Комментарии 381
Я считаю, что лучше сохранять достоверность истории.
то есть вся проблема решается запретом на пуш с форсом в мастер, нет? Это как по мне логично. Но вот в моем фичабрэнчике или локально — что плохого в ребейзе, если в ремоут все будет как если бы мы этим самым ребейзом никогда не пользовались?
Но нет никаких причин бояться их.
Trunk-based development?
то есть вся проблема решается запретом на пуш с форсом в мастер, нет?
Нет, это вообще не решает проблему. Допустим на локальном компьютере 10 коммитов. Программист делаем rebase на мастере и 5 из этих коммитов становятся поломаны. В 11 коммите он чинит поломку и делает push. force при этом пуше не нужен, всё пройдёт хорошо и битые коммиты окажутся в условно главном репозитории.
если в ремоут все будет как если бы мы этим самым ребейзом никогда не пользовались?
Не будет коммитов, которые явно ломают сборку?
Trunk-based development?
Это вы к чему? Так выглядит одна ветка, если в неё мёржили другие. Это не обязательно master.
Допустим на локальном компьютере 10 коммитов. Программист делаем rebase на мастере и 5 из этих коммитов становятся поломаны
А с какого перепугу 5 стали поломаны?
В 11 коммите он чинит поломку и делает push. force при этом пуше не нужен
Если из 10 коммитов хотя бы один был на сервере, то нужен
битые коммиты окажутся в условно главном репозитории.
Но в локальной ветке. Потом программист сквошит коммиты и вливает одним merge чистенький и исправленный коммит.
One feature — one commit
Не будет коммитов, которые явно ломают сборку?
squash/fixup
А с какого перепугу 5 стали поломаны?
Этому вопросу посвящена немаленькая часть статьи :). Чтобы не быть голословным цитирую кусочек.
Допустим, мы удалили из master зависимость, которая всё ещё используется в feature. Когда feature перебазируется в master, первый переприменённый коммит сломает вашу сборку, но если не будет конфликтов слияния, то процесс rebase продолжится. Ошибка из первого коммита останется во всех последующих, положив начало цепочке битых коммитов.
Вот
Если из 10 коммитов хотя бы один был на сервере, то нужен
Ну вроде очевидно, что я говорю о ситуации, в которой на сервере нет ни одного из этих коммитов.
One feature — one commit
И таким образом программист прибьёт историю и понять какой код для чего коммитили будет непросто я против такого подхода.
Вот
А без rebase после merge ошибка переедет в master — это просто восхитительно. Если же имеется в виду, что мы делаем git merge master, то ситуация никак не меняется, потому что после обратного merge в мастер у нас будет 10 битых коммитов и один merge commit с исправлениями. Вопрос: зачем нужны в истории 10 коммитов с ошибкой? Чтобы увлекательнее было лазить по коду с git bisect?
И таким образом программист прибьёт историю и понять какой код для чего коммитили будет непросто я против такого подхода
С такой историей лучше уж никакой истории. Она только дичайше засоряет git log
Если же имеется в виду, что мы делаем git merge master, то ситуация никак не меняется, потому что после обратного merge в мастер у нас будет 10 битых коммитов и один merge commit с исправлениями.
Нет, у нас будет 10 нормальных коммитов и, возможно один плохой сразу после мёржа.
Вопрос: зачем нужны в истории 10 коммитов с ошибкой?
10 коммитов с ошибкой могут появиться из-за rebase. Они, конечно, никому не нужны и поэтому rebase лучше избегать.
С такой историей лучше уж никакой истории. Она только дичайше засоряет git log
Я редко смотрю историю, чтобы получить понимание, как менялся код коммит за коммитом. Мне интересно увидеть что происходило в отдельном конкретном коммите. Для этого коммиты должны быть простыми и понятными.
Нет, у нас будет 10 нормальных коммитов и, возможно один плохой сразу после мёржа.
Лол. Ну как так-то? Зависимость в мастере убрана ДО мерджа фичи. Фикс делался в самом конце. Следовательно все коммиты до мерджа с мастером будут нерабочими.
10 коммитов с ошибкой могут появиться из-за rebase. Они, конечно, никому не нужны и поэтому rebase лучше избегать.
Даже если все 10 коммитов будут сбойными, то rebase для того и создан, чтобы потом сделать fixup и получить на выходе один правильный коммит.
Я редко смотрю историю, чтобы получить понимание, как менялся код коммит за коммитом. Мне интересно увидеть что происходило в отдельном конкретном коммите. Для этого коммиты должны быть простыми и понятными.
Это нужно один единственный раз: во время code review. После этого все коммиты должны быть засквошены и смерджены.
Лол. Ну как так-то? Зависимость в мастере убрана ДО мерджа фичи. Фикс делался в самом конце.
После мёржа в мастер коммиты какими были в ветке, такими и остались. Вы думаете код и мастера в них как-то проникнет? :)
Следовательно все коммиты до мерджа с мастером будут нерабочими.
Они не изменятся.
Это нужно один единственный раз: во время code review. После этого все коммиты должны быть засквошены и смерджены.
Это приводит к проблемам с пониманием что и зачем комитили.
После мёржа в мастер коммиты какими были в ветке, такими и остались. Вы думаете код и мастера в них как-то проникнет? :)
Это шутка? Какая мне разница, что сам по себе коммит в вакууме рабочий? Если он накладывается на мастер, где уже убрана нужная зависимость и значит все, что было, начиная отсюда — не работает. до тех пор, пока не был сделан 11-й коммит, который исправлял положение, внесенное мастером.
Это приводит к проблемам с пониманием что и зачем комитили.
Никаких проблем с пониманием, если в мастер приезжает один единственный коммит с хорошим commit message и ссылкой на таск.
В отличие, кстати, от ситуации, когда в мастер приезжает 11 коммитов с непонятно какими сообщениями (вы не можете быть уверены, что за все время работы над таском разработчик ни разу не закоммитился с ничего не значащим сообщением типа "fixed")
Если он накладывается на мастер, где уже убрана нужная зависимость и значит все, что было, начиная отсюда — не работает. до тех пор, пока не был сделан 11-й коммит, который исправлял положение, внесенное мастером.
Думаю, тут непонимание того, что именно означает "удалили зависимость". В статье этот момент действительно крайне непонятен, все домысливают по-своему.
Я бы понял это (предельно конструктивно по отношению к автору) так: есть некоторое API, реализуется подключенной библиотекой; в мастере убрали использование этой библиотеки и одновременно, или вслед за этим, убрали подключение библиотеки. Если разработка feature опиралась на эту библиотеку, то коммиты после rebase будут несобираемыми. Вот после этого, согласно автору статьи, делают правку типа "а теперь уберём вызовы того, чего уже нет".
Так вот — неправ тут именно автор, потому что если он требует рабочей истории для всяких bisect, то уже в коммите dʹ надо было требовать собираемости и тестируемости. Да, это требует чуть большей работы. Требуется добавить коммит, условно говоря, dʹfix1, перебазировать его по истории сразу после dʹ и слить с ним (squash/fixup), получив некий dʺ. Аналогично со следующими промежуточными. И уже такая история приемлема для отправки "наверх".
Когда я работал через Gerrit, то это было основным моим вариантом. Он допускает и построение коммита на основе достаточно старых версий (что неизбежно приводило к merge), но вариант с rebase требовал работы всех промежуточных стадий.
Никаких проблем с пониманием, если в мастер приезжает один единственный коммит с хорошим commit message и ссылкой на таск.
А вот это очень часто диверсия и делать так не надо. Потому что создание новой фичи может означать, например,
- несколько подготовительных рефакторингов
- исправление багов, найденных при рефакторинге или просто вычитке кода
- наконец, добавление функциональности для фичи
и потом склеивать это в один коммит означает получить дурнопахнущую нечитаемую кашу.
что за все время работы над таском разработчик ни разу не закоммитился с ничего не значащим сообщением типа "fixed")
Да он может хоть 100500 раз так делать. Но на экспорт другим он должен дать цепочку простых и понятных действий с чётким описанием, как для посторонних. Именно цепочку, а не один коммит.
После мёржа в мастер коммиты какими были в ветке, такими и остались. Вы думаете код и мастера в них как-то проникнет? :)
На мой взгляд, вы не понимаете фундаментальное понятие «ветка в git». Ветка — это всего лишь ссылка на какой-то коммит. Алиас, указатель, ссылка — не принципиально. Главное, что у ветки нет коммитов. Удалите ветку, но коммиты останутся.
Что значит «код мастера»? Мастер — это ветка, у нее нет кода. У цепочки коммитов, начинающейся с коммита, на который ссылается мастер будет только один коммит, содержащий патчи, которые разработчик в своей ветке делал. Это будет мердж коммит. Он будет содержать проблему, и у него будет «второй родительский» коммит, который со всеми своими предками содержит проблему. И фиксить в мастере вы будете мердж коммит, а не ветку разработчика.
Нет, это вы не понимаете о чем вам говорят.
Допустим, есть вот такая двойная цепочка коммитов (более старые коммиты ниже):
H / \ F G | | D E | | B C \ / A
D и E скрыто конфликтуют, поэтому H содержит баг. Ни один другой коммит этого бага не содержит, потому что ни в каком коммите кроме H не присутствуют изменения внесенные D и E одновременно.
Именно это и говорит poxvuibr. А его оппонент, Yeah почему-то утверждает что после появления коммита H коммиты E и G тоже стали нерабочими. Как это так случилось — не спрашивайте, я тоже не понимаю.
А по каким коммитам и в какой последовательности пойдет git bisect в вашем примере?
Нет, это вы не понимаете о чем вам говорят.
Вы оспариваете только мою последнюю фразу, при этом заявляете, что я не прав в целом. Все что я сказал про бранчи — верно и «код мастера» — это чушь. А если Вы не согласны с утверждением про наследование проблемы, код коммитов D, E в студию, плиз.
Нет, я не оспариваю вашу последнюю фразу, я поясняю вам о чем тут вообще был спор.
В данном случае словами "мастер" и "фича" были обозначены те коммиты, которые писались в рамках этой ветки. Можно хоть 10 раз ветку удалить — коммиты от этого не пропадут, тут вы правильно заметили. Вот только разговор именно про коммиты и шел.
Процитированная вами фраза "После мёржа в мастер коммиты какими были в ветке, такими и остались" означает что после появления коммита H коммиты C, E, G не изменились, а потому если они ранее были классифицированы как "рабочие", они не могли оказаться нерабочими после выполнения merge.
«код мастера» — это чушь.
Под кодом мастера я имел в виду те коммиты, которые были в мастере до мёржа. Под кодом ветки — коммиты, которые были в ветке.
А если Вы не согласны с утверждением про наследование проблемы, код коммитов D, E в студию, плиз.
После мёржа коммиты, которые были в ветке не изменятся. Их можно будет чекаутить и спокойно собирать код. Ни один из них поломан не будет. Будет поломан мёрж коммит, но его можно поправить перед тем, как пушить.
После ребейза на основе этих коммитов будут созданы новые коммиты, которые будут содержать проблему. Потенциально каждый из них может оказаться несобираемым, поэтому для того, чтобы в апстриме не было битых коммитов возможно каждый из них придётся поправить руками.
чтобы в апстриме не было битых коммитов возможно каждый из них придётся поправить руками.
Т.е. переписать историю? Вы же вроде против этого.
Пример в студию.
Т.е. переписать историю? Вы же вроде против этого.
Но это придётся сделать, чтобы все коммиты были нормальными. Я как раз предлагаю так не делать :).
Правда, я не против переписывания истории, если коммиты не успели попасть в апстрим. Я против огромных коммитов. И ещё я против возни с проверкой коммитов, которые можно не проверять, если делаешь мёрж.
Пример в студию.
Сложно это :). Но давайте попробуем
В коммите H есть функция mult, которая принимает int и умножает на 2
int mult(int number) {
return number*2;
}В коммите G мы её используем в одном месте
return mult(res);В коммитах E и С используем в двух других местах, не связанных с местом в G.
А в коммите D в мастере стало понятно, что нужно добавлять множитель в параметры.
- int mult(int number) {
- return number*2;
+int mult(int number, int multiplier) {
+ return number*multiplier;
}Потом сделали ребейс ветки на B
И получили несобираемый код. Причём не собирается ни один коммит в ветке. Нужно каждый изменить.
Если делать мёрж из мастера, то можно изменить только мёрж коммит перед тем, как мёржить ветку в мастер.
В коммите H есть функция mult, которая принимает int и умножает на 2Замените «умножает на 2» (ну кому, в самом деле, такая функция нужна) на «умножает float'ы» и добавьте в вашем изменении в аргументы FPSCR (или MXCSR) — и вот у вас уже жизненный пример для эмулятора ARM'а или X86.
Как видим от искусственного примера до реального — даже не шаг, а полшага…
Но количество изменений по сути — одинаковое в случае rebase и merge.
При этом, в случае rebase они аккуратно оказались именно там, где вводится использование mult(), а в случае merge — они вообще непонятно где — их можно отловить только косвенно диффом между мастером и результатом мержа, в каше с другими 100500 изменениями.
Следовательно все коммиты до мерджа с мастером будут нерабочими.
Вот тут у вас логическая ошибка. При мерже локальной ветки в master, она должна быть заребейзена на мастер и пройти тесты.
И таким образом программист прибьёт историю и понять какой код для чего коммитили будет непросто я против такого подхода.
это является проблемой только если у вас фичи не дробятся достаточно. Если у вас один коммит = одна фича = изменение парочки файлов не вижу проблемы разобраться.
это является проблемой только если у вас фичи не дробятся достаточно.
Если получается хорошо дробить фичи — не вижу проблем с тем, чтобы сквашить коммиты. Но у меня размер фич обычно больше, чем парочка файлов. Что, конечно, не может не печалить.
А самостоятельно дробить на подзадачи? Интересует как у других принято, скажем, вам же никто не запрещает дробить фичи на более мелкие фича брэнчи? Или жесткая привязка к тикетам в джире? Если так — можно ли самостоятельно дробить на подтаски? Или в таком случае затык может случиться на других этапах жизни таски?
Интересует как у других принято, скажем, вам же никто не запрещает дробить фичи на более мелкие фича брэнчи?
Часто в мастер всё равно фичу можно вливать только одним куском. Мелкие фича бренчи делай, но в мастер попадёт только та, что соответствует большой фиче.
технические средства типа GIT так или иначе связаны с организационными моментами. Скажем вы используете те же фича брэнчи, зачем? С технической то точки зрения они не нужны, а нужны они лишь для того что бы изолировать изменения которые пока не могут считаться стабильными. Не является ли это переносом технических средств в организационные?
Я это к чему. Инструменты и практики призваны решать проблемы. Но зачастую проблемы как таковой и нет, и инструмент/практика выбираются по принципу "ну вроде так большинство делает".
В этом отношении больше всего меня бесят любители всяких там scrum of scrum. Такое ощущение что кроме скрама мир ничего не придумал.
У фича брэнчей есть преимущества по сравнению с одной веткой, удобнее разрабатывать и проверять результат. А разбивать одну задачу на три потому что «мы хотим один коммит на задачу» кажется мне лишней бюрократией.
удобнее разрабатывать и проверять результат.
За счет чего? А как же быть с тем фактом. что поскольку у нас есть несколько версий кода которые работают, нам всеравно придется делать повторный регрес при сливании веток ибо "оно может внезапно перестать работать".
Да и "одна ветка" — это целая куча подходов которые невилируют недостаток изоляции функционала. Начиная от feature toggle и заканчивая branch by abstraction.
