Comments 23
Спасибо за статью! Видимо, накипело )
А как быть, если нужно протестировать, например, конверсию какой-то специфической страницы категории, которую в принципе не посещает 100% аудитории сайта?
В Google Analytics можно создать сегмент, который включает только посетителей специфичной страницы или типа страницы, например, с помощью url-паттерна.
Да-да, спасибо. Я просто к тому, что в статье говорится «вся аудитория сайта», а не вся аудитория тестируемой страницы.
И это намеренно – если мы не можем измерить эффект в тесте на всю аудиторию сайта – мы не сможем понять как тестируемое изменение влияет на бизнес в целом.
У каждого А/Б теста есть так называемый opportunity cost – запуская один тест, мы жертвуем возможностью запустить другой. Всегда нужно стремиться выявлять результат в эскпериментах для бизнеса, иначе cost рискует превысить profit.
У каждого А/Б теста есть так называемый opportunity cost – запуская один тест, мы жертвуем возможностью запустить другой. Всегда нужно стремиться выявлять результат в эскпериментах для бизнеса, иначе cost рискует превысить profit.
Статья неплохая, но вот стало интересно:
«Однако, в рамках следующего этапа пост-тест анализа были исключены заказы call-центра, а также аннулированные заказы.»
Почему были исключены анулированные заказы? И к анулированным заказам, были ли отнесены возвраты? Т.к если были, то это очень страно.
Магазин выполняет свою задачу, когда продает товар. Если товар возвращается, то в большинстве случаев, это проблема товара, и бизнес процессов и людей, которые решили продавать не качественный товар.
Например, вы сделали акцию, на товар на складе, чтобы его распродать, товара много. Весь распродали, конверсия увеличилась, но товар оказался не качественный и его весь вернули. Это не значит, что это нужно не учитывать. Т.к возможно для этого были сделаны разные улучшения, чтобы продать (или продавать и дальше этот товар).
В общем основной вопрос — почему исключили анулированные и были ли это тоже возвраты?
А так за статью спасибо. Хоть и PR статья, коих огромное кол-во. Но изложено доступно.
«Однако, в рамках следующего этапа пост-тест анализа были исключены заказы call-центра, а также аннулированные заказы.»
Почему были исключены анулированные заказы? И к анулированным заказам, были ли отнесены возвраты? Т.к если были, то это очень страно.
Магазин выполняет свою задачу, когда продает товар. Если товар возвращается, то в большинстве случаев, это проблема товара, и бизнес процессов и людей, которые решили продавать не качественный товар.
Например, вы сделали акцию, на товар на складе, чтобы его распродать, товара много. Весь распродали, конверсия увеличилась, но товар оказался не качественный и его весь вернули. Это не значит, что это нужно не учитывать. Т.к возможно для этого были сделаны разные улучшения, чтобы продать (или продавать и дальше этот товар).
В общем основной вопрос — почему исключили анулированные и были ли это тоже возвраты?
А так за статью спасибо. Хоть и PR статья, коих огромное кол-во. Но изложено доступно.
У каждого бизнеса свои цели – у кого-то повысить рыночную стоимость компании, которая опирается на «размещенную выручку» (это устойчивый в ecommerce термин для стоимости товаров в оформленных заказах без учета исполняемости), а у кого-то – поднять операционную прибыль.
Как-то это не выглядит как ответ, я намекал на то, что вы таким решением «искусствено» изменили конверсию, чтобы она вам подходила. В статье не написано, почему так было сделано, и получается, что люди, которые не понимают «зачем» тупо начнут так делать и получать не верные результаты.
Я это говорю не просто так, т.к у нас интернет магазин, который входит в ТОП-100 в штатах по выручке. И наши задачи работают в обоих направлениях, просто мы не делаем такого разграничения как «срежем ка мы возвраты, т.к тогда цифра красивей». Тест должен идти достаточно времени, чтобы убрать эти выбросы.
Также, каждый день идут промо-акции, рассылки, которые приводят на сайт разные группы людей, на разные группы товаров, что усложняет однозначно и быстро дать ответ, что стало лучше или хуже.
Еще выглядит странным, что вы говорите о 10-20 A/B тестов, но не говорите о Multivariate A/B тестах. Т.к если идет паралельно не один тест а несколько, нужно учитывать все вариации A/B тестов, чтобы видеть, какая связка в совокупности дает наилучший результат.
