
Что делать с понятием, соединяющим две разных технических области? Добавить третью! DevOps соединил «development» и «operations», но что в этом случае произошло с «testing»? А что должно произойти, чтобы всё было по уму?
Руслан Ахметзянов @arg89уже выступал у нас и на девопс-конференции DevOops, и на конференции по тестированию Heisenbug. Сейчас он готовит новый доклад, а мы готовим новые DevOops и Heisenbug — и в ожидании этого решили расшифровать для Хабра его предыдущее выступление. Кто-то может не согласиться с его выводами, но так даже интереснее!
Далее повествование идёт от лица спикера.
Сегодня мы поговорим о том, когда тестирование выпало из DevOps и как его туда вернуть.
Я работаю в Qameta Software, мы делаем опенсорс-продукт Allure Report, который помогает разработчикам и тестировщикам делать репортинг для автотестов. Моя миссия как человека, который занимается developer relations в этом стартапе — делать жизнь тестировщиков лучше и приятнее. Вы можете спросить: а что я делаю на конференции DevOops, если занимаюсь жизнью тестировщиков? И это правильный вопрос, именно об этом мы сегодня и поговорим.
При чем здесь тестировщики? В ответ на анонс моего доклада Серёга Егоров @bsideup из Atomic Jar, которые занимаются тест-контейнерами, написал в Твиттере:

Мол, у меня очень спорный посыл, а в DevOps всё нормально с тестированием, потому что разработчики давным-давно научились его делать и получилось, что QA не нужны.
Но я считаю подход «QA не нужны» немного разрушительным.
Да, разработчики действительно пишут много автоматизированных тестов — юнит-тесты, тестирование API, интеграционные тесты. Но разница здесь не в том, какие тесты пишут разработчики, а в том, как они их пишут.
Мне не хочется сейчас говорить что-то вроде «разработчик — творческая личность». Но разработчики — это созидатели, то есть они мыслят категориями создания: как написать программу так, чтобы она работала. И именно это проверяют: смотрят, что все концепты реализованы правильно, структуры данных работают верно, нормально взаимодействуют и хорошо описаны.
В итоге, если QA-подразделения вообще нет, то разработчики будут транслировать: «Смотрите, всё работает хорошо».
А когда существует подразделение QA, их основная задача — показать, что всё не так уж и хорошо.
Чтобы это всё обсуждать, давайте представим среднестатистическую команду, которая занимается разработкой софта.

У нас есть руководитель QA, который, скорее всего, имеет большой опыт ручного тестирования. Он знает, как надо тестировать.
У нас есть автоматизатор, который знает, как автоматизировать.
У нас есть разработчица — она пишет код и катит его в прод.
И, естественно, есть человек, который следит за тем, чтобы всё работало. Ну, такой «DevOps-инженер».
Что сейчас?
В целом эта команда замечательно работает. У нас есть пайплайн, на котором гоняются тесты, собранные в нескольких quality-гейтах. Обычно это какая-нибудь регрессия, приёмочное тестирование, смоук или какой-то канареечный релиз. Всё это есть в пайплайнах. Эти автотесты работают — периодически запускаются, падают или не падают. Если падают, то кто-то разбирает результаты. Сошлюсь тут на хабрапост от Superjob.

Одновременно с этим существует небольшой аппендикс, где ручные тестировщики на новую функциональность или сложные e2e-тесты всё ещё пишут развесистые тест-кейсы и прогоняют их руками. И в целом вроде бы всё работает. Как на картинке — машинки летят отдельно, люди летят отдельно, тесты выполняются, светофоры есть — очень круто. Ну, DevOps же!
Но тут я вспоминаю более раннюю фразу того же Серёги Егорова от 15 марта 2021 года:

Эта цитата великолепна. Можно сразу и не заметить, что в слове DevOps нет буквы Т, и так же можно не замечать, что с тестированием в DevOps всё тоже не так понятно.
Поэтому задача моего доклада — объяснить, как всё пошло не туда, и что можно сделать, чтобы эту букву Т вернуть. Потому что, скорее всего, люди, которые занимаются пайплайнами или разработкой, просто не видят того, что происходит в QA-подразделениях.
Невидимая сторона
Глядя на такой слайд, скорее всего, вы ждёте, что справа что-нибудь появится — какой-то текст или буллет-пойнты:

Но там ничего нет и не появится — сколько ни вглядывайтесь. Это и есть та невидимая сторона. И она выглядит как подразделение QA, которое немножечко выпадает из истории. Почему? Потому что тестировщики тоже пишут тесты.