А разбивать одну задачу на три потому что «мы хотим один коммит на задачу»
Я вопрос задавал не вам, меня конкретно интересовало насколько дают свободу разработчикам делать на их уровне дополнительную декомпозицию. Речь идет не о "один коммит на фичу" а "как сделать так что бы все фича брэнчи жили менее пары дней". Ибо если это возможно сделать, то можно дальше общаться на тему других подходов.
Вопрос. Сколько времени в среднем в день уходит на ревью? Сколько времени проходит в среднем от создания мердж реквеста до вливания ветки в основную? Как часто происходят конфликты? Что вы делаете если задача в целом протестирована но кто-то успел влить в основную ветку какие-то другие изменения и теперь у вас конфликты? происходит ли ретест после разруливания конфликтов? Происходит ли после этого повторное ревью (как никак то что раньше имело смысл может потерять его в связи с новыми изменениями).
p.s. из моего опыта — код ревью на этапе мердж реквеста показывает плохую эффективность, особенно в ситуациях когда команда может меняться (типичный аутсорс). Из того что пробовал — код ревью пост фактум + парное программирование с людьми которые запушили что-то не то намного больше выхлопа дает. Но это если есть такая возможность конечно.
Но в локальной ветке. Потом программист сквошит коммиты и вливает одним merge чистенький и исправленный коммит
Но что делать с ситуацией, когда спустя неделю требования поменялись и он понял, что изменения из 6,7,8 коммита уже не актуальны. Или, допустим, QA нашёл баг, который оказался именно в тех изменениях. В вашем случае ему будет сложнее откатывать(исправлять) изменения. А это, на самом деле, не такой редкий случай.
В 11 коммите он чинит поломку и делает push
- коммиты должны быть атомарны
- если у меня по какой-то причине есть 10 коммитов, которые я не хочу сквошить, то и ребейзить я их буду по одному, запуская тесты после каждого. Оно конечно может быть не удобно если у вас фичабрэнчи живут несколько дней в большой команде.
Не будет коммитов, которые явно ломают сборку?
если будут, это неплохой повод обсудить внутри команды вопрос координации. Они у вас так и так будут, просто реакция на это все будет разной.
Это вы к чему?
Нет мерджей — нет проблем с мерджами. А изолировать изменения можно не только фича брэнчами. Что вы скажем думаете о подходах с CI/CD?
коммиты должны быть атомарны
Атомарность не нарушается.
если у меня по какой-то причине есть 10 коммитов, которые я не хочу сквошить, то и ребейзить я их буду по одному, запуская тесты после каждого.
Чего ради мучаться, если можно сделать мёрж?
Чего ради мучаться, если можно сделать мёрж?
что бы не делать мердж. Ну то есть поясню. Последние несколько месяцев я перешел с фича брэнчей на trunk-based dev. просто потому что надоело следить за мердж реквестами. В целом этот процесс очень сильно замедлял процесс разработки и тестирования. Тем более что мы постепенно занимались еще и устранением технического долга и весьма масштабными рефакторингами (больше на уровне постоянного перемещения файлов по модулям, у нас все было плохо с декомпозицией проекта на ранних этапах)
В результате было принято решение всем работать в develop ветке и делать код фриз путем вмердживания (да да, merge --no-ff) в master для полноценного регрешен теста.
Тут сразу обусловлюсь что поскольку мы пишем чисто API и у нас есть мобилки, у меня по любому после каждого коммита должна быть соблюдена обратная совместимость. Так что с фича брэнчами или нет — мой флоу работы не сильно меняется с точки зрения разработки. Но это позволяет проще координировать действия между разработчиками (особенно когда их хотя бы больше 3-х и они не все сидят рядом), а в силу того что с одним и тем же кодом работает теперь больше людей (у нас увы покрытие кода тестами не такое большое как хотелось бы) — регрессии стали находить чаще и быстрее теми же силами.
Ну и поскольку все работают с develop и стараются пушить хотя бы один-два раза в день, намного удобнее отдельные коммиты подребейживать перед пушем, сквошить там и все такое.
В 11 коммите он чинит поломку и делает push.
Автор не осилил rebase interactive.
А bisect потом работает? git может понять, что все коммиты из фича ветки есть в мастере и ветках, отбранченных от мастера?
git может понять, что все коммиты из фича ветки есть в мастереА ему это не надо. фича мержится в мастер с параметром --squash, это значит, что будет все одним коммитом. А бисект вы можете посмотреть в ветке, если нужны конкретные коммиты фичи.
А ему это не надо. фича мержится в мастер с параметром --squash, это значит, что будет все одним коммитом.
Таким образом номальной истории у нас не будет и нормального bisect тоже. Я от этого отказываться не готов.
Нормальная история это такая история, с помощью которой можно понять что сделано в каждом коммите.
Разработчик работает над веткой. Тут он так писал, тут эдак, тут вообще рыбу заворачивал, тут новый фреймворк добавил, тут убрал. Зачем это в мастере?
Разработчик работает над веткой. Тут он так писал, тут эдак, тут вообще рыбу заворачивал, тут новый фреймворк добавил, тут убрал.
Коммиты лучше бы делать осмысленно.
Сильно много "лучше бы". И коммиты подавай вам осмысленные и сообщения о коммитах пиши красивые. Но реальная разработка — она не такая. Часто приходится что-то пробовать, что-то откатывать. К исходу дня в локальной ветке может быть 15-20 коммитов, некоторые из которых прямо противоположны предыдущим. Что тогда?
И коммиты подавай вам осмысленные и сообщения о коммитах пиши красивые.
И ещё хорошо бы код покрытый юнит тестами.
Часто приходится что-то пробовать, что-то откатывать.
Можно не комитить результаты проб и ошибок. Если закомитили — можно поправить историю.
А можно вообще не коммитить, пока таск не сделаешь. Зачем нужен git? Будем коммитить один раз, когда все уже точно готово. :)
Зачем нужен git?А вот на этот вопрос можно ответить совершенно точно: для того, чтобы можно было нарисовать красивую историю.
С небольшими, правильно выверенными, коммитами. С пониманием того, что, где и для чего делали. И с убранными «метаниями в поисках решения задачи».
Написание истории при работе с Git'ом (да даже и с SVN'ом) — такая же работа, как и написание кода.
Никто даже смотреть не будет на изменение в 1000 строк, которое вы предложите залить в Git (а разработка Git'а — это как бы эталонное применение Git'а, правильно?).
Его попросят разбить на части. Да-да, руками.
Считаю верхом безолаберности слать в мастер 100500 коммитов, где исправляются опечатки, форматирование, туда-сюда меняется реализация, «wip» коммиты. Никому не нужна вся эта драма.
Одна фича — один коммит — это тоже сказка и очень зависит от структуры проекта и того, как формулируются и детализируются фичи. Если, например, фичи высокоуровневые, их реализация может подразумевать изменения во многих подсистемах и логично оформлять изменения в разных подсистемах как отдельные коммиты.
Это же классика работы с гитом. У себя в локальной ветке можно делать что угодно. Но наружу надо отдавать красивую цепочку атомарных коммитов.
И тогда вы используете interactive rebase, объединяя коммиты в атомарные и красиво оформленные. И потом это мерджите/ребейзите в мастер.
Я буду читать предыдущие комменты до конца.
Вот для их осмысления и существует rebase. Или вы к модели водопада предлагаете вернуться?
Вот для их осмысления и существует rebase.
Тут речь шла про squash. Использовать rebase для генерации осмысленной истории можно, но только тогда, когда rebase делается для того, чтобы переставить коммиты или удалить какие-то. rebase на мастер осмысленности коммитам не добавляет. Squash тем более.
Или вы к модели водопада предлагаете вернуться?
Какое отношение модель водопада имеет к проблемам с rebase?
И squash и fixup вполне могут добавить осмысленности, Вы просто в каких-то розовых облаках витаете, где каждый коммит в рабочей ветке идеально продуман, логически выверен и не имеет ни единой опечатки. Отсюда и связь с водопадом, потому что на практике такое корпение над каждым коммитом в рабочей ветке — это пустая трата времени.
Объединение всех коммитов фичи в 1 — иногда оправдано, иногда — нет, но в целом если в ветке после rebase осталось больше 7 коммитов, то у вас что-то не так с определением границ фич.
Коммиты лучше бы делать осмысленно.
Так это одна из причин, почему стоит использовать rebase. Пишите код, не задумываясь о истории, делайте коммиты с сообщениями "tmp", "Foo", "debug", "watafak". А когда созреете — git rebase -i, и причесываете историю.
Покуда мастер билдится в каждый момент времени всё хорошо. То есть нерабочая ветка быть может где-то в середине, но не перед мержем в мастер. И да, merge покрывает 100% задач и не вижу никакой причины почему бы пользоваться чем-то другим. Разрезолвить все конфликты за раз лично мне например намного проще, чем покоммитно.
Смысла делать «красивую историю» нет, потому что это вранье.Может это и «враньё», но это единственный способ потом разобраться в том, что происходит.
Все успешные проекты рано или поздно переходят в состояние, когда 90% кода в них написано людьми, которые больше над проектом не работают (хотя бы потому, что люди смертны). Соотвественно спросить разработчиков о чём-либо нельзя. Что, в свою очередь, делает жизненно важным описание коммитов и понятность изменений, которые в этих коммитах были произведены. Ну а далее — всё просто: может у вас какие-нибудь супермены работают, я не знаю — но у нас не получается сразу «набело» все изменения делать, что при чтении промежуточных вариантов у читателя вопросов не возникало.
Но есть и альтернативное мнение (которого я придерживаюсь), которое состоит в том, что коммиты в feature-ветке — это поток мыслей разработчика пока он работал над веткой. На эти мысли многое может оказывать влияние: погода, настроение, успехи/неуспехи в личной жизни, разработчик может ставить эксперименты и попросту хулиганить. И я вполне допускаю, что он имеет на все это право. Но в конечном итоге мне нужна готовая фича, а не его поток мыслей. Мне нужна квинтэссенция таска, выраженная в коде. И поэтому это должен быть один красивый и рабочий (желательно) коммит с красивым описанием и ссылкой на баг-трекер. А поток мыслей пусть останется с разработчиком как часть его личности, отраженная в его личностных воспоминаниях. В гите это все не нужно. ИМХО
И поэтому это должен быть один красивый и рабочий (желательно) коммит с красивым описанием и ссылкой на баг-трекер.И что вы будете делать с этим коммитом на 10000 строк, если он вам что-нибудь поломает?
Я исхожу из того, что разработчики ядра используют git, в некотором смысле, эталонным образом. И вот у них одна фича почти никогда не бывает одним commit'ом. Обычно её просят разбить на лёгкие для понимания преобразования кода. Вот тут — мы добавили новый аргумент класс. Пустой пока. Тут — реализовали новую функциональность. Тут — исправили одного клиента. Там — второго. И в коммите номер 25 — удалили старую функциональность.
Тогда в случае необходимости — можно сделать
git bisect до небольшого, обозримого изменения. А не ковыряться в здоровенном изменении, которое в некоторых файлах может менять до 60% строк.Неважно, сколько строк затронула фича. Важно какой процент от codebase это составило. Если 10000 строк — это 1% от всего проекта, значит это небольшая фича, которая отлично просматривается в истории. И да, при таком объеме кода эта фича должна быть полностью покрыта тестами, которые делают крайне маловероятной ситуацию "все поломалось". А если 10000 строк — это 50%+ вашего проекта, то это значит, что кто-то не умеет дробить фичи на части. Это уже не фича, а переписывание половины проекта и такого коммита, конечно же быть не должно. Но вторая ситуация встречается только у не слишком умных или дисциплинированных разработчиков, которые привыкли всю разработку вести в одной ветке, временами мерджа ее в мастер и продолжая дальше. Излишне говорить, что это пагубная практика и от нее нужно избавляться весьма решительным образом.
На практике самое ужасное, что происходит — исчезновение «строительных лесов». То есть, грубо говоря, если вы переходите с BLAS на Eigen — то вы врял ди сделаете это за один день. Скорее всего вы сначала сделаете прослойку, которая позволит вам выбирать между BLAS и Eigen'ом (пусть даже она приведёт к повышенному расходу памяти и замедлению работы), потом, постепенно, переведёте всё с одной библиотеки на другую — ну и в самом конце «прослойку совместимости» (которая более не нужна и теперь только мешает) уберёте.
Так вот если вы этот процесс «схлопните» — то у вас и следов от этого промежуточного варианта не останется и в случае если тесты что-то не покрыли и у вас случится регрессия вам нужно будет сравнивать два весьма и весьма сильно отличающися варианта, либо, как альтернатива — вам придётся «возвести леса» заново.
Ну и какой тогда смысл в хранении истории, если ключевые моменты в ней прописаны недостаточно подробно для поиска ошибок?
Неважно, сколько строк затронула фича. Важно какой процент от codebase это составило. Если 10000 строк — это 1% от всего проекта, значит это небольшая фича, которая отлично просматривается в истории.Гениально! Вы всерьёз считаете, что вот этот вот patch на 90 мегабайт — можно разбить на десяток «небольших фич, которые будут отлично просматриваться в истории»? Там изменено всего-то 5% проекта. Какие-то жалкие 59806 файлов изменены. Подумаешь. Мелочь какая. Даёшь change'и на 100000 строк каждый!
Ну бред же! Размеры коммитов и фич должны разумно соотноситься с человеческими возможностями, а не с размерами проекта!
И да, при таком объеме кода эта фича должна быть полностью покрыта тестами, которые делают крайне маловероятной ситуацию «все поломалось».Как показывает практике «полное покрытие тестами» ни разу не гарантирует, что у вас всё будет работать правильно — при условии, что у вас задача нетривиальна и в ней много взаимозавимимостей.
Это уже не фича, а переписывание половины проекта и такого коммита, конечно же быть не должно.Опять-таки? С чего вы взяли? Если у вас был проект, помогающий вам «пасти котов» и там, через строчку, были классы «Cat», «CatBehavior» и тому подобные — а вы решили поддержать ещё и собак, то у вас легко может измениться половина строк в проекте из-за появления классов (интерфейсов в Java) «Animal», «AnimalBehavior» и тому подобное.
На этом фоне жалкая горстка изменений, вводящих класс Dog- просто «утонут». И понять — где случился косяк и почему у нас собаки всё ещё имеют втягивающиеся когти будет не проще с историей, чем без неё, просто исследую код. Нафига такая история кому нужна???
Но вторая ситуация встречается только у не слишком умных или дисциплинированных разработчиков, которые привыкли всю разработку вести в одной ветке, временами мерджа ее в мастер и продолжая дальше.Нет, такая ситуация встречается у нормальных разработчиков тоже. Переписывание половины проекта в рамках реализации одной фичи — всречается редко. А вот переписывание какого-нибудь файла целиком (или почти целиком) — очень даже. И если бы Alex Deucher (добавивший в вышеупомянутую «маленькую фичу на миллион строк добрые 300'000 оных строк) не разделял механические коммиты и „реальные“, то разобраться в этой каше не смог бы никто и никогда…
Гениально! Вы всерьёз считаете, что вот этот вот patch на 90 мегабайт — можно разбить на десяток «небольших фич, которые будут отлично просматриваться в истории»? Там изменено всего-то 5% проекта. Какие-то жалкие 59806 файлов изменены. Подумаешь. Мелочь какая. Даёшь change'и на 100000 строк каждый!
