

Мы стремимся к тому, чтобы после заказа такси к пользователю приезжал чистый, исправный автомобиль той марки, того цвета и с тем номером, которые отображаются в приложении. И для этого мы используем дистанционный контроль качества (ДКК).
Сегодня я расскажу читателям Хабра о том, как с помощью машинного обучения снизить затраты на контроль качества в быстро растущем сервисе с сотнями тысяч машин и не выпустить на линию машину, которая не соответствует правилам сервиса.
Как был устроен ДКК до прихода машинного обучения
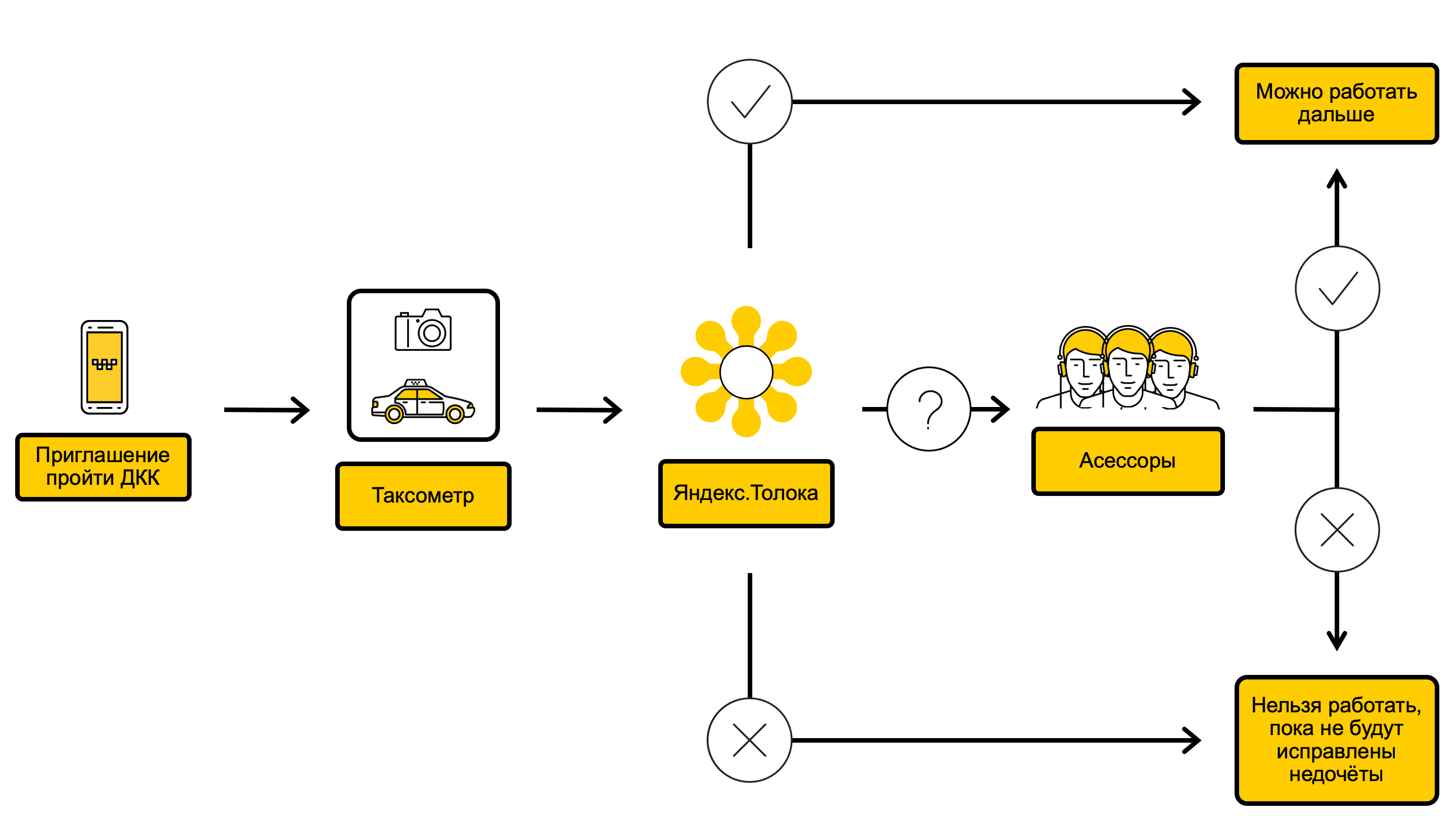
Схема процесса ДКК
В процессе ДКК мы проверяем фотографии автомобиля и принимаем решение о том, можно ли выполнять заказы на таком автомобиле или, например, перед этим его стоит помыть. Всё начинается с того, что через водительское приложение Таксометр мы вызываем водителя на ДКК. Обычно это происходит раз в 10 дней, но иногда реже или чаще – в зависимости от того, насколько успешно водитель проходил предыдущие проверки. Сразу после вызова на ДКК, водителю приходит сообщение с приглашением пройти фотоконтроль. Как только водитель принял приглашение, в том же приложении он фотографирует экстерьер и интерьер машины с разных ракурсов и отправляет фотографии Яндекс.Такси. Водитель может принимать заказы пока идёт ДКК.

Стартовый экран ДКК в приложении Таксометр

Экран фотографирования автомобиля в приложении Таксометр
Полученные фотографии попадают в Яндекс.Толоку — сервис, в котором с помощью краудсорсинга можно быстро выполнять простые, но большие по объёму задания. О том как устроена и зачем нужна Яндекс.Толока мы писали в нашем блоге.
В Яндекс.Толоке в процессе одной проверки как минимум три исполнителя отвечают на вопросы о состоянии автомобиля, и если исполнители пришли к единому мнению, на основе их ответов принимается решение о том, можно ли водителю принимать заказы. У проверки в Яндекс.Толоке два исхода:
- Если визуально с автомобилем всё в порядке, водитель продолжает принимать заказы.
- Если автомобиль грязный, повреждён, либо его марка, цвет или номер не соответствуют указанным в карточке водителя, Яндекс.Такси временно ограничивает возможность водителя принимать заказы.
Если исполнители не пришли к единому мнению, фотографии отправляют к сотрудникам Яндекс.Такси — асессорам, которые более тщательно проверяют автомобиль, а затем принимают финальное решение. Асессоры проходят специальную программу обучения и у них больше опыта.

Так видит ДКК исполнитель Яндекс.Толоки
Задача
C ростом Яндекс.Такси растёт и количество проверок ДКК, а это значит, что растут затраты на толокеров и асессоров. Кроме того, падает скорость проверки автомобиля. Пока идёт ДКК, можно как разрешать водителям принимать заказы, так и не разрешать. У обоих вариантов есть свои минусы: в первом случае недобросовестный водитель успеет принять несколько заказов на автомобиле, который не соответствует стандартам, во втором — все вызванные на фотоконтроль водители не смогут работать пока проверка не завершится. Поэтому важно проверять автомобили быстро, чтобы и пользователи, и водители не сталкивались с неудобствами.
Наблюдая за тем как графики затрат и среднего времени проверки растут, мы поняли, что хотим снизить затраты на Толоку, разгрузить асессоров и сократить среднее время проверки, иными словами, автоматизировать часть проверок. Естественно, мы не хотели жертвовать качеством сервиса и пропускать больше несоотвествующих стандартам качества автомобилей на линию, а также не хотели ограничивать принятие заказов добросовестными водителями. Нам нужно было автоматизировать ДКК и при этом не увеличить долю ошибок в общем потоке проверок.