Зачастую в подразделениях, которые занимаются качеством, ручники правят балом. Это значит, что структура тест-кейсов, процессы в отделе, механики разбора результатов, механики по составлению отчетов, основные детали и взаимодействия с другими подразделениями построены по принципам, которые были разработаны довольно давно. Это хорошие принципы, они позволяют находить очень много багов и вовремя их исправлять. Но пока весь остальной мир бежит галопом в сторону DevOps и пытается сделать shift left всего, что можно (или shift right, если left невозможно), это разбегание shift left — shift right, приводит к тому, что тестирование подбуксовывает.
Этому есть несколько причин. Например, в тестировании раньше не было инструментов, которыми можно было бы пользоваться для автоматизации. Все эти штуки появились совсем недавно. И в этой реальности, когда у нас есть куча руководителей подразделений, которые занимаются тем, что обеспечивают качество по-своему, есть большое количество тестировщиков-автоматизаторов, которые, скорее всего, под руководством и давлением старых процессов, старых структур и старых тест-кейсов отчаялись что-то доказать и сделать.
И они действительно пишут автоматизированные end-to-end тесты, которые чаще всего выглядят как ручные тестовые сценарии, которые загнаны в REST-код и гоняются на вашем CI/CD. И если вы это смотрите, то вполне вероятно, что вы ровно в этой ситуации и находитесь. Потому что, с точки зрения DevOps, тестирование есть — тесты присылают, они гоняются, результаты разбираются, ещё и девелоперы накидывают своих тестов. Да вообще всё круто! Все quality-гейты выглядят солидно.
Но эту штуку можно очень сильно улучшить. И об этом мы поговорим, чтобы ваше тестирование соотносилось с теми практиками и подходами, которые существуют в DevOps.
TestOps Lifecycle
Недавно мы в Qameta сформулировали штуку, которая называется TestOps Lifecycle. Она рассматривает девять стадий развития тестовой инфраструктуры команды и процессов.
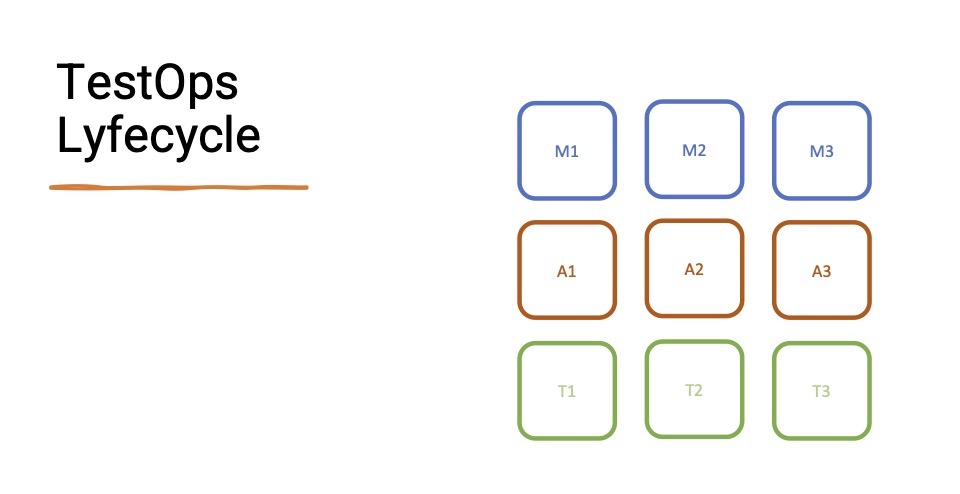
Каждый ряд отвечает за некую веху (M — manual, A — automated, T — TestOps), а каждый столбик — за степень её развития. М1 — ручное тестирование, которое только зародилось. A3 — это супер-топовая автоматизация.
TestOps — это подход, который мы предлагаем, чтобы естественным образом вернуть тестирование в DevOps. Долго название мы не выдумывали: DevTestOps не звучит, поэтому оставили просто TestOps. Подробнее о жизненном цикле говорилось в докладе Артёма Ерошенко «Сказка о потерянном времени». А еще подробнее этот концепт был раскрыт в нашем блоге.
Зачем нам нужен TestOps? Именно с этого вопроса и появился этот доклад, потому что полгода назад после конференции Heisenbug, когда мы сидели в барчике, я рассказывал коллегам, что мы делаем свой продукт, который помогает компаниям реализовывать TestOps. Меня спрашивают: «А что за TestOps? Ведь тестирование же и так есть в DevOps, ты же знаешь классический треугольник: Dev, Ops и QA».