Я это говорю не просто так, т.к у нас интернет магазин, который входит в ТОП-100 в штатах по выручке. И наши задачи работают в обоих направлениях, просто мы не делаем такого разграничения как «срежем ка мы возвраты, т.к тогда цифра красивей». Тест должен идти достаточно времени, чтобы убрать эти выбросы.
Также, каждый день идут промо-акции, рассылки, которые приводят на сайт разные группы людей, на разные группы товаров, что усложняет однозначно и быстро дать ответ, что стало лучше или хуже.
Еще выглядит странным, что вы говорите о 10-20 A/B тестов, но не говорите о Multivariate A/B тестах. Т.к если идет паралельно не один тест а несколько, нужно учитывать все вариации A/B тестов, чтобы видеть, какая связка в совокупности дает наилучший результат.
Спасибо за комментарий! Вы говорите правильно, однако, с «искусственным» изменением не соглашусь. Весь посыл статьи в том, что с помощью А/Б тестов можно и нужно принимать решения на основе данных, а не на основе «мнения HIPPO» (highest paid person's opinion). Проблема в том, что на пути принятия таких решений можно допустить массу ошибок и в этой статье мы собрали наиболее частые.
Что касается конкретного примера про исполняемость заказов из статьи, тут дело вот в чем. При нормальном проведении А/Б теста исполняемость заказов между сегментами отличаться не должна. Мы вносим изменение в интерфейс сайта, которое делает его удобнее и помогает большему количеству людей покупать. Если же в одном из сегментов значительно падает исполняемость – на мой взгляд практически на лицо манипуляция тестом, то есть кто-то осознанно, находясь в одном из сегментов теста, оформляет заказы, чтобы исказить результаты эксперимента.
Говоря о промо-акциях, рассылках и т.д. – по Закону Больших Чисел на бесконечности мы должны получить абсолютно равномерное распределение аудитории по акциям, рассылкам и любым другим срезам между сегментами теста. В статье приводится несколько доводов о важности проверки такого распределения, а так же о получении статистической достоверности превосходства одного варианта над другим.
P.S.: про 10-20 тестов – имелось ввиду, что 10-20 магазинов независимо друг от друга проводят тестирование нашей системы.
Что касается конкретного примера про исполняемость заказов из статьи, тут дело вот в чем. При нормальном проведении А/Б теста исполняемость заказов между сегментами отличаться не должна. Мы вносим изменение в интерфейс сайта, которое делает его удобнее и помогает большему количеству людей покупать. Если же в одном из сегментов значительно падает исполняемость – на мой взгляд практически на лицо манипуляция тестом, то есть кто-то осознанно, находясь в одном из сегментов теста, оформляет заказы, чтобы исказить результаты эксперимента.
Говоря о промо-акциях, рассылках и т.д. – по Закону Больших Чисел на бесконечности мы должны получить абсолютно равномерное распределение аудитории по акциям, рассылкам и любым другим срезам между сегментами теста. В статье приводится несколько доводов о важности проверки такого распределения, а так же о получении статистической достоверности превосходства одного варианта над другим.
P.S.: про 10-20 тестов – имелось ввиду, что 10-20 магазинов независимо друг от друга проводят тестирование нашей системы.
Зашел почитать, потому что очень красивая девочка на фото.
За статью — спасибо. Вроде как читаешь, и все понятно, то есть прописные истины, но с приведенными примерами, понимаешь, что если бы делал тесты А/Б до того, как прочел уже оформленное в слова и пункты, точно где-нибудь налажал бы.
Теперь при случае буду дольше думать и не совершу совершу меньше ошибок.
За статью — спасибо. Вроде как читаешь, и все понятно, то есть прописные истины, но с приведенными примерами, понимаешь, что если бы делал тесты А/Б до того, как прочел уже оформленное в слова и пункты, точно где-нибудь налажал бы.
Теперь при случае буду дольше думать и не совершу совершу меньше ошибок.
Эта девушка из магазина плакатов Startup Vitamins, такие плакаты висят в офисе Retail Rocket :)
www.startupvitamins.com/products/startup-canvas-experiment-fail-learn-repeat
www.startupvitamins.com/products/startup-canvas-experiment-fail-learn-repeat
Крайне важно, чтобы вся аудитория сайта относилась к одному из сегментов теста, в противном случае невозможно оценить влияние изменения на бизнес в целом.
