
Многие из нас постоянно думают о производительности веб-приложений: добиваются 60 FPS на медленных телефонах, загружают свои ассеты в идеальном порядке, кэшируют всё что можно, и много чего ещё.
Но не является ли такое представление о производительности веб-приложений слишком ограниченным? С позиции пользователя все эти действия — лишь крошечный кусок большого пирога производительности.
В этой статье мы пройдёмся по всем этапам использования сайта, как если бы это делал обычный человек, измерив длительность каждого из них. И особое внимание уделим конкретному шагу на одном конкретном сайте, который может быть ещё больше оптимизирован. Хочется верить, что решение (которым будет машинное обучение) может быть использовано во многих различных случаях на разных сайтах.
Проблема
В качестве примера возьмём сайт, на котором одни пользователи могут продавать лишние для них вещи, чтобы другие могли купить себе новое сокровище.
Когда пользователь регистрирует новый товар для продажи, он выбирает категорию, затем требуемый рекламный пакет, заполняет подробности, просматривает объявление, а затем его публикует.
Смущает первый шаг — выбор категории.
Во-первых, есть 674 категории, и пользователь может встать в тупик, в какую из них «засунуть», скажем, разбитый каяк (Стив Круг прекрасно сказал: не заставляйте меня думать).
Во-вторых, даже когда становится ясно, какой категории / подкатегории / подподкатегории принадлежит товар, процесс всё равно занимает около 12 секунд.
Если сказать, что можно сократить время загрузки страницы на 12 секунд, вы бы вполне ожидаемо удивились. Ну почему бы не сойти с ума настолько, чтобы сэкономить 12 секунд в другом месте, а?
Как сказал Юлий Цезарь: «12 секунд — это 12 секунд, чувак».
Первым делом приходит в голову, что если скормить заголовок, описание и цену товара правильно обученной модели машинного обучения, то она определит, к какой категории принадлежит товар.
Так что вместо того, чтобы тратить время на выбор категории, пользователь мог бы потратить 12 дополнительных секунд, глядя на двухъярусные самодельные кровати на reddit.
Машинное обучение — почему вы должны перестать его бояться
Что обычно делает разработчик, который абсолютно ничего не знает о машинном обучении, кроме того, что программы на нём могут играть в видеоигры и превзойти лучших в мире игроков в шахматы?
- Погуглить «Machine Learning».
- Покликать по ссылкам.
- Обнаружить Amazon Machine Learning.
- Понять, что не нужно ничего знать о машинном обучении.
- Расслабиться.
Процесс, как он есть
Он полностью описан в ML-документации Amazon. Если вы заинтересовались этой идеей, то запланируйте ~ 5 часов и прочитайте документацию, здесь мы не будем её рассматривать.
После прочтения документации можно сформулировать такой план:
- Запишите данные в CSV-файл. Каждая строка должна быть элементом (например, каяком), столбцы должны быть заголовками, описаниями, ценами и категориями.
- Загрузите в AWS S3.
- «Обучите» машину на этих данных (всё делается с помощью визуального мастера со встроенной помощью). Маленький облачный робот должен знать, как предсказать категорию на основе названия, описания и цены.
- Добавьте код к приведённому ниже фронтенду, который берёт заголовок / описание / цену, введённые пользователем, отправляет их в конечную точку предсказания (она автомагически создаётся Amazon) и показывает прогнозируемую категорию на экране.
Пример сайта
Можете воспользоваться прекрасной формой, которая имитирует ключевые аспекты этого процесса.
Эти захватывающие результаты не позволят вам потерять интерес во время предстоящих скучных объяснений. Просто поверьте, что предлагаемая категория действительно была предсказана на основе машинного обучения.
Давайте попробуем продать холодильник:

Как насчёт аквариума:

Маленький облачный робот знает, что такое аквариум!
Очень здорово, правда?
(Форма создана с помощью React/Redux, jQuery, MobX, RxJS, Bluebird, Bootstrap, Sass, Compass, NodeJS, Express и Lodash. И WebPack для сборки. Готовая вещь чуть больше 1 MB — #perfwin).