И действительно, смотрите, все работают вместе:
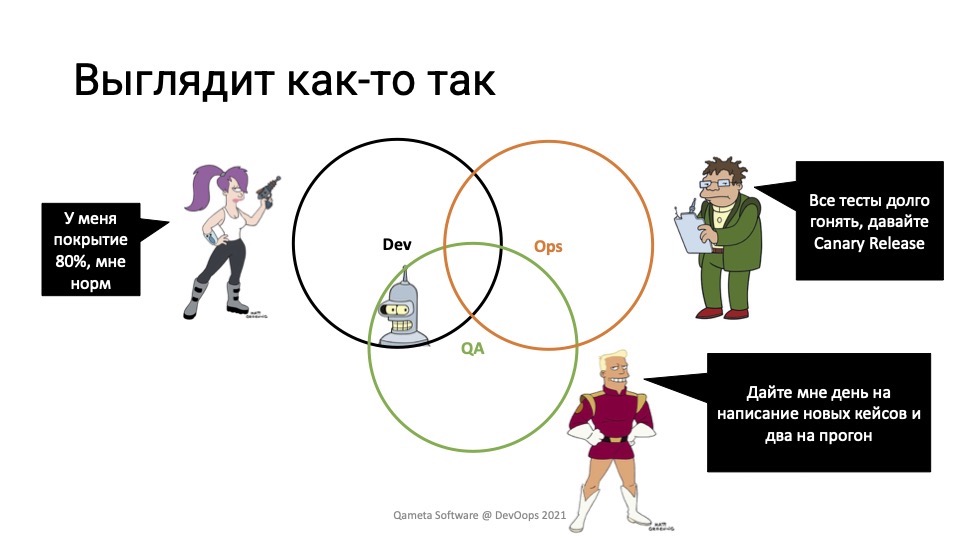
У девелоперов 80% кода покрыто тестами. Ops-ы говорят: «Слушайте, даже если мы что-то не успеваем, давайте делать canary-релизы». Управление качеством происходит. Но при этом тестирование происходит не всегда хорошо.
Где-то там находится маленький автоматизатор на стыке девелоперов и QA, потому что, скорее всего, автотесты гоняются на отдельном сервере на отдельные сборки. При этом руководитель подразделения говорит: «Слушайте, вы тут написали функциональности, нам нужен день на написание новых тест-кейсов, чтобы эту функциональность нормально end-to-end проверить. А ещё нужно денька два на прогон, потому что мы сейчас 50 ручных тестов проверим, а у нас пять тестировщиков. У них это займёт некоторое время»
Действительно ли тогда картинка выглядит так? Возможно, она выглядит как-то так:
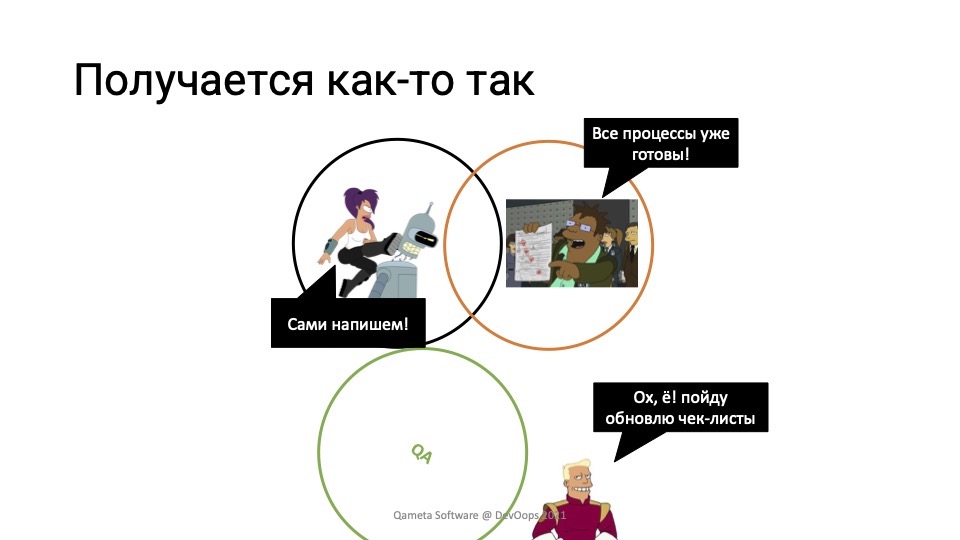
Девелоперы говорят: «QA не нужно, мы сами все тесты напишем».
Ребята из QA говорят: «Там всё гоняется, ребята хотят сильно быстрее. Пойду-ка я чек-листы обновлю и всё будет нормально».
Ops-ы кричат: «Так, у нас все процессы уже готовы, валите-ка вы нафиг. Смотрите, пайплайны есть, quality-гейты есть, тесты гоняются, результаты проверяются, релизы чистые. Мы же катим в прод! Ну да, бывают баги».
Давайте постараемся разобраться, почему эта невидимая сторона так сильно мешает тестированию войти в DevOps.
На предыдущем слайде вы видели Зеппа Браннигана, и он такой: «Ну, я пошёл заниматься своим делом». Можно подумать, что я хочу сказать, что ручные тестировщики — нехорошие. Но это не так. Ручные тестировщики — крутые специалисты. Они молодцы, они классно делают свою огромную работу, и у них есть свои уникальные компетенции. Но они не успевают писать тесты на новую функциональность, потому что последние годы заставили менеджеров думать, что нам нужно два релиза в день.