Почему оценка становится невозможной? А как же работают статистические опросы? По этой логике необходимо в каждом опросе опросить каждого гражданина России. Что неверно. В реальности опросы работают довольно хорошо.
А/Б тесты проводят на всей совокупности, так как стоимость тестирования от размера выборки не меняется. Другое дело, что тестирования альтернативной версии возможно на любой доли трафика, то есть новую версию сайта можно запустить на 10% трафика, тест по прежнему будет актуален, только статистической достоверности превосходства одной из вариаций придется ждать дольше.
В статье же упоминается проверка на размер выборки как таковой, очень важно убедиться, что она именно такая, как вы ожидаете. Одна из самых частых проблем – ожидаем, что тестируется 100% аудитории, а на самом деле – гораздо меньше.
В статье же упоминается проверка на размер выборки как таковой, очень важно убедиться, что она именно такая, как вы ожидаете. Одна из самых частых проблем – ожидаем, что тестируется 100% аудитории, а на самом деле – гораздо меньше.
спасибо за статью; есть несколько комментариев, сори, если выглядит как критика, хочется обсудить несколько моментов
1) Использование GA — видимо чтобы было удобнее клиентам показывать результаты. Для внутренней аналитики тоже его используете или просто нет возможности размещать свой счетчик по условиям сотрудничества?
2) Один из самых важных этапов в такого плана тестах — фильтрация данных, GA убивает возможность что-то фильтровать практически полностью, т.к. нет исходных данных (по которым всегда нужно пробегаться глазами и убирать всякий мусор)
3) Про сотруников магазинов и лояльных старых посетителях сайтах писали многие, это важный баг при тестировании. Но еще очень много багов чисто техническая ошибка (отрабатывает или нет ява скрипт и т.п.) Опять же GA практически убивает возможности это дополнительно проверять.
4) Один из вариантов контроля ява скрипта, например, это дополнительный свой счетчик на картинках или т.п., который работает очень примитивно, но очень надежно (или логи). Тогда можно сверять макропоказатели в АБ тестах.
— 5) Все говорят что распределить хорошо пользователей по группам сложно, но никто не обсуждает детали. Наверное, какие-то наработки которые не хочется выдавать даже на уровне идеи.
6) Распределить пользователей одинаково невозможно, по крайней мере на разумных выборках порядка 500 тыс. человек на эксперимент. Допустим берем: география (4-5 кластеров городов), пол и возраст (6-8 групп), социальный статус (3 вида), устройство (3 вида), время захода (3 времени), новый или постоянный ну и еще 3-4 показателя.
невозможно все сделать равными, будут достаточно сильные просадки по какому-то показателю;
(могу скинуть числовой пример, интересно какое решение даже вручную можно предложить для таких цифр)
7) я лично не верю в историю о идеальном балансировщике. решение для меня лежит в том чтобы одни группы распределить равномерно, а другие группы обработать на уровне фильтрации и поправочных коэффициентов
8) Вы правда смотрите условно только две цифры уровень достоверности (при принятии решения)? У вас же есть данные в динамике по дням (а лучше — группам по часам), из этого можно выжать больше для анализа. Разве нет?
1) Использование GA — видимо чтобы было удобнее клиентам показывать результаты. Для внутренней аналитики тоже его используете или просто нет возможности размещать свой счетчик по условиям сотрудничества?
2) Один из самых важных этапов в такого плана тестах — фильтрация данных, GA убивает возможность что-то фильтровать практически полностью, т.к. нет исходных данных (по которым всегда нужно пробегаться глазами и убирать всякий мусор)
3) Про сотруников магазинов и лояльных старых посетителях сайтах писали многие, это важный баг при тестировании. Но еще очень много багов чисто техническая ошибка (отрабатывает или нет ява скрипт и т.п.) Опять же GA практически убивает возможности это дополнительно проверять.
4) Один из вариантов контроля ява скрипта, например, это дополнительный свой счетчик на картинках или т.п., который работает очень примитивно, но очень надежно (или логи). Тогда можно сверять макропоказатели в АБ тестах.