Что, вот правда не видим разницы между тэгом версии и коммитом фичи/фикса? Если нет, то гуглим linux 4.12 changelog и внимательно считаем количество фиксов и фич в этом релизе. Вот именно столько должно было быть коммитов, а не один, десяток или 42. One feature — one commit
Как показывает практике «полное покрытие тестами» ни разу не гарантирует, что у вас всё будет работать правильно — при условии, что у вас задача нетривиальна и в ней много взаимозавимимостей.
А типа merge вместо rebase гарантирует?
Опять-таки? С чего вы взяли? Если у вас был проект, помогающий вам «пасти котов» и там, через строчку, были классы «Cat», «CatBehavior» и тому подобные — а вы решили поддержать ещё и собак, то у вас легко может измениться половина строк в проекте из-за появления классов (интерфейсов в Java) «Animal», «AnimalBehavior» и тому подобное.
Да, и эта функциональность должна быть разбита на несколько фич. Как минимум вынесение общей логики в абстрактные классы — отдельной фичей.
И если бы Alex Deucher (добавивший в вышеупомянутую «маленькую фичу на миллион строк добрые 300'000 оных строк) не разделял механические коммиты и „реальные“, то разобраться в этой каше не смог бы никто и никогда…
Смотрим выше, чем отличается версия от фичи.
А типа merge вместо rebase гарантирует?Merge без squash гарантирует, что у вас останется достаточно истории, для того, чтобы найти проблему.
Если нет, то гуглим linux 4.12 changelog и внимательно считаем количество фиксов и фич в этом релизе.Я правильно вас понял: для того, чтобы понять что должно быть фиксов или коммитом — нужно купить машину времени, заглянуть в будущее и посмотреть на то, что попало в trunk? А без машины времени — никак? Linux 4.12 changelog — это же просто список всех коммитов в ядро, не больше, не меньше.
Да, и эта функциональность должна быть разбита на несколько фич. Как минимум вынесение общей логики в абстрактные классы — отдельной фичей.Идея понятна. Вот только в списке фич какого-нибудь ядра 4.12 фичи «рефакторинг интерфейса DRM» вы не найдёте. Драйвер для Radeon RX Vega — да. А вот какой-нибудь «drop definitions of removed ION_IOC_{FREE,SHARE} ioctls» вы там в качестве отдельной фичи вы вряд ли увидите. Это — часть исправлений в драйвере ION'а, на отдельную фичу, оно, я извиняюсь, «не тянет».
Смотрим выше, чем отличается версия от фичи.Смотрим, смотрим. Пока совет выглядит так: чтобы узнать что есть фича, а что — нет, слетайте-ка в будущее да посмотрите на список коммитов.
Отличный совет, только на практике он слабо применим.
все упирается в понятие "цельный рабочий функционал". Вы же как-то смогли разбить работу на несколько коммитов. Скорее всего даже в каждом коммите присутствовал какой-то функционал.
Но все разработчики коммитят в ветку, которая после того, как все завершили — должна собраться и функционал должен заработать.
И уже после этого идет мерж в мастер или куда-то еще.
Но количество коммитов в ветке, пока все заработает — никак не ограничено. Может разработчик решил запушить, потому что конец рабочего дня, может потому что ему пришлось переключиться на что-то другое, а этот функционал будет продолжать делать другой разработчик — не суть важно. Никто не привязывается к коммитам, привязываются к ветке.
Единственное правило — в одном коммите идет работа только по одному тикету, commit message соответственно номер только одного тикета — тогда при кроссчеке все отслеживается.
нужно изменить бэкэнд, фронтэнд и что-то в структуре базы.
изменения в базе сделать с учетом обратной совместимости в большинстве случаев возможно (особенно если речь идет о фичах которые делаются хотя бы за рабочую неделю).
бэкэнд так же можно пилить спокойно и вливать в мастер отдельно, так как если это что-то новое (новый эндпоинт, новое поле и т.д.) мы точно знаем что мы ничего не сломали.
Фронтэнд — тут сложнее. Лично мне нравятся фичатоглы, как минимум потому что можно помимо простой изоляции функционала делать еще и a/b тестирование, а так же иметь возможность быстренько отключить свежий функционал. Ну или возможность держать бета тестеров на продакшене.
Но да, все это будет работать только при определенном покрытии кода тестами, сильно зависит от уровня команды и в целом есть проекты где не так уж сильно нужна высокая скорость доставки функционала.
Просто делается скрипт миграции данных из старой схемы в новую, или из старой структуры в новую, и все.
Понятно, что в зависимости от проекта бэкенд можно пробовать и вливать отдельно, но если это изменение связано с изменениями в базе, то отдельно никак не выйдет.
Поэтому, гораздо проще вливать не коммитами, а целиком готовой фичей, которая была уже протестирована на этой отдельной ветке.
P.S. Держать бета-тестеров на продакшене можно далеко не для всех приложений
Делать изменения в структуре базы с учетом обратной совместимости? В подавляющем большинстве случаев это не нужно.В аду для таких разработчиков есть отдельный котёл. Хотя это и часто применяемая практика. Что вы будете делать, если после миграции какая-то функциональность отвалилась? Что будут делать условные «тётеньки из бухгалтерии» я и так знаю — считать всё, что ваша база перестала считать на, условно, «счётах» — и желать вашей смерти. И они правы.
Грамотные up и down миграции в большинстве случаев покрывают случай "что-то отвалилось". Изменения в структуре с уч'том обратной совместимости нужны, прежде всего, имхо, для нулевого даунтайма при деплое.
Грамотные up и down миграции в большинстве случаев покрывают случай «что-то отвалилось».Случаи, которые этим покрываются — это случаи, когда все данные из новой версии могут быть безболезненно, без потери данных, помещены в старую. В этом случае миграции не должно было быть вообще — то есть в 90% случаев это просто «блажь».
В случае же если новая версия хранит что-то, чего старая версия хранить не умеет — down миграция приведёт к потере данных, что, в большинстве случаев, недопустимо.
В тяжёлых, запущенных случаях — можно сделать переход в два этапа: вначале перейти на новую структуру, где будет место для новой информации, но новой информации не будет, а потом — уже расширить функциональность без потери старых, проверенных, клиентов.
Но в любом случае — это должно быть исключительным, редким явлением, а не «нормой жизни»…
Случаи, которые этим покрываются — это случаи, когда все данные из новой версии могут быть безболезненно, без потери данных, помещены в старую. В этом случае миграции не должно было быть вообще — то есть в 90% случаев это просто «блажь».
Переносы колонок из одной таблицы в другую, денормализация путём слияния таблиц и так далее. Тут данные из новой версии могут без проблем быть перенесены в старую, но миграция всё же нужна. Правда, тут откат обычно совсем не проблема.
Плюс случаи, когда чиним поломанные данные. Всегда есть вероятность, что вместо того, чтобы починить, поломаем ещё сильнее. Поэтому надо иметь возможность откатиться к старой версии, про которую мы знаем, что там поломано.
Зачастую потеря данных вполне допустима при срочном откате. Грубо, добавили в профиль пользователя новое поле, создали миграцию, но что-то пошло не так на, например, фронте для старых пользователей, у которых этого поля нет, хотя данные пишутся для новых, и решили откатить мерж-коммит по этой фиче, в который и миграция входила. Что кто-то успел заполнить это поле — невелика потеря с точки зрения бизнеса, если подавляющее большинство пользователя с незаполненным ничего сделать не могут. Хотя, на доун миграции можно предусмотреть сохранение этих данных в отдельную таблицу.
В тяжёлых, запущенных случаях
Это обычная практика для проектов, где zero-downtime одно из основных требований. На первом этапе запуска фичи переходим на структуру где есть новая, но старая не удалена, старые клиенты пишут в старую, новые в обе, какие-то воркеры/триггеры дописывают в новую из старых. Когда убедились, что новые работают нормально, а старых не осталось, то тогда обновляем новых клиентов на версию, где пишут только в новую и когда обновлятся удаляем старую структуру.
Нормальная история это такая история, с помощью которой можно понять что сделано в каждом коммите.
Ага, удачи вам потом с cherry-pick'ом…
Ага, удачи вам потом с cherry-pick'ом…А какая с ним проблема? Git merge корректно разруливает ситуацию когда в обоих ветках было сделано одно и то же изменение (в частности если в одну из них был за-cherry-pick'ан CL из другой ветки). Вот если после этого делатьь git rebase — тогда может быть беда…
А потом чери-пикать это все в другую ветку.
А потом чери-пикать это все в другую ветку.Ну да… и?
Я отвечал на то что нужно комитить каждый чих, и не делать squash.Вот как раз если деть squash, то потом непонятно как cherry-pick'ать. Потому что у вас будут как вещи, которые нужны (скажем расширения в API для поддержки новой функциональности), так и вещи, которые не нужны (собственно сама новая функциональность с тестами и прочим) в одном огромном CL'е.
А как раз если CL'ей много и они небольшие, то проблемы сделать git blame (ну или git log если ситуация совсем тяжёлая) я не вижу. Вернее проблемы могут быть, конечно, но по сравнению с попытками выцепить из CL'я на несколько тысяч строк, и производящего рефакторинг и меняющемго API и добавляющего новую фичу и тут же подключающую её к frontend'у (а там, в свою очередь, могут и другие фичи потребоваться, чтобы можно было это всё использовать) маленький кусочек добавлющий в функцию новый аргумент — это не проблемы.
Вот как раз если деть squash, то потом непонятно как cherry-pick'ать.
Просто у вас примеры какие-то слишком «крайние». Я лично обычно придерживаюсь подхода одна фича — одна ветка.
Предположим нам в текущий релиз нужно добавить какую-то одну фичу.
Берем и чери-пикаем конкретно ее, а не 100500 мелких комитов (ситуация в которой накосячить гораздо проще)
меняющемго API и добавляющего новую фичу и тут же подключающую её к frontend'у
У вас АПИ и фронтэнд в одном репозитории лежат?
Предположим нам в текущий релиз нужно добавить какую-то одну фичу.Тут, я боюсь, мы с вами расходимся насчёт трактивки понятия «фича» и «добавить».
У вас АПИ и фронтэнд в одном репозитории лежат?Если честно подобные вопросы меня поначалу при обсуждении этой статьи просто удивляли до глубины души, но раз это регулярно повторяется, то… нет не все API и не весь фронтэнд лежат в одном репозитории — у нас есть кой-какие компоненты, которые лежат отдельно. Это ужасно неудобно и мы пытаемся с этим бороться с переменным успехом. До идеала таки далеко — в частности потому, что Git для этого несколько не приспособлен…
Но в общем и целом — да, конечно. Соотвественно для меня «добавление фичи» — это серия CL'ей, которые «протаскивают» фичу снизу доверху. А как иначе мы вообще можем говорить о «добавлении» какой-нибудь фичи, если её пользователь не видит?
По мне, достаточно того, что bisect найдёт "сломали, когда вмержили ветку". Дальше проверяем уже её (что, как правило, не понадобится, если ветка была на одну задачу).
Вот-вот… Сначала что-то монструозное пилят в отдельной ветке полгода, без единого ребейза на master… А потом rebase виноват в том, что надо несколько часов потратить на него для сохранения нескольких сотен коммитов :-)
Сначала что-то монструозное пилят в отдельной ветке полгода, без единого ребейза на master…
Да, мастер в ветку мёржат.
А потом rebase виноват в том, что надо несколько часов потратить на него для сохранения нескольких сотен коммитов :-)
rebase виноват в том, что коммиты выходят битыми. Такое впечатление, что вы не читали статью.
Статью то я читал… только она о каких-то вымышленных проблемах, которые мне за 8 лет использования rebase ни разу не встретились… Потому что по факту после rebase у вас остаётся всё такая же отдельная ветка, на которой вы всё так же запускаете тесты, и если что-то поломалось, то сначала выясняете в чём проблема, исправляете её, делаете ещё раз ребейз (начиная со второго раза это всегда легко), прогоняете тесты ещё раз, и убедившись, что всё работает, вливаете эту ветку в master.
Таким образом, битые коммиты после ребейз теоретически возможны, если прокралась какая-то ошибка, которая: 1) не мешает компиляции и запуску проекта; 2) не отлавливается тестами. Впрочем, сюрприз, такую ошибку вы и после merge ещё не скоро заметите. Только с линейной историей отследить и исправить её будет гораздо легче, вот и вся разница.
P.S. Ребейз всегда делается интерактивный, ума ни приложу, кому и зачем может захотететься запустить его в неинтерактивном режиме.
отдельная ветка, на которой вы всё так же запускаете тесты, и если что-то поломалось, то сначала выясняете в чём проблема, исправляете её
Еще один довод поднять staging со сборкой на каждый PR. У нас такого пока нет, страдаем.
Ну, можно для начала CI настроить с прогоном тестов на каждый коммит (в любую ветку).
Хотя полный проект может и не надо собирать по PR, достаточно сделать такую сборку по кнопке и собирать только релизы.
По flow: делаем rebase в ветках PR, а в GitHub есть возможность «Squash and Merge» — классная штука, github.com/blog/2141-squash-your-commits.
Да, деплой на staging лучше всё-таки с ручным управлением оставить. Чтобы тестировщики сами могли определять, какую ветку они в текущий момент тестируют и она не изменилась случайно, только из-за того, что новый PR пришёл.
Полностью согласен с автором. Однако считаю rebase уместным для кейса, когда у тебя есть пара коммитов и нужно синхронизироваться с апстримом
git pull --rebaseДопустим, мы удалили из master зависимость, которая всё ещё используется в feature. Когда feature перебазируется в master, первый переприменённый коммит сломает вашу сборку, но если не будет конфликтов слияния, то процесс rebase продолжится.
Что-то я не понял чем вам здесь merge поможет?
Автор, думаю, имеет в виду, что если мёржить master в feature при необходимости (вместо rebase), то не будет лишних сломанных коммитов в истории. То есть при rebase может внезапно появиться коммит из серии "… а тут мы исправляем баг, из-за которого десять предыдущих коммитов даже не компилируются, потому что был rebase, но его тут не видно". Если же делать merge, то в явном виде будет сломанный merge commit и фикс сразу за ним (хотя история будет более кучерявая, это да).
Другое дело, не представляю, как работает по смерженным веткам bisect.
Я думаю, что эта проблема как раз не стоит, поскольку даже после rebase всё равно можно сделать merge --no-ff. Автор как-то всё вместе подаёт, но в целом это независимые вещи, можно делать rebase и иметь явные слияния.
Это уже другой вопрос, я в ответе повыше об этом написал. Автор до кучи ещё добавляет проблему линейной истории (и MonkAlex как раз об этом пишет, так что тут я отвечаю как раз на эту проблему — которая в общем-то не относится к проблеме сломанных коммитов).
Что значит "могут быть"? Конфликты будут ровно теми же самыми. Разница лишь в том, что при rebase конфликты разрешаются по-коммитно и соответственно — проще (практика "разделяй и властвуй"), а при merge — всё кучей. Как по мне, то при merge можно наделать не меньше, а даже больше ошибок.
Там речь не про конфликты слияния. Речь про то, что в мастере могли сделать изменения, которые конфликты слияния не вызывают, но код ломают. То есть, допустим, отключили библиотеку, которая была нужна. В результате rebase пройдёт нормально, коммиты накатит заново на обновлённый master, но компилироваться они не будут.
… я стесняюсь спросить, а в случае с мержом ситуация чем будет отличаться? Сделаем мерж, конфликта не будет, но компилироваться тоже не будет.
Тем, все коммиты, кроме коммита с мёржем — будут компилироваться.
