
Привет, дорогие читатели Хабра!
Автор статьи: Николай Задубровский (тг-@Nikolay347), выпускник OTUS.
Исследование выполнено под руководством @mashkka_t в рамках выпускного проекта на курсе Machine Learning в OTUS.
Хочу поделиться с вами своим опытом анализа данных и машинного обучения на примере интересной и полезной задачи — классификации грибов на съедобные и ядовитые. А именно, в данной статье я расскажу о том, как обучал различные модели машинного обучения отличать съедобные грибы от несъедобных, с какими сложностями столкнулся в процессе и какие интересные наблюдения про грибы и ML открыл по пути.
Итак, пройдемся по шагам от подготовки данных к машинному обучению до оценки разных моделей градиентного бустинга.
Для начала давайте познакомимся с данными, которые я использовал для решения задачи классификации грибов [Mushroom Classification].

Данные взяты с сайта [www.kaggle.com] и содержат информацию о 8124 грибах из 23 видах семейства Agaricus и Lepiota. Для каждого гриба есть 22 признака, которые описывают его внешний вид и запах, такие как форма и цвет шляпки, тип поверхности шляпки, цвет жабер, тип кольца и т.д. Все признаки являются категориальными и имеют разное количество категорий. Целевая переменная — это класс гриба: съедобный (e) или ядовитый (p). Данные сбалансированы по классам: есть почти одинаковое количество съедобных и ядовитых грибов.
Для анализа данных я использовал язык программирования Python и различные библиотеки для работы с данными, такие как pandas, numpy, seaborn, matplotlib и другие. Я также использовал библиотеку fastcluster, которая предоставляет более быстрые и оптимизированные алгоритмы для кластеризации данных. Библиотека fastcluster совместима с библиотекой scipy.
В этой части я хочу рассказать, как я подготовил данные к машинному обучению.
Загружаем данные из файла mushrooms.csv в датафрейм pandas
Вот что мы видим:
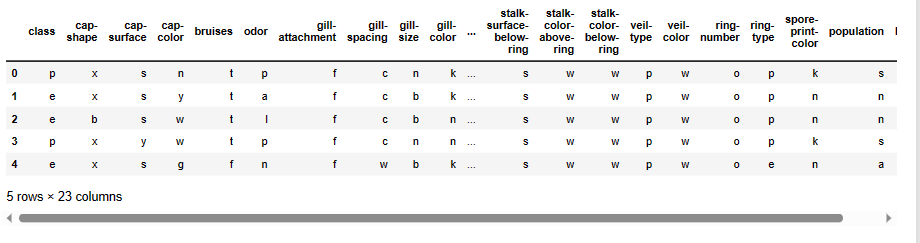
Как мы видим, данные представлены в виде букв, которые обозначают разные категории для каждого признака. Например, для признака cap-shape (форма шляпки) есть шесть возможных значений: bell (b), conical ©, convex (x), flat (f), knobbed (k) или sunken (s). Для признака odor (запах) есть девять возможных значений: almond (a), anise (l), creosote ©, fishy (y), foul (f), musty (m), none (n), pungent (p) или spicy (s). И так далее.
Посмотрим на информацию о данных: типы, размер, пропущенные значения
Просмотрим информацию:
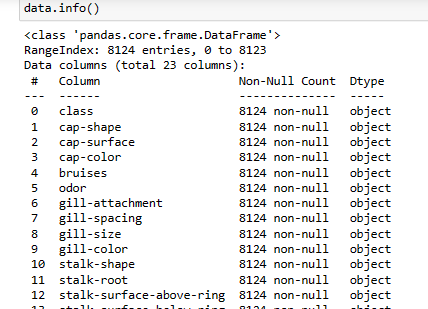
Вывод:
— Мы видим, что данные содержат 8124 строк и 23 столбца, каждый из которых соответствует одному признаку гриба.
— Все признаки имеют тип object, то есть они являются категориальными переменными, которые принимают различные символьные значения.
— В данных нет пропущенных значений, то есть все столбцы имеют 8124 непустых значений.
Для того, чтобы лучше понять данные, я построил таблицу сопряженности. Таблица сопряженности показывает частоту или долю комбинаций значений категориальных признаков в данных. Это помогает увидеть, какие категории чаще или реже встречаются вместе.
Посмотрим на распределение признаков по категориям: сколько уникальных значений есть в каждом признаке:

Вывод:
— Данные содержат 23 признака, каждый из которых имеет разное количество уникальных значений, то есть разные категории, в которые можно разделить данные по этому признаку.
— Самый маленький признак по количеству уникальных значений это veil-type, который имеет только одно значение: частичная вуаль (p). Этот признак не несет никакой информации о классе гриба, поэтому мы можем его удалить из данных (по поводу удаления посмотрим анализируем ещё признаки).
— Самый большой признак по количеству уникальных значений это gill-color, который имеет 12 разных значений: черный (k), коричневый (n), шоколадный (h), серый (g), зеленый (r), оранжевый (o), розовый (p), фиолетовый (u), красный (e), белый (w), желтый (y).
— Этот признак может быть важным для определения класса гриба, так как цвет жабер может указывать на наличие или отсутствие яда.
— Остальные признаки имеют от 2 до 9 уникальных значений, которые соответствуют различным характеристикам грибов, таким как форма, поверхность, запах, кольцо и т.д.
Моё предположение, что для построения модели градиентного бустинга мне нужно выбрать те признаки, которые наиболее сильно влияют на целевую переменную class, то есть на то, является ли гриб съедобным или ядовитым.
— Я могу использовать разные методы для отбора признаков, такие как анализ корреляций, важности признаков или статистические тесты. Но в общем случае, мне нужно искать те признаки, которые хорошо разделяют классы грибов и не сильно коррелируют друг с другом.
— Я могу предложить несколько признаков, которые, по моему мнению, могут быть хорошими кандидатами для построения модели градиентного бустинга.
Это:

— odor: запах гриба. Этот признак имеет 9 уникальных значений и сильно связан с классом гриба. Например, все грибы с миндальным или анисовым запахом являются съедобными, а все грибы с острым или противным запахом являются ядовитыми.
— gill-color: цвет жабер гриба. Этот признак имеет 12 уникальных значений и также сильно связан с классом гриба. Например, все грибы с зелеными жабрами являются ядовитыми, а все грибы с розовыми жабрами являются съедобными.
— spore-print-color: цвет спорового порошка гриба. Этот признак имеет 9 уникальных значений и также сильно связан с классом гриба. Например, все грибы с шоколадным или зеленым цветом спорового порошка являются ядовитыми, а все грибы с черным или коричневым цветом спорового порошка являются съедобными.
Для того, чтобы лучше понять данные, я построил таблицу сопряженности для трех категориальных признаков: class, gill-color и habitat. Таблица сопряженности показывает частоту или долю комбинаций значений категориальных признаков в данных. Это помогает увидеть, какие категории чаще или реже встречаются вместе.
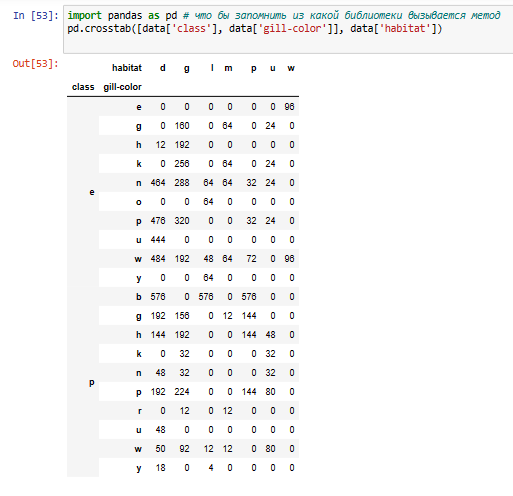
Таблица сопряженности показывает частоту или долю комбинаций значений категориальных признаков в данных.
— В таблице видно, как распределены классы и цвета жабер грибов по разным местообитаниям. Классы грибов обозначены буквами e (съедобный) и p (ядовитый), цвета жабер грибов обозначены буквами k (черный), n (коричневый), b (бежевый), h (шоколадный), g (серый), r (зеленый), o (оранжевый), p (розовый), u (фиолетовый), e (красный), w (белый) и y (желтый), а местообитания грибов обозначены буквами d (лес), g (трава), l (листья), m (луга), p (пастбища), u (город) и w (отходы).
— В таблице можно заметить некоторые закономерности и особенности в распределении данных. Например:
— Все грибы с зелеными жабрами (r) являются ядовитыми (p) и встречаются только в лугах (m).
— Все грибы с розовыми жабрами (p) являются съедобными (e) и встречаются в разных местообитаниях, но чаще всего в лесах (d).
— Все грибы с фиолетовыми жабрами (u) являются съедобными (e) и встречаются только в лесах (d).
— Все грибы с красными жабрами (e) являются ядовитыми (p) и встречаются только на отходах (w).
— Большинство грибов с белыми жабрами (w) являются ядовитыми (p) и встречаются в разных местообитаниях, но чаще всего на отходах (w).
— Большинство грибов с коричневыми жабрами (n) являются съедобными (e) и встречаются в разных местообитаниях, но чаще всего в лесах (d).
Эта информация помогает нам понять, какие признаки хорошо разделяют классы грибов и какие признаки имеют большее или меньшее разнообразие значений.
Я использовал библиотеку fastcluster совместно с тепловой картой, которая предоставляет более быстрые и оптимизированные алгоритмы для кластеризации данных. Кстати, библиотека fastcluster совместима с библиотекой scipy.
Тепловая карта с кластеризацией — это графическое представление данных, где индивидуальные значения в таблице отображаются при помощи цвета, а строки и столбцы организованы в виде деревьев по их схожести или расстоянию. Такой вид визуализации помогает найти закономерности, группы и аномалии в данных.
Тепловая карта показывает цветовое кодирование значений в матрице данных, а кластеризация показывает, какие строки и столбцы матрицы похожи друг на друга по своим значениям.
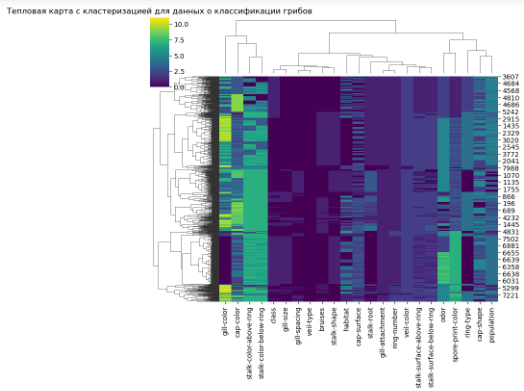
Вывод:
В этом графике можно увидеть, какие признаки или объекты имеют схожие или различные характеристики.
— Самый важный признак для классификации грибов на съедобные и ядовитые — это запах (odor). Это видно по тому, что он имеет наибольший контраст цветов на диагонали и наибольшее разделение на две группы по строкам и столбцам. Грибы с запахом аниса (a) или лимона (l) всегда съедобные, а грибы с запахом рыбы (y), гнили (m), перца (p), или фенола (c) всегда ядовитые.
— Другие признаки, которые также хорошо разделяют грибы на съедобные и ядовитые, это цвет пятен на шляпке (spore-print-color), цвет шляпки (cap-color), форма шляпки (cap-shape), и тип жабер (gill-size). Эти признаки имеют высокую корреляцию с признаком класса (class) и низкую корреляцию между собой.
— Некоторые признаки имеют мало влияния на классификацию грибов, такие как цвет жабер (gill-color), тип поверхности шляпки (cap-surface), или тип кольца (ring-type). Эти признаки имеют низкую корреляцию с признаком класса и высокую корреляцию между собой. Они также имеют мало контраста цветов на диагонали и мало разделения на группы по строкам и столбцам.
Строим гистограмму для целевой переменной (class):
Смотрим на распределение целевой переменной:

Из графика видим, что некоторые признаки имеют очень низкую вариативность или сильно коррелируют с целевой переменной
— Например, признаки veil-type (см.рисунок), veil-color, gill-attachment, bruises.
— Такие признаки можно удалить из данных, так как они не несут полезной информации для моделирования.
Удаляем ненужные признаки, которые имеют очень низкую вариативность или сильно коррелируют с целевой переменной.

Видим, что осталось 19 признаков.
Преобразуем категориальные признаки в числовые как 0 и 1 с помощью LabelEncoder.
Это нужно для того, чтобы модели могли работать с данными в виде матриц и векторов. Метод создаёт для каждой категории отдельный столбец с бинарными значениями 0 или 1, в зависимости от того, принадлежит ли объект к этой категории или нет.
Смотрим на первые пять строк данных после кодирования.

Видим, что теперь все признаки имеют тип int64 и имеют значения от 0 до n-1, где n — это количество категорий для каждого признака.
Удаляем дубликаты из данных, если они есть.
Нормализуем данные с помощью MinMaxScaler, чтобы все признаки имели значения в диапазоне от 0 до 1.
В этой части я хочу рассказать, как я построил и оценил разные модели градиентного бустинга, и как я оптимизировал параметры моделей с помощью современных библиотек.
Теперь нужно подготовить данные для моделирования, разделив их на признаки и целевую переменную.

А также на обучающую и тестовую выборки. Я использовал разумные параметры для разбиения данных, тем самым обеспечил воспроизводимость эксперимента.