— 5) Все говорят что распределить хорошо пользователей по группам сложно, но никто не обсуждает детали. Наверное, какие-то наработки которые не хочется выдавать даже на уровне идеи.
6) Распределить пользователей одинаково невозможно, по крайней мере на разумных выборках порядка 500 тыс. человек на эксперимент. Допустим берем: география (4-5 кластеров городов), пол и возраст (6-8 групп), социальный статус (3 вида), устройство (3 вида), время захода (3 времени), новый или постоянный ну и еще 3-4 показателя.
невозможно все сделать равными, будут достаточно сильные просадки по какому-то показателю;
(могу скинуть числовой пример, интересно какое решение даже вручную можно предложить для таких цифр)
7) я лично не верю в историю о идеальном балансировщике. решение для меня лежит в том чтобы одни группы распределить равномерно, а другие группы обработать на уровне фильтрации и поправочных коэффициентов
8) Вы правда смотрите условно только две цифры уровень достоверности (при принятии решения)? У вас же есть данные в динамике по дням (а лучше — группам по часам), из этого можно выжать больше для анализа. Разве нет?
Очень много вопросов, из ответов можно составить новую статью такого же объема. Постараюсь очень кратко выразить свои мысли по всем вопросам сразу.
Google Analytics – самый популярный инструмент в мире для веб-аналитики и вероятность его правильный работы в общем случае максимальна (большое количество пользователей, репортящих проблемы, наибольшее среди аналогов количество экспертов по настройке, максимальное количество обучающих материалов – есть даже шутка такая в профессиональной тусовке про Яндекс.Метрику и Google Analytics).
По этой же причине мы используем этот иструмент для тестирования эффективности нашей системы для наших клиентов – всем привычно. Для внутренней аналитики платформы Retail Rocket GA не используется, объемы не те – бесплатная версия имеет ограничение в 10 миллионов хитов в месяц, мы преодолеем его менее чем за полчаса :) Но в нашем личном кабинете и на промо-сайте Google Analytics, конечно же, установлена.
Распределить пользователей одинаково возможно. Нам не удалось добиться хорошего распределения и исключения других описанных в статье проблем «модными» инструментами вроде Visual Website Optimizer и Optimizely как раз по причинам, которые вы описываете, поэтому мы создали и поддерживаем open source библиотеку для проведения А/Б тестов. Результаты распределения трафика очень достойные, пример:
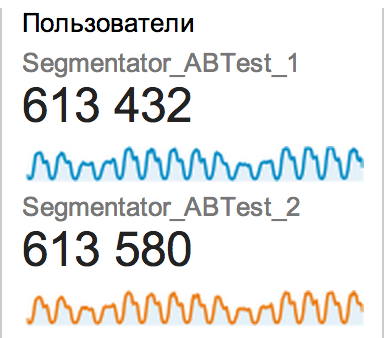
Такое распределение наблюдается по всем срезам. Достигается оно, в основном, за счет двух вещей:
По последнему вопросу – все примеры из статьи касаются тестирования сайтов наших клиентов (интернет-магазинов) в состояниях «с Retail Rocket» и «без Retail Rocket» для оценки эффекта платформы на продажи магазина. Факторы же ранжирования товаров в конкретных алгоритмах могут быть самыми разными и зависеть от сегмента пользователя, его действий, свойств сущностей, с которыми он взаимодействовал, и даже погодных условий в его регионе. Какие-то вещи о наших подходах будем постепенно раскрывать, для этого мы и завели инженерный блог :)
Google Analytics – самый популярный инструмент в мире для веб-аналитики и вероятность его правильный работы в общем случае максимальна (большое количество пользователей, репортящих проблемы, наибольшее среди аналогов количество экспертов по настройке, максимальное количество обучающих материалов – есть даже шутка такая в профессиональной тусовке про Яндекс.Метрику и Google Analytics).
По этой же причине мы используем этот иструмент для тестирования эффективности нашей системы для наших клиентов – всем привычно. Для внутренней аналитики платформы Retail Rocket GA не используется, объемы не те – бесплатная версия имеет ограничение в 10 миллионов хитов в месяц, мы преодолеем его менее чем за полчаса :) Но в нашем личном кабинете и на промо-сайте Google Analytics, конечно же, установлена.