Ещё раз сделаю отсылочку к ребятам из SuperJob, потому что у них была такая же история. У них была куча ручных тестировщиков, и они релизились раз в неделю. Потом пришел кто-то из менеджеров и сказал: «Слушайте, ребятки, тут все вообще-то релизятся два раза в неделю». И все такие: «Ну, давайте релизиться дважды в неделю». Ручные тестировщики почесали репу: «Тогда нам придётся рабочий день увеличивать или тестировщиков нанять, потому что это долго. Давайте что-нибудь попробуем автоматизировать». Они взяли базовый PHP-фреймворк, начали писать тестики на PHP и всё ускорили.
Потом приходят менеджеры и говорят: «Так, мы в два раза ускорились. Давайте теперь дважды в день релизить». И тут начинается головная боль, потому что в таком темпе вообще никак это не успеть. И есть ещё куча проблем — ребята не успевают прогонять эти тесты, особенно если они ручные. Разбирать падения — это вообще боль, потому что, если у вас есть тысяча тестов и падает 5%, это 50 тестов. Если у вас нет автоматизации, репортинга и так далее, то вручную всё это проверять — это больно.
Раньше не было никаких инструментов, поэтому сейчас нужно за ними активно следить на конференциях. А мы знаем, какой процент людей ходит на конференции или митапы. Кто-то, может, почитывает Хабр, и на этом всё. Не все знают про новые инструменты, и нет никакого глобального обучения. Нормальные курсы появляются только сейчас. Поэтому надо учиться, учиться и еще раз учиться, а у ручных тестировщиков и своей работы немало.
Как жить
Я поверху пробежался по основным проблемам, и чтобы все их описать, сейчас постараюсь рассказать о том, как эта штука должна работать. Расскажу, какие есть основные вехи в развитии подразделения, прохождение которых поможет сломать стену между легаси-тестированием и DevOps-ready тестированием.
Вот та самая «схема из девяти квадратиков», в реальности она выглядит чуть-чуть сложнее:

Мы сегодня не будем рассматривать все 9 стадий, потому что в контексте этого доклада нам интересно, когда уже есть какое-то тестирование и нам нужно его двигать вперед. Нас интересуют 5 стадий.
Я попробую рассказать вам, как из М2 перейти в стадию А1, то есть ввести какую-то автоматизацию. А затем её поднастроить.
И есть опциональные шаги, которые можно пропустить, если у вас уже очень крутая команда.
Итак, как нам прийти в шаг Т2? Мы не говорим про T3, потому что там уже условная команда мечты и всё прекрасно.
M2-M3

Первая история — это переход из М2 в М3. Давайте посмотрим, что такое стадия М2. Это когда у нас есть команда нормальных ручных тестировщиков-миддлов, парочка сеньоров, и основные задачи на этом этапе — повышать прозрачность тестирования.
То есть делать такие процессы, чтобы люди понимали, куда все двигается, какие тесты прошли, какие не прошли. Формализовать работу с тест-кейсами, создать шаблоны, спроектировать все эти тест-кейсы и уйти от принципа «чуваки, не парьтесь, я всё проверил». Условно, если разработчик говорит: «Вот эту функциональность проверять не надо, там всё покрыто тестами», ручные тестировщики на этапе М2 должны сказать: «Нет, подожди, мы напишем свои E2E-тесты и всё погоняем».
Здесь важно понять, что на этом этапе уже нужны коммуникации. Я уже упоминал, что тестировщики и разработчики относятся к тестированию по-разному. Разработчик пытается убедиться в том, что всё работает, как надо. А тестировщики пытаются найти случаи, в которых что-то работает не так.
И на позиции М2 мы должны создать нужное количество тест-кейсов, обеспечить покрытие, обеспечить все процессы. При этом у этой штуки скорость будет линейно масштабироваться в зависимости от количества тестировщиков. Даже не линейно, а скорее логарифмически, потому что в какой-то момент новые тестировщики будут настолько погружены в инфраструктуру и управленческие проблемы, что быстрее работать она не будет.
И в этом месте нужны TMS — Test Management Systems, которые заменяют тестировщикам в больших командах условный Excel. Они позволяют использовать удобный интерфейс для создания тест-кейсов, проходить в них шажки и галочками всё отмечать. Многие TMS умеют закидывать результаты ручного тестирования на СI, чтобы CI сам понимал, что тесты прошли и прогон можно зацепить вебхуком, чтобы всё побежало. В качестве примеров назову TestRail и PractiTest — это индустриальные стандарты, они очень часто используются.
Чтобы попасть из стадии M2 на M3, нужно сначала начать измерять время качества и количества прогонов и покрыть все E2E-тестами, а затем переходить к следующему шагу: оптимизировать ручную работу.
