
Перед вами — седьмая (заключительная) часть серии статей о разработке REST-серверов на Go. В предыдущих статьях мы занимались, в основном, различными подходами к разработке REST API для простого приложения, автоматизирующего управление задачами. Сегодня мы исследуем кое-что совершенно новое и поговорим о том, как сделать похожий API, пользуясь не REST, а GraphQL.

Хотя тут я уделяю определённое внимание причинам выбора GraphQL и сравнению GraphQL и REST, это здесь не главное. Есть множество статей, освещающих эти вопросы, и я советую вам поискать их и почитать. Главная цель этого материала заключается в том, чтобы привести пример создания GraphQL-сервера на Go. Для того чтобы не усложнять нашу задачу, этот сервер использует модель данных, очень похожую на модель, реализованную в одном из вариантов сервера из предыдущих материалов (речь идёт о простом бэкенде, дающем возможность работать со списком задач).
Обратимся к Википедии: «GraphQL — это опенсорсный язык запросов для работы с API, а так же — среда для выполнения запросов».
Вспомним базу данных для хранения сведений о задачах из первого материала. Она очень проста. Поэтому для того чтобы у нас появились бы реальные причины использования GraphQL, нам стоит приблизить эту базу данных к чему-то такому, что может использоваться в реальных проектах. Добавим к каждой задаче набор вложений. Теперь соответствующие типы в Go будут выглядеть так:
А если вам удобнее работать со схемами баз данных — вот такая схема.
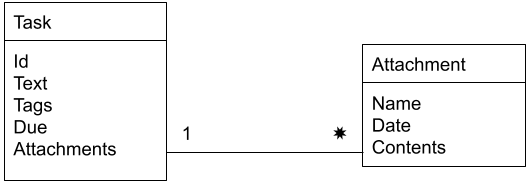
Схема базы данных
Линия
До сих пор наш REST API выглядел так:
Тут стоит обратить особое внимание на то, что многие из этих запросов возвращают список задач. Представим, что теперь, как описано выше, у задач есть вложения. А эти вложения могут быть довольно объёмными. В новых условиях в ответ на запрос, направленный на получение задач по тегу (
Для решения этой задачи часто пользуются подходом, при применении которого, в нашем случае, в ответ на запрос
Но теперь перед нами встаёт обратная проблема, выражающаяся в возврате в ответ на запрос недостаточного количества данных (under-fetching). Получается, что мы, вместо того, чтобы получить необходимую информацию, выполнив лишь один запрос, вынуждены выполнять целую кучу запросов. Возможно — по одному запросу на каждую задачу с соответствующим тегом, и ещё по одному на каждое вложение каждой задачи. У такого подхода есть и свои проблемы, например — увеличение времени, нужного на получение всех необходимых данных от сервера.
Задумаемся ненадолго о том, как можно решить вышеописанные проблемы. Очевидно — можно создать в REST API особую конечную точку, которая возвращает именно то, что нам нужно. Например, она могла бы выглядеть как
Ещё одна возможность заключается в том, чтобы в API имелась бы единственная конечная точка, к которой можно было бы отправлять более сложные запросы. Эти запросы, немного напоминающие SQL-запросы, будут содержать точные сведения о том, какие именно данные нам нужны.
Именно так работает GraphQL. К сравнению этой технологии с SQL я ещё вернусь, а пока давайте поговорим о том, как это реализовано в GraphQL. Вот — GraphQL-запрос, который может быть отправлен клиентом:
В ответ на этот запрос клиент получит список задач. Но для каждой задачи будет возвращено лишь текстовое описание задачи и названия всех её вложений. А это — именно то, что нам нужно. И приходит всё это к нам в ответ на единственный запрос.
Я взял код сервера из предыдущих статей и переписал его в расчёте на использование GraphQL. Модель данных обновлена с учётом использования вложений. Тут можно найти полный код сервера.
