Comments 21
Но... ChatGPT не умеет в реальном времени обучатся на том, что ему отвечают пользователи, потому что так работают веса модели. То, как он второй раз тебе ответил - чистая случайность. Да там никто и не скрывает, что нейросеть ограничена знаниями по дате, за которую был собран датасет для обучения.
Она ответила иначе: что будет использовать полученную информацию в ответах для других пользователей.
Она просто настроена на вежливое общение, она чисто физически не умеет ничего запоминать за пределами одной сессии.
Шутка-минутка, объясняющая суть

Спасибо. Получается ChatGPT дала неверный ответ?
ChatGPT не имеет инструментов воздействия на саму себя, не может себя менять никаким образом. Этим занимаютсся инженеры OpenAI по собственному желанию. Она только выдает ответы, а о самой себе она может отвечать в рамках доступных ей сведений, которые были даны ей. Остальное она может додумывать. Лингвистические ИИ на данный момент тем и характерны, что они додумывают то, чего не знают или в чём не уверены. Во мило пообщались, но если вы не пометили ответы ИИ "палец вверх" или "палец вниз", вы никак не повлияли на улучшение этого ИИ в будущем и ваше общение с большой долей вероятности никак не будет обработано. Потому что таких как вы - десятки миллионов, и физически некому обрабатывать такие обьемы диалогов. Сам ИИ можно было бы натренировать обрабатывать свои же диалоги и как-то их оценивать (выуживать из них места, где люди его учат чему-то новому, или исправляют его ошибки и он сам это признаёт), и это можно было бы реализовать, но это огромные вычислительные и финансовые ресурсы. Поэтому на данном этапе улучшение ИИ лежит на самих людях.
Остальное она может додумывать. Лингвистические ИИ на данный момент тем и характерны, что они додумывают то, чего не знают или в чём не уверены.Все же додумывание нужно брать в кавычки, что бы не вводить читателей в заблуждение. Ответы это всего лишь аппроксимации очень сложной функции (авторегрессии) полученной на этапе обучения, которая частично может модифицироваться благодаря контекстному обучению в сессии. У человека это уровень автоматического получения результата на ассоциативном уровне мышления. За день таких мыслей у человека возникает немало, но включив ту самую думалку, уровень рационального мышления, затратного энергетически, который работает по некоторым правилам, и проанализировав такой результат часто отклоняем его, как неверный. Этого чаты на базе GPT-3 пока делать не могут, как их не обучай, и сколько параметров модели не увеличивай. Ответы будут улучшаться, но от неверных и бессмысленных избавиться не удастся. Тут требуются дополнительные технологические решения, приближающие к уровню рационального мышления человека — наличие внутренних критиков, конкурирующие предположения, систем оценок, представления интересов, мотиваций, и тп. Если точнее, то это приближение к уровню Системы 2 в дуальной теории процессов мышления. А далее нужно кооптировать уровень образного мышления, для этого ИИ должен работать не только с языком, но и другими типами информации — изображениями, звуками, и тд, и вырабатывать при обучении ассоциативную модель связей между всеми этими типами информации. И это все равно не будет уровень человека, с его думалкой, воображалкой, интуичелкой, и тд, т.к. у него еще гигантские знания в неявной форме заложенные эволюционно, и передающиеся генетически, эпигенитически, и некоторыми неявными формами обучения начинающимися еще на эмбриональном уровне. Хотя можно не повторять возможности человека, но что получится в результате таких разработок, будем ли мы понимать такой ИИ, это отдельный вопрос.