При этом есть два пути. Можно сразу пойти за автоматизацией в А1. А можно пойти в сторону M3: это когда у нас появляется команда крутых ручников, умеющих использовать инструменты автоматизации ручного тестирования. То есть инструменты вроде Postman, Playwright, Fake Data, QA Wolf, инструменты для тестирования, которые позволяют эмулировать вёрстку на экранах с разными разрешениями без обилия разных девайсов и ручного запуска всех этих вещей.
А для чего все это? Для того, чтобы начать верить в автоматизацию. Тогда дальнейший переход в А1 будет намного менее болезненный.
Зачем нам вообще переходить из этого места? Потому что на М2 мы можем только донанимать тестировщиков, и у этого подхода, очевидно, есть пределы. M3 масштабируется намного лучше, потому что автоматизированные инструменты позволяют всё померить, понять, где проблемы, и что-то оптимизировать. Но при этом все еще остается большой предельный срок и мы все еще зависим от людей, которые осуществляют тестирование, и мы можем забыть о трех ночных прогонах. Нет, наверняка есть команды, в которых тестировщики любят работать по ночам. Однако это не очень хорошо с точки зрения вселенной и отношения к людям. Поэтому мы хотим от этого уходить.
M2-A1
Давайте посмотрим на переход от М2 к А1. А1 — это стадия, на которой у нас есть один автоматизатор и основные задачи — просто начать что-то автоматизировать и покрыть простыми тестами mission-critical кейсы. При этом у нас Restful-тесты будут полностью копировать пошагово ручные сценарии.
У нас есть 30-шаговая портянка, в которой написано «Мы логинимся сюда, вводим пароль, смотрим кнопку, кнопка отображается, всё правильно». Вы, наверное, представляете, как выглядит типичный ручной тест-кейс, где надо все ручками проверить и прокликать. Мы делаем точно такие же тесты, только теперь эту работу выполняют роботы. Соответственно, всё запускается, mission-critical тесты у нас прогоняются, Jenkins терпеливо ждет, когда пройдут ручные тесты. Автоматизированные уже условно быстро пробегают. Но нам всё равно нужно дождаться, когда пробегутся основные ручные тесты. Потому что это некий переходный режим. Как видите, Бендер тут у нас ещё совсем сосунок и он не готов к тому, чтобы самостоятельно взять себе функциональность и всю мощность тестирования, но он готовится. И на этом шаге очень важно начать генерировать автоматизированные тест-кейсы и считать от них пользу. Что я имею в виду? Я имею в виду, что вы написали один автоматизированный тест-кейс, а теперь посмотрите, как часто он прогоняется, как часто он находит ошибки и насколько быстрее он проходит. Потому что как только Зепп Бранниган, который уверовал еще на стадии M3 или не уверовал на стадии М2 в автоматизацию, посмотрит и посчитает, дальше все пойдет намного проще.
Вторая штука — это научиться делать самодокументацию. При изменении какой-то функциональности или изменении теста, если самодокументацию не сделать, то она начнёт очень быстро устаревать, когда мы начнем наращивать объем тестов. Каждое отделение фиче-ветки будет делать документацию устаревший, потому что где-то меняется функциональность. Вручную документацию править плохо, потому что автоматизатор поправит тест, а ручной тестировщик, который занимается докой, про это может вообще не вспомнить или не узнать. Вы, конечно, можете заниматься тем, чтобы строить сложные системы коммуникации и нотификации в Slack, но может быть всё-таки стоит подумать про автоматизацию — мы же на DevOps-конференции :)
Здесь у нас остаются некоторые проблемы — сильно быстрее не стало, и вот это очень опасный шаг. Потому что мы начали делать автоматизацию, смотрим на это и думаем: «Быстрее не стало, зато стало очень запутаннее!» У нас появилась куча инструментов, новые люди, которые немножко отличаются от классических тестировщиков, у нас появились новые коммуникации. Теперь ещё и тестировщики странно на нас поглядывают.
A1-A2
Поэтому нам нужно быстренько двигаться в стадию А2. А это такая стадия, на которой автоматизаторы уже умеют пушить в репу и строить аналитику в Grafana. Компании уже стараются построить стабильность SQS — Software Quality System. И первое, что здесь нужно это сделать — кнопку для всех. Что значит кнопка? Это значит, что когда мы увеличили покрытие автоматизации, когда мы уже знаем, что наши тесты хорошие, мы начинаем эти тесты потихонечку перепиливать и делать их атомарными.