… кроме коммита с мержом и всех последующих, вы хотели сказать? И чем это отличается от "будут компилироваться все коммиты до середины ребейза"?
(и это мы еще не затронули сценария, когда ребейз делается в фиче-ветке, а мерж делается с --no-ff, и тогда вообще не понятно, в чем разница)
кроме коммита с мержом и всех последующих, вы хотели сказать?
После мёржа запустим тесты и увидим, что код сломан и поправим.
это мы еще не затронули сценария, когда ребейз делается в фиче-ветке, а мерж делается с --no-ff, и тогда вообще не понятно, в чем разница
Я честно говоря не понял, что вы имеете в виду.
После мёржа запустим тесты и увидим, что код сломан и поправим.
… после ребейза запустим тесты, увидим, что код сломан, и поправим в том коммите, где сломалось. Ребейз надо делать не один раз, а столько, сколько надо для достижения результата.
Я честно говоря не понял, что вы имеете в виду
git checkout feature
git rebase master
git checkout master
git merge --no-ff featureНо я уже понял, что мы с вами говорили про мержи в разные стороны.
после ребейза запустим тесты, увидим, что код сломан, и поправим в том коммите, где сломалось. Ребейз надо делать не один раз, а столько, сколько надо для достижения результата.
Вот, кстати, да. Статья написана так, как-будто после rebase ветка сразу объединяется с master, хотя по факту (при адекватной разработке) слияние будет только после прохождения тестов в ребейзнутой ветке.
Как? Если не было конфликтов, как я вообще узнаю, что изменения в мастере поломали мою ветку???
Если не было конфликтов, как я вообще узнаю, что изменения в мастере поломали мою ветку???
Узнаете после прогона тестов или после того, как не скомпилируется код.
Другими словами, в случае rebase это обнаружится до вливания ветки в master, а в случае с merge — после. Вот и приехали.
В случае с rebase надо будет делать rebase много раз. В случае с мёржем — не придётся.
Повторный rebase — это тривиальнейшая процедура, уже без конфликтов в 99% случаев. Зато в master не будет ни одного битого (с т.з. тестов) коммита, а в случае с merge их так просто не избежать.
Главный аргумент статьи провалился из-за банального непонимания автора как правильно делать rebase. Из "бонусов" merge остались только уродливые merge-коммиты из master в ветку и обратно, которые типо интересно кому-то будет смотреть.
Повторный rebase — это тривиальнейшая процедура, уже без конфликтов в 99% случаев.
Зачем делать эту тривиальнейшую процедуру, если её можно и не делать?
Зато в master не будет ни одного битого (с т.з. тестов) коммита, а в случае с merge их так просто не избежать.
Откуда им взяться в случае c merge?
Зачем делать эту тривиальнейшую процедуру, если её можно и не делать?
Чтобы не было битых коммитов и чтобы была удобная в работе история коммитов.
Откуда им взяться в случае c merge?
Оттуда что сначала идёт merge, а потом уже проверка. И, как тут уже писали, придётся доп.коммит с исправлениями после merge делать.
Оттуда что сначала идёт merge, а потом уже проверка. И, как тут уже писали, придётся доп.коммит с исправлениями после merge делать.
Нет, не придётся. Нужно смёржить мастер в ветку, прогнать тесты, поправить код, сделать git commit --amend, а потом уже мёржить ветку в мастер. И не будет битых коммитов.
Чтобы не было битых коммитов и чтобы была удобная в работе история коммитов.
Вы вроде не выступаете за то, чтобы делать squash при мёрже? Видимо под удобной в работе историей вы имеете в виду линейную. Чем она удобна? В чём преимущество перед нелинейной?
Нужно смёржить мастер в ветку, прогнать тесты, поправить код, сделать git commit --amend, а потом уже мёржить ветку в мастер.
Ну вариант, да. Хотя лично для меня все эти мерджи master в ветку выглядят как какое-то дикое извращение.
Вы вроде не выступаете за то, чтобы делать squash при мёрже?
У меня нет строгого правила, что должен остаться обязательно 1 коммит, т.к. иногда удобнее сделать 3-5 коммитов в одной ветке, чем дробить это на 3-5 минифич. Но ветки по 100 коммитов, или как тут писали на 10000 значимо измененных строк, я не одобряю.
Видимо под удобной в работе историей вы имеете в виду линейную. Чем она удобна? В чём преимущество перед нелинейной?
Ну тут имхо очевидно. Что может быть проще прямой линии? Всё красиво и откатывать при необходимости можно фичи целиком, а не по 100 коммитов. Зачем засорять себе восприятие какими-то коммитами, которых по факту никогда не было в master? Чтобы найдя к-н опечатку вооружиться git bisect в поисках коммита, в котором она была сделана? Чтобы что? Чтобы revert сделать? А если там ещё изменения есть кроме той опечатки… И эти все пляски с бубном вместо того, чтобы за пару секунд исправить опечатку и закоммитить исправление? Или это так важно найти кто виноват и оштрафовать его на ползарплаты?
А если там ещё изменения есть кроме той опечатки… И эти все пляски с бубном вместо того, чтобы за пару секунд исправить опечатку и закоммитить исправление?
Возможно, Вы не работаете с историей изменений так, как можно было бы
Или это так важно найти кто виноват и оштрафовать его на ползарплаты?
Работая с «чужим» кодом, было бы неплохо знать для чего и почему он был написан. Вы приводите в пример опечатку, но ошибки в коде — далеко не всегда — опечатки, а знать, зачем, почему, кем и когда были внесены исправления — полезно.
Лично я буквально не так давно сталкивался, с таким:
1. я добавляю Assert, чтобы ограничить приход неверных данных от устройства, т.к. при них валится ошибка где-то в глубоком месте
2. через неделю этот Assert убирают, т.к. он валится, а то, что это приведёт к ошибке, из-за которой, собсна он был добавлен, никто не посмотрел. И лишь потому, что я просматривал diff'ы коммитов, я это заметил. Вот такая регрессия. А если бы включили мозг и посмотрели историю, в сообщении коммита прочли бы.
З.Ы. Да-да, тестов на этом проекте нет
Другой пример:
у нас был прокси-сервер, на котором мне нужно было сначала авторизоваться «ручками» (в веб-форме). Естественно, я написал скрипт, который curl'ом делает всё за меня, но после очередного обновления скрипт внезавно сломался (причём причинно-следственная связь, как Вы понимаете, была не прямая), в ходе муторной диагностики (https://sourceforge.net/p/curl/bugs/1099/) и благодаря git bisect стало понятно кто и почему виноват и, главное, как это исправить
Да-да, тестов на этом проекте нет
Тогда можно комментарии хотя бы писать. А то что толку от вашей истории коммитов, если assert всё равно убрали не глядя?
благодаря git bisect стало понятно кто и почему виноват и, главное, как это исправить
git bisect будет так же работать и в случае с rebase, тут разницы то принципиальной нет. Просто, имхо, вы преувеличиваете, что необходимость в этом возникает чуть ли не ежедневно.
а в вышеупомянутом моём случае — уверен, что assert бы убрали, а гипотетический комментарий — нет )
на самом деле, такую проблему бы решили тесты )) потому что «быстрое исправление (убрать assert)» не включая голову, решило бы текущую проблему, а тесты бы, сломавшись, заставили её включить…
а, как показывает сугубо мой опыт, без включения головы, ни «моя» история git, ни «ваш» комментарий — не помогают сколько-нибудь значимо, только «принуждение» (CI + тесты + хуки Git): когда без соблюдения формальных требований — сборка не проходит
Просто, имхо, вы преувеличиваете, что необходимость в этом возникает чуть ли не ежедневно
ну тогда Вы не поверите ))
…
а мой комментарий
… благодаря git bisect стало понятно...
был к Вашему
Зачем засорять себе восприятие какими-то коммитами, которых по факту никогда не было в master? Чтобы найдя к-н опечатку вооружиться git bisect в поисках коммита, в котором она была сделана? Чтобы что? Чтобы revert сделать? А если там ещё изменения есть кроме той опечатки… И эти все пляски с бубном вместо того, чтобы за пару секунд исправить опечатку и закоммитить исправление? Или это так важно найти кто виноват и оштрафовать его на ползарплаты?
повторюсь:
Вы приводите в пример опечатку, но ошибки в коде — далеко не всегда — опечатки,
уточню: я не противопоставил здесь rebase и merge и их «влиянию» на работу bisect
я акцентировал внимание на том, что Ваше «зачем искать почему написано ТАК, если проще просто исправить» — неприменимо, ИМХО, к не-опечаткам
Очевидно, что тесты лучше, но если у вас их нет, то за 5 минут их не добавишь. Но это ж кем надо быть, чтобы убрать строку, не прочитав комментарий рядом с ней?
я акцентировал внимание на том, что Ваше «зачем искать почему написано ТАК, если проще просто исправить» — неприменимо, ИМХО, к не-опечаткам
Да, но не-опечатки крайне редко тесты проходят… А вот в к-н строке опечатка может проскочить. Поэтому это единственная вероятная ситуация, которая мне пришла в голову для случая, когда ошибка не обнаружилась во время rebase. Конечно, бывают и более хитрые случаи, но весьма редко.
git commit --amendИмеется в виду мёрж из мастера в feature, я правильно понимаю? Принципиально ничем, просто будет только один сломанный коммит (вот этот самый merge commit), и следующий коммит с фиксом — видно где сломалось и почему сломалось. Если же был rebase (которого в истории не остаётся), то история будет выглядеть так, как будто разработчик сделал десять нерабочих коммитов, и только потом заметил, что ни один из них не компилируется.
Это если заметили, что сломалось, сразу после мержа. Это эквивалентно "заметили, что сломалось, сразу после ребейза" — и в этом случае полезно править именно тот коммит в ребейзе, который принес проблему, а не делать верхний. А если заметили сильно после, то пофиг уже, честное слово.
Это эквивалентно "заметили, что сломалось, сразу после ребейза" — и в этом случае полезно править именно тот коммит в ребейзе, который принес проблему, а не делать верхний.
Мёрж будет делать удобнее, чем возиться с переписыванием истории. Но, возможно, это на любителя.
То есть всегда делать ручной rebase, это имеется в виду? Останавливаться после каждого коммита при rebase и проверять? Признаться, я не видел, чтобы это часто делалось, да и процедура выглядит хрупко — репозиторий в середине rebase, какие-то коммиты из будущего в подвешенном состоянии, а мы что-то на живую правим. Или я не так понял?
P.S.: Мы, может, не так друг друга поняли? Тут речь по подмёрживание из master в feature, не про финал, когда мы в другую сторону мёржим.
То есть всегда делать ручной rebase, это имеется в виду?
Не всегда, а если после ребейза сломалось.
процедура выглядит хрупко — репозиторий в середине rebase, какие-то коммиты из будущего в подвешенном состоянии, а мы что-то на живую правим.
Если каждый коммит после себя давал рабочую систему (а это критичное условие для работы git bisect), то ничего особо хрупкого в этом нет.
Не всегда, а если после ребейза сломалось.
То есть — просто чтобы я понимал — процедура будет выглядеть как "сделали обычный rebase, проверили, если сломалось, то откатили rebase и начали ручной rebase, проверяя каждый коммит", я правильно себе это представляю? Как-то много аллегорических телодвижений получается.
процедура будет выглядеть как "сделали обычный rebase, проверили, если сломалось, то откатили rebase и начали ручной rebase, проверяя каждый коммит",
Еще проще. Сделали ребейз, проверили, не сломалось ли, затем сделали git bisect начиная с первого коммита фичи. Найдя коммит — правим его через (например, через git rebase -i).
А еще можно "сделали ребейз, прогнали тесты, сломалось — откатили ребейз, сделали мерж".
Как-то много аллегорических телодвижений получается.
Ну да, немало. Зато на выходе более читаемая история.
Я не говорю, что это решение на все случаи, но есть моменты, когда это удобнее.
Хм… bisect я использую настолько редко, что каждый раз приходится вспоминать как им пользоваться, поэтому, может быть, я предвзято сужу и мне кажется сложным. :) Но я понял подход, в принципе имеет смысл, если хочется хорошо читаемой истории.
Вообще, это больше позиция автора статьи, я не говорю, что есть единый правильный способ. Есть фичи-долгострои, есть фичи на два коммита, есть изменения в мастере, для которых можно посмотреть на дифф и почти с полной уверенностью сказать, что rebase ничего не сломает… Я в целом согласен, что между "использовать merge" и "использовать rebase" надо выбрать "использовать здравый смысл".
Хм… bisect я использую настолько редко, что каждый раз приходится вспоминать как им пользоваться
А в статье он приводится как аргумент.
Останавливаться после каждого коммита при rebase и проверять?
Для этого даже когда-то сделали параметр
--exec для git rebaseПроверить достаточно общий результат. А вот когда ошибка всплыла — имеет смысл исправить ее в том коммите который ее вызвал.
Так ведь Ричард Хипп написал fossil в том числе и чтобы избавится от rebase. Он однажды сказал, что в git историю пишут победители, а в fossil история такая, какая случилась в реальности.
И зачем вообще писать историю проекта если эта история будет причесана и раскрашена? Пользы от такой истории будет намного меньше, а правда всегда лучше, даже если и неприглядная.
И зачем вообще писать историю проекта если эта история будет причесана и раскрашена?
Затем, что далеко не всегда интересно, сколько раз я подмержил основную ветку в свою собственную.
Затем, что далеко не всегда интересно, сколько раз я подмержил основную ветку в свою собственную.
История, она пишется чтобы читать ее в будущем. Как можно знать кому и что будет интересно в будущем?
Как можно знать кому и что будет интересно в будущем?
Из опыта. После того, как неоднократно почитаешь собственные же ветки с постоянными мержами, начинаешь понимать, когда это полезно, а когда нет.
Интересна история, которая делает что-то полезное: вот фича, вот я её сделал, вот я её интегрировал, вот исправил баг, вот откатил, ибо уже не надо. А история: вот тут макет фичи, вот тут я что-то ещё дописал, вот тут я опечатался и исправил, вот комит, который я вообще не хочу объяснить ибо стыдно — не нужна от слова совсем.
Гораздо важнее не делать force илит rebase на ветку с которой идет сборка — в таком виде всегда очень четко понятно что было вчера и чего изменилось сегодня.
Практика показывает, что без squash/fixup 90% вашей истории будет состоять из коммитов типа:
- fixed
- updated
- 1
- lol
и т.д.
Это не умозрительное предположение, это — факт, который имел место в моей практике.
Практика показывает, что без squash/fixup 90% вашей истории будет состоять из коммитов типа
Нужно блюсти дисциплину :)
Тогда вылезет история, что большую часть времени программист будет выдумывать комментарии к комиту, или, что скорее всего, перейдет в svn режим, с редкими коммитами в общую репу.
Модифицировать историю нельзя, когда она есть не только на твоей машине и кто-то, кроме тебя комитит в ветку. Если ветка не прошла код ревью — можно разбить коммиты на части и сделать git push --force или, если --force нельзя, то удалить с сервера ветку и запушить её ещё раз с новой историей. Это никому не помешает.
Здесь обсуждается предложение никогда не модифицировать историю.
Если вы вливаете в свой репозиторий код «не глядя» — то вам уже ничего не поможет.
johnfound утверждал что приватную тоже нельзя модифицировать. Ему возразили что в таком случае будет либо куча коммитов без сообщений, либо "режим svn". И тут появляетесь вы, заявляя что проблема таких коммитов решается… модификацией истории!