Распределить пользователей одинаково возможно. Нам не удалось добиться хорошего распределения и исключения других описанных в статье проблем «модными» инструментами вроде Visual Website Optimizer и Optimizely как раз по причинам, которые вы описываете, поэтому мы создали и поддерживаем open source библиотеку для проведения А/Б тестов. Результаты распределения трафика очень достойные, пример:
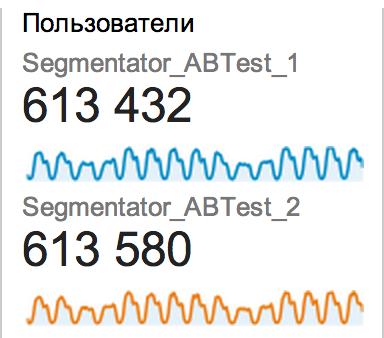
Такое распределение наблюдается по всем срезам. Достигается оно, в основном, за счет двух вещей:
- Очень простой код, который только делит трафик и больше ничего. Никаких WYSIWYG-редакторов с манипуляциями DOM и прочих крутых фич.
- Библиотека скачивается с GitHub, хостится сайтом и подключается синхронно в head
По последнему вопросу – все примеры из статьи касаются тестирования сайтов наших клиентов (интернет-магазинов) в состояниях «с Retail Rocket» и «без Retail Rocket» для оценки эффекта платформы на продажи магазина. Факторы же ранжирования товаров в конкретных алгоритмах могут быть самыми разными и зависеть от сегмента пользователя, его действий, свойств сущностей, с которыми он взаимодействовал, и даже погодных условий в его регионе. Какие-то вещи о наших подходах будем постепенно раскрывать, для этого мы и завели инженерный блог :)
спасибо большое за ответ; очень мало интересной информации по АБ тестам доступно; на «американцев» надежды мало, они всегда общими словами отделываются, поэтому хочется верить что российский сервис чуть больше деталей расскажет. Поэтому и столько вопросов :)
— уточню про идеальное распределение пользователей
0. почему это может быть важно: вот вы делаете два среза tablet RR_recs и tablet not_RR_recs. В вашем случае разница очень большая, поэтому все очевидно и без учета возможного шума. Но может оказаться и так, что разница будет 5-10%. И если, например, что в «tablet RR_recs» по какой то причине будет 60% женщин, а в tablet not_RR_recs будет 40% женщин. То качество срезов будет критично для анализа результатов.
1. Почему балансировщику сложно. Как я написал есть около 8 параметров и по каждому от 2 до 8-10 групп. Итого может быть, например, порядка 5*8*3*3*3*3*3*6*3=175 тыс. комбинаций этих параметров.
Да, они не равновероятны, но все таки мы выбираем группы так, чтобы какое-то сравнимое количество было людей в них.
Теперь берем 500 тыс. человек в эксперименте. Получается в среднем по 3 чел. на комбинацию параметров.
2. Вопрос: как в теории разделить на 2 группы так, чтобы по каждому параметру было примерно равномерно?
3. Понятно что А/А тесты можно пройти и при достаточно простом делении, достаточно, например, брать последнюю цифру айпи адреса и достаточно качественное будет распределение. Но если аккуратно оценивать равномерность — как быть?
4. Поясню в чем примерно возникает затык.
Шаг 1. Берем 500 тыс. человек. Делим на 2 группы по полу (мужчины и женщины). 250 тыс. в одной и 250 тыс. в другой. Половина из 250 тыс. пойдет в А. Другая половина пойдет в Б, осталось только понять какая именно.
Шаг 2. Берем 250 тыс мужчин и делим на 5 групп по географии. Получаем условно по 50 тыс. в каждой.
Шаг 3. 50 тыс. делим на группы на время захода на сайт, получаем условно по 17 тыс. в каждой группе
и т.д.
Шаг 9. Получаем условно 10 человек. Из них 7 заходили с дестопа 2 с планшета и 1 с мобильного. И вот тут не делится на две части поровну.
И как не крути в каком-то срезе как правило будет перекос. Это чисто комбинаторно невозможно, если я не ошибаюсь.
5. Я думаю что вы используете вероятностный подход. С какой то вероятностью кидаете человека в какую то кучку.
6. Но вероятностный подход будет давать до 10-15% различия на каком-то срезе. Или у вас лучше результаты? Или вы не очень много срезов используете?