Как мы внедряли машинное обучение в ДКК
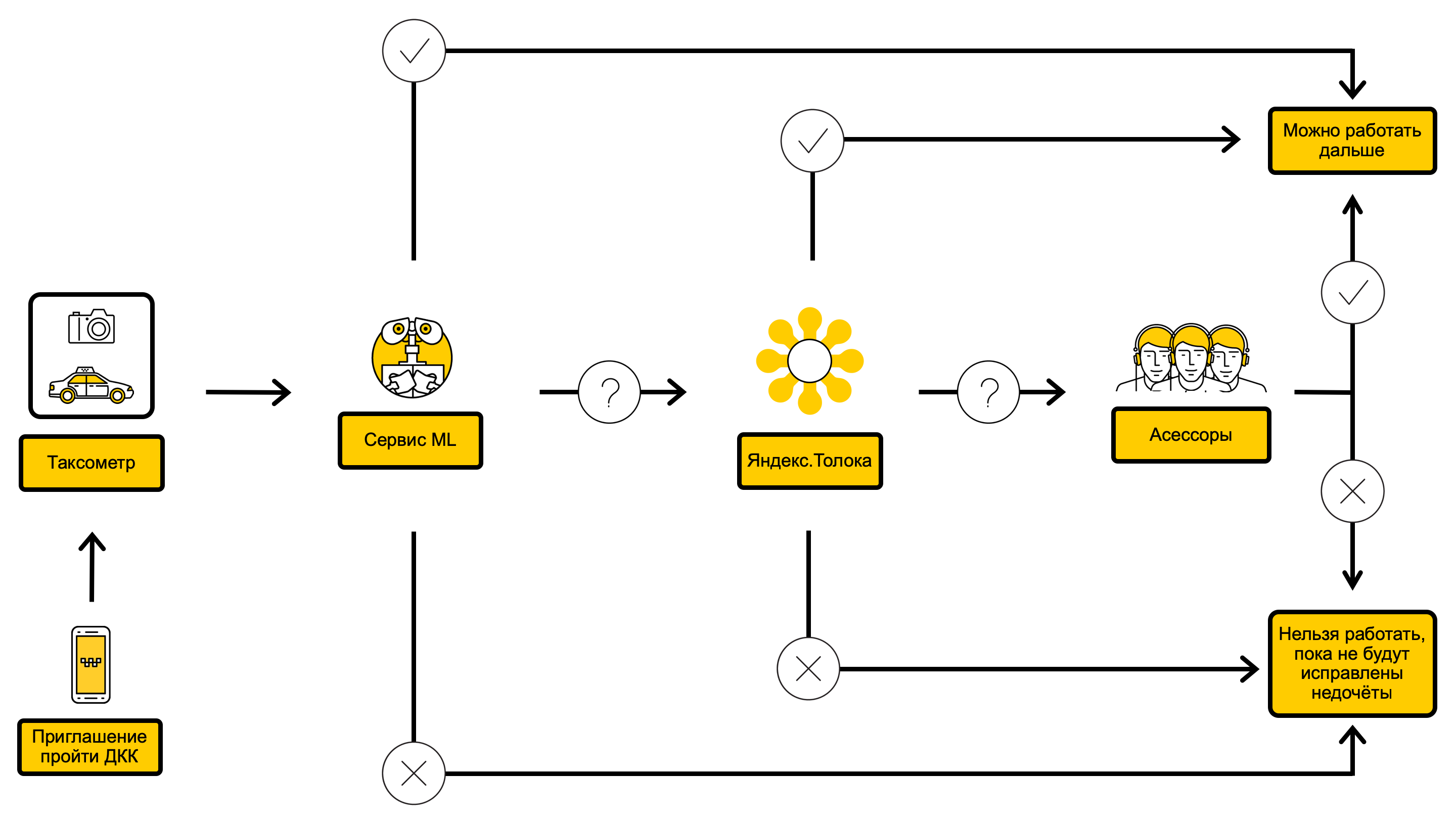
Схема процесса ДКК с ML внутри
Для начала мы определились с постановкой задачи: автоматизировать как можно больше проверок, при этом не увеличив частоту ошибок в общем потоке.