Существует несколько пакетов, рассчитанных на работу с GraphQL в Go-проектах. В этом эксперименте я решил воспользоваться gqlgen. Пакет принимает GraphQL-схему в виде входных данных и генерирует Go-код, реализующий HTTP-сервер для обслуживания запросов к соответствующим данным. Обработчики (на GraphQL-жаргоне называемые распознавателями (resolver)) представляют собой заготовки, за реализацию которых отвечает программист. К gqlgen подготовлено достойное руководство, поэтому мы уделим основное внимание тому, как работает сервер.
Вот — GraphQL-схема для нашего бэкенда (эти схемы составляют на языке, правила которого закреплены в спецификации):
Тут стоит обратить внимание на несколько деталей:
И наконец — сложно не заменить типы
Подобные графовые данные может быть сложно конструировать в расчёте на их использование во входных параметрах. Как быть в том случае, если они являются взаимно рекурсивными? В результате в GraphQL используется строгое разделение — типы, которые можно использовать для оформления входных данных, должны быть чётко обозначены. Они могут представлять собой лишь деревья, а не графы. В результате, хотя мы, теоретически, могли бы переиспользовать тип
Вот как я организовал работу над этим проектом:
Если говорить о распознавателях, то gqlgen создаёт пустой тип
Пакет gqlgen, кроме того, генерирует пустые методы-обработчики, код которых нам нужно написать. Для большинства распознавателей это — очень простой код. Например — такой:
Обратите внимание на то, что наш распознаватель возвращает полный список задач. Возможности GraphQL по выбору конкретных полей (или защита от избыточных данных) реализована в коде, сгенерированном gqlgen. Насколько я понял, в распознавателе нельзя узнать о том, какие именно поля нужно вернуть в ответ на конкретный запрос, поэтому нам всегда нужно брать из базы данных всё, что может пригодиться. Возможно, это — ограничение gqlgen, или, может, это — особенность всех GraphQL-серверов — точно этого я не знаю. Если описать это языком SQL, то окажется, что нам предлагается всегда выполнять запрос вида
И, наконец, gqlgen генерирует функцию
Здесь
Одна из самых замечательных возможностей GraphQL — это интерактивная среда (playground), благодаря которой эксперименты с сервером, проводимые прямо из браузера, превращаются в очень приятное и простое занятие. В вышеприведённом серверном коде можно заметить регистрацию

Приложение graphql-playground
Как видите, я, в левой панели, ввёл запрос, о котором рассказывал выше, а после того, как он был выполнен, данные, возвращённые сервером, были выведены в правой панели. Интерактивная среда поддерживает подсветку синтаксиса, автозавершение ввода, позволяет открывать множество вкладок и даже умеет «переводить» запросы в команды
Если анализировать лишь общую картину, то у GraphQL имеются очевидные преимущества перед REST. В частности — в области эффективности, в ситуациях, когда избыток или недостаток данных может сделать работу с REST API далёкой от оптимальной. Но подобная гибкость GraphQL не бесплатна. А именно — благодаря ей можно, без особых проблем, отправлять на серверы произвольные и очень сложные GraphQL-запросы, то есть — организовывать DoS-атаки. Но, конечно, есть рекомендации, следование которым помогает разработчикам GraphQL-серверов избегать подобных неприятностей.
GraphQL — это развивающаяся технология. Вместе с ней развивается и множество интересных инструментов. Например — вышеописанная интерактивная среда. Но технология REST существует гораздо дольше, GraphQL тяжело конкурировать с ней в плане w.r.t.-инструментов и универсальности. Так, практически любой сервер в наши дни обладает REST API, разработано множество инструментов для мониторинга, логирования, профилирования и разного рода исследований таких API. Технология REST, кроме того, очень проста — речь идёт об обычных путях, к которым обращаются через HTTP. Часто к ним можно обращаться с помощью простых curl-конструкций или из браузера. А технология GraphQL устроена сложнее, так как тексты GraphQL-запросов должны размещаться в телах POST-запросов.