Зачем вы продолжаете повторять очевидные вещи? Что и кому вы доказываете?
А что и кому пытаетесь доказать вы — я не знаю.
Даже приватную историю можно не модифицировать, а создавать новую. Грубо, делать не git checkout branch && git rebase master, а git checkout -b new-branch master && git merge --no-commit branch...
Опять же практика показывает, что в мастере должна быть дисциплина. Одна фича — один комит.
А моя практика показывает, что так нельзя, потому что потом тяжелее понять какой код для чего комитили.
Видно, что за чем, когда какие баги фиксились, когда какие фичи заливались в мастер.
Это и так можно без проблем понять.
Практика показывает, что люди, которые пушат в мастер не на начальном этапе проекта, должны гореть в аду.
Ну-ну. Тех, кто плхие коммит сообщения пишет увольнять?
И к тому же, поясните мне, чем лучше 20 одинаковых сообщений типа:
"Fixed #20 Here we have soooo long feature name"
Это не намного информативнее, чем то, что я привел выше
Ну-ну. Тех, кто плхие коммит сообщения пишет увольнять?
Да. И я сейчас серьёзно. Ибо в долгосрочной перспективе плохое сообщение в важном месте может дать большую потерю времени на попытку понять что происходит. Это также необходимо, как архитектурная документация и комментарии в сложных местах кода.
Конечно сначала надо обсудить, но если человек принципиально не комментирует, его надо выгонять без сожаления.
Это троллинг такой? Надеюсь, вы не управляете командой, потому что увольнение за неправильные commit message — это просто жестяк какой-то.
"Иван, вы отлично работали, у вас 10-летний опыт, сделали много прекрасных вещей, но вы делаете неправильные commit message и поэтому мы вас увольняем."
Ну не за один коммит, а за нежелание писать нормальные развернутые сообщения.
Ок, тогда так. Сегодня мы судим нашего товарища Ивана. У нас есть доводы за и против:
Иван пишет отличный код
Иван покрывает все тестами
Иван выполняет на 20% больше тасков, чем команда в среднем
Иван пишет плохие commit messages
Вердикт однозначен: УВОЛИТЬ!!!
Да я бы в тот же день заявление на увольнение написал)
У нас принято оформление истории перед запросом на влитие в master, тогда коммиты и сквошатся между собой, и тексты правятся.
Почему мы вообще используем Git? Потому что это наш самый важный инструмент для отслеживания источника багов в коде.
Я думаю ошибка вот в этом подходе.
Самый важный инструмент для отслеживания источника багов в коде — это результаты тестов и программист. А откуда баг произошел — можно конечно blame, но это вещь вторичная. Ибо чинить баг нужно исправлением кода, а не ковырянием с merge и rebase.
И проще просто руками пофиксить и замержить новое исправление, чем чинить это через какие-то mind-games в git.
Вот для этого как раз и нужен интерактивный ребейз.
Было:
improve feature
fix typo in feature
fix bug in feature
fix skipped code style
feature
fix code styleСтало:
feature
fix code styleДальше мержим в главную ветку с --no-ff.
И зачем вообще писать историю проекта если эта история будет причесана и раскрашена? Пользы от такой истории будет намного меньше, а правда всегда лучше, даже если и неприглядная.
Затем, что Git появился для удобства управления патчами ядра Linux, которые присылаются через списки рассылки. После чего с большой вероятностью следует обсуждение [серии] патча и его доработка, и лишь затем — включение в основной репозиторий. Так что при таком workflow — он просто необходим.
* такой вывод сделан мной на основе опыта отсылки нескольких патчей самого Git
Думаете, разбиение этого патча на 500 коммитов сильно упростит ревью?
Может просто не надо такие монструозные ветки делать?
И это — переход от одной минорной версии к другой! Так что 10000 строк — это не бог весть какое изменение. Нормальные, в общем-то, масшабы если вы делаете серьёзный рефакторинг, возможно с помощью coccinelle.
Но если вы сделаете --squash и склите вместе механические преобразования и что-то, что написано руками — то потом никто и никогда в этом разобраться толком не сможет.
Странная у Вас логика… Типа между версиями один автор мог закоммитить только 1 фичу?
Рефакторинг — да, может затронуть много строк, но если делать 1 вид рефакторинга в 1 коммите (а это по сути и есть границы технической фичи), то никаких проблем не возникнет, вне зависимости от кол-ва затронутых строк.
а это по сути и есть границы технической фичиПроблема в том, что никто не даст вам делать серьёзный рефакторинг пока не увидит для чего этот рефакторинг нужен. А потом ещё и тесты отдельно попросят написать.
В любом случае — будет цепочка коммитов. Иногда — включающая в себя десятки (если не сотни) patchset'ов.
Rebase почти неизбежен, например, при работе с апстримом. Ну или в общем в том случае, когда вы не контролируете или слабо контролируете основу на которой пилите фичу.

Для всех адептов merge, вместо тысячи слов:

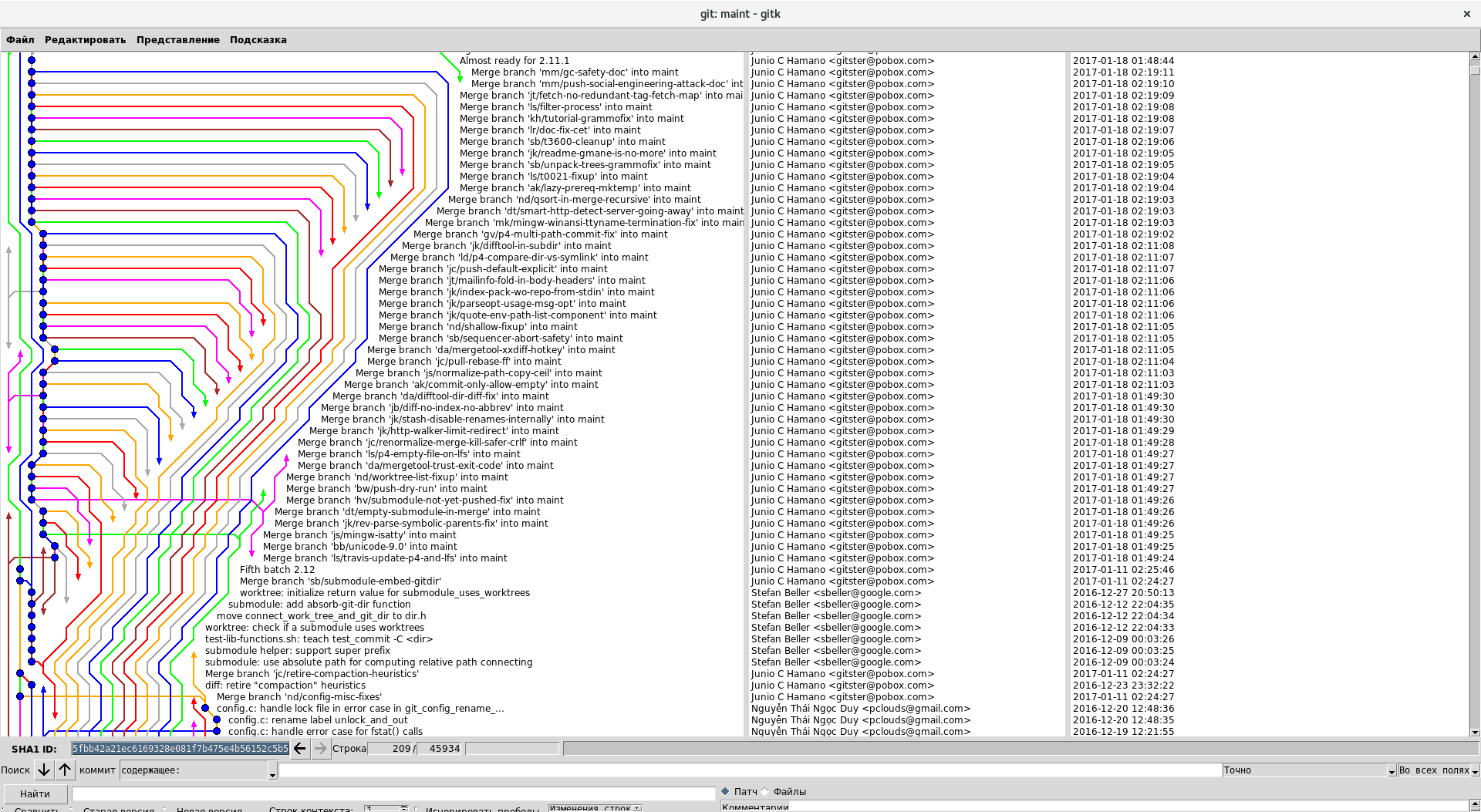
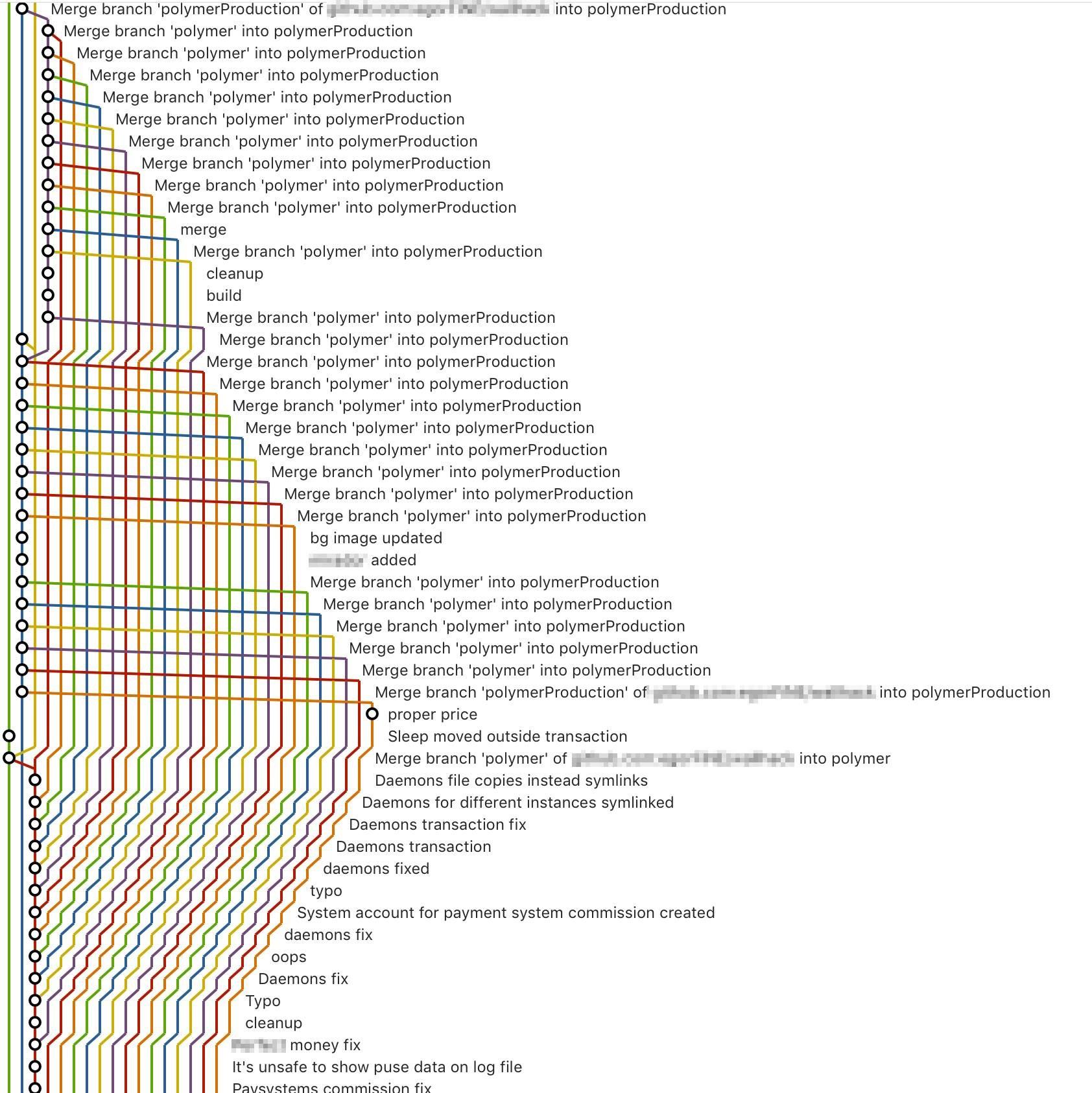
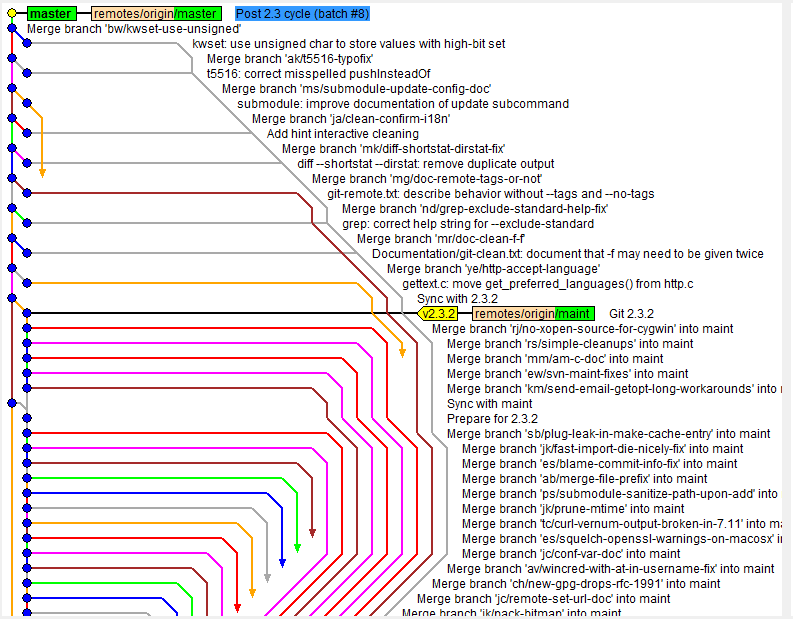
Очень хотелось бы увидеть, как автор ищет здесь баг при помощи git bisect. Думаю, что такое шоу можно отлично стримить в twitch. Это будет блокбастер
Посмотреть на Яндекс Картах
bisect, он отлично находит сначала проблемный коммит слияния (merge-commit), затем проходится по уже «линейным» коммитам ветки, которую влили. Так что что блокбастера не будетbisect`е в модели разработки ветка-слияние (без рибейса). А я, чтобы не быть голословным, проверил на проекте самого Git (там дерево слияний — подобно приведённым картинкам), и никакого блокбастера, к счастью, не наблюдалЧисло веток никак не влияет на сам факт существования истории. Хочется видеть историю без мерджей — напишите (найдите) визуализатор, который вам ее так покажет. При rebase даже написать визуализатор, который покажет то, что на скриншоте нет возможности. А потеря информации (тем более вводимой вручную) — это плохо.
А из какого это проекта?
Напоминает схему токийского метро )

сравните с

Как минимум, разница в том, что в 1м случае, весьма затруднительно увидеть все комиты конкретного фиче-бранча целиком. Потому что вся история представляет собой винегрет из комитов разных фиче-бранчейю В случае же rebase-подхода, все комиты прекрасно сгрупированы по своим фиче-бранчам. История фичей всего продукта очень даже наглядна, в таком случае.
