
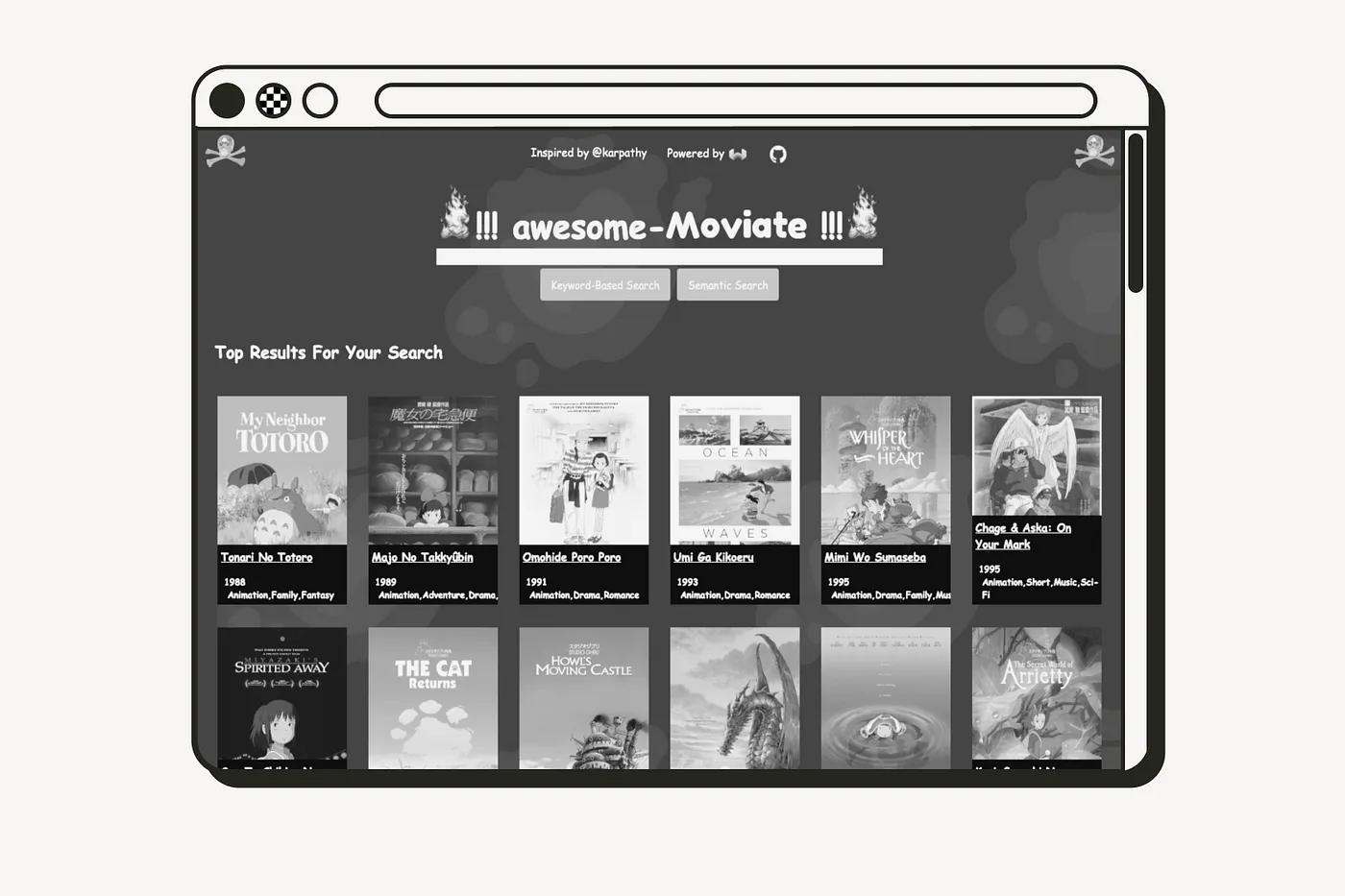
В апреле 2023 года Андрей Карпати, один из основателей OpenAI и бывший директор по ИИ в Tesla, поделился своим занятным проектом выходного дня – системой поиска и рекомендации кино.
Её пользовательский интерфейс откровенно прост и предлагает две основных функции: блок поиска, в котором можно искать кино по названию, и вывод списка из 40 похожих фильмов при клике по интересующему.