Для построения и оценки моделей градиентного бустинга я использовал три популярные библиотеки: XGBoost, LightGBM и CatBoost. Градиентный бустинг — это ансамблевый метод машинного обучения, который строит несколько слабых моделей (обычно решающих деревьев) и комбинирует их в одну сильную модель с помощью аддитивного обучения. Каждая новая модель пытается исправить ошибки предыдущих моделей, используя градиентный спуск для минимизации функции потерь.
XGBoost — это расширение алгоритма градиентного бустинга, которое использует распределённое вычисление, оптимизацию деревьев и регуляризацию для повышения скорости и точности обучения.
LightGBM — это еще одно расширение алгоритма градиентного бустинга, которое использует метод градиентного одностороннего дерева (Gradient-based One-Side Sampling) для ускорения обучения и уменьшения потребления памяти.
CatBoost — это новая библиотека для градиентного бустинга, которая использует категориальные признаки напрямую, без необходимости их преобразования. Также она использует метод симметричного дерева (Symmetric Tree) для улучшения качества модели и предотвращения переобучения.
Для каждой из этих библиотек (XGBoost, LightGBM, CatBoost ) я сделал следующие шаги:
1. Обучил модель на обучающих данных с некоторыми параметрами, которые я выбрал на основе своего опыта и рекомендаций из документации.
Например, давайте посмотрим на библиотеку CatBoost для обучения классификатора на основе градиентного бустинга на деревьях решений.
CatBoost — это открытая библиотека, разработанная компанией Яндекс, которая предоставляет эффективный и гибкий способ реализации градиентного бустинга. Одной из особенностей CatBoost является то, что он умеет работать с категориальными признаками, используя перестановочный подход в отличие от классического алгоритма.
В коде я задаю некоторые параметры классификатора CatBoost:
n_estimators=48 означает, что я хочу построить 48 деревьев решений.
learning_rate=0.1 означает, что я хочу использовать средний шаг обучения, чтобы достичь оптимального баланса между скоростью и точностью.
max_depth=1 означает, что я хочу ограничить максимальную глубину каждого дерева одним уровнем, что делает модель более простой и устойчивой к переобучению.
l2_leaf_reg=1 означает, что я хочу использовать L2-регуляризацию для листьев деревьев, чтобы штрафовать за большие значения весов и предотвратить переобучение.
L2-регуляризация — это способ уменьшить сложность модели, чтобы она не переобучалась на обучающих данных. Переобучение — это когда модель слишком хорошо подстраивается под обучающие данные, но плохо работает на новых данных. L2-регуляризация добавляет штраф к функции потерь модели, который зависит от квадрата весов модели. Веса модели — это числа, которые определяют, как модель использует признаки для предсказания меток классов. Чем больше веса, тем больше влияние признака на предсказание. L2-регуляризация заставляет модель выбирать меньшие веса, чтобы уменьшить штраф и функцию потерь. Это делает модель более простой и устойчивой к шуму в данных.
Теоретическая справка:
Штраф — это дополнительный член в функции потерь, который увеличивает значение функции потерь, если модель слишком сложная или переобученная. Функция потерь — это мера того, насколько хорошо модель предсказывает правильные ответы на обучающих данных. Чем меньше значение функции потерь, тем лучше модель. Однако, если модель слишком хорошо подстраивается под обучающие данные, она может потерять способность обобщать на новых данных, то есть переобучиться. Чтобы избежать этого, мы добавляем штраф к функции потерь, который увеличивает ее значение, если модель слишком сложная. Сложность модели зависит от весов модели, которые определяют, как модель использует признаки для предсказания. Чем больше веса, тем больше влияние признака на предсказание. Штраф заставляет модель выбирать меньшие веса, чтобы уменьшить значение функции потерь и сложность модели. Это делает модель более простой и устойчивой к шуму в данных.
logging_level='Silent' означает, что я хочу отключить вывод информации о процессе обучения в консоль.

Затем вызывается метод fit для обучения вашего классификатора на обучающих данных X_train и y_train, которые содержат признаки и метки классов.
2. Предсказал метки классов для тестовых данных с помощью обученной модели.
Далее, я использую обученную модель CatBoost для предсказания меток классов для тестовых данных X_test, которые содержат признаки, но не метки. После чего, вызывается метод predict для классификатора clf_cb и сохраняю результат в переменную y_pred_cb, которая будет массивом из 0 и 1, соответствующих двум классам.

3. Предсказал вероятность принадлежности к классу ядовитых грибов для тестовых данных с помощью обученной модели.
Далее, я хочу использовать обученную модель CatBoost для предсказания вероятностей принадлежности к классу ядовитых грибов для тестовых данных X_test, которые содержат признаки, но не метки. Вызываем метод predict_proba для классификатора clf_cb и получаем двумерный массив, в котором каждая строка соответствует одному объекту, а каждый столбец соответствует одному классу. Вероятности в массиве показывают, насколько модель уверена, что объект принадлежит данному классу. Выбираем второй столбец массива с помощью индекса [:, 1], который соответствует классу ядовитых грибов и сохраняем результат в переменной y_prob_cb, которая будет одномерным массивом из чисел от 0 до 1, соответствующих вероятностям принадлежности к классу ядовитых грибов.