Я заметил, что есть темы, которые GPT знает очень хорошо, и там он дает довольно точные ответы, а есть такие где он выдумывает. Причём в тех темах, в которых он более осведомлён, если задавать вопросы, ставящие ИИ в тупик, он перестаёт выдумывать и уверенно отвечает, что либо не знает, либо просит дополнительный контекст. Вы еще забыли, что GPT построена на "трансформере" с его механизмом "внимания", для оптимизации вычислений. И мое мнение состоит в том, что из-за того, что модель не имеет полносвязности, при обучении происходит "накладка" семантики понятий в тексте друг на друга. Например из-за того, что некая важная часть в тексте имеет больший смысловой "вес", который перетягивет "внимание" сети на себя. И GPT теряет из "виду" менее "заметные" части, которые в некоторых комбинациях могут давать иной контекст. Если бы сеть была полносвязной, все эти мелкие взаимосвязи были бы учтены, а с механизмом внимания GPT акцентируется на самых "явных" и максимально частотных "комбинациях". Отсюда ИМХО и торчат уши "галлюцинаций" и выдумываний фактов. Просто происходит "сшибка" или накладка в механизме группировки по семантике, когда понятия из разных контекстов, достаточно близкие для GPT ошибочно группируются вместе, просто потому что механизм внимания так подсказал.
По этому считаю, что проблемы GPT не в том, что она не подражает мыслительным механизмам человека, а в том, что в GPT реализуются наименее вычислительно затратные, но и более "грубые" принципы работы. А текущие подходы считаю вполне жизнеспособными для достижения сверхчеловеческого интеллекта, без переусложнения. Ведь ИМХО связи в нашем мозге тоже не полносвязные, поэтому нужны дополнительные механизмы для повышения его работоспособности, которые будут атавизмом для цифровых ИИ, просто из-за более простого строения, не ограниченного биологическими ограничениями мозга человека.
В конечном итоге развитие ИИ на данном этапе стопорится сложностью полного обучения (время) и стоимостью работы оборудования (деньги). Когда две эти проблемы будут решены, вы получите тот ИИ, который хотели.
По этому считаю, что проблемы GPT не в том, что она не подражает мыслительным механизмам человека, а в том, что в GPT реализуются наименее вычислительно затратные, но и более «грубые» принципы работы…Оба фактора влияют на корректность ответов чата. Но второй никогда не компенсирует первый. Тут дело не только в оптимизации структуры и функций, которую мозг прошел в результате эволюционного развития, но и чисто физические ограничения по энергоэффективности (1, 2) и технологическим решениям (1, 2). В перспективе обычные компы с графическими платами и их кластерами заменят нейроморфные технологии над которыми сейчас работают все основные производители микроэлектроники. Они ближе к биологическим прототипам, и в значительной степени лишены этих недостатков.
В конечном итоге развитие ИИ на данном этапе стопорится сложностью полного обучения (время) и стоимостью работы оборудования (деньги). Когда две эти проблемы будут решены, вы получите тот ИИ, который хотели.
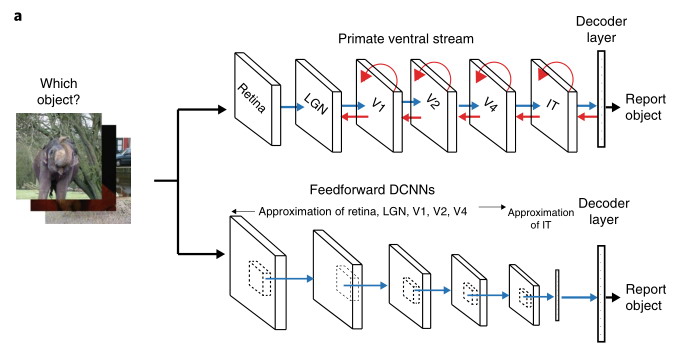
А текущие подходы считаю вполне жизнеспособными для достижения сверхчеловеческого интеллекта, без переусложнения.Это линейная логика развития, как показывает практика она работает в ограниченных временных масштабах. Разработчики ИИ, среди которых есть такие видные, как ЛеКун, говорят об особом пути развития ИИ. Но если заглянуть в его работы, то они изобилуют ссылками на нейрофизиологические исследования, и сравнения результатов решений с ними. Достаточно посмотреть на сверточные сети над которыми он работал, они имеют прототип в вентральном пути зрительной системы приматов. Это и понятно, если решения сильно отклоняются от биологических прототипов, то непонятно как использовать и интерпретировать результаты их работы, они же должны быть понятны для человека. Поэтому отбор решений идет во вполне определенном биологически инспирированном направлении. Единственно, что архитектура компов накладывает ограничения на реализацию некоторых решений, например, обучения, и приводит к использованию метода обратного распространения ошибки, которое не имеет полного аналога в нейробиологии. Как результат он имеет серьезные недостатки в виде невозможности непрерывного обучения нейросетей из-за проблемы катастрофического забывания. Нейроморфные решения лишены этого недостатка, т.к. моделируют нейропластичность биологических сетей, и используют ассоциативные (хеббианские) методы обучения.