Простота REST имеет далеко идущие последствия. В типичном веб-бэкенде REST-запросы обслуживаются SQL-запросами (часто — нетривиальными), отправляемыми к базам данных. А тот, кто пользуется GraphQL, вынужден пользоваться ещё и особым языком запросов, который в чём-то немного похож на SQL, а в чём-то сильно от SQL отличается, так как модель графов, на которой основана технология GraphQL, на самом деле, не соответствует той модели, на которой основаны реляционные базы данных. Опыт подсказывает мне, что, используя GraphQL, приходится держать в голове больше сведений, чем при использовании SQL. В частности, речь идёт о GraphQL-запросе и о том, как он «переводится» на язык реляционной базы данных, лежащей в основе системы хранения данных сервера. Перспективные проекты, вроде Dgraph (база данных, изначально рассчитанная на GraphQL, с бэкендом, основанным на графовых данных) и PostGraphile (система, которая автоматически строит соответствия между GraphQL и PostgreSQL) — это интересные разработки, за которыми стоит понаблюдать тем, кто интересуется GraphQL.
Ещё один момент, на который стоит обратить внимание, это — кеширование. REST хорошо уживается с HTTP-кешированием, так как эта технология, в основном, основана на идемпотентных GET-запросах. А вот у GraphQL, в этом смысле, всё не так благополучно, так как эта система, на уровне HTTP, не различает идемпотентные запросы на получение данных и запросы на изменение данных.
В итоге же можно сказать, что программисты либо ограничены тем, с какими системами им нужно взаимодействовать, либо (в редких приятных случаях) — имеют возможность выбирать технологии для новых проектов. В последнем случае стоит просто выбрать тот инструмент, который лучше всего подходит для конкретной задачи. И чем шире выбор — тем лучше.
Применяете ли вы GraphQL при создании Go-серверов?


Предыдущие части:
Разработка REST-серверов на Go. Часть 1: стандартная библиотека
Разработка REST-серверов на Go. Часть 2: применение маршрутизатора gorilla/mux
Разработка REST-серверов на Go. Часть 3: использование веб-фреймворка Gin
Разработка REST-серверов на Go. Часть 4: применение OpenAPI и Swagger
Разработка REST-серверов на Go. Часть 5: Middleware
Разработка REST-серверов на Go. Часть 6: аутентификация
Вы тут — Разработка REST-серверов на Go. Часть 7: GraphQL
Разработка REST-серверов на Go. Часть 2: применение маршрутизатора gorilla/mux
Разработка REST-серверов на Go. Часть 3: использование веб-фреймворка Gin
Разработка REST-серверов на Go. Часть 4: применение OpenAPI и Swagger
Разработка REST-серверов на Go. Часть 5: Middleware
Разработка REST-серверов на Go. Часть 6: аутентификация
Вы тут — Разработка REST-серверов на Go. Часть 7: GraphQL
Хотя тут я уделяю определённое внимание причинам выбора GraphQL и сравнению GraphQL и REST, это здесь не главное. Есть множество статей, освещающих эти вопросы, и я советую вам поискать их и почитать. Главная цель этого материала заключается в том, чтобы привести пример создания GraphQL-сервера на Go. Для того чтобы не усложнять нашу задачу, этот сервер использует модель данных, очень похожую на модель, реализованную в одном из вариантов сервера из предыдущих материалов (речь идёт о простом бэкенде, дающем возможность работать со списком задач).
Зачем нам нужна технология GraphQL?
Обратимся к Википедии: «GraphQL — это опенсорсный язык запросов для работы с API, а так же — среда для выполнения запросов».
Вспомним базу данных для хранения сведений о задачах из первого материала. Она очень проста. Поэтому для того чтобы у нас появились бы реальные причины использования GraphQL, нам стоит приблизить эту базу данных к чему-то такому, что может использоваться в реальных проектах. Добавим к каждой задаче набор вложений. Теперь соответствующие типы в Go будут выглядеть так:
type Attachment struct {
Name string `json:"Name"`
Date time.Time `json:"Date"`
Contents string `json:"Contents"`
}
type Task struct {
ID int `json:"Id"`
Text string `json:"Text"`
Tags []string `json:"Tags"`
Due time.Time `json:"Due"`
Attachments []*Attachment `json:"Attachments"`
А если вам удобнее работать со схемами баз данных — вот такая схема.