Несмотря на популярность этого проекта, Карпати, к сожалению, пока не поделился с публикой его исходным кодом.
И вот почему
 Источник
Источник
 Источник
ИсточникChaturvedi: «Может, откроете исходный код проекта?»
Andrej Karpathy: «Даже не знаю. Он такой страшный, что мне стыдно».
Так что запасайтесь попкорном и будем воссоздавать его сами на основе OpenAI и векторной базы данных!
 Сервис доступен на awesome-movies.life
Сервис доступен на awesome-movies.lifeЧто потребуется
Этот проект построен на четырёх основных компонентах:
- OpenAI-модель для генерации представлений (embeddings);
- векторная база данных Weaviate для хранения представлений, заполняемая скриптом Python;
- фронтенд: HTML, CSS, JS;
- бэкенд: NodeJs.
Получается, что для реализации этого проекта вам потребуется:
- Python для обработки данных и заполнения векторной БД;
- Docker и Docker-Compose для локального выполнения БД;
- Node.js и npm для локального выполнения приложения;
- ключ OpenAI API для доступа к модели OpenAI.
Реализация системы поиска фильмов
В этом разделе мы проанализируем проект Карпати и постараемся воссоздать его со всеми присущими ему особенностями. Для построения простого механизма поиска кино потребуется проделать следующее:
- подготовка: формирование датасета фильмов;
- шаг 1: генерация и сохранение представлений;
- шаг 2: поиск фильмов;
- шаг 3: получение рекомендаций похожих фильмов;
- шаг 4: запуск демо.
Весь код лежит в открытом виде на GitHub.
▍ Подготовка: формирование датасета фильмов
Проект Карпати индексирует 11 762 фильма, вышедших с начала 1970 года, включая описание сюжета и аннотацию из Википедии.
Чтобы получить нечто аналогичное, не прибегая к ручному скрейпингу Википедии, можно воспользоваться следующими датасетами с Kaggle:
- датасет с 48 000+ фильмов (лицензия: CC0: Public Domain) для столбцов
'id','name','PosterLink','Genres','Actors','Director','Description','Keywords'и'DatePublished'; - Wikipedia Movie Plots (лицензия: CC BY-SA 4.0) для столбца
'plot'.
Эти два датасета совмещаются по названию и году выпуска фильма, после чего отфильтровываются, оставляя картины, вышедшие после 1970. Все этапы предварительной обработки прописаны в файле
add_data.py. Полученный датафрейм содержит примерно 35 000 фильмов, среди которых около 8500, помимо аннотации, также сопровождаются описанием сюжета. 
Предварительно обработанный датафрейм фильмов
▍ Шаг 1: Генерация и сохранение представлений
Ключевым элементом этого демо-проекта выступают представления объектов данных о фильмах, которые используются в основном для вывода рекомендаций на основе сходства. В проекте Карпати для аннотаций фильмов и их сюжетов генерируются векторные представления. Реализовать это можно с помощью двух инструментов:
- Показатель «частота термина – обратная частота документа» (TF-IDF, Term Frequency-Inverse Document Frequency), который представляет простые биграммы и используется для определения частоты вхождений отдельных слов относительно общего набора слов документа.
- Модель генерации представлений
text-embedding-ada-002от OpenAI, которая используется для определения семантического сходства.
Помимо этого, сходство вычисляется на основе аннотации и сюжета фильма из Википедии с использованием для ранжирования одного из двух способов:
- метода k-ближайших соседей (kNN), использующий косинусное сходство;
- метода опорных векторов.
Для хорошей и быстрой базовой настройки Карпати предлагает комбинацию модели
text-embedding-ada-002 и kNN.И последнее, но не менее важное – как осмысленно ответил сам автор проекта, векторные представления сохраняются в
np.array:
Комментарий под оригинальным твитом
Hugh Anon: «А как вы сохраняли векторные представления?»
Andrej Karpathy: «Вnp.array. Сегодня люди зачастую спешат использовать нечто слишком навороченное».