Аргументы в пользу «чистоты истории» лично для меня весьма сомнительны. На моем опыте еще не было такого, что бы вопросы типа «какая хронология комитов в абсолютно паралельных бранчах», а тем более «сколько раз юзер А синкал свой бранч с мастером», приносили хоть какую-то пользу.
Как минимум, разница в том, что в 1м случае, весьма затруднительно увидеть все комиты конкретного фиче-бранча целиком.А оно вам нужно?
На моем опыте еще не было такого, что бы вопросы типа «какая хронология комитов в абсолютно паралельных бранчах», а тем более «сколько раз юзер А синкал свой бранч с мастером», приносили хоть какую-то пользу.Реальную пользу приносят реальные, работающие, проходящие все тесты билды. Вопрос: сколько ресурсов вы готовы потратить на то, чтобы иметь такие после каждого rebase?
В том, что линейная история лучше нелинейной никто не спорит. Вопрос в том, что история, в которой каждый шаг — реальный, проверенный, коммит лучше «лжеистории», где вроде как коммиты есть — вот только реально собрать и использовать нифига нельзя.
А оно вам нужно?
Читабельность истории кода возрастает в разы. «Во-первых, это красиво» Во-вторых, так гораздо легче увидеть кто чего добавил в мастер, пока я был в отпуске, например.
Ведь читабельность кода — считается одним из важнейших показателей его качества, по определенным причинам. И по схожим причинам читабельность истории кода тоже важна, я считаю.
Вопрос: сколько ресурсов вы готовы потратить на то, чтобы иметь такие после каждого rebase?
А сколько ресурсов надо, что бы иметь такие билды после каждого мержа мастера в свой бранч? И в том и в том случае все будет зависеть от частоты синка и наличия мерж-конфликтов. А это уже зависит от того, насколько эффективно распределены задачи и области ответственности между разработчиками, т.е. от коммуникации внутри команды. Мерж или рибейз, как команды гита, тут ни при чем.
И в качестве бонуса: при правильно налаженном процессе разработки, рибейз-подход ничем не затратнее мерж-подхода, и даже немного лучше его. Рибейз-подход позволяет выявлять мерж-конфликты на локальных репозиториях, а не во время принятия мерж-риквеста. Поскольку мерж бранча в мастер, если этот бранч уже успешно зарибейжен на мастер, никогда не приведет к мерж-конфликту.
Далее под «мастер» я буду подразумевать бранч разработки. У кого-то это master, у кого-то это dev
Рекомендую, процесс разработки строить на основании следующего алгоритма:
0. фича готова
1. рибейз фичи на последний мастер + пуш форсом (у нас же каждый работает в своей фиче-бранче, правда? Если нет, то стоит серьезно задуматься о том, что бы каждый разработчик работал в своем отдельном фиче-бранче...)
2. открытие мерж-запроса (например, в GitLab) и код ревью
3. после всех фиксов по код ревью, локальный билд + прогон юнит тестов + тестирование фичи разработчиком локально
4. финальный рибейз ветки на последний мастер если он обновился
4.1 если возникли (сложные) мерж-конфликты, то повторить пп 3-4
5. пуш(--force-with-lease) и принятие мерж риквеста — ветка автоматически мержится в мастер(дев) без каких-либо мерж-конфликтов, поскольку она уже зарибейжена на последний мастер
А все возможные проблемы одновременных мерж-риквестов хорошо разруливаются методом согласования между разработчиками кто за кем будет вливаться.
Ну и конечно же права на рибейз мастера или пуш форсом надо забрать у всех, кроме админа/тим-лида), что бы руки не чесались. В идеале — что бы мастер можно было изменить только через мерж-риквест в GitLab(или что там у вас)
Вопрос в том, что история, в которой каждый шаг — реальный, проверенный, комит лучше «лжеистории», где вроде как комиты есть — вот только реально собрать и использовать нифига нельзя.
В целом, согласен. Я тоже противник идеи сквошить все комиты в один, перед мержем в мастер. Разве что быстрые фиксап-комиты нужно сквошить. В остальном, нужно стараться делать атомарные комиты.
Читабельность кода нужна, чтобы было удобно вносить в него правки и ковырять баги.
А читабельность истории не нужна никому, но нужна ее корректность, например для парсинга и составления кросс-чеков или каких-нибудь отчетов, типа «сколько разработчиков работало над вот такой функциональностью».
В данном случае нужна не читабельность, а… «парсебильность» и конечно корректность — name convention по коммит сообщениям и именам бренчей.
А читабельность истории не нужна никому
Говорите за себя. А я сам решу, нужна ли мне читабельность истории или нет и для чего.
не читабельность, а… «парсебильность»
В данном случае речь шла как раз не о «парсебельности» — перечитайте ветвь обсуждения, для начала. И та же «парсебельность», которую вы упомянули, относится к читабельности истории.
И в качестве бонуса: при правильно налаженном процессе разработки, рибейз-подход ничем не затратнее мерж-подхода, и даже немного лучше его.Затратнее. Он сериализует разработку. Если у вас разработчков — 10 человек, то это незаметно вообще. При 100 — начинает напрягать. При 1000 — это уже почти невозможно. При 10'000 — это катастрофа и разработка просто встанет нафиг.
А все возможные проблемы одновременных мерж-риквестов хорошо разруливаются методом согласования между разработчиками кто за кем будет вливаться.Вы это серьёзно? Вы предлагает всем 10'000+ разработчиков, которые могут вливать код в наш репозиторий договариваться? Я это даже теоретически себе представить не могу…
В идеале — что бы мастер можно было изменить только через мерж-риквест в GitLab(или что там у вас)У нас так сложилось, что несколько систем в ходу.
10'000+ разработчиков которые работают в одной ветке? merge будет при таком подходе испытывать те же самые проблемы с сериализацией что и rebase.
10'000+ разработчиков которые работают в одной ветке?10'000 разработчиков работают в trunk'е.
merge будет при таком подходе испытывать те же самые проблемы с сериализацией что и rebase.С какого перепугу? Они работают с одним репозиторием, да, но это не значит, что все 10000 разработчиков правят один файл. Большинство коммитов друг-друга вообще никак не задевают, так как правят разные подсистемы.
При 10'000 — это катастрофа и разработка просто встанет нафиг.
я плохо себе представляю процесс координации и сотни человек в пределах одного репозитория если они работают с общими вещами… (ну то есть когда есть репозиторий и в нем десятки отдельных компонентов и каждый работает со своим — то это норм) причем вопрос rebase/merge при этом будет смехотворен по сравнению с другими проблемами как мне кажется.
ну то есть когда есть репозиторий и в нем десятки отдельных компонентов и каждый работает со своим — то это нормКаждый, разумеется, работает «со своим» — вот только множество файлов, являющиеся «своими» — пересекаются.
Простейший пример: люди, разрабатывающие версию программы под Android и iOS, разумеется, имеют свои подпроекты и друг к другу не заходят. Но у них есть и общая часть. Которую меняют не только разработчи UI для iOS и Android'а, но и разработчики backend'а (меняющие и клиентский код при необходимости). А те, кто разрабывают билд-систему могут и коммит, затрагивающий 10000 файлов устроить (но, понятно, исходники они трогать не будут).
Так что каждый конкретный файл в каждый конкретный момент времени меняют не так много разработчиков, на заранее сказать — кто это может делать, а кто нет — нельзя.
Вы описали какой-то ад сточки зрения контроля за инфраструктурой. 1000 человек работающих в одном git репозитории, без каких-либо разграничений, с возможностью бэкэндщикам править что-то в коде мобилок, да еще и "общая" инфраструктура сборки для бэка и мобилок....
Ну то есть я допускаю что в таких подходах может быть необходимость но все же жизненный цикл бэкэнда и мобильного приложения, система сборки и т.д. настолько сильно различаются как правило что нет смысла это держать в одной куче. Тем более когда с кучей работает так много людей.
Если я чего-то не понимаю, был бы рад если бы вы поделились деталями "зачем так сделали и какие проблемы это решает". Думаю я из этого что-то да узнаю нового.
Лично я все компоненты такого уровня (мобильные клиенты, фронтэнд, бэкэнд, билд инфраструктура) вообще держу в разных репозиториях. Так выходит больше контроля над ситуацией.
Вы описали какой-то ад сточки зрения контроля за инфраструктурой.Почему?
1000 человек работающих в одном git репозитории, без каких-либо разграничений, с возможностью бэкэндщикам править что-то в коде мобилок, да еще и «общая» инфраструктура сборки для бэка и мобилок....Ограничения, разумеется, есть. Но они такого сорта: «Вася может править все файлы Android.mk по всему репозиторию», или «Петя может править только файлы, относящиеся к протоколу доставки новостей — но на сервере и на клиенте одновременно». Ну и есть несколько людей, которые могут измения вообще везде. Немного, конечно, но они есть.
Ну то есть я допускаю что в таких подходах может быть необходимость но все же жизненный цикл бэкэнда и мобильного приложения, система сборки и т.д. настолько сильно различаются как правило что нет смысла это держать в одной куче.Ну это если вы позволите иметь разные жизненные циклы, разные системы сборки и прочее.
Почему, собственно, у вас мобильные приложения имеют другой «жизненный цикл»? И почему они используют другую систему сборки?
Практика показывает, что без этого вполне можно обойтись.
Если я чего-то не понимаю, был бы рад если бы вы поделились деталями «зачем так сделали и какие проблемы это решает»А какую вообще проблему решают системы контроля версий? Почему вы ими пользуетесь и почему перешли с RCS на CVS и Svn/Git? Почему, чёрт побери, исходники Gdb живут в одном репозитории с исходниками Goldа и Gasа?
Ответ: потому что так удобнее. Задача, как бы, всегда одна и та же: получить контроль над исходниками. И чем меньше у вас репозиториев — тем меньше искусственных границ.
Лично я все компоненты такого уровня (мобильные клиенты, фронтэнд, бэкэнд, билд инфраструктура) вообще держу в разных репозиториях. Так выходит больше контроля над ситуацией.Серьёзно? А если вам нужно код перенести из фронтэнда в бэкэнд или наоборот? Или, того хлеще, он нужен в обоих местах? Предположим вы пишите MMORPG и хотите на сервере перепроверить результаты боя (а то мало ли — кто-нибудь подхачит клиент и будет у вас команда героев 999го уровня «в лёгкую» выноситься зелёным новичком 1го уровня)?
Система сборки в отдельном репозитории — это прекрасно, но предпложим, вы хотите сделать что-нибудь подобное — кто будет править все Makefile'ы (CMakeLists.txt или что у вас там)?
Пока что все случаи, которые я видел и в которых использовалось несколько репозиториев кончались тем, что «сверху» над этим всем надстравиалась структура, которая эмулировала монорепозиторий. Все эти NPM'ы, NuGet'ы и прочие всякие Cargo — прекрасны, но, давайте скажем честно, они — всего-навсего попытки обойти невозможность использования, по тем или иным причинам — техническим (у вас нет возможности хранить историю проекта в котором 2 миллиарда файлов) или организационным (разные компоненты делают разные люди, часть из которых на аутсорсе и вы не можете дать им доступ, пусть даже ограниченный, к вашему «основному» репозиторию) одного большого репозитория.
При 10'000 — это катастрофа и разработка просто встанет нафиг
Совершенно верно, 10'000 активных комитеров в один репозиторий — это настоящая катастрофа. Нормальные проекты, которых подавляющее большинство, это от 1 до, ну максимум, 100 человек в одном репозитории. И даже если 100 человек комитят в один репозиторий, то на таких больших проектах очередность мерж-реквестов может определяться тим-лидом или по принципу FIFO. «Сложно, но можно» Проекты, на которых больше 100 активных комитеров, обычно настолько большие, что они разбиты на отдельные команды, которые работают над отдельными модулями(сервисами), а они ведутся в отдельных репозиториях.
Проекты, на которых больше 100 активных комитеров, обычно настолько большие, что они разбиты на отдельные команды, которые работают над отдельными модулями(сервисами), а они ведутся в отдельных репозиториях.Что черезвычайно усложняет работу над ними. Да, используя костыли типа repo это всё можно заставить рабортать — но сложно и неудобно.
Ограничения тут скорее технические. В недаром в последнее время происходит посредовательный отказ от такого подхода. При переходе на git Microsoft озаботился не тем, как вы устроить 100500 репозиториев, а над тем, как масштабировать Git. Google и Facebook, правда, Git не используют, но также держат весь код в одном репозитории.
Что черезвычайно усложняет работу над ними.
Это все равно что заявить, мол, ООП черезвычайно усложняет разработку, а вот в процедурном стиле меньше кода получается.
Ограничения тут скорее технические.
Google и Facebook, правда, Git не используют, но также держат весь код в одном репозитории
Потому что это настолько большие продуктовые компании, что их способы управления кодовой базой стали исключением из правил, а не правилом. Для более чем 99% процентов проектов, которые используют системы типа git, их пример не применим в принципе. И для небольших команд описанный мною процесс отлично подходит. Я уже на 2х проектах в этом убедился.
Ого! А вот это — уже новое слово «в науке и технике». Обычно на мои заявления о том, что монорепозиторий — лучше и удобнее следует как раз отговорка, что «это — может быть хорошо для мелких компаний, но большие так не делают». А, типа, «настоящие монстры» (IBM там, Microsoft и прочие) монорепозиторий не используют.Google и Facebook, правда, Git не используют, но также держат весь код в одном репозитории.Потому что это настолько большие продуктовые компании, что их способы управления кодовой базой стали исключением из правил, а не правилом.
Теперь, когда «монстры» начали-таки переход на монорепозитории отговорки сменились на противоположные.
Усложняет разработку не ООП, а его неверное использование. Когда вы создаёте жёсткие контракты там, где они, в общем-то, не нужны. И да, во многих случаях ООП не упрощает разработку, а усложняет.Что черезвычайно усложняет работу над ними.Это все равно что заявить, мол, ООП черезвычайно усложняет разработку, а вот в процедурном стиле меньше кода получается.
И для небольших команд описанный мною процесс отлично подходит.Для небольших команд можно и с файликами в архиве и копирование подкаталогов с разными версиями обойтись, но… зачем?
Для более чем 99% процентов проектов, которые используют системы типа git, их пример не применим в принципе.Не знаю что такое «системы типа git», но конкретно git изначально предназначен для работы с монорепозиториями. И хотя со временем к нему пристроили костыли (всякие repo, субмодули и прочее) — но это не меняет того факта, что всё это — таки костыли, которые приходится использовать «от бедности», а не часть оригинального дизайна…
сменились на противоположные
Противоположные чему? Какие отговорки? Мой посыл в том, что «титаны» играют по правилам «титанов», а «простые смертные» — по своим, образно выражаясь. Или вы хотите сказать, что каждый абстрактный стартап «Рога и копыта» из 35и девелоперов должен применять модель поведения фейсбука или Гугла? Нонсенс.
А про аутсорс-компании, где проекты независимы, и введение монорепозитирия в них было бы не только невозможным, но и нарушало все NDA, я вообще молчу…
но конкретно git изначально предназначен для работы с монорепозиториями
Откуда вы это взяли? Можно ссылку на первоисточник?
Итого:
Вижу, дискуссия в конструктивном русле у нас как-то тут не особо выходит… Зато у меня к вам предложение, которое может вас заинтересовать) Как насчет написать свою статью о монорепозиториях? Поделитесь своим опытом работы с ними, расскажите о достоинствах или недостатках, лайфхаках, ньюансах и т.д. Уверен, найдется много разработчиков, которым это будет интересно.