{kind=link}
{kind=link}
Я заметил, что есть темы, которые GPT знает очень хорошо, и там он дает довольно точные ответы, а есть такие где он выдумывает. Причём в тех темах, в которых он более осведомлён, если задавать вопросы, ставящие ИИ в тупик, он перестаёт выдумывать и уверенно отвечает, что либо не знает, либо просит дополнительный контекст.Давайте посмотрим откуда это берется, и какие аналоги имеются в мышлении человека. Чат основан на самой большой модели GPT-3, см. описание, которая имеет ограничение контекстного окна в 2000 токенов, это же ограничение действовало при обучении модели. Дообучение в сессиях состоит в использовании метода обучения Few-Shot по нескольким примерам. Там приведен замечательный график как дообучение влияет на точность ответов модели. Как видно приблизительно после 10 подсказок эффективность перестает расти, и модель фактически работает в режиме обучающей выборки. В сумме вместе с ответами чата они не должны превышать ~2000 символов (есть нюансы перевода символов в токены). После этого модель может утратить контекст и начать фантазировать. Никакого тупика в логике нет, есть исчерпание заложенного ресурса. Далее ответы становятся более случайными, из-за этой потери контекста, и в зависимости от используемого метода и параметров сэмплирования (см. здесь описание и примеры кода). Дополнительно обучение модели из-за ограничения объема входного окна также приводит к ухудшению предсказания ответов. Ответы в стиле «не знаю» не означают, что чат провел рациональный анализ запроса подобно человеку, который использует для этого все ресурсы мышления, и обоснованно выдает достаточно стабильный ответ. У чата это вероятностный процесс, может продолжать фантазировать и дальше.
Теперь как это происходит в диалоге у человека. Известно, что объем рабочей памяти человека ограничен. Несколько упрощая, если диалог достаточно длительный, то человек, естественно, не помнит его дословного содержания, в отличии от чата, а сжимает информацию, помня об основных его моментах — контексте диалога. Этого достаточно для поддержания темы разговора. Однако при очень длительных диалогах его суть часто может теряться, происходит банальное переполнение рабочей памяти, и контекст начинает теряться. Точно также может появляется различная фигня не относящаяся к исходной теме диалога, особенно склочного характера, когда начинают играть роль также эмоции. Другой вариант, контекст устанавливается заранее одним из собеседников, или обоими. Например, человек специалист в определенной области, получает задание на работу от руководителя, и тот объясняет в каких условиях и объеме его умения должны быть использованы, и только затем предметно обсуждаются детали. В этом случае диалог может продолжаться плодотворно достаточно долго. Это напоминает работу с чатом, где желательно исходно установить правильный контекст с минимальным заполнением контекстного окна, а затем уже переходить к деталям запроса. Но в этом случае избежать переполнения не удастся, чат не обладает способностью сжимать содержимое беседы, поддерживать и обновлять контекст в минимальном объеме, отдаляя момент переполнения окна. Поэтому контекст необходимо восстанавливать в новой сессии, для продолжения диалога. И наконец, вариант с вопросом о бугелях) который сразу же может привести человека к фантазиям, без всякого переполнения рабочей памяти так же, как и чат. Таких примеров в коментах здесь приводилось не мало.