В этом проекте мы также задействуем модель
text-embedding-ada-002 от OpenAI, но будем сохранять генерируемые ей представления в векторной базе данных.Если точнее, то в качестве опенсорсной векторной базы данных мы возьмём Weaviate. И хотя я мог бы поспорить, что векторные БД работают намного быстрее при сохранении представлений в
np.array, потому что используют векторное индексирование, будем честны: при нашем масштабе, измеряемом в тысячах, разницы в скорости вы не заметите. Основной причиной для использования здесь векторной БД стало то, что Weaviate имеет богатую и готовую к использованию функциональность вроде автоматической векторизации с помощью моделей генерации представлений.Первым делом, как показано в файле
add_data.py, вам нужно настроить клиента Weaviate, который будет подключаться к локальному экземпляру БД Weaviate. Помимо этого, нужно определить здесь ключ OpenAI API, чтобы можно было использовать интегрированные модули OpenAI.# pip weaviate-client
import weaviate
import os
openai_key = os.environ.get("OPENAI_API_KEY", "")
# Настройка клиента.
client = weaviate.Client(
url = "http://localhost:8080",
additional_headers={
"X-OpenAI-Api-Key": openai_key,
})Далее мы определим коллекцию данных под названием Movies для сохранения объектов данных о фильмах. Это будет аналогично созданию таблицы в реляционной БД. На этом шаге определяем в качестве векторизатора модуль
text2vec-openai, чтобы автоматически векторизовать данные при их импорте и запросе. А в настройках самого модуля прописываем использование модели представлений text-embedding-ada-002. Помимо этого, можете установить в качестве меры сходства косинусный коэффициент.movie_class_schema = {
"class": "Movies",
"description": "A collection of movies since 1970.",
"vectorizer": "text2vec-openai",
"moduleConfig": {
"text2vec-openai": {
"vectorizeClassName": False,
"model": "ada",
"modelVersion": "002",
"type": "text"
},
},
"vectorIndexConfig": {"distance" : "cosine"},
}Далее определяем свойства объектов данных фильмов и выбираем, для каких из них генерировать представления. В приведённом ниже фрагменте кода видно, что для свойств
movie_id и title представления не генерируются, так как для модуля векторизации установлено "skip" : True. Дело в том, что нам нужно генерировать представления только для description и plot.movie_class_schema["properties"] = [
{
"name": "movie_id",
"dataType": ["number"],
"description": "The id of the movie",
"moduleConfig": {
"text2vec-openai": {
"skip" : True,
"vectorizePropertyName" : False
}
}
},
{
"name": "title",
"dataType": ["text"],
"description": "The name of the movie",
"moduleConfig": {
"text2vec-openai": {
"skip" : True,
"vectorizePropertyName" : False
}
}
},
# Сокращено...
{
"name": "description",
"dataType": ["text"],
"description": "overview of the movie",
},
{
"name": "Plot",
"dataType": ["text"],
"description": "Plot of the movie from Wikipedia",
},
]
# Создание класса
client.schema.create_class(movie_class_schema)Наконец, определяем пакетную обработку для заполнения векторной базы данных:
# Настройка пакетной обработки для ускорения импорта
client.batch.configure(batch_size=10)
# Импорт данных
for i in range(len(df)):
item = df.iloc[i]
movie_object = {
'movie_id':float(item['id']),
'title': str(item['Name']).lower(),
# Сокращено...
'description':str(item['Description']),
'plot': str(item['Plot']),
}
client.batch.add_data_object(movie_object, "Movies")▍ Шаг 2: поиск фильмов
В проекте Карпати функция поиска работает по ключевым словам, сопоставляя запрос с названиями фильмов и выдавая максимально совпадающие результаты. Когда некоторые люди начали писать, что ожидали возможность семантического поиска фильмов, Карпати согласился, что это бы стало хорошим дополнением проекта:

Комментарий под оригинальным твитом
Andrej Karpathy: «К сожалению, сейчас поиск работает только для конкретных фильмов. Потенциально есть возможность выполнять поиск по содержимому, потому что вы можете встраивать запрос и искать в соответствии с ним. Это бы стало хорошим дополнением. Я вкратце протестировал эту возможность в консоли, но в интерфейс не добавлял, так как она показалась мне слегка недоработанной».
В текущем же проекте файле
queries.js реализуется три вида поиска:- поиск по ключевым словам (BM25);
- семантический поиск;
- гибридный поиск, представляющий комбинацию двух предыдущих.