А про аутсорс-компании, где проекты независимы, и введение монорепозитирия в них было бы не только невозможным, но и нарушало все NDA, я вообще молчу…В случае, когда вы вынуждены использовать несколько репозиториев по юридическим причинам — вы таки будете их использовать. Более того, даже Гугл не весь свой код держит в Piper'е — ровно по этой причине.
Мой посыл в том, что «титаны» играют по правилам «титанов», а «простые смертные» — по своим, образно выражаясь.Угу. Только вот лет 10 назад, до того, как Facebook и Google стали «титанами» этот самый довод использовался компаниями для обьяснения того, что у них 10 репозиториев на 100 человек. Дескать хорошо держать всё в одном SourceSafe, если у вас три разработчика и бекап влазит на CD-ROM, а мы уже большие — должны вести себя как большие.
От примеров Google и Facebook'а, которые тогда уже были, но ещё не были «титанами» отмахивались со словами «они нифига не понимают
Или вы хотите сказать, что каждый абстрактный стартап «Рога и копыта» из 35и девелоперов должен применять модель поведения фейсбука или Гугла?А почему бы и нет? Разумеется им стоит применять модель поведения Гугла примерно 2001-2002 года и Facebook'а примерно 2004-2005 года (когда у них было примерно столько же сотрудников), а не сегодняшних «титанов», но… у них и тогда тоже был монорепозиторий!
Git изначально предназначался для работы с ядром Linux'а — и ядро Linux'а категорически отказывается делиться на подпроекты.но конкретно git изначально предназначен для работы с монорепозиториямиОткуда вы это взяли? Можно ссылку на первоисточник?
Git изначально предназначался для работы с ядром Linux'а — и ядро Linux'а категорически отказывается делиться на подпроекты.
Из того, что «Git изначально предназначался для работы с ядром Linux'а» и «ядро Linux'а категорически отказывается делиться на подпроекты» вовсе не следует, что «git изначально предназначен для работы с монорепозиториями» У вас какие-то странные доводы. С таким же успехом можно заявить, что FAT32 изначально предназначались для работы с монорепозиториями, что есть некорректно. Вы путаете красное с горячим. Монорепозиторий — это способ организации процесса разработки, в то время как git — это технология хранения файлов, которой по большому счету все равно, чьи и какие файлы там будут храниться.
Монорепозиторий — это способ организации процесса разработки,Верно.
в то время как git — это технология хранения файлов, которой по большому счету все равно, чьи и какие файлы там будут храниться.Которая, однако, была создана в первую очередь из-за того, что существовавшие тогда DVCS (Monotone, GNU Arch и прочие) не могли осилить репозиторий такого размера. Альтернатива — разбить единый проект на несколько подпроектов и несколько репозиториев — фактически даже не рассматривалась.
Фактически Git был создан даже не для монорепозиториев, а для монорепозитория — одного. То, что он оказался полезен для чего-то там ещё — почти случайность.
С таким же успехом можно заявить, что FAT32 изначально предназначались для работы с монорепозиториямиСерьёзно? Кто-то не смог уместить свой репозиторий на FAT16 и запилил FAT32? Интересная история… из альтернативной вселенной.
А почему бы и нет?
Не убедительно. Не вижу доводов в пользу монорепозиториев.
1. пофиксить код во время разрешения мерж-конфликта
2. сделать фикс уже после рибейза/мержа отдельным комитом
3. переписать бранч начиная с комита, в котором возник мерж-конфликт. Т.е. делаете soft reset до последнего рабочего комита, фиксите код и заново делаете комиты.
Какой из этих трех способов лучше подходит — надо смотреть по ситуации.
Если же мерж-конфликтов по какой-то причине не произошло, то вариант 2 или 3
Вообще, с одной стороны, удивляюсь, какие проблемы может порождать коллективная деятельность; с другой — обратил внимание на пару команд по «причёсыванию» кода (на даче-то у меня Git больше как крупноячеистый undo, но эстетика не помешает).
Я так понял, что мёрдж-конфликт — это когда две ветки меняют один и тот же фрагмент кода
Верно.
в случае какого-нибудь модуля, у зависимости которого в master изменился интерфейс, явного конфликта не будет
В таком случае, если вы выявили проблему уже после рибейза, но не знаете, какой комит ломает бранч, могу порекомендовать попробовать один трюк:
git rebase master -i --no-ff --exec "run_tests.sh"Если предположить, что текущий бранч уже зарибейжен на последний master, то эта команда запускает повторный интерактивный рибейз на мастер (-i --no-ff) и для каждого комита будет выполнен, например, скрипт run_tests.sh (билд, запук тестов и т.д. или что угодно)
Таким образом, с помощью скрипта вы сможете найти комит, на котором произошел баг.
Только сразу предупрежу — я этот трюк попробовал на тестовом репозитории, вам же рекомендую на всякий случай сделать «бекап» бранча методом создания временного бранча (как указатель на тот же комит, на который ссылается бранч, который собираетесь фиксить)
Как всё категорично. Вот когда готовлю PR в сторонние репозитории то постоянно делаю rebase, ибо разработчикам проекта не обязательно знать что именно и в каком порядке было сделано, им нужно чтобы фича работала и чтобы отсутствовали конфликты слияния. Ну и тестировать всё буду я + разработчики соответствующего проекта.
А с обычными проектами использую merge, ибо логичнее.
Поэтому опрос не имеет смысла в текущем виде, есть сценарии использования для обоих команд, и говорить что нужно всегда использовать какую-то одну глупо.
Не понимаю, как можно противопоставлять мерж ребейзу. Это разные команды, для разных задач. Это как рассуждать на тему "что круче отвертка или гаечный ключ?".
Вообще была замечательная статья от Atlassian где все вроде бы и так разложили по полочкам:
https://www.atlassian.com/git/tutorials/merging-vs-rebasing
И вывод собственно тоже простой — используете то, что вам нужно.
Допустим, мы удалили из master зависимость, которая всё ещё используется в feature.
Это что имеется в виду? Удалили коммит из master, серьёзно?
Решение конфликтов посреди rebase длинной цепочки коммитов часто превращается в непростую задачу
Абсолютно эквивалентную по сложности решению конфликтов при merge большой ветки.
Для этого мы могли бы использовать интерактивный rebase.
Кхм, а кто-то реально использует неинтерактивный?
P.S. Вся статья — какая-то голая риторика, без единого практически значимого аргумента. То, что по время rebase можно допустить ошибку — это не проблема rebase, такую же ошибку можно и во время merge допустить.
Где купить новое кресло? У меня подгорело.
Я глянул оригинал и по ходу автор (не переводчик) не вдупляет, что есть get merge --no-ff и выдаёт мердж-коммиты за "хорошо", когда их после ребейза итак можно сделать без fast-foward'а.
Автор по ходу делает ребейз раз в полгода и на фичах, которые покрывают всю систему, а не определённый ее участок. Также автор не в курсе, что есть отличная фича по имени rerere, которая запоминает, как резолвить конфликты.
Кароче мой ответ здесь дублирую:
Author, dont’ you know, that git merge --no-ff exists? After rebase you should not merge your feature with fast forward, but create merge commit. So rebase will help to analyze what you did without exploding brains, and no fast-forward merge will help others see the boundaries of your feature.
Git flow also invented. Rebase is forbidden in trunk-like branches like master/develop, but in feature branches you should rebase often.
If you have many conflicts with develop/master — then its’ a clear sign, that your team has bad code base of bad focusing, when many people do same things instead of their own focused features.
Also git has nice feature called rerere. Just google it.
https://medium.com/@ustimenko.alexander/author-dont-you-know-that-git-merge-no-ff-exists-460449b8407
Я глянул оригинал и по ходу автор (не переводчик) не вдупляет, что есть get merge --no-ff и выдаёт мердж-коммиты за "хорошо", когда их после ребейза итак можно сделать без fast-foward'а.
Как это всё решает проблему поломанных ребейзом коммитов?
поломанных ребейзом коммитов
Нет такой проблемы. Проблема конфликтов решается человеком, а не ребейзом или мерджем. И там и там мозг работает, а не инструмент. Мердж и ребейз — это всего лишь менее опрятный и более опрятный способ передачи того, что ты сделал далее.
Для меня мердж — это как раскидать вещи по комнате и предложить потом найти другому человеку в них что-то. Ребейз — это хотя бы в одну кучу всё сложить, а мердж-коммит (который и есть тот самый no fast forward) — отделяет одну кучу от другой.
Всё это из коробки есть в гит флоу.
Проблема т.н. "поломаных комитов", вернее постоянных конфликтов, связана вообще с другим — отсутствие фокусировки по задачам и/или ужасная кодовая база. Но никак не со способом записывать историю.
Надо просто взять себе за правило всегда делать ТОЛЬКО интерактивный rebase. И тогда никаких поломанных коммитов не будет
Ребейз не может сломать коммит. Автор просто плохо понимает, что происходит. Если в мастер был сделан коммит, удаляющий какую-то зависимость, используемую в фиче, то ни ребейз, ни мердж тут не спасут. При этом коммиты остаются нормальными, они все несут в себе всё те же изменения. Автор сваливает в кучу две проблемы — проблему слияния веток с точки зрения инструмента git, и с точки зрения логики кода. Если две ветки не совместимы на уровне кода, то git тут не при чем. Если две ветки совместимы, то можно использовать и ребейз, и мердж — зависит от конкретной ситуации и принятых политик. Проблема надуманная.
Дорогие коллеги, которые выступают категорически против rebase. Внимание, задачка:
Вы отбранчевались от мастера и пилите фичу. В это время в мастер приезжает 4 мерджа: 2 больших фичи, 1 критический фикс, одна большая фича.
Вам нужно интегрировать в свою ветку критический фикс, который приехал с третьим мерждом, но при этом те большие фичи вам не нужны (вы не хотите возиться с сайд-эффектами). Вы категорически не приемлете rebase. Ваши действия
В том-то и дело, что я тоже cherry-pick имел в виду, но перед мерджом во избежание конфликтов нужно будет этот коммит в feature-branch скипнуть, а это уже rebase
Идентичные изменения конфликтом git не считает же...
Как это не считает? А какой вариант этих единичных изменений он вольёт?
Как у идентичных изменений может быть два разных варианта?..
Одна и та же строка изменена в двух разных коммитах. Не забывайте, что при cherry-pick создается новый коммит, а не копируется начальный.
Одна и та же строка изменена в двух разных коммитах одинаково.
$ echo xxx>foo
$ git add foo
warning: LF will be replaced by CRLF in foo.
The file will have its original line endings in your working directory.
$ git commit foo
warning: LF will be replaced by CRLF in foo.
The file will have its original line endings in your working directory.
[master 366bc1d] foo
1 file changed, 1 insertion(+)
create mode 100644 foo
$ git checkout HEAD~1 -b bar
Switched to a new branch 'bar'
$ git cherry-pick master
[bar 466fb73] foo
Date: Tue Oct 24 16:01:53 2017 +0500
1 file changed, 1 insertion(+)
create mode 100644 foo
$ git merge master
Merge made by the 'recursive' strategy.
$ git log --graph --format=oneline
* 15cc8d728221d930207ac82dc179f3f840d1d83d (HEAD -> bar) Merge branch 'master' into bar
|\
| * 366bc1d3de2a196a9b42d4859ba006ad72b13ed4 (master) foo
* | 466fb73499a11a377c38deea3cc6807056f84e0b foo
|/
* 0bba79c02f513f2536fc106f4063cdaf6d0a6c47 initialЕсли при ребейзе оставить чери-пикнутый коммит, то он просто покажет предупреждение типа "пустой коммит" и пропустит его автоматически. Но можно и скипнуть, не принципиально.
У вас там что, все фикс ветки с начала времен хранятся? вы не удаляете ветки после ПР и мерджа?
Да даже если и удаляет — в коммит-то в истории остался.
Хуже получается когда фикс-ветка началась уже после разветвления текущей фичи и мастера.
А если фича ещё не доделана, то зачем в ней хотфикс?Например потому что тот фикс мог менять API.
На самом деле правило и в случае rebase и в случае cherry-pick'а — одно и то же: если вы сделали rebase или cherry-pick — вы обязаны протестиовать всё, что вы перебросили из одного места в другое. Наложить по очереди все патчи и проверить что ничего не поломано. rebase + hotfix в конце же — хуже, чем squash: вы получаете «дырявую» историю — и ничего об этом не знаете пока не решаете ей воспользоваться!
P.s. я никого не защищаю, просто был такой кейс.
Вам нужно интегрировать в свою ветку критический фикс, который приехал с третьим мерждом, но при этом те большие фичи вам не нужны (вы не хотите возиться с сайд-эффектами). Вы категорически не приемлете rebase. Ваши действия
Мёржу к себе в код багфикс ветку с критическим фиксом и работаю дальше.
Никогда не понимал такого. Пожар и процесс разработки пересекаться не должны. Именно для пожара существуют бекапы. А делать нерабочие, а точнее сказать недописанные коммиты, это портить историю проекта.
У меня вообще все мои git каталоги синхронизируются между работой и домом через syncthing (и еще на одну машину, на всякий случай). И мне не составляет труда дома довести разработку до законченной стадии что бы сделать рабочий коммит.
А зачем такие сложности?
У меня единое рабочее пространство на работе и дома (за счёт синхронизации) и не так важно есть в этом пространстве git или нет.
А git решает не задачу переноса изменений с машину на машину (эту задачу лучше поручить профильному инструменту), а контроль этих самых изменений. Каждому инструменту — свои задачи.
Раньше тоже так делал, пока один раз не сломал локальный репозиторий (git, конечно, живучий по сравнению с svn, но всё же). В итоге стал делать Sync-коммиты, которые потом сквошу.
Этот аргумент выглядит главным в статье. Так вот, тоже самое достигается rebase со squash и сохранением ветки feature (вообще не понял зачем автор решил ее удалить). При этом мы избавляемся от «железных дорог».
Так вот, тоже самое достигается rebase со squash и сохранением ветки feature (вообще не понял зачем автор решил ее удалить).Git bisect по-прежнему работает?
При этом мы избавляемся от «железных дорог».Зачем ради красивой картинки ломать инструменты? После rebase со squash вы теряете историю. Да, её, наверное, можно откопать — но для этого нужно быть археологом. А Git, как бы, создавался для того, чтобы этого не требовалось.
Git bisect по-прежнему работает?
Да. Если вы задаете этот вопрос, значит вы не поняли, что я предложил. Для продолжения дискуссии необходимо, чтобы вы попробовали сделать следующее:
git rebase -i --onto branch_to branch_from_start branch_from_end Уточню: левая граница исключена, правая включена, т.е. branch_from_start не войдет в цепочку ребейза. Далее, в любимом редакторе (я, надеюсь, вы настраиваете git для использования любимого редактора) верхний коммит оставляем pick, остальные ставим squash. Сохраняем, наблюдаем, смотрим результат.
После rebase со squash вы теряете историю.
Попробуйте сделать то, что я описал Выше, а потом поясните какую историю я теряю. Но на всякий случай напишу, что у меня с историей.
Мое видение следующее: ветки разработки должны содержать всё, dev должен содержать коммиты, соответствующие завершенным изменениям (фиксам и фичам), master должен содержать только релизы. Поиск проблемы состоит из последовательно поиска релиза (обычно мы и так знаем в каком релизе проблемы), затем поиска фичи/фикса в dev, затем анализ ветки разработчика. При этом последнее не всегда необходимо, т.к. стоит править именно фичу целиком, а не отдельный ее коммит.