И мое мнение состоит в том, что из-за того, что модель не имеет полносвязности, при обучении происходит «накладка» семантики понятий в тексте друг на друга.Имеется в виду, что все нейроны в сети связаны, и слоев нет? Сама архитектура трансформера на уровне слоев полносвязная, чем и гордятся ее разработчики. Без слоев (в нейрофизиологии карт) не обойтись, похоже это фундаментальная особенность биологических нейронных сетей, выработанная эволюционно.
Она дает наиболее подходящие под обучающую выборку.
Вот мы недавно спрашивали, чем лошадь от носорога отличается. Сеть пришла к выводу, что бронированной кожей. Походу выдала кучу перлов, типа что лошадь меньшей высоты(неправда) или что питаются они разными вещами. Но при вопросе чем именно — выдала одинаковый набор. Абсолютно, даже порядок одинаковый.
И, кстати, нам не удалось убедить ее, что носорог — horse-like. Хотя ее аргументы против были вообещ никакими. Вида «оно отличается, вот насорог имеет ноги, а лошеподобное — ноги».
Менять свою выборку текущая версия НЕ УМЕЕТ.
Пообщавшись с chatgpt достаточно часто можно получить либо неверный ответ, либо неточный. к примеру все (я думаю многие) же знают что такое "веретено деления", чему учат ещё в школе. Спросите ChatGPT "что такое веретено деления".
нейросети не обладают свойством интроспекции, также как и чувстами, но вполне их эмулируют.
Эта зараза мне стала объяснять содержание статьи Хинтона конца 2022 года утверждая, что знакома с ней, а так же, что статья выпущена в 2021, получив от меня только название и автора. Когда я сказал, что статья на самом деле выпущена в 2022 году и не могла быть в тренировочном датасете, она (зараза эта) извинилась за конфуз и больше на тему статьи галлюцинировать отказалась.
Из диалога мы узнали, что ChatGPT доверяет информации, полученной от 8-летнего мальчика и будет использовать эту информацию в других диалогах.
1. Нет никаких оснований предполагать, что информация о деталях того, как ChatGPT используется, как построен его многопользовательский режим, и как используются реплики пользователей, присутствовала в исходном датасете.
2. Известно, что ChatGPT склонен очень правдоподобно фантазировать на темы, о которых у него нет данных.
Вывод: я бы вообще не доверял тому, что говорит ChatGPT о том как он будет использовать реплики пользователей для самообучения.
Это у вас 8-летний ребенок сам так написал, «потому что длина волны - это характеристика волны»? Крутой!
ChatGPT нередко придумывает информацию. По малоизвестным вопросам - больше. Я как-то собирал информацию по африканским диктаторам, попробовал ChatGPT - он начал выдавать выдумки, просто смешивая информацию по разным странам. Наверное так и должна вести себя языковая вероятностная модель, но при работе с ним это нужно учитывать и проверять информацию.
По программированию лучше, но тоже бывает. ChatGPT может придумывать несуществующие функции и методы классов - но такие, которые вполне могли бы существовать и были бы вполне уместны, но - вот так сложилось - не реализованы. Таким образом, выдача выглядит весьма правдоподобно.
Ещё можно спросить ее про украинских президентов. Там вообще параллельная реальность. Христофора Порошенко знаете, который брат Петра Порошенко? Да, он сразу после Петра стал президентом, еще в 2014 году. Даже биографию и достижения выдаст. И при этом chatGPT очень упорствует в своих выкладках. Никаких Януковичей, что вы! Так что не удивлюсь, если африканских диктаторов там вообще рандомайзер генерил ;)
А что все друг начали так доверять ИИ? Только потому, что он начал более связно говорить? Никакому интеллекту безоговорочно доверять не стоит, ни живому, ни искусственному. Собственно интеллектом что-то и становится благодаря ошибкам и умению на них учиться.
Я пытался с её помощью дописать песню, но на русском она стихи плохо пишет. Зато на английском сочинила и аккорды подобрала, получилось весьма неплохо, на мой взгляд: https://youtu.be/u2VyA7qW0nA
Насколько точную информацию выдает ChatGPT?