Схема базы данных
Линия
1 ---- * между таблицами указывает, в терминах реляционных баз данных, на отношение «один ко многим». Это значит, что с одной задачей может быть связано несколько вложений.До сих пор наш REST API выглядел так:
POST /task/ : создаёт задачу и возвращает её ID
GET /task/<taskid> : возвращает одну задачу по её ID
GET /task/ : возвращает все задачи
DELETE /task/<taskid> : удаляет задачу по ID
GET /tag/<tagname> : возвращает список задач с заданным тегом
GET /due/<yy>/<mm>/<dd> : возвращает список задач, запланированных на указанную дату
Тут стоит обратить особое внимание на то, что многие из этих запросов возвращают список задач. Представим, что теперь, как описано выше, у задач есть вложения. А эти вложения могут быть довольно объёмными. В новых условиях в ответ на запрос, направленный на получение задач по тегу (
GET /tag/<tagname>), может вернуться очень много данных, которые, если, например, клиенту нужны лишь названия задач, окажутся избыточными. Это — ситуация, далёкая от идеала, в особенности — при работе с нашим API по медленному или дорогому интернет-соединению (например — если список задач выводится на мобильном устройстве). Это — проблема, от которой страдают обычные REST API, когда в ответ на запрос приходит больше данных, чем нужно (over-fetching).Для решения этой задачи часто пользуются подходом, при применении которого, в нашем случае, в ответ на запрос
GET /tag/<tagname> возвращались бы лишь ID задач, а не сами задачи. Потом, имея эти ID, клиент может перебрать их список и, для получения нужных задач целиком, выполнить запросы GET /task/<taskid>. Правда, и при таком подходе клиент получит некоторый объём избыточных данных, так как, возможно, ему не нужны все данные задач, в состав которых входят и вложения. Поэтому тут можно возвращать лишь имена (или ID) вложений и оснастить наш API ещё одной конечной точкой, возвращающей вложения по их ID.Но теперь перед нами встаёт обратная проблема, выражающаяся в возврате в ответ на запрос недостаточного количества данных (under-fetching). Получается, что мы, вместо того, чтобы получить необходимую информацию, выполнив лишь один запрос, вынуждены выполнять целую кучу запросов. Возможно — по одному запросу на каждую задачу с соответствующим тегом, и ещё по одному на каждое вложение каждой задачи. У такого подхода есть и свои проблемы, например — увеличение времени, нужного на получение всех необходимых данных от сервера.
Как GraphQL решает проблемы избыточного и недостаточного объёма получаемых данных?
Задумаемся ненадолго о том, как можно решить вышеописанные проблемы. Очевидно — можно создать в REST API особую конечную точку, которая возвращает именно то, что нам нужно. Например, она могла бы выглядеть как
GET /task-name-and-attachment-name-in-tag/<tagname> и возвращала бы список имён задач со списком имён вложений для каждой из этих задач. Получается, что при таком подходе ни недостатка, ни избытка данных не наблюдается! Это — вполне рабочий подход, некоторые REST API имеют специализированные конечные точки вроде этой. Но проблема таких конечных точек очевидна: они не отличаются гибкостью. Предположим, что нам нужны те же данные, но получать их мы собираемся без использования тега. Например, надо получить такой же список задач, запланированных на указанную дату. Придётся ли создавать новую конечную точку, возвращающую те же данные, но теперь — с отбором по дате? Это, конечно, возможно, но совершенно очевидным должно быть то, что по мере того, как API будет усложняться, в нём будет появляться множество конечных точек, в той или иной мере дублирующих функционал друг друга.Ещё одна возможность заключается в том, чтобы в API имелась бы единственная конечная точка, к которой можно было бы отправлять более сложные запросы. Эти запросы, немного напоминающие SQL-запросы, будут содержать точные сведения о том, какие именно данные нам нужны.
