Помните, как на школьных уроках литературы иногда надо было развернуто ответить на вопрос о сюжетной линии героя или каком-то событии книги? Например, объяснить мотивацию и развитие Евгения Онегина. Чтобы ответить на этот вопрос на пятёрку, мало пролистать краткий пересказ романа — придётся прочитать его весь.
Примерно для этого в 2020 году предложили RAG (retrieval-augmented generation) методы. Есть и другая мотивация для RAG — после обучения LLM на большой базе данных возникает вопрос, что делать с обновлением этой самой базы. Дообучение — не беспроигрышный вариант, так как это не всегда удобно для гигантских объемов данных. В базовом подходе RAG база знаний нарезается на небольшие куски текста, chunks, в 100-1000 слов, которые в виде эмбеддингов хранятся, как правило, в векторной БД, пока не понадобятся. Запросы пользователя дополняются найденными чанками в качестве контекста и выглядят для модели как один большой запрос.
Так вот, большинство существующих RAG методов способны переварить только небольшое количество достаточно коротких и последовательных чанков. Это ограничивает возможность оперировать крупномасштабным контекстом. Возвращаясь к уроку литературы, если перед тем, как выдать ответ, прочитать несколько последовательных строф романа, этого явно будет недостаточно. Недавно вышедшая Стэнфордская статья RAPTOR: Recursive Abstractive Processing for Tree-organized Retrieval призвана решить эту проблему. Основная идея заключается в том, чтобы обобщать отдельные куски большого материала, затем обобщать обобщения и так дальше. В итоге получаем небольшое количество кусков, которые на самом деле содержат в себе информацию об всех изначальных чанках. Похожую идею, но в ровно два уровня, рассказывал Юрий Землянский на нашем вебинаре пару лет назад.
В RAPTOR это реализовано с помощью дерева. Сначала чанки текста объединяются в кластеры, затем происходит суммаризация каждого кластера. Результат суммаризации становится новым уровнем дерева и процесс повторяется рекурсивно, генерируя дерево снизу вверх, то есть от листьев к корням.
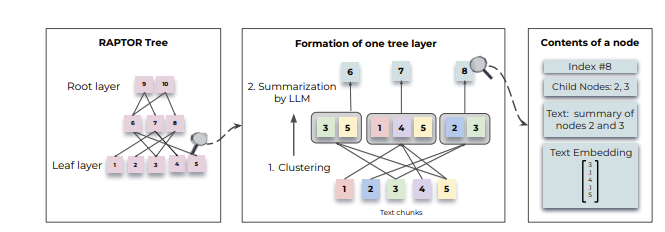
Сама идея появилась из того, что длинные тексты часто состоят из подтем и имеют некоторую иерархическую структуру. Авторам хотелось сохранить эту семантическую глубину и взаимосвязи частей. Рекурсивное дерево хорошо как раз тем, что сохраняет одновременно и глобальное понимание, и детализированность.
Подробнее об устройстве RAPTOR
Исходный корпус разбивается на последовательные куски текста длиной не более 100 токенов. При этом предложения не прерываются — если объем в 100 токенов превышен, то всё последнее предложение переносится в следующий чанк целиком. Это важно, чтобы сохранить согласованность контекста и семантики. Эмбеддинги строятся с помощью энкодера BERT. Так получаются листья будущего дерева.
Кластеризация первичных листьев и узлов следующих уровней идёт не жестким образом, то есть один узел может попасть сразу в несколько кластеров. Эта дополнительная гибкость нужна, чтобы учесть, что отдельный фрагмент текста может относиться сразу к нескольким темам. Алгоритм кластеризации основан на модели гауссовой смеси — предполагается, что точки принадлежат смеси конечного числа распределений Гаусса. Такое предположение не выглядит естественным для текста, но главное — работает. Правда, в случае с высокой размерностью эмбеддингов возникает проблема измерения близости. Для этого авторы использовали метод сокращения размерности Uniform Manifold Approximation and Projection (UMAP). Оптимальное число кластеров определяется по Байесовскому информационному критерию. Суммаризация проходит с помощью GPT-3.5-turbo с промптом “Write a summary of the following, including as many key details as possible: {context}: “
В результате крупный текст сжимается примерно в три раза

Чтобы вытащить из построенного дерева информацию, подходящую под запрос, в RAPTOR попробовали два пути — проход по дереву и сворачивание дерева. Первый выбирает несколько наиболее подходящих корневых узлов дерева. Затем к выборке добавляются их дочерние узлы и вновь выбираются наиболее подходящие из этого нового пула узлов. Процесс продолжается до тех пор, пока не дойдём до листьев. Второй путь проще — все узлы рассматриваются одновременно, без учета структуры дерева. Вместо того, чтобы идти по слоям, дерево сплющивается в один слой, из которого и выбираются подходящие узлы.
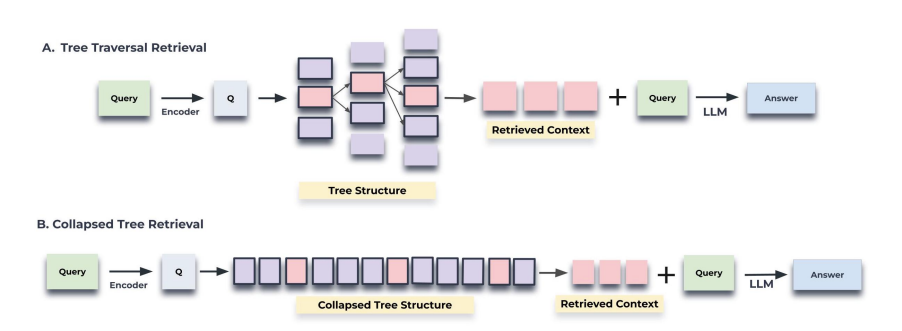
Как ни странно, второй способ даёт результат лучше (проверяли на 20 произведениях из датасета QASPER). Получается, что сама структура дерева не важна после того, как узлы уже получены. Авторы предполагают, что сворачивание дерева даёт больше гибкости — извлекается информация именно той степени детализации, которая нужна под данный запрос. Правда, приходится проводить поиск по гораздо большему числу узлов (впрочем, этот процесс можно оптимизировать).
RAPTOR проверили на нескольких датасетах: NarrativeQA (набор вопросов и ответов по полным текстам книг и сценариев фильмов), QASPER (вопросы по NLP статьям) и QuALITY (вопросы с выбором ответа по длинным отрывкам в 5000 токенов). Cам по себе RAPTOR обошёл BM25 и DRP, хотя и не слишком впечатляюще. А вместе с GPT-4 показал новый state-of-the-art
Больше наших обзоров AI‑статей на канале Pro AI.