Хорошо, а теперь о менее впечатляющих вещах.
Поскольку вначале было просто баловство, то теперь нужно получить откуда-то реальные данные. Например, 10 000 предметов в нескольких десятках категорий. Был взят локальный торговый сайт, и написан небольшой парсер, который сохранял URL-адреса и DOM в CSV. Это заняло около четырёх часов: половина времени, затраченного на весь эксперимент с машинным обучением.
Готовый CSV был загружен на S3 и проведён через мастер, чтобы настроить и обучить программу. Общее время CPU для обучения составило 3 минуты.
Интерфейс работает в реальном времени, поэтому можно проверить, действительно ли он вернёт мне то, что нужно, если передать ему определённые параметры,.
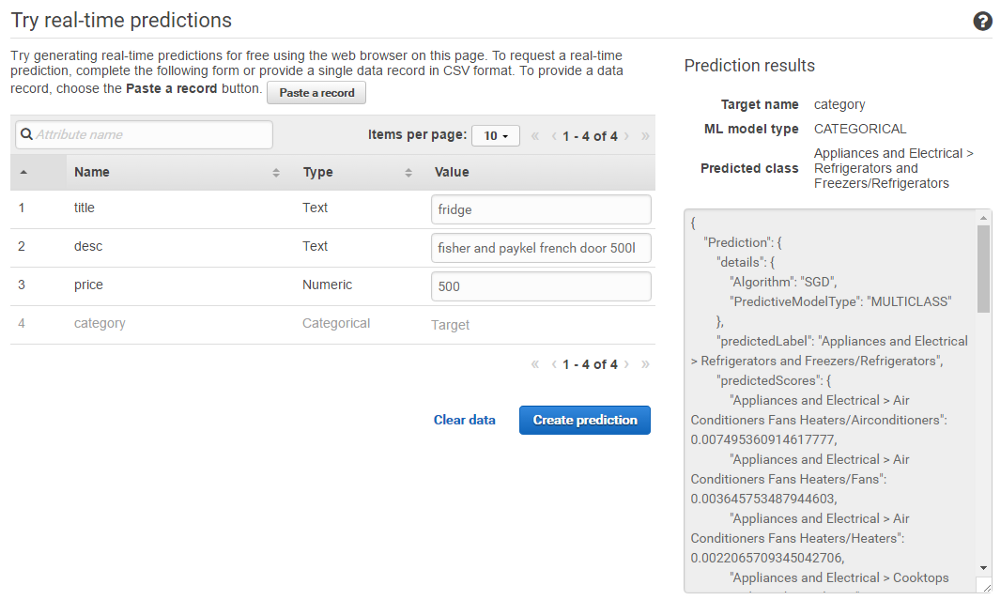
ОК, работает.
А теперь не хочется дёргать API Amazon напрямую из браузера, чтобы он не был общедоступным. Поэтому удалим его с Node-сервера.
Бэкенд-код
Общий подход довольно прост. Передаём API идентификатор и данные, а он присылает прогноз.
const AWS = require('aws-sdk');
const machineLearning = new AWS.MachineLearning();
const params = {
MLModelId: 'some-model-id',
PredictEndpoint: 'some-endpoint',
Record: {},
};
machineLearning.predict(params, (err, prediction) => {
// у нас есть предсказание!