Каждый из этих механизмов поиска будет возвращать
num_movies = 20 фильмов со свойствами ['title', 'poster_link', 'genres', 'year', 'director', 'movie_id'].Для включения поиска по ключевым словам используйте запрос
.withBm25() по свойствам ['title', 'director', 'genres', 'actors', 'keywords', 'description', 'plot']. При этом свойству 'title' можно придать больший вес, указав 'title^3'.async function get_keyword_results(text) {
let data = await client.graphql
.get()
.withClassName('Movies')
.withBm25({query: text,
properties: ['title^3', 'director', 'genres', 'actors', 'keywords', 'description', 'plot'],
})
.withFields(['title', 'poster_link', 'genres', 'year', 'director', 'movie_id'])
.withLimit(num_movies)
.do()
.then(info => {
return info
})
.catch(err => {
console.error(err)
})
return data;
}Чтобы включить семантический поиск, используйте запрос
.withNearText(). Он будет автоматически векторизовать содержимое поискового запроса и находить в векторном пространстве максимально подходящие фильмы.async function get_semantic_results(text) {
let data = await client.graphql
.get()
.withClassName('Movies')
.withFields(['title', 'poster_link', 'genres', 'year', 'director', 'movie_id'])
.withNearText({concepts: [text]})
.withLimit(num_movies)
.do()
.then(info => {
return info
})
.catch(err => {
console.error(err)
});
return data;
}Для включения гибридного поиска используйте запрос
.withHybrid(). Параметр alpha : 0.5 означает, что поиск по ключевым словам и семантический поиск имеют равный вес.async function get_hybrid_results(text) {
let data = await client.graphql
.get()
.withClassName('Movies')
.withFields(['title', 'poster_link', 'genres', 'year', 'director', 'movie_id'])
.withHybrid({query: text, alpha: 0.5})
.withLimit(num_movies)
.do()
.then(info => {
return info
})
.catch(err => {
console.error(err)
});
return data;
}▍ Шаг 3: Получение рекомендаций похожих фильмов
Для получения рекомендаций похожих фильмов используйте поисковый запрос
.withNearObject(), как показано в файле queries.js. Передавая id фильма, запрос возвращает из векторного пространства num_movies = 20 фильмов, наиболее соответствующих указанному.async function get_recommended_movies(mov_id) {
let data = await client.graphql
.get()
.withClassName('Movies')
.withFields(['title', 'genres', 'year', 'poster_link', 'movie_id'])
.withNearObject({id: mov_id})
.withLimit(20)
.do()
.then(info => {
return info;
})
.catch(err => {
console.error(err)
});
return data;
}▍ Шаг 4: запуск демо
Наконец, заворачиваем всё аккуратно в веб-приложение в культовой стилистике GeoCities из 2000-х (не стану утомлять вас деталями фронтенда) и вуаля! Всё готово!
Для локального запуска демо клонируйте репозиторий GitHub.
git clone git@github.com:weaviate-tutorials/awesome-moviate.gitПерейдите в каталог демо и настройте виртуальную среду.
python -m venv .venv
source .venv/bin/activateУстановите в ней переменные среды для
$OPENAI_API_KEY. Также для установки всех необходимых зависимостей выполните в этом каталоге следующую команду:pip install -r requirements.txtТеперь для локального запуска Weaviate через Docker установите
OPENAI_API_KEY в файле docker-compose.yml и выполните:docker compose up -dНастроив экземпляр Weaviate, запустите файл
add_data.py для заполнения векторной базы данных.python add_data.pyЧтобы запустить приложение, установите все необходимые модули.
npm installПосле этого для его локального запуска просто выполните следующую команду:
npm run startТеперь можете начинать пользоваться вашим приложением по адресу
http://localhost:3000/.Обобщение
В этой статье мы воссоздали проект Андрея Карпати, реализовав систему рекомендаций фильмов. Ниже я прикрепил короткое видео этого проекта в действии:
Сервис доступен на awesome-movies.lifeВ отличие от оригинала, в моей системе поиска для хранения представлений используется векторная база данных. Кроме того, я расширил её функциональность, включив семантический и гибридный варианты поиска.
Поэкспериментировав с этим механизмом, вы заметите, что он не идеален. Как отметил сам Карпати:
«Работает неплохо, но требует некоторой настройки».
Как я уже писал, исходный код доступен на GitHub, так что можете дополнить его своими идеями.
В качестве возможных доработок можно поиграться с векторизацией различных свойств, изменить развесовку между поиском по ключевым словам и семантическим поиском, а также заменить модель генерации представлений опенсорсной альтернативой.
Скидки, итоги розыгрышей и новости о спутнике RUVDS — в нашем Telegram-канале ?