Именно так работает GraphQL. К сравнению этой технологии с SQL я ещё вернусь, а пока давайте поговорим о том, как это реализовано в GraphQL. Вот — GraphQL-запрос, который может быть отправлен клиентом:
query {
getTasksByTag(tag: "shopping") {
Text
Attachments{
Name
}
}
}
В ответ на этот запрос клиент получит список задач. Но для каждой задачи будет возвращено лишь текстовое описание задачи и названия всех её вложений. А это — именно то, что нам нужно. И приходит всё это к нам в ответ на единственный запрос.
Наш Go-сервер с GraphQL
Я взял код сервера из предыдущих статей и переписал его в расчёте на использование GraphQL. Модель данных обновлена с учётом использования вложений. Тут можно найти полный код сервера.
Существует несколько пакетов, рассчитанных на работу с GraphQL в Go-проектах. В этом эксперименте я решил воспользоваться gqlgen. Пакет принимает GraphQL-схему в виде входных данных и генерирует Go-код, реализующий HTTP-сервер для обслуживания запросов к соответствующим данным. Обработчики (на GraphQL-жаргоне называемые распознавателями (resolver)) представляют собой заготовки, за реализацию которых отвечает программист. К gqlgen подготовлено достойное руководство, поэтому мы уделим основное внимание тому, как работает сервер.
Вот — GraphQL-схема для нашего бэкенда (эти схемы составляют на языке, правила которого закреплены в спецификации):
type Query {
getAllTasks: [Task]
getTask(id: ID!): Task
getTasksByTag(tag: String!): [Task]
getTasksByDue(due: Time!): [Task]
}
type Mutation {
createTask(input: NewTask!): Task!
deleteTask(id: ID!): Boolean
deleteAllTasks: Boolean
}
scalar Time
type Attachment {
Name: String!
Date: Time!
Contents: String!
}
type Task {
Id: ID!
Text: String!
Tags: [String!]
Due: Time!
Attachments: [Attachment!]
}
input NewAttachment {
Name: String!
Date: Time!
Contents: String!
}
input NewTask {
Text: String!
Tags: [String!]
Due: Time!
Attachments: [NewAttachment!]
}
Тут стоит обратить внимание на несколько деталей:
QueryиMutation— это особые типы GraphQL. Они описывают API. Другие типы тоже вызывают определённый интерес. GraphQL — это строго типизированная система! Это очень хорошо, так как позволяет чётче описывать процесс валидации входных данных (формат JSON, обычно используемый в REST API, типизирован гораздо слабее).- Даже не смотря на то, что API, описанные в типе
Query, похоже, возвращают[Task], то есть — список задач, тут нет проблемы получения избыточных данных. Как видно из примера запроса, приведённого в предыдущем разделе, GraphQL позволяет клиентам точно описывать в запросах поля, которые им нужны, в результате в ответе на запрос приходят исключительно эти поля. - В GraphQL нет встроенных типов для значений, представляющих время и дату, но при работе с GraphQL можно создавать расширения. Тут я использую расширение
scalar Time, встроенное в gqlgen. Библиотека связывает эту конструкцию с типом Gotime.Time.
И наконец — сложно не заменить типы
NewTask и NewAttachment, которые дублируют типы Task и Attachment. Зачем они нужны? Ответ на этот вопрос получается довольно-таки сложным. Типы GraphQL могут представлять графы, в нашем случае смысл этого заключается в том, что у одной задачи может быть множество вложений. Но в теории одно и то же вложение может принадлежать нескольким задачам. Это может быть причиной того, что в названии «GraphQL» есть слово «graph» (я был бы счастлив узнать о том, не ошибаюсь ли я в этом предположении), а это сильно отличается от того, как проектируют реляционные базы данных.Подобные графовые данные может быть сложно конструировать в расчёте на их использование во входных параметрах. Как быть в том случае, если они являются взаимно рекурсивными? В результате в GraphQL используется строгое разделение — типы, которые можно использовать для оформления входных данных, должны быть чётко обозначены. Они могут представлять собой лишь деревья, а не графы. В результате, хотя мы, теоретически, могли бы переиспользовать тип
Task для описания входных параметров (так как это — не граф), GraphQL это запрещает и настаивает на использовании нового типа.Вот как я организовал работу над этим проектом:
- Выполнил команду
go run github.com/99designs/gqlgen init. - Подготовил вышеописанную GraphQL-схему.