Давайте разберёмся с тем, какими бывают ошибки в нашей задаче. Они бывают двух видов: false positive и false negative. В нашей терминологии negative — результат проверки, с которым водитель может продолжать работать, а positive — результат, который влечёт за собой временное ограничение на приём заказов. Тогда false negative — случай, в котором мы были вынуждены разрешить водителю с плохим автомобилем принимать заказы, а false positive — наоборот, когда мы не разрешили работать водителю, у которого с автомобилем всё хорошо. Выходит, что False Negative Rate (FNR) — доля водителей с «плохими» автомобилями, которым мы разрешили принимать заказы, а False Positive Rate (FPR) — доля водителей, которым мы не разрешили работать, хотя у них с автомобилями всё хорошо. Таким образом, от внедрения машинного обучения в систему мы хотели следующего: автоматизировать как можно больше проверок, при этом не увеличив FPR и FNR в сравнении с системой без машинного обучения.
Далее, необходимо было понять на какие метрики ориентироваться при выборе моделей и порогов для принятия решений на основе их предсказаний. Из условий задачи ясно, что нас интересуют три величины:
- Доля потока, на который модели машинного обучения могут дать ответ автоматически.
- FNR системы.
- FPR системы.
Мы максимизируем первую величину при соблюдении ограничений на вторую и третью.
Тут может возникнуть вопрос: почему бы не максимизировать экономию денег или минимизировать среднее время проверки напрямую, а не через долю автоматизированных проверок? Оптимизировать деньги — очень привлекательная идея, но, как правило, трудноосуществимая. В нашем случае экономия складывается из двух факторов: первый — экономия с каждой автоматизированной проверки, ведь каждая проверка у асессоров или в Яндекс.Толоке стоит денег; второй — экономия с уменьшения числа ошибок, ведь каждая ошибка стоит Яндекс.Такси денег. Объективно посчитать, во сколько нам обходятся ошибки, — очень сложная задача, поэтому мы ограничены расчётом экономии только по первому фактору. Такая величина монотонно возрастает по доле автоматизированных проверок, так что можно максимизировать эту долю вместо экономии. Такие же рассуждения применимы к среднему времени ДКК, оно так же монотонно убывает по доле автоматизированных проверок.
Выбор модели
Можно сказать, что проверка ДКК сводится к выбору вариантов ответов для ряда вопросов о состоянии автомобиля по его фотографиям, а это звучит как задача классификации изображений. Такие задачи решает компьютерное зрение, а в наше время – конкретный инструмент, свёрточные нейронные сети. Их мы и решили использовать для автоматизации ДКК.
Первый вариант решения или подход «всё и сразу»
Теперь, когда мы поняли, что оптимизировать и для чего, настало время собрать данные и обучить на них модели. Собрать данные было легко, потому что все проверки ДКК логируются и лежат в хранилище в удобном виде. В первом варианте решения в качестве признаков выступали фото экстерьера и интерьера машины с четырёх ракурсов, марка, модель и цвет машины, а также результаты 10 предыдущих проверок ДКК. Как целевые переменные мы взяли ответы на все вопросы проверки, например: «Повреждён ли автомобиль?» или «Соответствует ли цвет автомобиля указанному в карточке водителя?». Главной целевой переменной был ответ на главный вопрос: «Нужно ли ограничивать возможность водителя принимать заказы?». Мы учили одну большую модель, очень похожую на VGG с SENet attention, отвечать на все вопросы одновременно и в итоге столкнулись с несколькими проблемами.

Подход «всё и сразу»
Проблемы подхода «всё и сразу»:
- Мы не могли ответить на вопрос о соответствии номера автомобиля на фото указанному в карточке водителя. Большая сеть для классификации изображений не справлялась с такой задачей, для этого нужна специальная модель Optical Character Recognition (OCR), заточенная распознавать номерные знаки.
- Целевая переменная была неполной и зашумлённой. Находя во внешнем виде автомобиля серьёзный недочёт, которого было достаточно для принятия решения, асессоры зачастую забывали ответить на остальные вопросы. А значит, если автомобиль на фото был одновременно и грязным, и битым, то с высокой вероятностью мы наблюдали только одну из отметок: «грязный автомобиль» или «автомобиль с повреждениями», в то время как для нашей модели требовались обе.