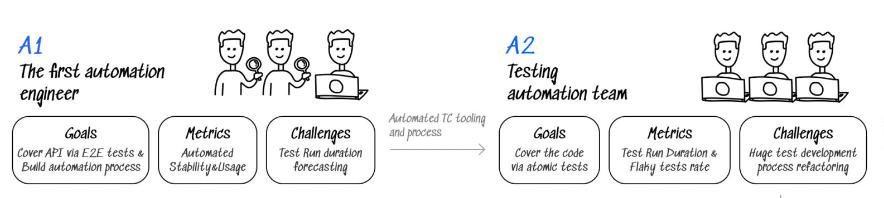
Готовим сами данные и готовим какое-то API, чтобы эти тесты нормально ходили туда-сюда в код. При этом это можно делать и со стороны разработки, и со стороны тестирования. То есть, когда мы научим наших двух Бендеров со стороны разработки и со стороны тестирования общаться, мы должны сделать кнопочку и заставлять всех нажимать эту кнопочку. А кнопочка делает одну простую вещь — запускает набор автоматизированных тестов и показывает результат. И мы делаем так, чтобы про эту кнопку все знали.
Если у нас покрытие обеспечено, как только у нас возникает эта история, могут возникнуть и проблемы. Наша задача — сделать так, чтобы разработчик сделал фиче-ветку и как только внес изменения, то нажал кнопку. Если где-то что-то упало, мы должны быстро пофиксить тесты, а если они фиксятся долго, то, скорее всего, на шаге А1 мы что-то сделали не так — надо возвращаться и переделывать.
Что такое атомарные тесты? Это значит, что когда у нас существует развесистый тест-кейс из предыдущего пункта, он в автоматизации жутко неудобен. Потому что автоматизация привыкла тестировать одну функцию. Если у разработчика есть один юнит-тест, он же не такой уж и большой. И здесь мы стремимся к тому же самому эффекту — мы хотим, чтобы один тест тестировал маленькую функциональность. Всё остальное мы мокаем, закрываем заглушками, изолируем и делаем на один ручной тест-кейс пять-семь автоматических тестов. И вот в этот момент сама документация нам очень важна, потому что эти пять-семь тестов очень сложно будет смапить на ручные тест-кейсы, которые существовали до этого в документации. Документация она существует либо в testRel, либо в Confluence в виде списка тест-кейсов или тест-сьютов. И как только мы попробуем эти автоматизированные тест-кейсы натянуть на нашу документацию, мы поймём, что все плохо. Если у нас будет сама документация, то у нас будет больше тестов в доке, но при этом каждый из них будет всегда актуален.
И когда это всё происходит, наш Бендер становится расслабленный, берет бутылочку пива и, в целом, всё хорошо. Я снова возвращаюсь к истории Superjob, потому что ребята круто всё сделали. Они действительно настроили автоматизацию таким образом, что регрессионные и acceptance quality-гейты прогонялись полностью автоматически, они начали релизить дважды в сутки, это тоже круто. У них остался только один дежурный разработчик и один дежурный тестировщик на случай, если релизы вдруг падают или не проходят «качественные ворота».
Но опять же, если вы почитаете статью, то в конце увидите замечательную мысль о том, что все еще не закончено. Потому что у вас все еще есть куча проблем. Флакающие тесты, которые дают разные результаты при неизменном коде теста — в зависимости от времени запуска, в зависимости от инфраструктуры, на которой запустили, в зависимости от параметров launch-a, в зависимости от положения Меркурия в доме Луны (или как это правильно говорится?). В общем, в зависимости от странных и непонятных факторов.
Здесь наши инструменты — это Grafana, Allure Report, ReportPortal и так далее. Эти штуки позволяют нам смотреть аналитику с автотестов быстро, четко, понятно. Заодно они помогут нам результаты разбирать.
Автоматизаторы боятся

И вот вроде всё хорошо, но при этом сохраняется несколько проблем. Автоматизаторы боятся пойти к разработчикам и спросить, хорошие ли их тесты. Потому что они написаны на каком-то DSL или птичьем языке и разработчики скажут: «Чуваки, мы не особо хотим в этом разбираться, наверное, нормальные тесты. Но в целом мы и так сами всё покрыли. Вы можете не париться. У нас наш код работает».
Они не умеют запускать тесты самостоятельно. Поэтому если кнопка есть, то хорошо. А если её нет, то чтобы автоматизатору прогнать новый тест-сьют на launch-е на нашей инфраструктуре, ему надо пойти к Ops-ам, попросить эту инфраструктуру и выделить серверное время. Там ему скажут: «У нас сейчас большой релиз, мы не знаем, когда его можно выделить». Это всё очень дискомфортно, потому что автотестирование находится в своём «колодце экспертизы».

Также им очень сложно работать с ожиданиями. Когда приходят менеджеры и спрашивают: «Как быстро у нас будут пролетать наши тесты?» А они отвечают: «Мы не знаем, потому что может быть нам вообще не дадут пайплайны. А может быть их быстро дадут, и мы не знаем, сколько дадут циклу времени».