- Выполнил команду
go run github.com/99designs/gqlgen generate. - Отредактировал сгенерированный код, реализовав распознаватели.
- Запустил сгенерированный
server.go.
Если говорить о распознавателях, то gqlgen создаёт пустой тип
struct, называемый Resolver, с использованием которого определяют методы-обработчики. Эту структуру нужно привести в соответствие с нуждами приложения и включить в неё общие данные, необходимые всем распознавателям. В нашем случае это — лишь хранилище задач:type Resolver struct {
Store *taskstore.TaskStore
}
Пакет gqlgen, кроме того, генерирует пустые методы-обработчики, код которых нам нужно написать. Для большинства распознавателей это — очень простой код. Например — такой:
func (r *queryResolver) GetAllTasks(ctx context.Context) ([]*model.Task, error) {
return r.Store.GetAllTasks(), nil
}
Обратите внимание на то, что наш распознаватель возвращает полный список задач. Возможности GraphQL по выбору конкретных полей (или защита от избыточных данных) реализована в коде, сгенерированном gqlgen. Насколько я понял, в распознавателе нельзя узнать о том, какие именно поля нужно вернуть в ответ на конкретный запрос, поэтому нам всегда нужно брать из базы данных всё, что может пригодиться. Возможно, это — ограничение gqlgen, или, может, это — особенность всех GraphQL-серверов — точно этого я не знаю. Если описать это языком SQL, то окажется, что нам предлагается всегда выполнять запрос вида
select * from ..., а не запрос, нацеленный на конкретные поля. После того, как наш распознаватель вернёт GraphQL-движку эти данные, движок отправит в ответ на запрос только поля, которые нужны клиенту.И, наконец, gqlgen генерирует функцию
main в файле server.go, код которой мы можем отредактировать:func main() {
port := os.Getenv("PORT")
if port == "" {
port = defaultPort
}
resolver := &graph.Resolver{
Store: taskstore.New(),
}
srv := handler.NewDefaultServer(generated.NewExecutableSchema(generated.Config{Resolvers: resolver}))
http.Handle("/", playground.Handler("GraphQL playground", "/query"))
http.Handle("/query", srv)
log.Printf("connect to http://localhost:%s/ for GraphQL playground", port)
log.Fatal(http.ListenAndServe(":"+port, nil))
}
Здесь
handler.NewDefaultServer — это GraphQL-сервер, он регистрируется по пути /query. Мы можем добавить тут больше путей, например — можно даже смешать REST и GraphQL.Интерактивная среда для экспериментов с GraphQL-сервером
Одна из самых замечательных возможностей GraphQL — это интерактивная среда (playground), благодаря которой эксперименты с сервером, проводимые прямо из браузера, превращаются в очень приятное и простое занятие. В вышеприведённом серверном коде можно заметить регистрацию
playground.Handler, предназначенного для обслуживания корневого пути. Он даёт доступ к одностраничному приложению, называемому graphql-playground. Вот как оно выглядит.
Приложение graphql-playground
Как видите, я, в левой панели, ввёл запрос, о котором рассказывал выше, а после того, как он был выполнен, данные, возвращённые сервером, были выведены в правой панели. Интерактивная среда поддерживает подсветку синтаксиса, автозавершение ввода, позволяет открывать множество вкладок и даже умеет «переводить» запросы в команды
curl, что пригодится в том случае, если подобные команды планируется использовать в тестировочных скриптах.Сравнение GraphQL и REST
Если анализировать лишь общую картину, то у GraphQL имеются очевидные преимущества перед REST. В частности — в области эффективности, в ситуациях, когда избыток или недостаток данных может сделать работу с REST API далёкой от оптимальной. Но подобная гибкость GraphQL не бесплатна. А именно — благодаря ей можно, без особых проблем, отправлять на серверы произвольные и очень сложные GraphQL-запросы, то есть — организовывать DoS-атаки. Но, конечно, есть рекомендации, следование которым помогает разработчикам GraphQL-серверов избегать подобных неприятностей.
