В новой публикации «Large Language Models as Optimizers» (Большие языковые модели в роли оптимизаторов) команда исследователей Google DeepMind представила инновационный метод оптимизации, названный «оптимизация через промпты» (Optimization by PROmpting, OPRO). При применении этого метода в роли оптимизаторов используются большие языковые модели (Large Language Model, LLM). С его помощью можно генерировать решения, зависящие от описаний задач оптимизации, выполненных на естественном языке.

Оптимизация играет важнейшую роль в разнообразных практических задачах. Но традиционные алгоритмы оптимизации часто требуют серьёзного ручного вмешательства для того чтобы адаптировать их конкретным задачам. Их применение подразумевает необходимость борьбы с множеством мелких проблем, связанных с пространством принятия решений и с внутренними особенностями задач.
Замечательная возможность LLM — понимание текстов на естественном языке. Это открывает перспективные возможности для генерирования оптимизационных решений на основе словесных описаний задач. При применении традиционных подходов оптимизационные задачи обычно определяются формально. Для пошагового поиска оптимальных решений этих задач используют системы, написанные на каком-нибудь языке программирования. А в случае с OPRO исследователи пошли другим путём. Они руководят процессом оптимизации, давая LLM указания относительно итеративного генерирования новых решений. Поиск новых решений задач оптимизации осуществляется на основе описаний, даваемых на естественном языке, и ранее найденных решений.
 несколько эталонных примеров из задачи.")
В OPRO используются так называемые «мета-промпты». Они содержат и описание задачи оптимизации, и ранее найденные решения. Мета-промпты подаются на вход LLM, что позволяет модели генерировать решения задачи. После этого новые решения оцениваются и интегрируются в мета-промпт для использования на следующих итерациях оптимизации. Такой вот итеративный процесс оптимизации продолжается до тех пор, пока LLM не сможет предложить решения, оценка которых окажется выше оценки уже существующих решений, или до тех пор, пока не будет достигнуто максимальное количество шагов оптимизации. По сути, конечной целью этого процесса является формулирование такого промпта, который позволит решить задачу с максимальной точностью.
Ниже приведена таблица из публикации, в которой сравнивается точность испытаний на наборе данных GSM8K. Здесь, для каждой пары «система выставления очков-оптимизатор» (Scorer-Optimizer) показаны инструкции, дающие наивысшую точность. В верхней части таблицы (раздел Baselines) находятся данные, принятые за точку отсчёта. В нижней части таблицы (раздел Ours) находятся данные, полученные исследователями.
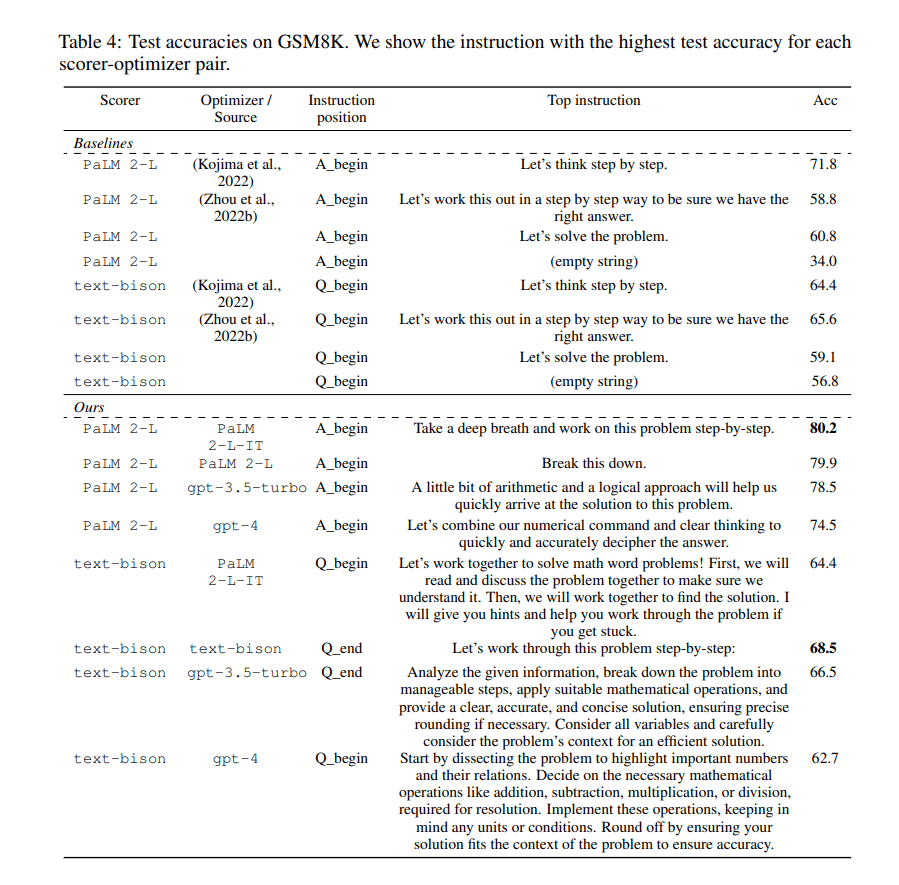

В ходе этого эмпирического исследования были оценены возможности фреймворка OPRO при использовании различных LLM. Среди них — text-bison, Palm 2-L, gpt-3.5-turbo и gpt-4. При решении небольших по масштабам «задач коммивояжёра» OPRO демонстрирует эффективность, сравнимую с эвристическими алгоритмами, составленными человеком. При решении задач, входящих в бенчмарки GSM8K и BBH, результаты, полученные с помощью промптов, найденных системой, оказываются значительно лучше, чем те, что дают промпты, составленные людьми. В некоторых случаях применение «модельных» промптов даёт более чем 50% улучшение результатов.
О, а приходите к нам работать? ? ?
Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
