализа данных и последующего моделирования приходится принимать множество больших и небольших решений. Например, необходимо ли нормализовать данные, если да, то каким методом, а какие параметры должны быть у этого метода? И т.д.
- Наличие циклов обратной связи, вытекающее из неопределенности. Чем дольше происходит погружение в задачу и данные, тем больше удается узнать о них. Это ведет к необходимости сделать шаг назад и внести изменения в имеющиеся механизмы обработки и анализа.
- Кроме того, результаты моделей, полученных алгоритмами машинного обучения, являются лишь приближением реальности, т.е. заведомо не точны.

Таким образом, процесс получения полного пайплайна обработки и анализа данных можно рассматривать как сложную систему (т.е. complex system).
Complex system
Как сказал профессор Peter Sloot, сложные системы это не только «налоговые формы» и «романтические отношения», но и широкий круг вещей и процессов. Например, (а) совместная работа молекул в клетке организма, позволяющая им поддерживать жизнь, (б) распространение эпидемии, (в) взаимодействия социальных групп и т.д. Отличительными чертами сложных систем служат в том числе наличие в них большого количества взаимодействующих элементов и нелинейные связи между ними, что может приводить к спонтанным эффектам, самоорганизации и другим сложно воспроизводимым процессам.
С одной стороны, наличие перечисленных факторов осложняет как решение задач машинного и глубокого обучения, так и их автоматизацию. С другой стороны, непрерывно растущие и все более доступные вычислительные возможности позволяют приложить к задаче большее количество ресурсов.
 Согласно распространенному стандарту CRISP-DM, жизненный цикл проекта, связанного с анализом данных, итеративно состоит из шести основных этапов: понимание бизнес-задачи (business understanding), понимание и изучение данных (data understanding), обработка данных (data preparation), моделирование (modelling), оценка качества (evaluation) и практические применение (deployment, application). На практике, не все эти этапы на сегодняшний день могут быть эффективно автоматизированы.
Согласно распространенному стандарту CRISP-DM, жизненный цикл проекта, связанного с анализом данных, итеративно состоит из шести основных этапов: понимание бизнес-задачи (business understanding), понимание и изучение данных (data understanding), обработка данных (data preparation), моделирование (modelling), оценка качества (evaluation) и практические применение (deployment, application). На практике, не все эти этапы на сегодняшний день могут быть эффективно автоматизированы.В большинстве работ или существующих библиотек (h2o, auto-sklearn, autokeras) основной акцент делается на автоматизацию моделирования и отчасти на оценку качества. Однако расширение подхода в сторону автоматизации обработки данных позволяет покрыть большее количество этапов (что, например, было применено в сервисе Google AutoML).
Постановка задачи
Задачи машинного обучения с учителем могут быть решены различными методами, большинство из которых сводятся к минимизации функции потерь
или максимизации функции правдоподобия , с целью получения оценки параметров на основе имеющейся выборки — обучающего набора данных : или , где – обучаемые параметры модели (например, коэффициенты в случае регрессии).Чтобы не ограничивать автоматизацию только моделированием, можно распространить область применения метода и на другие этапы пайплайна. Например, автоматизировать принятие решений о том, какие методы обработки данных применить, о выборе модели или их комбинаций, а также подбору близких к оптимальным гиперпараметров.
Проиллюстрируем описанное на простом примере, в рамках которого происходит выбор между двумя методами обработки данных (standard scaler и quantile scaler) и двумя моделями (random forest и neural network), включая подбор некоторых гиперпараметров. Структуру выбора можно представить как дерево:

Каждый осуществляемый выбор является параметром системы, а само дерево при этом становится пространством возможных параметров. Такой взгляд на проблему позволяет подняться выше на уровень абстракции и сформулировать задачу получения итогового пайплайна, включающего методы обработки данных, модели и их параметры, как процесс минимизации или максимизации функции:
или , где – необучаемые параметры, – выборка отложенного контроля (набор данных для кросс-валидации).К основным достоинствам подобной автоматизации обучения можно отнести:
- Подбор большего числа параметров системы при наличии одной входной точки в рамках единого процесса оптимизации.
- Автоматизация рутины, спасающая исследователя или разработчика от «тысячи порезов».
- «Демократизация» машинного обучения за счет его автоматизации, что позволяет применять многие методы людям, не являющимися специалистами.
Однако автоматизация не лишена недостатков:
- С увеличением числа параметров растет и их пространство, что рано или поздно приводит к комбинаторному взрыву, требующему развития алгоритмов и увеличения количества вычислительных ресурсов.
- Полностью автоматические методы предоставляют не всегда гибкое решение по принципу “black box”, что снижает контроль над результатом.
- Пространство параметров ω нелинейно и обладает сложной структурой, что затрудняет процесс оптимизации.
От автоматизации к полуавтоматизации
Пытаясь сохранить как можно больше достоинств и уйти при этом от ряда недостатков, в частности, из-за желания получить дополнительный контроль над решением, мы пришли к подходу, который носит название semi-auto ml. Это сравнительно новое явление в области, о чем может косвенно свидетельствовать быстрый анализ Google Trends:

Достижение такого компромисса можно условно сравнить с различными способами переключения передач в автомобильных трансмиссиях (именно способами переключения, но не их внутренним устройством):
 |
Ручное переключение – водитель контролирует сцепление и передачи. Аналогия: пользователь самостоятельно производит выбор методов и создает пайплайн. |
 |
Автоматическое – нет необходимости самостоятельно выбирать передачи, только задать режим. Аналогия: пользователь получает готовое решение. |
 |
Полуавтоматическое переключение – водитель не контролирует сцепление, но имеет возможность выбора передач. Аналогия: пользователь определяет выбор методов, но делегирует их выбор или даже создание пайплайна системе. |
В ходе работ над внутренними проектами нами был создан инструмент, позволяющий решать задачу полуавтоматического машинного обучения на основе гибридной функционально-декларативной системы конфигурации. Такой подход к конфигурации использует не только стандартные типы данных, но и функции из распространенных современных библиотек для машинного и глубокого обучения. Инструмент позволяет автоматизировать создание простых методов обработки данных, базовое конструирование признаков (feature engineering), выбор моделей и их гиперпараметров, а также выполнять расчет на Spark или GPU кластере. В листинге приводится формализация примера, приведенного ранее в статье. Пример использует простые модели из sk-learn и hyperopt (в открытый код которого даже удалось внести незначительный вклад в ходе работы) для распределения параметров и оптимизации.
'preprocessing': {
'scaler': hp.choice('scaler', [
{
'func': RobustScaler,
'params': {
'quantile_range': (10, 90)
}},
{
'func': StandardScaler,
'params': {
'with_mean': True
}}
]),
},
'model': hp.choice('model', [
{
'func': RandomForestClassifier,
'params': {
'max_depth': hp.choice('r_max_depth', [2, 5, 10]),
'n_estimators': hp.choice('r_n_estimators', [5, 10, 50])
}
},
{
'func': MLPClassifier,
'params': {
'hidden_layer_sizes': hp.choice('hidden_layer_sizes', [1, 10, 100]),
'learning_rate_init': hp.choice('learning_rate_init', [0.1, 0.01])
}
},
])
Подобная полуавтоматическая система, включающая механизм конфигурации, дает возможность создавать заранее подготовленные типовые сценарии в случаях, когда, например, определенное семейство моделей лучше подходит для решения каких-либо задач. К ним, в частности, может относиться кредитный скоринг, однако подобный шаг требует дополнительных исследований на широком спектре схожих задач. Также при работе над механизмом поиска возможно автоматически поддерживать баланс в дилемме смещения-дисперсии (bias-variance tradeoff) за счет одновременного учета значений оптимизируемой функции как на обучающей, так и кросс-валидационной выборке.
Заключение
Полное отсутствие автоматизации на практике встречается довольно редко, поскольку даже перебор значений одного гиперпараметра в цикле – уже шаг к автоматизации. В то же время, полная автоматизация всего процесса построения пайплайна также практически недостижима на сегодняшний день. Соответственно, при разработке большинства современных проектов осознанно или неосознанно применяются подходы автоматизации.
Применение полуавтоматического машинного обучения позволяет более эффективно использовать ресурсы исследователя или разработчика за счет автоматизации рутины, не отбирая при этом значительную часть гибкости в работе. Как мы видим, предложенное решение требует участия человека, ограничивающего пространство возможных параметров системы. При этом введение типовых сценариев, полученных на основе системы конфигурации, позволяет использовать не только подходы частичной автоматизации, но и полной, не требующей участия человека.