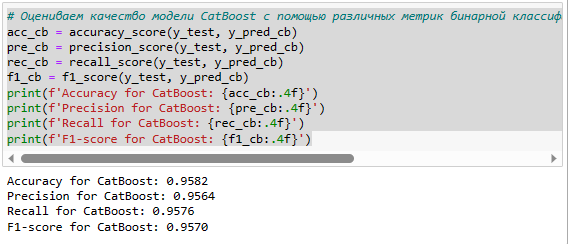
4. Оценил качество модели с помощью различных метрик бинарной классификации, таких как accuracy (точность), precision (точность), recall (полнота), f1-score (среднее гармоническое точности и полноты) и roc-auc (площадь под кривой ошибок).
Я оцениваю качество модели CatBoost с помощью различных метрик бинарной классификации. Бинарная классификация — это задача машинного обучения, в которой модель должна предсказать, к какому из двух классов принадлежит объект. В нашем случае, классы — это ядовитые и съедобные грибы. Метрики бинарной классификации — это числовые показатели, которые характеризуют, насколько хорошо модель предсказывает правильные классы для тестовых данных. Я использую четыре метрики: accuracy, precision, recall и f1_score.
Я постараюсь объяснить, что они значат и как интерпретировать их значения.
Accuracy (точность) — это доля правильных предсказаний модели от общего числа объектов, равное 0.9582 что означает, что она правильно предсказывает класс гриба в 95,82 % случаев.
Precision (точность) — это доля правильных предсказаний модели для положительного класса от общего числа предсказаний для этого класса, имеет равное 0.9564, что означает, что из всех грибов, которые модель предсказала как ядовитые, 95,64 % действительно являются ядовитыми.
Recall (полнота) — это доля правильных предсказаний модели для положительного класса от общего числа объектов этого класса. Чем выше recall, тем меньше пропусков модели, модель имеет recall равное 0.9576, что означает, что из всех ядовитых грибов в тестовых данных, модель правильно определила 95.76%.
F1-score (F-мера) — это среднее гармоническое между precision и recall. Это компромиссная метрика, которая учитывает и ложные срабатывания, и пропуски модели. Чем выше F1-score, тем лучше модель. Наша модель CatBoost имеет F1-score равное 0.9570, что означает, что она достигла хорошего баланса между точностью и полнотой.
В нашем случае модель CatBoost показала отличные результаты по всем метрикам бинарной классификации. Она имеет высокую точность, точность, полноту и F-меру, что говорит о том, что она хорошо предсказывает класс ядовитых грибов и редко делает ошибки.
5. Построил ROC-кривую и посчитал площадь под ней для модели CatBoost
Построил ROC-кривую для модели, которая показывает зависимость между долей верных положительных ответов (TPR) и долей ложных положительных ответов (FPR) при изменении порога классификации. Чем выше ROC-кривая и больше площадь под ней (AUC), тем лучше модель.

Теперь посмотрим на результаты по метрике AUC-ROC. Она имеет AUC-ROC равное 0.9999, что означает, что она почти идеально разделяет два класса ядовитых и съедобных грибов. Мы можем видеть это по графику ROC-кривой, который показывает, что кривая очень близка к левому верхнему углу. Это означает, что модель имеет очень высокую полноту и специфичность при любом пороге предсказания.
6. Визуализация влияния коэффициентов на целевую переменную для модели CatBoost
Далее, я хотел бы визуализировать влияние коэффициентов на целевую переменную для модели, которые показывают, какие признаки имеют большее или меньшее значение для предсказания класса гриба по его признакам.

Из таблицы видно, что самыми важными признаками для предсказания класса гриба оказались запах (odor), gill-size: размер жабер, широкие (b) или узкие (n), spore-print-color: цвет спорового порошка, черный (k), коричневый (n), шоколадный (h), зеленый (r), оранжевый (o), фиолетовый (u), белый (w), желтый (y) и gill-color: цвет жабер, черный (k), коричневый (n), шоколадный (h), серый (g), зеленый (r), оранжевый (o), розовый (p), фиолетовый (u), красный (e), белый (w), желтый (y). Эти признаки объясняют больше 80% вариации целевой переменной.
Это означает, что данные признаки очень сильно влияет на то, является ли он ядовитым или съедобным.
7. В этой части я хочу рассказать, как я сравнил результаты трёх моделей по разным метрикам качества и как я выбрал лучшую модель для задачи классификации грибов.
Применение других библиотек LightGBM и XGBoost являющимися библиотеками из ансамблевых методов машинного обучения аналогично показанной библиотеки CatBoost (см.выше).
Теперь давайте построим ROC — кривую для этих трех моделей:
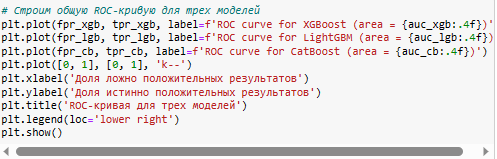