А2-А3

Эти проблемы мы постараемся решить переходом между А2 и А3. Наша задача — сделать так, чтобы тестировщики могли спокойно запускать свои тесты и потихоньку начинали заниматься инфраструктурой.
То есть мы делаем кнопку доступной, простой и рабочей. Далее мы отдаем тестовую инфраструктуру. Под ней я имею в виду всякие эмуляторы-контейнеры, Selenium-кластеры и прочее. То есть не надо отдавать всю инфраструктуру, но то, что имеет отношение к тестам, отдайте тестировщикам. Пусть они разбираются, учатся этим управлять, и когда они к вам придут, они будут говорить не «Ой, там у вас в докерах где-то что-то надо сделать», а «Чуваки, в этом кластере давайте сделаем так-то»
Отвлекаюсь на замечательную историю. Я недавно написал прекрасную статью на Хабр про пять инструментов для автоматизаторов на удаленке. Там есть Docker и Jenkins. В какой-то момент прилетает коммент, который выглядит примерно так: «Я не понимаю, для кого написана эта статья, потому что я тестировщик. Почему я, сидя дома на удаленке, должен поднимать и разбираться в Докере и Дженкинсе. Там же девопсы должны сидеть, которые получают 900 тысяч в секунду. Это же их работа». На самом деле, это их работа. Но ребята в тестировании должны понимать, как она делается и что под капотом у этой работы.
Поэтому кроме этого нужно отдавать тестерам мелкие штуки — проапдейтить браузеры, например. Эти штуки позволят им освоиться в вашем пайплайне. Теоретически, на этом этапе очень многие останавливаются, и в этот момент все выглядит довольно хорошо. Вот у нас Selenium-кластеры, вот у нас автотесты, написанные на адекватном фреймворке — все выглядит хорошо. Но есть проблемы.
Помимо того, что придётся потратить время на то, чтобы ваши коллеги освоились с новыми технологиями. Это всё еще неидеально.
Что делать?

Мы вроде все подсобрали, участники процессов собрали все в кучку, но можно лучше. И TestOps — он про то, что можно сделать лучше.
А2-Т2

Поговорим про переход А2 или А3 в Т2. Если у вас сильная команда тестирования, то мы можем сразу прыгать на уровень T2, который подразумевает несколько вещей. Здесь мы будем говорить о том, что DevOps — он про общение и про то, что мы все в одной лодке. А когда мы все в одной лодке, мы должны друг друга понимать. Как только тесты будут непонятны разработчикам, у нас рассыпятся коммуникации. Как нам это исправить? Переходить на нативные инструменты.
Если мы тестируем Java, давайте писать тесты на Java. Если бэкенд на Go, давайте писать тесты на Go. Если мы тестируем фронт, то это, скорее всего, TypeScript или JavaScript. Давайте выбирать фреймворки для этих технологий.
Переход на нативные инструменты позволяет сделать второй очень важный шаг для качественного перехода. Это код-ревью с разработчиками. Представьте себе ситуацию, когда тестировщики пишут нативные E2E-тесты, они искренне верят, что эти тесты хорошие и у нас даже есть уверенность, что всё в порядке. Но если они начнут приходить к разработчикам и спрашивать, действительно ли тесты нормально проверяют код? Почему это круто и почему тестировщик не может сам понять, все ли в порядке? Потому что код команды разработки лучше всего знает команда разработки. Сколько ты его ни читай и ни копайся в нем, нюансы будут известны только тем, кто этот код написал. Особенно если этот код, например, реактивный. Там вообще фиг разберешься. Если это какие-то простые вещи, то там нет необходимости. Но мы же любим новые технологии, поэтому в какой-то момент все переедут на реактивную Java, и там будет всё весело. Поэтому тестировщик может всё тестами обложить, но насколько это всё будет работать под капотом, никому не будет понятно кроме самих разработчиков. Поэтому переходим на нативные инструменты и делаем код-ревью с разработчиками.
Что мы делаем дальше? А дальше мы отдаем тестировщикам контроль над тестовыми серверами. Это как бы шаг назад, но это можно сделать в рамках перехода А2-Т2, потому что теоретически Т1 — про то, чтобы тестировщики забрали себе всю инфраструктуру, которой владеют. И здесь имеется в виду, что тестировщики будут именно отвечать за состояние инфраструктуры тестовых серверов. Они могут сами зайти туда, обновить версии, обновить софт, поработать над содержимым баз данных или почистить их и так далее. Если что-то пойдет не так, то никто не побежит кричать «Нам все сломали ребята из инфраструктурной команды». Тестировщики сами все сломали — сами виноваты. Это хорошо, потому что, если что, они знают к кому из коллег можно пойти.