- Отсутствовала интерпретируемость решения модели. Модель могла с точностью выше случайной ответить на главный вопрос проверки, но этот ответ слабо коррелировал с ответами на остальные вопросы. Иными словами, если ответ был: «Стоит ограничить возможность принимать заказы», — мы почти никогда не видели причину такого решения в остальных ответах модели. В целом, точность ответов на все вопросы, кроме главного, была близка к случайной. Мы не могли объяснить водителю, что именно нужно исправить, чтобы снова принимать заказы, а значит, не могли ограничивать возможность водителя принимать заказы.
- Количество ошибок false negative в ответе на вопрос: «Нужно ли ограничивать возможность водителя принимать заказы?» — было слишком велико, чтобы начать автоматически одобрять проверки. Мы не смогли обеспечить такой же FNR, как в системе, работающей без машинного обучения, а это было одним из требований в нашей задаче.
Вместе эти четыре причины не позволили нам применить первый вариант решения на практике, но мы не стали унывать и придумали второй вариант.
Второй вариант решения, или подход «всё, но постепенно»
Мы решили сосредоточиться на проверках экстерьера машины, ведь они составляют около 70% всего потока. Кроме того, мы решили разбить общую задачу на подзадачи и научиться отвечать на все вопросы ДКК по отдельности.

Подход «всё, но постепенно»
Когда-то давно наша служба уже занималась автоматизацией ДКК и успела внедрить модель, которая позволяет фильтровать тёмные и нерелевантные фотографии. Эту модель мы продолжили использовать и дальше, чтобы отвечать на вопрос: «Присутствуют ли следующие настоящие фотографии машины: перед, левый бок, правый бок, зад?».
Наша работа над вторым вариантом решения началась с того, что мы использовали модель службы компьютерного зрения Яндекс.Поиска (от тех самых людей, которые сделали DeepHD) для распознавания номерных знаков на автомобилях. Так мы смогли ответить на вопрос: «Соответствуют ли полностью номер и код региона автомобиля указанным в карточке водителя?» Если говорить об этом более подробно, мы сравнивали результат распознавания с указанным в карточке водителя номером и в зависимости от расстояния Левенштейна между ними выбирали один из вариантов ответа: «номер совпадает», «номер не совпадает» или «нельзя точно ответить на вопрос».
Далее мы обучили классификаторы автомобилей распознавать марки и модели, а также цвета. С этого момента мы могли отвечать на вопрос: «Соответствуют ли марка, модель и цвет автомобиля указанным в карточке водителя?»
В завершение мы обучили классификаторы находить повреждённые и грязные автомобили, это позволило закрыть вопросы: «Есть ли повреждения или дефекты на кузове автомобиля?» и «Насколько грязный кузов автомобиля?»
Подход «всё, но постепенно» позволил нам решить проблему проверки номера автомобиля. Также мы смогли избавиться от неполноты и зашумлённости целевой переменной, ведь теперь у нас была выборка, где объектами класса negative были полностью успешные проверки, а объектами класса positive — проверки, где асессор или все три исполнителя Яндекс.Толоки нашли определённый недочёт, например повреждения корпуса. После решения первых двух проблем наши модели стали интерпретируемыми, и мы могли объяснить водителю причину ограничения, чтобы к следующей проверке он исправил недочёты. Общее качество ответов на вопросы также сильно выросло, а FPR и FNR для некоторых комбинаций порогов уверенности моделей упали до уровня Яндекс.Толоки, что позволило внедрять модели в продакшн.
Внедрение в продакшн
Перед нами стоял выбор: запустить регулярный процесс, который будет применять модели к скопившимся в очереди проверкам, или сделать отдельный сервис, куда можно будет ходить по API и получать ответы моделей в реальном времени. Так как для нас важно быстро находить «плохие» автомобили, мы выбрали второй вариант. Как только основная часть сервиса была написана и он смог поддерживать необходимую функциональность, мы начали добавлять в него модели.