GraphQL — это развивающаяся технология. Вместе с ней развивается и множество интересных инструментов. Например — вышеописанная интерактивная среда. Но технология REST существует гораздо дольше, GraphQL тяжело конкурировать с ней в плане w.r.t.-инструментов и универсальности. Так, практически любой сервер в наши дни обладает REST API, разработано множество инструментов для мониторинга, логирования, профилирования и разного рода исследований таких API. Технология REST, кроме того, очень проста — речь идёт об обычных путях, к которым обращаются через HTTP. Часто к ним можно обращаться с помощью простых curl-конструкций или из браузера. А технология GraphQL устроена сложнее, так как тексты GraphQL-запросов должны размещаться в телах POST-запросов.
Простота REST имеет далеко идущие последствия. В типичном веб-бэкенде REST-запросы обслуживаются SQL-запросами (часто — нетривиальными), отправляемыми к базам данных. А тот, кто пользуется GraphQL, вынужден пользоваться ещё и особым языком запросов, который в чём-то немного похож на SQL, а в чём-то сильно от SQL отличается, так как модель графов, на которой основана технология GraphQL, на самом деле, не соответствует той модели, на которой основаны реляционные базы данных. Опыт подсказывает мне, что, используя GraphQL, приходится держать в голове больше сведений, чем при использовании SQL. В частности, речь идёт о GraphQL-запросе и о том, как он «переводится» на язык реляционной базы данных, лежащей в основе системы хранения данных сервера. Перспективные проекты, вроде Dgraph (база данных, изначально рассчитанная на GraphQL, с бэкендом, основанным на графовых данных) и PostGraphile (система, которая автоматически строит соответствия между GraphQL и PostgreSQL) — это интересные разработки, за которыми стоит понаблюдать тем, кто интересуется GraphQL.
Ещё один момент, на который стоит обратить внимание, это — кеширование. REST хорошо уживается с HTTP-кешированием, так как эта технология, в основном, основана на идемпотентных GET-запросах. А вот у GraphQL, в этом смысле, всё не так благополучно, так как эта система, на уровне HTTP, не различает идемпотентные запросы на получение данных и запросы на изменение данных.
В итоге же можно сказать, что программисты либо ограничены тем, с какими системами им нужно взаимодействовать, либо (в редких приятных случаях) — имеют возможность выбирать технологии для новых проектов. В последнем случае стоит просто выбрать тот инструмент, который лучше всего подходит для конкретной задачи. И чем шире выбор — тем лучше.
Предыдущие части:
Разработка REST-серверов на Go. Часть 1: стандартная библиотека
Разработка REST-серверов на Go. Часть 2: применение маршрутизатора gorilla/mux
Разработка REST-серверов на Go. Часть 3: использование веб-фреймворка Gin
Разработка REST-серверов на Go. Часть 4: применение OpenAPI и Swagger
Разработка REST-серверов на Go. Часть 5: Middleware
Разработка REST-серверов на Go. Часть 6: аутентификация
Вы тут — Разработка REST-серверов на Go. Часть 7: GraphQL
Разработка REST-серверов на Go. Часть 2: применение маршрутизатора gorilla/mux
Разработка REST-серверов на Go. Часть 3: использование веб-фреймворка Gin
Разработка REST-серверов на Go. Часть 4: применение OpenAPI и Swagger
Разработка REST-серверов на Go. Часть 5: Middleware
Разработка REST-серверов на Go. Часть 6: аутентификация
Вы тут — Разработка REST-серверов на Go. Часть 7: GraphQL
Применяете ли вы GraphQL при создании Go-серверов?