И все это нас приводит к золотому Бендеру. Здесь тестирование — это прекрасная автоматизация, которая становится прекрасной за счет двух вещей — тестирование становится прогнозируемым и используются нативные инструменты. Тестирование становится прогнозируемым, потому что ресурсами управляют тестировщики, и прекрасная «кнопочка» нажимается часто и разными людьми и, скорее всего, она тоже автоматизированная. То есть в момент, когда у вас отводится ветка, тесты прогоняются. Потом, когда она пытается смержиться обратно, все тесты тоже автоматически прогоняются. У нас появляется огромное количество результатов тестов и огромное количество артефактов от команды тестирования, которых в начале нашего пути не было. То есть в мире DevOps, который следует пайплайну и постоянно бежит-бежит-бежит. Сейчас у нас эти вещи автоматически появляются естественным образом.
Сейчас я это рассказываю и, наверное, из аудитории кто-нибудь должен крикнуть: «Вы тут такие умные, а что тогда все давно так не сделали?» Конечно, под капотом всего того, что я рассказываю, лежит очень много деталей. Это и инструменты, которые надо будет выбрать, и то, как их внедрить, и то, как с ними работать. Таких нюансов будет очень много, но сейчас я рассказываю верхнеуровнево, потому что хочется зажечь вас желанием разбираться с тем, как помочь тестировщикам. И чтобы это сделать, в выводах я собрал набор конкретных шагов.
Выводы
Первое, что нужно сделать, — сходить в ваше тестирование и посмотреть, как у них там всё происходит. Что у них с менеджментом, кто руководитель, действительно ли он прогрессивный человек, который любит современные подходы и топит за то, чтобы вы все работали вместе? Или там сидят ребята, которые говорят: «У нас все тесты написаны, наши ручники их отлично гоняют, наши релизы безглючные, и что вы от нас хотите? Сидите гоняйте свои релизы каждые два дня, а мы на новую функциональность будем вовремя раз в неделю на мажорные релизы всё прогонять». Выясните, какой тип менеджера у вас. Понятно, что-то это некий градиент, вряд ли вы найдете конкретно такую версию.
Посмотрите, как живут ваши автоматизаторы. Счастливы ли они, какие тесты они пишут — нативные или нет? Это тесты, которые выглядят максимально как реализованный в коде ручной сценарий с пятью-тридцатью шагами или это всё-таки маленькие атомарные клевые тесты, которые часто запускаются? Вот эти все вопросы, которые я проговаривал ранее, можно смапить на этот списочек и спокойно всё продиагностировать.
Посмотрите, что делается с результатами тестов. Мы для этого разрабатываем Allure Report, и зачастую он используется не тестировщиками, а разработчиками. Они часто затаскивают его в команды и компании, потому что у них очень много тестов, репорты постоянно разваливаются, а в код вносятся постоянные изменения.
Так давайте сделаем так, чтобы тестировщики тоже нормально составляли репорты и всем их показывали. Очень часто внутри тестирования есть набор метрик, которые нужны тестированию, чтобы показать что оно классно работает. Но при этом эти метрики мало кто смотрит снаружи.
Поэтому создайте какие-то отчёты, которые будут доступны всем. Allure Report доступен на гитхабе бесплатно. А еще можно законтрибьютить: там уже написано много нативных интеграций для популярных фреймворков. Но если вдруг у вас какая-то самописная адовая штука, можете тоже написать свой плагин и закинуть к нам.
Когда вы понимаете, что по кусочкам всё вроде нормально, вы сможете определить, на каком этапе тестирование находится в вашем пайплайне — на М1, М3, А2 или вы почти в области Т2. У вас может быть всё хорошо, а может быть снаружи хорошо, а на самом деле не очень. Потому что где-то есть какие-то заковырки.
Если вы эту картину составите, то будете знать, какую часть работы автоматизировать. Может быть, действительно не надо покрывать автотестами всю функциональность, а достаточно автоматизировать ручную работу, потому что так будет удобнее, проще и быстрее. Главное — автоматизируйте, это один из главных принципов DevOps.
И второй принцип — общайтесь! Общайтесь с тестировщиками, общайтесь с разработчиками, если вы не разработчик. Сделайте так, чтобы все три части нашего треугольника активно взаимодействовали. Делитесь ответственностью, экспертизой и инструментами, которые вы используете.

Всем TestOps! Если вы будете все это делать, скорее всего, сможете построить все процессы так, что жить станет лучше.
Уже скоро мы проведём бесплатный онлайн-фестиваль TechTrain. И на нём Руслан представит своего рода продолжение к этому посту — доклад «Quality Gates: I need your clothes, boots, and motorcycle».
А за этим последует наш конференционный сезон, где пройдут и конференция DevOops по девопсу, и Heisenbug по тестированию. И на второй без Руслана тоже не обойдётся — смотрите там его доклад «TestOps 101: Part 2».
Так что, если для вас актуальны подобные темы — советуем обратить внимание и на TechTrain, и на весь наш конференционный сезон.