Кстати, а любители «железнодорожных путей» и неизменной истории в курсе, что иногда git-репо приходится архивировать? Или например, о том, что крупные компании не могут использовать git, т.к. он не тянет их большую историю?
Мое видение следующее: ветки разработки должны содержать всёДальше можно не продолжать. Git, в общем-то — распределённая система. В центральном репозитории никаких веток разработчика нет — и быть не должно. Они существуют только и исключительно на машине раззработчика. Пока он разрабатывает.
Никому не интересно копамять в ваших беспорядочных метаниях, извините. После вливания в мастер там должна остаться чистая история. Причём обас слова важны: там должна быть история и она должна быть чистой. Во всяком случае так Git изначаль задумал. Так-то можно и гвозди в стену вкручивать и шурупы забивать.
Кстати, а любители «железнодорожных путей» и неизменной истории в курсе, что иногда git-репо приходится архивировать? Или например, о том, что крупные компании не могут использовать git, т.к. он не тянет их большую историю?А не происходит ли это из-за того, что вы её не чистите и засоряете посторонним хламом?
P.S. История не должна быть «неизменной». Git — это не Mercurial. История должна быть чистой. rebase — отличный инструмент для этого, надо только не забывать прогонять тесты после того, как вы сделаете rebase.
Мы НЕ теряем историю. Мы делаем ее лучше. На собственной шкуре установил, что без rebase история абсолютно нечитабельна и переполнена идиотскими сообщениями типа fixed, updated и пр. Но как только команда начинает хотя бы делать squash — тут же история становится полезной. One feature — one commit
В статье описаны надуманные проблемы людей, которые не умеют и не хотят учиться использовать rebase
В статье описаны надуманные проблемы людей, которые не умеют и не хотят учиться использовать rebase
В статье описаны проблемы людей, которые не хотят во время rebase исправлять каждый коммит, потому что это долго и непонятно зачем нужно.
Хочу обратить ваше внимание, что вы делаете замечания о том, что причина в том, что люди чего-то не умеют, хотя они вам несколько раз озвучили причины.
С таким же успехом я могу начать рассказывать вам, что надуманы ваши проблемы и вы просто не умеете и не хотите учиться пользоваться нелинейной историей.
Но я так не делаю.
Зачем исправлять каждый коммит если достаточно исправлять те где поймали ошибку?
Если ошибка только в одном коммите, то нужно поправить только один. Но она может быть и в нескольких, например, если после создания ветки в мастере поменялся соства аргументов какого-нибудь метода, который используется в нескольких коммитах. В худшем случае придётся поправить все коммиты.
И, так как потенциально ошибка может быть в любом коммите — нужно каждый собрать и прогнать на каждом тесты.
Rebase разве не исправляет все коммиты от последнего до первого общего?
если вместо master говориться про fix-ветку или локальную, то она может и должна сдвинуться на текущий dev, а затем комитить, но это в локальной! как можно в dev пушить краш!? это же для всех разработчиков, пожалейте их и их время.
Машину времени вы где покупали?
Что здесь названо словом «компот»?
Трудно прогонять тесты? Да, трудно. Это доказывает преимущества ребейса перед мерджем? Нет, не доказывает.
Пре ребейсе нужно прогнать тесты для каждого коммита, при мёрже — только один раз. Таким образом, на ребейс уйдёт значительно больше времени. Поэтому мёрж — быстрее. Преимущество в скорости доказано.
Представим, что Вы прогнали тесты и получили ошибку (а то и несколько). Как будете искать «виновные» коммиты? Как будете исправлять?
Когда делаешь мёрж и после мёржа упали тесты — не нужно искать виновные коммиты. Нужно поправить код и запушить мёрж. А вот в случае с ребейсом виновные коммиты таки будут, но найдутся автоматически, так как тесты надо будет прогнать для каждого коммита.
Извиняюсь, правда 40 тысяч комитов за день?Угу. Именно столько. Только не в Chrome, а в основном репозитории Гугла.
Я увидел только несколько десятков максимум.До 30 в час. Но да Chrome относительно не так велик.
Или 1 комит = 1 000 компотов?Нет. Один телефон — 20 опечаток. Больше не буду с телефона постить. Себе дороже потом разгребать ошибки.
Извиняюсь, правда 40 тысяч комитов за день?
Угу. Именно столько. Только не в Chrome, а в основном репозитории Гугла.
Ну или 400 тысяч, только не в Гугле, а по всему миру. Но мы то с вами смотрим на «реальный проект — Chromium». А там как выяснилось 720 за день, да и то в пике, вчера (24.10), например, 346 было. А тесты с возможностью гугла можно и параллельно для разных комитов пускать, хотя теперь после сокращения числа комитов на 2 порядка, может и время на тесты «слегка» приукрашено…
вот прям как в анекдоте:
стою я на асфальте в лыжи обутый то ли лыжи не едут то я еб***ый
вы ищите проблему в инструменте, где её нет, и не ищете в процессах и людях которые этим инструментом пользуются
Очень плохо.
Допустим, мы удалили из master зависимость, которая всё ещё используется в feature.
Feature всегда должен мерджиться в мастер исключительно через fast-forward, т.е. все коммиты из мастера уже должны быть в feature. Если это не так, то автор бранча feature делает rebase мастера к себе и правит свои коммиты.
Т.е. при правильном подходе проблемы просто нет.
Нельзя feature мержить в мастер через fast-forward после того как master был замержен в feature! Потому что при просмотре истории в большинстве утилит получится будто feature основная ветка, а master был в нее вмержен. :-(
после того как master был замержен в feature
В том-то и суть, что нельзя мерджить master в feature. Только rebase. А вот feature в master — merge
А почему нельзя мерджить мастер в фичу?
Мессиво в истории получится.
Вообще есть два противоположных подхода в работе с гитом
- ветки — это крупные фичи. Каждая ветка тестируется независимо, а перед релизом из фич собирается версия в мастере. Каждая ветка разрабатывается длительный срок и содержит много коммитов от разных людей
- ветки — это мелкие pull request-ы. Каждый PR пишется одним человеком за 1 час -3 дня, содержит, как правило, один коммит и мерджится сразу.
При первом подходе мердж коммиты нужны, при втором — вредны и только запутывают. На практике я встречал только второй подход.
Есть и промежуточные, например:
ветка — достаточно крупная фича, содержит много атомарных коммитов, пускай и от одного человека. Перед релизом фичи в неё мержится мастер, всё тестируется, а при релизе вливаетя в мастер.
Для разрешения сложных конфликтов мы используем git imerge — надстройку над Git, которая позволяет эффективно бороться с конфликтами (хотя, на самом деле, она нужна в очень редких случаях), переписывание истории локальных бранчей (чтобы косяков и их исправлений в истории видно не было), rebase перед мержем (если надо), CI workflow, который при мерже сам делает локальный мерж фичи в мастер и тестирует финальный результат (то, как это будет в мастере), а только потом кладет это в мастер.
Я стараюсь если и переписывать историю, то исключительно до пуша в общий репозиторий. Максимум, когда себе позволяю переписывать в общем — упавший билд или проваленные тесты. Главная причина — алгоритм работы git pull, который молча смержит оргинальную и переписанную истории. Вторая — комментарии на github, которые оказываются непонятно к чему привязаны.
Насчет поиска комментов после переписывания истории — да, это проблемная часть практически во всех системах. Мы пользуемся BitBucket, там у пулреквестов есть вкладка Activity, которая показывает хронологию всех действий, включая комменты.
Также, мы часто стараемся записывать исправления как fixup коммиты, но не делать rebase. Тогда проверяющему проще посмотреть, какие были сделаны изменения. А перед мержем можно сделать git rebase -i и все fixup коммиты куда надо уйдут.
Есть еще Gerrit, который там как-то с этим борется, но интерфейс из 90х убивает все желание пользоваться этим.
Есть еще Gerrit, который там как-то с этим борется, но интерфейс из 90х убивает все желание пользоваться этим.А вот и конфликт поколений, похоже, проявился: для меня одним из главных достоинств Gerrit'а является его лаконичный и удобный интерфейс, без всяких свистоперделок — но с управлением с клавиатуры. Правда недавно они сделали «редизайн», но, слава богу, пока что это всё опционально, классический UI по прежнему доступен…
Раньше я всегда делал git rebase, но потом прострелил себе колено.
Но объясните, в чём проблемы с т.н. железнодорожными путями?
Разве это не проблема исключительно визуализатора?
Скажем, выше приведена картинка просто отвратительнейшей визуализации орграфа.
Сходу нашел GitVersionTree и BranchMaster — наработки, но отражающие ключевую идую: двумерная визуализация орграфа для изучения/просмотра топологии веток.
Как мне кажется, если есть интегрируемый в среду разработки инструмент просмотра истории репозитория, страх перед ветвистостью историей существенно снизится и разработчики начнут выбирать инструмент (rebase vs merge) исходя из их целевого назначения, а не из страха иметь историю, которую встроенный визуализатор отображает запутанно.
Попробуйте пару раз вмерджить master ветку в вашу feature-ветку с фиксом конфликтов, а потом все это счастье вмерджить обратно в master. И покажите вашу клевую визуализацию того, что получилось. Я дичайше хочу заценить
Для двух веток вышеобозначенное решение Урю работает даже из-под консоли, если не заглядывать черезчур глубоко в прошлое, а ограничиться перечисленными вами коммитами.
Мне кажется возможным написать визуализатор, порождающий картинки в духе

Ось времени: слева направо.
Цельная линия отмечает первого родителя, пунктирная — второго.
Сможете сказать, что произошло в этом репозитории?
главное: не требовать единомоментное отображение сообщений всех коммитов и прочей ёмкой информации на экране, иначе получим тот же gitk с ограничением 1 коммит на строку. Цель ведь обозреть происходящее в истории, что откуда куда попало. А метаинформацию можно показывать при наведении/нажатии или через переход в режим gitk-like сразу в окрестности выбранного на этом графе коммита.
Впрочем, соглашусь, что если бы была возможность сохранять в merge-коммите информацию о том, требовалось или не требовалось разрешение конфликтов, картинки принципиально можно было бы сделать проще.
Если основная ветка ушла далеко от ветки фичи, то ребейз сделать сложнее. При ребейзе вы разруливаете конфликты на каждом коммите (rerere может спасти), а при мерже лишь один раз.
Но если вы rebase используется для синхронизации кодобазы, то он должен выполнятся максимально часто. Просто не нужно допускать сильного расхождения веток.
Эта ошибка проявится только после завершения процесса rebase, и обычно она исправляется с помощью нового bugfix-коммита g, применённого сверху.
Обычно такая ошибка исправляется редактированием предыдущих коммитов. Статью можно назвать "Я ниасилил rebase interactive".
В голосовалке не хватает пункта "Использую и rebase, и merge".
Все таки как сказали выше — это две разные команды для разных задач.

это разные команды для разных задач!
Вот это
Допустим, мы удалили из master зависимость, которая всё ещё используется в feature.
Эта ошибка проявится только после завершения процесса rebase, и обычно она исправляется с помощью нового bugfix-коммита g, применённого сверху.
совершенно непонятно — почему "обычно" именно так? Почему она не может быть применена напрямую к коммиту dʹ, если дальше по тексту требуется качество сборки и тестирования после любого коммита? Автор сам себе противоречит.
Решение конфликтов посреди rebase длинной цепочки коммитов часто превращается в непростую задачу: с ней трудно справиться, не наделав новых ошибок.
Есть такая проблема, но это отдельный фактор. Иногда действительно сложно понять, что же происходит. Хотя у меня большинство сложностей исчезли, когда сделал merge.conflictstyle=diff3: видно, что и как меняется. Хуже то, что один и тот же конфликт иногда приходится обрабатывать в целой цепочке коммитов. Да, это такая цена за ребейз.
Вы притворяетесь, что коммиты были написаны сегодня, хотя по факту они написаны вчера на основе другого коммита. Вы вытащили коммиты из исходного контекста, завуалировав то, что произошло в действительности. Вы уверены, что код соберётся? Вы уверены, что сообщения коммитов всё ещё имеют смысл?
Отвечу на это так — где я уверен, я делаю ребейз. Где не уверен — не делаю или корректирую так, чтобы оно соответствовало.
Автотестирование каждого коммита помогает этому.
Rebase — чисто эстетическая операция.
Да. Но тщеславие — ни при чём. При чём — читаемость истории через много лет, проектов и жизненных передряг. И ребейз часто этому помогает. Разумеется, он не абсолютно хорош, но никто и не говорил обратного.
Да, в голосовалке я поддержал именно rebase, несмотря на то, что использую оба.
Вдогонку: картинки динамические совершенно не по делу, вместо каждой 2-3 статических было бы нагляднее и проще уследить за происходящим. Да, это претензия к оригиналу, а не переводу.
Новая фича — новая ветка, несколько новых фич — несколько новых веток.
Фразу
Графики нелинейной истории, «железнодорожные пути», могут выглядеть пугающе.вообще не понял.
Теперь стало понятно назначение ребейса, но не понятно, зачем его с мерджем тут сравнили.
Если время от времени делать rebase своих веток с обзором коммитов коллег и запуском тестов, то все локальные ветки будут каждый день актуальны и готовы к практически безболезненному вливанию в мастер. И пути фич будут короткими (читать снизу вверх):
|
|\ # вмержили и запушили feature_2
| | # доделали feature_2
|/ feature_2 # решили конфликт, передав привет коллеге из Мексики
| |
|/ feature_1 # подтянули висячие фичи 1 и 2
| # утро
|
/| # коллега из Мексики вмержил своё
| |
| | # пошли спать
| |\ # вечером вмержили feature_3
\| | | # ещё чуть допилили feature_2
| | # делаем feature_3
|/ feature_3
|/ feature_2 # поправили совместимость со вчерашними коммитами
|/ feature_1 # подтянули старые фичи по git rebase master
| # утрокак будто каждая фича делалась один день.
Если же время от времени не актуализировать локальные ветки ребейсами, то:
| \ \ |
|\ \ \| # в конце месяца получаем кучу конфликтов при мерже каждой
| \ \ \
| | \ |\
| |\| | \
|
| ...
|
/| | |\|/|
| | |/| | | # пилим, мержим и черри-пикаем master
| |/| |/| |
\| |/| /\|
|
| ...
|
|/ feature_3
|/ feature_2
|/ feature_1 # начали три фичи в начале месяца
|Так что с rebase удобнее решать конфликты ежедневно по чуть-чуть, чем устраивать аврал раз в месяц.
Инструменты Git — Перезапись истории
Инструменты Git — Перезапись истории
Т.е. инструмент для перезаписывания истории ака git rebase нужен для… правильно — для перезаписывания истории. Иногда это называется «unix way» — когда чайник, сделанный для кипячения воды, кипятит воду, а тостер жарит хлеб, а инструмент для перезаписывания истоии перезаписывает историю.
От сюда следует, что для слияние своей ветки с мастером, нужно использовать команду «слить», по английски merge. Она сливает ветки. Не кипятит воду. Не жарит хлеб.
Но если я хочу перед слиянием в мастер убедиться в актуальности сделанных мной изменений, а так же слить некоторые коммиты, иными словами переписать историю, то я всё таки сперва воспользуюсь инструментом для переписывания истории git rebase, ещё разок проверю свою рабу, скормлю её билдботу, а затем отдам тестировщику, который после регрессионного тестирования сделает merge в мастер. Затем скипятит воду, и пожарит хлеб.
Почему нужно перестать использовать Git rebase