Из таблицы и графика мы можем видеть, что все три модели показывают очень высокое качество на данных о грибах. Однако модель CatBoost имеет небольшое преимущество перед другими моделями по всем метрикам.
Таким образом, я могу сделать вывод, что модель CatBoost лучше справляется с задачей классификации грибов на съедобные и ядовитые, чем модели XGBoost и LightGBM. Однако разница между ними не очень велика, и все они являются хорошими алгоритмами для решения такого рода задач.
8. Бонус
Для оптимизации параметров моделей я использовал библиотеку hyperopt, которая предоставляет инструменты для поиска оптимальных параметров с помощью алгоритма Tree-structured Parzen Estimator (TPE).

Это алгоритм, который использует подходы, чтобы найти наилучшие значения гиперпараметров для модели. Гиперпараметры — это параметры, которые не обучаются моделью, а задаются заранее. Они влияют на скорость и качество обучения модели. Обучаем модель CatBoost на обучающих данных с использованием hyperopt для подбора оптимальных параметров.
Определяем пространство поиска параметров.

Это означает, что я искал лучшую комбинацию из следующих параметров:
n_estimators — количество деревьев, которые будут построены при решении задачи классификации. Я выбрал три возможных значения: 100, 300 или 50.
learning_rate — скорость обучения, которая определяет величину шага градиента при оптимизации функции потерь. Я выбрал логарифмически равномерное распределение в диапазоне от 0.01 до 0.2.
max_depth — максимальная глубина деревьев, которые будут построены при решении задачи классификации. Я выбрал два значения: 3 и 8.
l2_leaf_reg — коэффициент регуляризации L2, который штрафует модель за слишком большие веса и помогает предотвратить переобучение. Я выбрал равномерное распределение в диапазоне от 1 до 10.
logging_level — уровень логирования, который определяет, какая информация будет выводиться на экран во время обучения модели. Я выбрал значение ‘Silent’, чтобы не видеть промежуточные результаты или статистику обучения.
Для того, чтобы найти лучший набор параметров, я использовал функцию fmin из библиотеки hyperopt, которая минимизирует заданную функцию потерь с помощью алгоритма Tree-structured Parzen Estimator (TPE).
Оцениваем качество модели CatBoost с помощью различных метрик бинарной классификации (accuracy, precision, recall, f1_score)

Как видим показатели модели улучшились:
— accuracy на 0,0368
— precision на 0,0436
— recall на 0,0321
— f1_score на 0,0378
Заключение: Дорогие читатели мы смогли улучшить показатели модели по сравнению с базовой моделью:

— добились значительного увеличения точности (accuracy) модели, которая показывает, как часто модель правильно предсказывает метки классов. Это означает, что модель более надёжна и эффективна, чем базовая модель;
— увеличили точность (precision) и полноту (recall) модели, которые показывают, как хорошо модель отличает разные классы. Это означает, что модель более способна избегать ложных срабатываний и ложных пропусков, чем базовая модель;
— повысили F1-меру (f1_score) модели, которая является средним гармоническим точности и полноты. Это означает, что модель более сбалансирована и учитывает оба аспекта качества классификации, чем базовая модель.
В общем и целом, hyperopt — это мощный и удобный инструмент для автоматического подбора оптимальных параметров для модели машинного обучения.
Спасибо за внимание!