});record, извините, имеется в виду Record, является объектом JSON, где свойства — это то, на чём обучена модель (название, описание и цена).Чтобы не оставлять в статье незаконченный код, вот весь файл server.js, который предоставляет конечную точку
/predict:const express = require('express');
const bodyParser = require('body-parser');
const AWS = require('aws-sdk');
const app = express();
app.use(express.static('public'));
app.use(bodyParser.json());
AWS.config.loadFromPath('./private/aws-credentials.json');
const machineLearning = new AWS.MachineLearning();
app.post('/predict', (req, res) => {
const params = {
MLModelId: 'my-model-id',
PredictEndpoint: 'https://realtime.machinelearning.us-east-1.amazonaws.com',
Record: req.body,
};
machineLearning.predict(params, (err, data) => {
if (err) {
console.log(err);
} else {
res.json({ category: data.Prediction.predictedLabel });
}
});
});
app.listen(8080);И содержимое aws-credentials.json:
const express = require('express');
const bodyParser = require('body-parser');
const AWS = require('aws-sdk');
const app = express();
app.use(express.static('public'));
app.use(bodyParser.json());
AWS.config.loadFromPath('./private/aws-credentials.json');
const machineLearning = new AWS.MachineLearning();
app.post('/predict', (req, res) => {
const params = {
MLModelId: 'my-model-id',
PredictEndpoint: 'https://realtime.machinelearning.us-east-1.amazonaws.com',
Record: req.body,
};
machineLearning.predict(params, (err, data) => {
if (err) {
console.log(err);
} else {
res.json({ category: data.Prediction.predictedLabel });
}
});
});
app.listen(8080);(Очевидно, что каталог
/private находится в .gitignore, поэтому не будет проверяться.)Прекрасно, c бэкендом закончили.
Фронтенд-код
Код, отвечающий за форму, довольно прост. Он делает следующее:
- Прослушивает события
blurв соответствующих полях. - Получает значения из элементов формы.
- Оправляет их POST-запросом в конечную точку
/predict, созданную в приведённом выше коде. - Помещает полученное предсказание в поле категории и показывает весь раздел.
(function() {
const titleEl = document.getElementById('title-input');
const descriptionEl = document.getElementById('desc-input');
const priceEl = document.getElementById('price-input');
const catSuggestionsEl = document.getElementById('cat-suggestions');
const catSuggestionEl = document.getElementById('suggested-category');
function predictCategory() {
const fetchOptions = {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
title: titleEl.value,
description: descriptionEl.value,
price: priceEl.value,
})
};
fetch('/predict', fetchOptions)
.then(response => response.json())
.then(prediction => {
catSuggestionEl.textContent = prediction.category;
catSuggestionsEl.style.display = 'block';
});
}
document.querySelectorAll('.user-input').forEach(el => {
el.addEventListener('blur', predictCategory);
});
})();Вот и всё. Это 100% кода, требуемого для того, чтобы облачный робот использовал данные пользователя и предсказывал категорию, к которой относится элемент.
Замолчи и возьми мои деньги
Держите свои шляпы друзья, всё это волшебство не приходит бесплатно…
Модель, которую мы использовали для примера (обучалась на 10 000 строк / 4 столбцах), занимает 6,3 Мб. Поскольку у нас есть конечная точка, ожидающая получения запросов, то расход памяти можно считать на уровне 6,3 Мб. Стоимость составляет $0,0001 / час. Или около восьми баксов в год. За каждый прогноз также взимается плата в размере $0,0001. Так что не используйте предсказания понапрасну.
Конечно, не только Amazon, предлагает подобные услуги. У Google есть TensorFlow, но у них с первых же строк совершенно убойное руководство по началу работы. Microsoft также предлагает модель машинного обучения. Microsoft Azure Machine Learning значительно превосходит Amazon. Итерация намного быстрее, потому что вы можете добавлять / удалять столбцы, не загружая файлы повторно. Наше обучение, занимающее 11 минут на Amazon, занимает 23 секунды на Azure. И, между прочим, их «студийный» интерфейс — очень хорошо сделанное веб-приложение.
Что дальше?
Вышеприведённый пример, безусловно, надуман. И тут не выложен скриншот, где программа приняла тостер за лошадь. И всё равно это чертовски потрясающе. Обычный человек может попробовать машинное обучение и, возможно, сделать некоторые улучшения для пользователей.
Можно было бы перечислить все возможные проблемы, но будет куда интереснее, если вы сами их найдёте. Так что идите, пробуйте, и добивайтесь успеха.