это можно легко проверить, просто возьмите эксперимент и посчитайте процентовку в А и в Б по следующим срезам (проверить — я имею в виду если вам интересно это для себя сделать):
-пол
-возраст
-источник трафика (на уровне поисковый/прямой/...)
-время дня
-устройство
-город (кластер по географии)
-новый/постоянный
-социальный статус/интересы
-страница входа (например, рубрика/товар)
— уточню про идеальное распределение пользователей
0. почему это может быть важно: вот вы делаете два среза tablet RR_recs и tablet not_RR_recs. В вашем случае разница очень большая, поэтому все очевидно и без учета возможного шума. Но может оказаться и так, что разница будет 5-10%. И если, например, что в «tablet RR_recs» по какой то причине будет 60% женщин, а в tablet not_RR_recs будет 40% женщин. То качество срезов будет критично для анализа результатов.
1. Почему балансировщику сложно. Как я написал есть около 8 параметров и по каждому от 2 до 8-10 групп. Итого может быть, например, порядка 5*8*3*3*3*3*3*6*3=175 тыс. комбинаций этих параметров.
Да, они не равновероятны, но все таки мы выбираем группы так, чтобы какое-то сравнимое количество было людей в них.
Теперь берем 500 тыс. человек в эксперименте. Получается в среднем по 3 чел. на комбинацию параметров.
2. Вопрос: как в теории разделить на 2 группы так, чтобы по каждому параметру было примерно равномерно?
3. Понятно что А/А тесты можно пройти и при достаточно простом делении, достаточно, например, брать последнюю цифру айпи адреса и достаточно качественное будет распределение. Но если аккуратно оценивать равномерность — как быть?
4. Поясню в чем примерно возникает затык.
Шаг 1. Берем 500 тыс. человек. Делим на 2 группы по полу (мужчины и женщины). 250 тыс. в одной и 250 тыс. в другой. Половина из 250 тыс. пойдет в А. Другая половина пойдет в Б, осталось только понять какая именно.
Шаг 2. Берем 250 тыс мужчин и делим на 5 групп по географии. Получаем условно по 50 тыс. в каждой.
Шаг 3. 50 тыс. делим на группы на время захода на сайт, получаем условно по 17 тыс. в каждой группе
и т.д.
Шаг 9. Получаем условно 10 человек. Из них 7 заходили с дестопа 2 с планшета и 1 с мобильного. И вот тут не делится на две части поровну.
И как не крути в каком-то срезе как правило будет перекос. Это чисто комбинаторно невозможно, если я не ошибаюсь.
5. Я думаю что вы используете вероятностный подход. С какой то вероятностью кидаете человека в какую то кучку.
6. Но вероятностный подход будет давать до 10-15% различия на каком-то срезе. Или у вас лучше результаты? Или вы не очень много срезов используете?
это можно легко проверить, просто возьмите эксперимент и посчитайте процентовку в А и в Б по следующим срезам (проверить — я имею в виду если вам интересно это для себя сделать):
-пол
-возраст
-источник трафика (на уровне поисковый/прямой/...)
-время дня
-устройство
-город (кластер по географии)
-новый/постоянный
-социальный статус/интересы
-страница входа (например, рубрика/товар)
По Закону Больших Чисел если обеспечить случайность распределения, то на бесконечности оно будет абсолютно равномерным.
Специально для Вас сделал еще пару скриншотов из того же теста, из которого делался скриншот в предыдущем комментарии, но за другой интервал: take.ms/t3pAb и take.ms/2igdy
Такая картина _должна_ быть. Пример с планшетами в статье показывает, как найти проблему в тесте и том конкретном случае на планшетах в тестовой версии ехала верстка, что искажало результаты теста.
Специально для Вас сделал еще пару скриншотов из того же теста, из которого делался скриншот в предыдущем комментарии, но за другой интервал: take.ms/t3pAb и take.ms/2igdy
Такая картина _должна_ быть. Пример с планшетами в статье показывает, как найти проблему в тесте и том конкретном случае на планшетах в тестовой версии ехала верстка, что искажало результаты теста.
Не подскажете, как с помощью GA протестировать не отдельную страницу с товаром, а страницы товаров в целом?
Sign up to leave a comment.
Подводные камни A/Б-тестирования или почему 99% ваших сплит-тестов проводятся неверно?