Чтобы полностью одобрить проверку, нужно уметь отвечать на все вопросы инструкции, но чтобы ограничить недобросовестному водителю доступ к сервису, в некоторых случаях достаточно уметь отвечать хотя бы на один вопрос. Поэтому мы решили не ждать, пока будут готовы все модели, а добавлять их по мере готовности. Обобщённо пайплайн добавления модели выглядит так:
- Собрать выборку.
- Обучить модель.
- Измерить качество и подобрать пороги офлайн.
- Добавить модель в сервис в фоновом режиме и измерить качество онлайн.
- Включить модель в продакшн и начать принимать решения на основе её предсказаний.
Такой подход позволил нам не только моментально находить всё больше «плохих» автомобилей по мере внедрения новых моделей, но и без дополнительных временных затрат измерять качество онлайн, пока модели работали в фоновом режиме.
В конце концов наступил момент, когда мы добавили в сервис и протестировали последнюю модель. Теперь мы могли отвечать на все вопросы проверок, а значит автоматически их одобрять. Так как «хороших» автомобилей в Яндекс.Такси гораздо больше, чем «плохих», автоматическое одобрение проверок привело к резкому росту нашей основной метрики — части потока автоматизированных проверок. Нам оставалось только подобрать правильные пороги, которые бы максимизировали долю автоматизированных проверок, при этом сохраняя общие FPR и FNR всей системы на прежнем уровне. Для подбора порогов мы использовали выборку, которую независимо друг от друга размечали исполнители Яндекс.Толоки, асессоры и сотрудник Яндекс.Такси, обучавший асессоров проверять автомобили. Его разметку мы и использовали в качестве истинных значений целевой переменной.
Результаты
Как только мы включили модели в продакшн, нужно было измерить онлайн-качество решений, принятых на основе их ответов. И вот какие цифры мы увидели:
- 30% проверок экстерьера автомобиля теперь получали автоматический ответ.
- FNR остался на том же уровне, а FPR упал, и мы стали реже ограничивать доступ к сервису тем, кто этого не заслужил.
- На 14% снизилась нагрузка на асессоров, и они смогли больше времени уделять сложным проверкам, которые не смог взять на себя сервис машинного обучения.
- Время обнаружения автомобилей с серьёзными недочётами в ходе проверки сократилось с нескольких часов до нескольких секунд.
Таким образом, внедрение машинного обучения не только помогло сэкономить деньги, но и позволило сделать сервис более безопасным и комфортным для пользователей. Тем не менее, это ещё далеко не конец истории. Наша быстро растущая команда и дальше будет активно работать над тем, чтобы автоматизировать ещё больше проверок и сделать Яндекс.Такси ещё более удобным, комфортным и безопасным.
Мораль истории
В работе над автоматизацией ДКК в Яндекс.Такси мы столкнулись с множеством проблем, отыскали несколько успешных решений и сделали шесть важных выводов:
- Не всегда можно решить задачу в лоб (даже если у вас есть Deep learning).
- Модель настолько хороша, насколько хороши данные, на которых её обучили (звучит банально, но это так).
- В решении любой задачи важно отталкиваться от реальных нужд бизнеса, а не от минимизации кросс-энтропии.
- В решении некоторых задач люди по прежнему важны, несмотря на внедрение машинного обучения (привет, Яндекс.Толока!).
- Решения на основе предсказаний моделей машинного обучения могут приниматься не во всех случаях, а только в той части, где модели очень уверены в своих ответах. В остальных случаях, вероятно, стоит принимать решения старым способом — с помощью людей.
- Помимо выбора архитектуры и обучения модели, есть ещё множество стадий проекта, которые могут очень сильно повлиять на то, как хорошо будет решена задача бизнеса. Эти стадии: сбор данных, выбор метрик качества, варианта внедрения модели, продуктовой логики принятия решений на основе предсказаний моделей и многое другое.
